
基于注意力机制的单视角三维重建
2019-08-15 10:51胡飞叶龙钟微张勤
中国传媒大学学报(自然科学版) 2019年4期
胡飞,叶龙,钟微,张勤
(中国传媒大学媒介音视频教育部重点实验室 北京 100024)
1 引言
三维重建是建模中不可或缺的问题。对于三维物体,二维图像仅是物体部分数据采样。因此,在将图像转换为三维模型时,尤其是当我们从一个单一视图重建三维对象时,对象的细节非常容易丢失。在这种情况下,主要的挑战是使计算焦点更加关注潜在的细节缺失区域,以便可以更完整地重建三维对象。
手动三维建模需要很高的成本,并且正在被自动重建方法所取代。深度学习在图像领域的发展是及其成功,而其在三维视觉领域的应用则才刚刚开始。随着大规模三维数据集合,诸如IKEA 3D、PASCAL 3D+[1]、ShapeNet 等数据库的全面建立,已经有大量的学者将研究的目标放在的基于深度学习的三维视觉领域。
由于神经网络对输入和输出的表示有标准化的要求,因此多边形网格和隐式曲面的表示并不太容易应用到学习方法中。尽管体素表示的复杂性很高,但体素的矩阵表示的性质完全满足标准化的要求。因此,体素表示是基于学习的3D重建中的常见表示。当然,固定点数的点云表示也是另一种折衷方法。本文主要研究基于体素表示的方法。
Abhishek Kar[1]等人在2014年提出了PASCAL 3D+的三维数据集,通过图像分割网络和视角估计网络的结合,在固定类别的基础上完成了三维模型的重建。
Andrey Kurenkov[2]等人引入了一个模型字典库,根据输入图像,在模型字典库中找去最接近的一个备选模型,将输入图像与备选模型一起进入网络,最终完成整个重建过程。
Maxim Tatarchenko等人在[3]中加入了视角信息的编码,完成了从普通RGB图像到RGBD图像的转换,网咯分别接收图像和视角信息。
Christopher B. Choy等人在[4]中,引入了长短期记忆网络(Long Short-Term Memory,LSTM)的思想。作者构造了一个3D-LSTM的结构,巧妙的在一个网络中实现了1个视角及多个视角的三维重建。
Fan H等人[5]则是完成了基于单视角的点云重建,作者首先将问题定性为固定点数的三维重建,并根据任务测试了不同的网路结构和损失函数。
[6]创造性的完成了端到端的单视角图像直接生成点线面模型的任务,本文巧妙的利用了图卷积网络的表示方法,网络结构如图1.7所示,并针对任务构建相应的损失函数和评价方法,使得深度学习与三维重建的结合前进了一大步。
当我们重现现有论文的实验时,我们发现输出模型通常缺乏细节信息。我们将问题归结为单视图重建任务的病态性和现有网络的片面性。而这些细节部分可以在相应的输入图像中找到对应的像素点。因此,我们希望通过引入注意力机制来解决这个问题。
本文整体结构安排如下:第二章介绍注意力机制和网络模型,第三章介绍我们是如何将注意力机制引入到三维重建模型中,第四章用实验对比来验证我们的模型在三维重建中的有效性。
2 基于注意力机制的模型
注意力机制是人工智能领域对神经科学研究[7,8]中的视觉模式的模仿。
神经科学的研究[7,8]中发现,许多动物通常只关注其视觉输入的特定部分以计算适当的反应。将这个原理迁移到计算机视觉中,即在相应的视觉任务中,我们所获得的数据在任务中是冗余的,我们不需要对所有的信息平均话处理,我们只需要选择与目标任务最相关的信息。在深度学习和人工智能发展之后,许多研究人员对神经网络中的注意力机制进行了广泛的研究[9-12]。
为了解决生成模型的细节缺失问题,我们将注意力机制引入到三维重建中来。本章采用的是软注意力机制的方法。我们整体网络框架如图1所示,它由两个分支完成,上支为三维自动编码器网络(3D Autoencoder,3DAE),输入为单幅图像,以编码器-解码器的结构生成3D轮廓;下支为注意力网络(Attention Network),采用图像输入,通过注意力机制提取细节信息,然后解码5生成上支所缺失的细节。最后,我们将两者结合生成完整的3D形状。
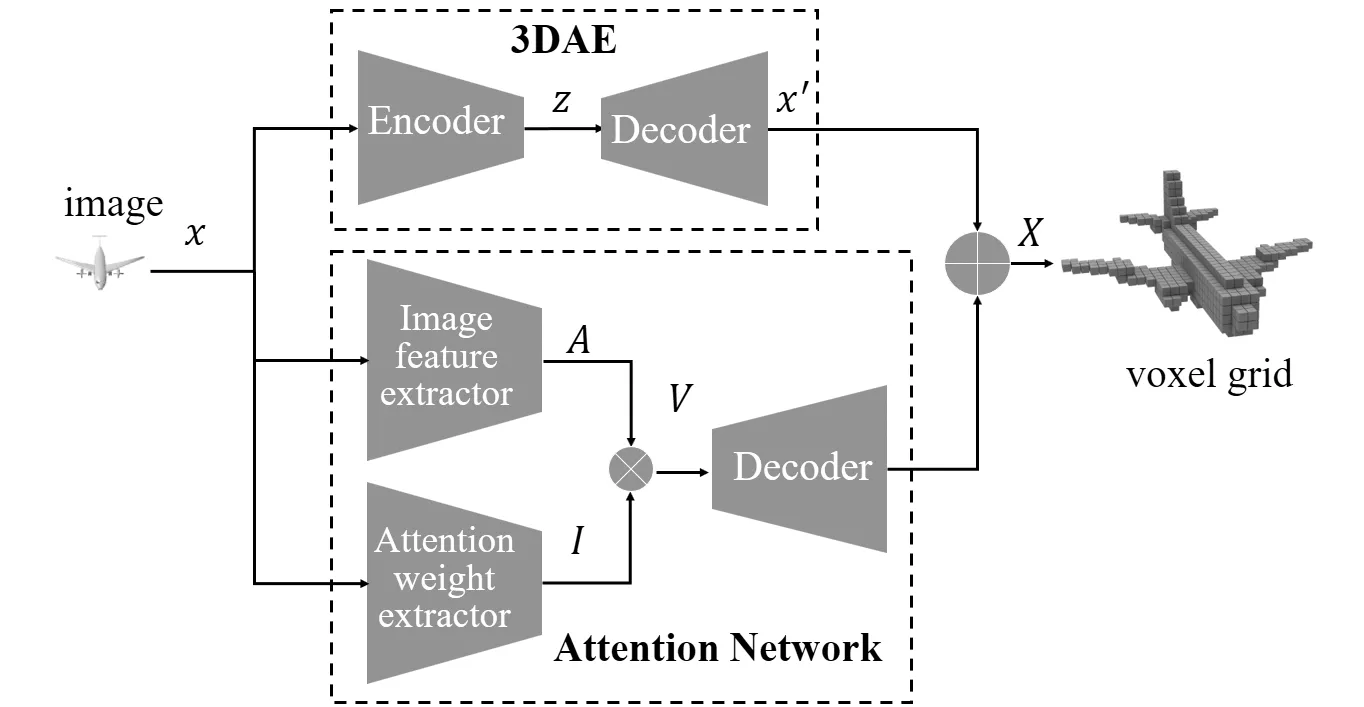
图1 注意力-自编码三维重建网络(AAN)网络结构图
我们将图1的网络称为注意力-自编码三维重建网络(Attention-Autoencoder Network,AAN)。
2.1 3DAE网络结构
自动编码器是由编码器和解码器组成的生成模型。自动编码器是生成任务中最常用的模型。本文从任意视图采样的二维图像送到二维图像编码器以产生低维特征向量。三维体素解码器扩展图像特征以生成相应的三维体素。
也就是说,我们结构由两个自动编码器组合而成,如图2所示,我们预训练一个二维图像的变分自动编码器以及一个三维模型的变分自动编码器,选取2D自动编码器的编码器部分与3D自动编码器的解码器部分相结合。

图2 两个变分自动编码器的组合过程
令先验的隐变量为中心各向同性多元高斯,渲染图像是从某个先验分布p(I)生成的,真实模型是从某个先验分布p(V)生成的。假设我们可以在隐变量空间中推断出相同的特征:z | I=z | V。这意味着图像p(z | I)的后验分布等于体素的后验分布,p(z | V)。q(z)~N(u,d)是对后验p(z | I)的变分近似。通过重新参数化的技巧,q(z)被重写为q(z)=u + d * N(0,I)。使用编码器网络,我们可以学习u,d,然后从分布N(0,1)中采样随机变量e。利用3DAE解码网络,我们可以从后验变量z=u + d * e推断出三维表示。
如果输入图像、输出体素和权重是固定的,那么在隐变量空间中只有一个固定变量z能生成唯一的输出。也就是说解码网络推断的是精确的z,而不是随机变量。因此,利用连续向量(u,d),存在某个向量e,网络可以利用该向量e推断出2D图像的某个3D表示。这意味着变量(u,d)是图像和各个体素的共有特征。
因此我们删除了结构中的采样过程,如图3所示,我们的网络由两部分组成:2D卷积神经网络和3D反卷积神经网络。
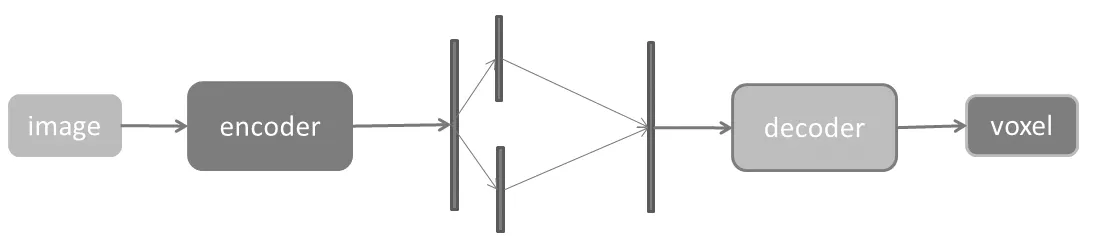
图3 3DAE的基本网络结构
我们的重建网络由两部分组成:图像编码器和体素解码器。在每个全连接层后,放置非线性激活函数。编码器将127 * 127的 RGB图像转换为低维特征,然后将其馈送到变换单元。解码器然后获取3D低维特征并将它们变换为最终体素。
第三章的实验部分会更进一步验证我们的网络结构去随机变量的合理性问题。
2.2 注意力机制
为了解决细节缺失的问题,我们在3DAE重建网络中增加了注意力分支,以完成三维模型的形状。我们设计了一个基于卷积的注意力网络(如图3.13的下半部分所示),以建立体积占用中缺失细节与图像局部特征之间的对应关系。
卷积网络可以从2D图像中提取一组特征向量。提取器产生m维向量A,其每个元素代表图像的局部区域。
A={a1,a2,…,am},am
(1)
由于3DAE可以产生粗略的形状,我们可以获得无法重建的残余体素。在卷积注意力网络中,反向传播算法将残余体素投射回注意力权重特征向量。映射关系记录为I,并且可以从中间层获得。I是n维向量,并且每个元素表示图像的这些局部区域与残余体素之间的相关性。这样它就可以被视为重要加权特征向量。
I={i1,i2,…,in},in
(2)
总的来说,如图1的下半部分所示,我们将2D图像x馈送到注意力网络。从两个子分支(即,将图像特征提取作为权重矩阵Wf和重要性加权提取作为权重矩阵Ww),当m=n时,我们可以得到关注向量V。V包含不同图像区域有助于形状完成的各种信息。在馈入解码器Wd之后,V被扩展到残余体素。该过程用以下公式表示,X是全形状三维模型的分布。
V=Wfx⊙(Wwx)T=A⊙I
(3)
X-x′=Wd·V
(4)
注意力网络是AAN的体素补充分支,与3DAE分支共享相同的输入图像。它建立了图像局部特征与缺失边缘体素之间的映射关系,并利用这种关系赋予图像更重要区域更高的权重。通过与3DAE分支相同的解码架构,Attention Network可以精确地生成更好的细节体素模型。
图3.16是我们的模型可视化的重建样例,图片(b)、(c)两列能够清晰的显示注意力模型在生成模型的过程中所起到的作用。

图4 重建可视化的样例。第一排是飞机,第二排是汽车。(a)列是ShapeNet数据集中的真实数据。(b)和(c)是相同预测值的不同投影,其中蓝色体素网格由3DAE网络生,粉红色体素网格由注意力网络生成
2.3 损失函数
我们的重建网络由两部分组成:图像编码器和体素解码器。在每个全连接层后,放置非线性激活函数。编码器将127 * 127的 RGB图像转换为低维特征,然后将其馈送到变换单元。解码器然后获取3D低维特征并将它们变换为最终体素。
损失函数是影响网络收敛的关键因素,在本任务中将采用组合损失函数。
由于模型的表示是体素网格,这是一个的二值矩阵,因此体素重建任务可以看成32768维的逻辑回归任务。由于三维体素的稀疏性,重建问题是一个大规模不均衡分布分类问题。常用处理非均衡数据问题的函数是加权交叉熵损失函数:
wSCE=-w*t*log(σ(o))
-(1-t)*log(1-σ(0))
(5)
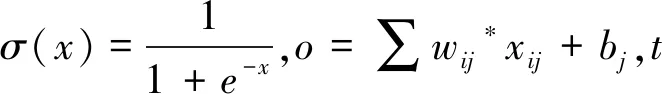
而交叉熵损失函数主要使得预测分布与目标分布之间的距离接近,而我们的三维重建任务中,除了要保证分布上的一致性,还需要保证具体每一个体素上的一致性。因此,我们对加权交叉熵损失函数加以细微调整,增加二阶距修正项,表达式如下:
Loss=-w*t*log(σ(o))-(1-t)*log(1-σ(o))+λ(t-σ(o))2
(6)
其中λ为超参数。
当然在实验中,我们还测试了其他几种用于非均衡数据的损失函数,包括disc function、focal loss function等损失函数,其中disc function的函数为:
(7)
Focal Loss Funciton表示如下:
(8)
为了避免两个超参数的大量调参,我们在实验中采用了如下的简化形式:
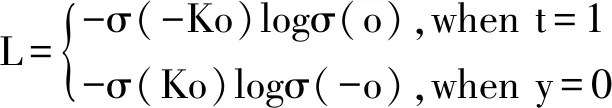
(9)
其中K为超参数,我们在雏形网络上,我们分别在带随机变量和不带随机变量的网络中测试了以上各种损失函数。详细的实验结果可以参见第三章。
3 实验与分析
在本章节,我们将给出具体的实验参数和实验结果,并定性定量的分析了我们的实验结果。
3.1 数据集和实验细节
本文采用两个数据集,ShapeNet和Pascal 3D+。
ShapeNet是一个数据量相当庞大的三维模型数据集,是由普林斯顿大学,斯坦福大学和TTIC的研究人员所收集整理。该数据集为开放数据集部分开放。为世界各地的研究人员提供这些数据,以便在计算机图形学,计算机视觉,机器人学和其他相关学科方面进行研究。该数据集包含两个子集,ShapeNetCore和ShapeNetSem。
ShapeNetCore是完整ShapeNet数据集的子集,具有单个清洁三维模型和手动验证的类别和对齐注释。它涵盖55个常见对象类别,约有51,300个独特的三维模型。
ShapeNetSem是一个更小,更密集注释的子集,由12,000个模型组成,分布在更广泛的270个类别中。除了手动验证的类别标签外,这些模型还使用实际维度进行注释,在类别级别估算其材料成分,并估算其总体积和重量。
本文所测试的数据集,对ShapeNetCore筛选掉部分较少*类别后的数据集,其中包含13个常见类别中的约40,000个三维模型。后文中,我们统一称该数据集为ShapeNet。
PASCAL 3D +于2014年由斯坦福大学计算视觉和几何实验室收集整理,这是一个用于3D物体检测和姿态估计的数据集。该数据集包含PASCAL VOC 2012的12个对象类别中的12,093个3D CAD模型,这些类别均由ShapeNetCore涵盖。我们将这些CAD模型统一转换为我们所需要体素格式。我们将数据集分成训练和测试集,其中1/2用于训练,剩下的1/2用于测试。
所有体素统一采用32×32×32的分辨率,每一个32×32×32的体素模型在网络计算中,对应一个32×32×32的矩阵,占用体素块的对应矩阵值为1,否者为0。
我们在所有实验中使用ADAM算法回传神经网络。预训练神经网络的学习率为0.001,正式训练时的神经网络的学习率为0.0001。
我们在实验测试阶段准确率采用的是IoU(intersection-over-union)。该指标用于衡量特定数据集上对象检测器的准确性。常见的对象检测如PASCAL VOC任务评价指标就可以用IoU来衡量。

3.2 去随机变量的有效性验证
为了验证损失函数的有效性,我们分别在添加随机变量和不添加随机变量的网络中分别实验了章节3.2中的各个损失函数,网络结构如图5、6所示。

图5 3DAE带随机变量的网络结构
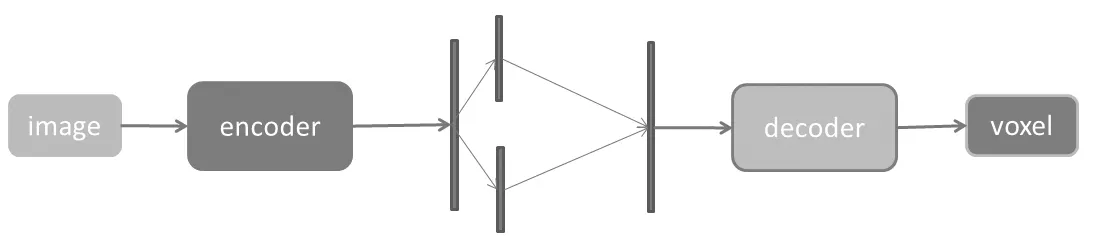
图6 3DAE不带随机变量的网络结构
我们在ShapeNet上完成对应的不同实验,实验结果如表1所示,通过在不同损失函数的模型测试结果,我们发现所有结果均为不带随机变量的模型结果要优于带随机变量的模型结果。而该测试结果也从侧面应正了我们损失函数的有效性。

表1 网络中关于网络结构和损失函数的测试
3.3 ShapeNet测试分析
我们首先在ShapeNet上测试我们的模型,我们将我们的结果与现有的深度学习三维重建方法3D-R2N2[4],PSGN[5]的结果进行比较。我们的注意力-自编码三维重建网络(AAN)和比较方法的13个类别的IoU准确度如表2所示。
其中3D-R2N2是从单视图或多视图图像重建三维模型。表2中的结果显示,单视图重建结果中,我们在大多数类别中实现了更好的性能。特别是,在13个类别中的8个中,我们的结果甚至比用于5个视图的3D-R2N2重建更好。尽管PSGN在某些类别中实现了更高的IoU准确度,但生成的三维模型由固定数量的1024个点表示,不同于我们的注意力-自编码三维重建网络(AAN)具有32×32×32的维度占用问题,这意味着评估的比较是不公平的,并且PSGN中更高的IoU准确度与模型看起来更不具有正相关性。3DAN的类别平均IoU为0.627,而AAN的IoU为 0.640,这也显示了注意力机制的有效性。
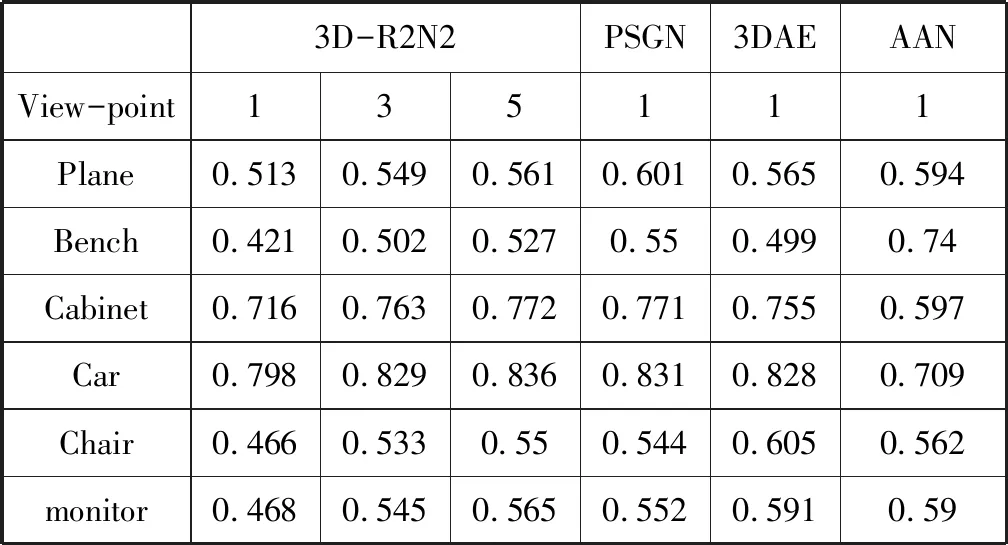
表2 各个算法在ShapeNet数据集上的三维重建结果IoU测试结果
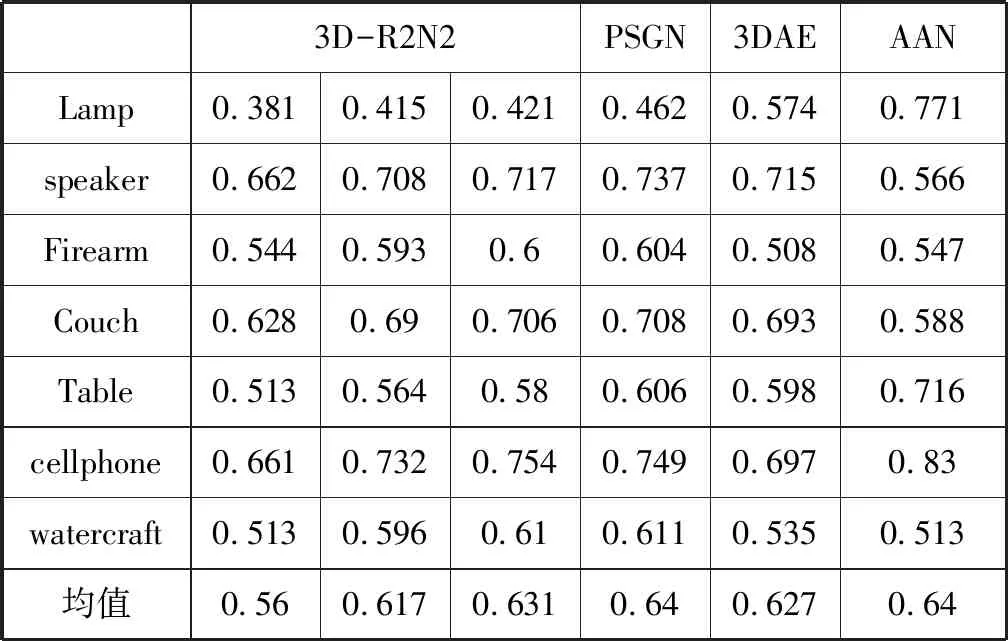
续表
我们的实验结果的体素网格可视化显示在图7中,我们将AAN的重建结果与3D-R2N2和3DAE进行定性分析比较(因为PSGN预测了3D点云,在视觉上是不可比性的)。第一列是三维对象的二维单视角视图,第二列是ShapeNet数据集中的体素模型真实值。其他列则是来自单视觉图像的网络重建实验结果,实线部分是真实值的边界线,因此我们可以明确地看到区别。前五个重建样本显示我们AAN弥补了缺乏的细节,特别是在第四排的椅子腿等纤细结构中,这样我们就能得到更精确的结果。最后两行显示了重建物体依然存在空洞,这是现有技术方法的局限性。

图7 各算法模型在ShapeNet上的输出可视化
3.4 Pascal 3D+数据集测试
为了验证网络的泛化性,我们在数据集Pascal 3D+,同样对我们的网络进行了测试,测试的平均IoU结果如表3所示。图8是我们的AAN网络的部分预测结果展示。
表3中的平均IoU结果显示,我们的模型是要优于另外两种现有模型的。

表3 已有各个算法在Pascal 3D+上平均IoU

图8 模型在Pascal 3D+上的数据可视化,其中第一列是图像,第二列是真实值,第三列是预测模型
4 结论
本文针对三维重建中的细节缺失问题提出了一种基于注意力机制的完成三维重建的方法。模型由两个部分完成,一个部分以单幅图像为输入,以自动编码器的结构完成三维雏形构建;另一个部分同样采用图像输入,通过注意力机制提取细节信息,生成雏形中所缺失的细节。最后,我们将两者合并生成更为完整的三维形状。值得注意的是,在自动编码器结构部分去掉随机变量后,该部分的网络结构本质上已经变成了一个基本自动编码器的结构,而不是初始化的变分自动编码器,两个变分自动编码器仅仅是为了给我们雏形构建部分的网络提供一个较好的初始值。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
家庭医学(2022年3期)2022-04-07
锻压装备与制造技术(2021年5期)2021-11-13
贵州大学学报(自然科学版)(2021年5期)2021-09-26
北京航空航天大学学报(2021年6期)2021-07-20
电子技术与软件工程(2021年8期)2021-06-16
现代计算机(2021年8期)2021-05-13
科学技术创新(2021年5期)2021-03-17
中华养生保健(2020年7期)2020-11-16
——编码器
演艺科技(2020年7期)2020-08-13
