
面向异构金融数据的情感分析方法研究
2019-08-12 03:44:44郑天宇
现代计算机 2019年19期
郑天宇
(上海海事大学信息工程学院,上海201306)
0 引言
基于网络的技术不断被金融领域所接受,投资者可以在线下轻而易举地获得关于上市公司的经营信息。随着2000 亿条微博被国家图书馆保存,舆情作为一种新的消息来源与分析媒介在生活和工作中越来越重要地得以展现。新闻网站和股吧作为一种金融界信息发布与交换的方式,已逐渐成为消息披露和交易决策交换等相关信息的主要来源。舆情网站为各个领域的投资者提供了一个平台,使得人们可以聚集在一起,接收并分享他们对公司股票的看法。但由于关键的信息隐藏在大量数据中,从海量文本中获取有用的信息仍然很困难,投资决策者几乎不可能阅读完相关网站并罗列出所有信息,因此提供可以准确获取舆情信息的方法可以极大地帮助投资者进行投资决策[1-3]。
网站中包含的数据几乎没有结构化的,如何有效地处理和利用非结构化数据是一个具有挑战性的机器学习问题。在金融网站的新闻发布子模块,每个数据条目都与某一时刻股票的表现及市场看法有关,将此看作可用时间序列表示的金融异构数据[4]。某些主题词语和主题的频率均是随时间变化的,对股票的看法也随着时间的推移及其在证券交易所的种种行为表现而变化。也就是说股票的情绪展现和股价走势及外部事件之间存在相关性,Chen 等人[5]发现多种信息源头例如博客等可以密切预测股市行为。
1 系统概述
第一步涉及数据采集,我们从cnstock 抓取了金融新闻消息板并将数据利用pymongo 存储在MongoDB中。下一步是从非结构化数据中提取消息。首先进行预处理,删除常见HTML 标签提取有用的部分,如我们需要的日期、作者、消息文本等。然后基于提取的信息构建情感分类器。通过比对异构数据预测出的情感与该支股票的日线数据得到的实际价值,给对应的先前新闻打上“看涨”、“看跌”的标签并由新算法计算出新闻作者总体的情感阈值,利用此步骤对一支股票相关的未打标签的新闻异构文本构建新特征集进行文本分析。系统架构如图1 所示。
1.1 数据收集
基于Scrapy 和Redis 的分布式技术编写爬虫。crawler_cnstock、crawler_jrj 主要爬取中国证券网、金融界汇总的股票新闻模块的新闻标题、内容、作者、时间、网址,由于服务器时而存在无响应问题,我们重复运行爬虫汇总了三日内的异构文本数据。为了获取沪深股票的行情表现数据,我们从Tushare 获取日线数据,特征包括开盘价、最高价、最低价、成交额、股票代码、名称、板块等信息。

图1 新闻文本计算情感权重预测股票表现系统构架
提取相关信息后,依次对爬取入库的新闻文本进行去停用词、加载股票名称新词、将语料库中每段异构信息转换为单个词语和作者(包括姓名及新闻机构名称)的向量,日期我们采取映射成整数值的形式,使用TF-IDF 公式计算向量中每个条目的值:

TF-IDF(词频-逆文档频率)用于评估包含单词或特征的条目对语料库中整体信息的重要程度,随该条目在某一文章出现次数增加而重要比例增加,随在语料库中出现频率的增加而重要程度衰减。
1.2 情感预测
首先假设公司发布的官方新闻与股票的表现有很高的相关性。同样地,在股票表现发生剧烈变化时,跟风的新闻机构的情感也可能发生变化。基于以上直觉,我们将情感建模为一种有条件依赖于过去一天的舆情和股票价值的马尔科夫过程。即在时刻i,对新闻m 的情感建模如下:
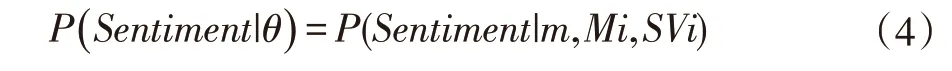
i+1 时刻的预测会取决于先前i 时刻的值,Mi 为i时刻的消息集,SVi 为i 时刻的股票价值表现(以收盘价为例)。选择合适的学习算法训练上述模型的参数。由于未来将面临较大异构数据集的考验,我们使用朴素贝叶斯及决策树进行训练。
1.3 情感权重值计算
基于有些新闻发布机构对于金融市场更加权威这一观点,专业的金融分析报道者理应获得更多的情感权重值,这意味着他们发布的舆论比其他人发布的观点更为可信且重要。但根据用户画像获得作者的背景在情感分析的领域往往较为困难,面相媒体舆情的情感分析很少去获得舆情源头的画像资料,因为就像有些股吧论坛中的这些特征用户可以任意填入他们自己有关的背景信息,有些媒体机构也可以留下无用或是不准确的信息。
我们使用算法依据舆情创作人在他们资料中的历史表现来计算作者的情感权重值,对每条信息使用情感预测步骤得出作者的情感倾向可能,并将该信息发布时间附近的实际股价表现进行横向比较,如果作者表达的情感倾向符合实际股价表现,那么作者或新闻机构的情感权重值将会增加。考虑到一个公式(5)、(6)除了在方向上可以计算符合度方向,还可以关注幅度,例如:上述步骤训练出作者情感为强烈沽空一只股票,但股票表现的收盘价仅略有下降,那么作者也不会得到太多情感权重。

其中,SentimentProbability 表示情感倾向概率,MidScore 为设置的常数,在情感倾向中通常设置为表示中性的0.5,StockChange 为收盘价较昨日收盘价的涨跌百分比,将此项和情感倾向概率组合作为权重赋给新闻作者的情感预测表现。NumOfPrecision、NumOf-Normal 和NumOfPrediction 分别代表新闻作者精准预测的次数、一般符合的次数及预测匹配总次数,Sector-Coefficient 是一个惩罚系数,当新闻评论的是一个板块时,此项设置为1 用于抵消作者的情感匹配度。
1.4 股票预测
股票预测是一项艰难的任务,在方法中,我们根据对应的新闻情感对时间i 处的股票价值进行预测:
图2 展示了用于贝叶斯网的股票预测模型,训练一种分类器使用过去一天提取或计算出的融合特征来预测股票价格的涨跌,特征包含情感倾向、归属作者的情感权重值及该股涉及的新闻总数。
同时为验证文本信息中作者情感权重是否和股票价格之间有显著性关系,利用以资产定价模型为代表的因子模型加入语料库中目标股票对应新闻的所有作者的情感权重平均值,以对数收益率确定待估系数,公式(7)如下:
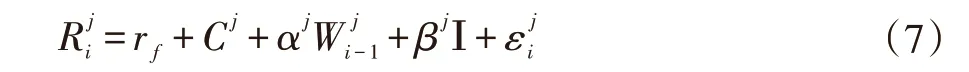
模型中,标签使用表示i 时刻股票j 的价格S 的对数收益率,rf是假设的该年沪深指数的年平均收益率的日化收益,以此来代替无风险收益率,为日期i 时股票j 对应的新闻所属作者的情感权重均值,Ι 为指示函数,为服从正态分布的随机数噪声,待估系数分别是Cj、αj、βj。但从回归的结果我们看到股价收益率虽然和网络新闻舆情具备显著相关特征,但的αj系数极小,对应的t、F 统计量很大,说明影响虽显著相关但对其影响的范围很小。假设是由于参差不齐水平的新闻作者发布的若干舆情在可信度上进行了标准化,为准确说明这一现象,我们再对上步骤得到的作者情感权重依次排序,取3 个分位数,然后按照分位数对股票的舆情发布机构作者的情感权重值分块为3 组,分别是WB1、WB2、WB3,模型如下。这样做的好处是保证分组后组内新闻数目是一致的但不同组别意味着不同的作者情感权重(权重值依次增大),并依照这种方法将相似文本特征的异构金融数据进行文本分类及预测。
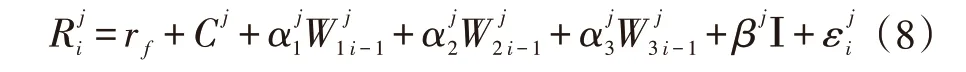
2 实验与结果
对6 支股票的128 支新闻及对应的47 个作者的相关数据针对对数收益率进行线性回归,回归结果如表1 所示。

表1 回归结果
可以看到α3比α1、α2大了一个数量级别,对于单日收益率而言,一个数量级别已经对对数收益提供了很好的解释力。根据代表信任程度较高的高权重作者情感对金融市场投资者的决策更具影响力,从而更能影响次日的股票收益。表2 显示使用朴素贝叶斯对涵盖6 个板块的个股情感预测准确度的结果。

表2 加入情感权重前后股票表现预测的准确度
使用加入作者情感权重值的情感预测模型的性格会得到提升,针对不同板块增加了1%-8%不等的准确度,表明了加入作者情感权重可以帮助消除文本情感噪音。
3 结语
本文在考虑现有的面向金融新闻文本情感提取算法的基础上加以改进,使其能更好地为文本情感分析决策提供支持。同时引入了文本源头的情感权重值,在消除过滤情感倾向预测中不相关噪声情绪的同时提高了准确率。接下来如何在长范围时间序列的基础上进一步提升预测准确率,需要更进一步的研究。
猜你喜欢
当代陕西(2020年17期)2020-10-28 08:18:18
人大建设(2018年5期)2018-08-16 07:09:00
电信科学(2017年6期)2017-07-01 15:44:57
股市动态分析(2016年23期)2016-12-27 19:01:58
股市动态分析(2016年22期)2016-12-27 10:39:02
股市动态分析(2016年7期)2016-09-29 11:18:25
股市动态分析(2016年4期)2016-09-29 08:39:10
中国民政(2016年16期)2016-09-19 02:16:48
中国民政(2016年10期)2016-06-05 09:04:16
中国民政(2016年24期)2016-02-11 03:34:38
