
基于经验指导的深度确定性多行动者-评论家算法
2019-07-30 11:26:54陈红名姜玉斌张琳琳
计算机研究与发展 2019年8期
陈红名 刘 全,2,3,4 闫 岩 何 斌 姜玉斌 张琳琳
1(苏州大学计算机科学与技术学院 江苏苏州 215006)2(江苏省计算机信息处理技术重点实验室(苏州大学) 江苏苏州 215006)3(符号计算与知识工程教育部重点实验室(吉林大学) 长春 130012)4(软件新技术与产业化协同创新中心 南京 210000)
目前,强化学习已经广泛应用于仿真模拟、工业控制和博弈游戏等领域[1-5].强化学习(reinforcement learning)的目标是学习一个最优策略使得智能体(agent)能够获得最大的累积奖赏[6].强化学习方法大体上可以分为3类:基于值函数的方法、策略搜索方法(或策略梯度方法)和行动者-评论家方法.
基于值函数的方法通过学习一个值函数获得一个最优策略,这种方法适用于离散动作空间的任务,对于连续动作空间来说是并不适用的.例如Rummery和Niranjan[7]提出的Sarsa算法、Watkins等人[8]提出的Q-Learning算法.对比基于值函数的方法,策略搜索方法并没有学习值函数而是直接学习一个策略,使得累积奖赏最大化.例如Williams提出的基于蒙特卡洛方法[9](Monte Carlo methods, MC)的强化(reinforce)算法和使用基线的强化(reinforce with baseline)算法[10],后者是前者的泛化.行动者-评论家算法结合了基于值的方法和策略搜索方法,其中参数化的策略称为行动者,学习到的值函数称为评论家.例如Barto和Sutton等人[11]提出的行动者-评论家算法(actor-critic, AC),Peters和Schaal提出的自然行动者-评论家方法[12](natural actor-critic, NAC).
传统强化学习面临的问题是对于高维状态动作空间感知能力不足.最近几年随着深度学习(deep learning, DL)的流行,由于其对高维状态动作空间有很好的表示能力,因此深度学习与传统强化学习的结合产生了深度强化学习(deep reinforcement learning, DRL)这一研究热点.这一类方法在一些游戏和机器人控制任务上取得了不错的成果.比如基于Q-Learning的深度Q网络(deep Q-network, DQN)[13]算法在49个Atari 2600游戏中的实验结果超过以往所有算法,并且可以媲美职业人类玩家的水平.在DQN之上有很多改进的算法版本,例如在此基础上提出的竞争网络结构[14](dueling network architecture, DNA)和可用于连续动作空间的归一化优势函数连续Q学习[15](continuous Q-Learning with normalized advantage functions, NAF)等,还有基于行动者-评论家方法的深度确定性策略梯度[16](deep deterministic policy gradient, DDPG)方法,以及异步优势行动者-评论家[17](asynchronous advantage actor-critic, A3C)方法等.此外深度强化学习在其他研究方向比如图像处理、自然语言处理等都有一些重要应用[18-20].
基于值函数的方法像深度Q网络等,大多是根据值函数通过ε-greedy策略来选择动作,即以ε的概率随机选择动作,以1-ε的概率选择具有最大值的动作.这类方法在离散动作空间任务中具有很好的效果,而对于连续控制任务却不是很适用[21],这是因为连续动作空间中具有最大值的动作不易确定.基于策略梯度的方法可以分为随机策略梯度[22](stochastic policy gradients, SPG)和确定性策略梯度[23](deterministic policy gradients, DPG).随机策略梯度在选择动作时输出是每个可能的动作的概率,这类方法也不太适用于连续动作空间任务.而确定性策略梯度方法在选择行动时,策略的输出是一个确定的动作,因此可以很好地应用于连续控制任务.确定性策略梯度与AC方法的结合形成了确定性AC方法[23](deterministic actor-critic, DAC),比如DDPG.这类方法虽然可以很好地适用于连续动作空间,但是其性能很大程度上取决于探索方法的好坏.它们一般通过在动作中加入外部噪声实现探索或者使用高斯策略实现探索,但这些探索方式实际上是盲目的,因此在一些连续控制任务表现不是很好.
为了提高确定性AC方法在连续控制问题上的性能,本文提出了基于经验指导的深度确定性多行动者-评论家算法(experience-guided deep deter-ministic actor-critic with multi-actor,EGDDAC-MA). EGDDAC-MA并不需要外部探索噪声源,而是从自身优秀经验中学习一个指导网络,对行动的选择和评论家网络的更新进行指导.此外为了缓解单个网络的学习压力,EGDDAC-MA使用了多个行动者网络,各个行动者网络之间互不干扰,执行情节的不同阶段.
实验上,本文首先对比基于经验的指导相比于外部探索噪声的优势,证明了多行动者机制可以有效缓解网络学习波动,然后比较了深度确定性策略梯度算法(deep deterministic policy gradient, DDPG)、置信区域策略优化算法[24](trust region policy optimization, TRPO)、对TRPO进行改进的近端策略优化算法(proximal policy optimization Algorithms, PPO)和EGDDAC-MA在多个连续任务上的性能.本文还使用了专家经验来取代自身优秀经验进行实验,发现在提供专家经验条件下,EGDDAC-MA可以快速学到一个不错的策略.
1 背景知识
1.1 强化学习和随机行动者-评论家算法
强化学习问题通常使用Markov决策过程(Markov decision process, MDP)进行建模.一个MDP问题可以用一个四元组(S,A,R,P)表示,其中S为状态集合,A为动作集合,R为奖赏函数,P为状态转移函数.在与环境E交互过程中,每个时间步agent在状态st执行动作at,获得奖赏rt+1并到达下一个状态st+1,这里st∈S,at∈A,rt=R(st,at),S⊆Rns,A⊆Rna.Agent的目标是最大化累积奖赏:
(1)
作为强化学习中的一种重要方法,随机行动者-评论家算法(stochastic actor-critic)使用随机策略梯度来更新策略,其中行动者(actor)和评论家(critic)进行了参数化处理,这里用π(a|s,θπ):S→P(A)和Q(s,a|θq)分别表示行动者(策略)和评论家(动作值函数),其中,θπ和θq是参数,P(A)表示动作空间概率分布.策略和动作值函数可以是线性的,也可以使用神经网络表示.行动者-评论家算法的目标是寻找一个最优策略使得累积奖赏最大化.
在强化学习中,无论是状态值函数还是动作值函数都满足贝尔曼方程:
Qπ(st,at)=Est~E,at~π,rt+1=R(st,at)[rt+1+
γEat+1~π[Qπ(st+1,at+1)]].
(2)
式(2)中,由于期望回报是不可知的,所以值函数在随机行动者-评论家算法中是用来做评估的,用于计算TD 误差(TD error):
δ=rt+1+γQ(st+1,at+1|θq)-Q(st,at|θq),
(3)
其中,γ是折扣因子,根据随机策略梯度理论[6](stochastic policy gradient theorem),策略π(a|s,θπ)参数更新所使用的梯度可以表示为

(4)

(5)

(6)
其中,αθq,αθπ是梯度更新的步长参数.
行动者-评论家算法的模型如图1所示:
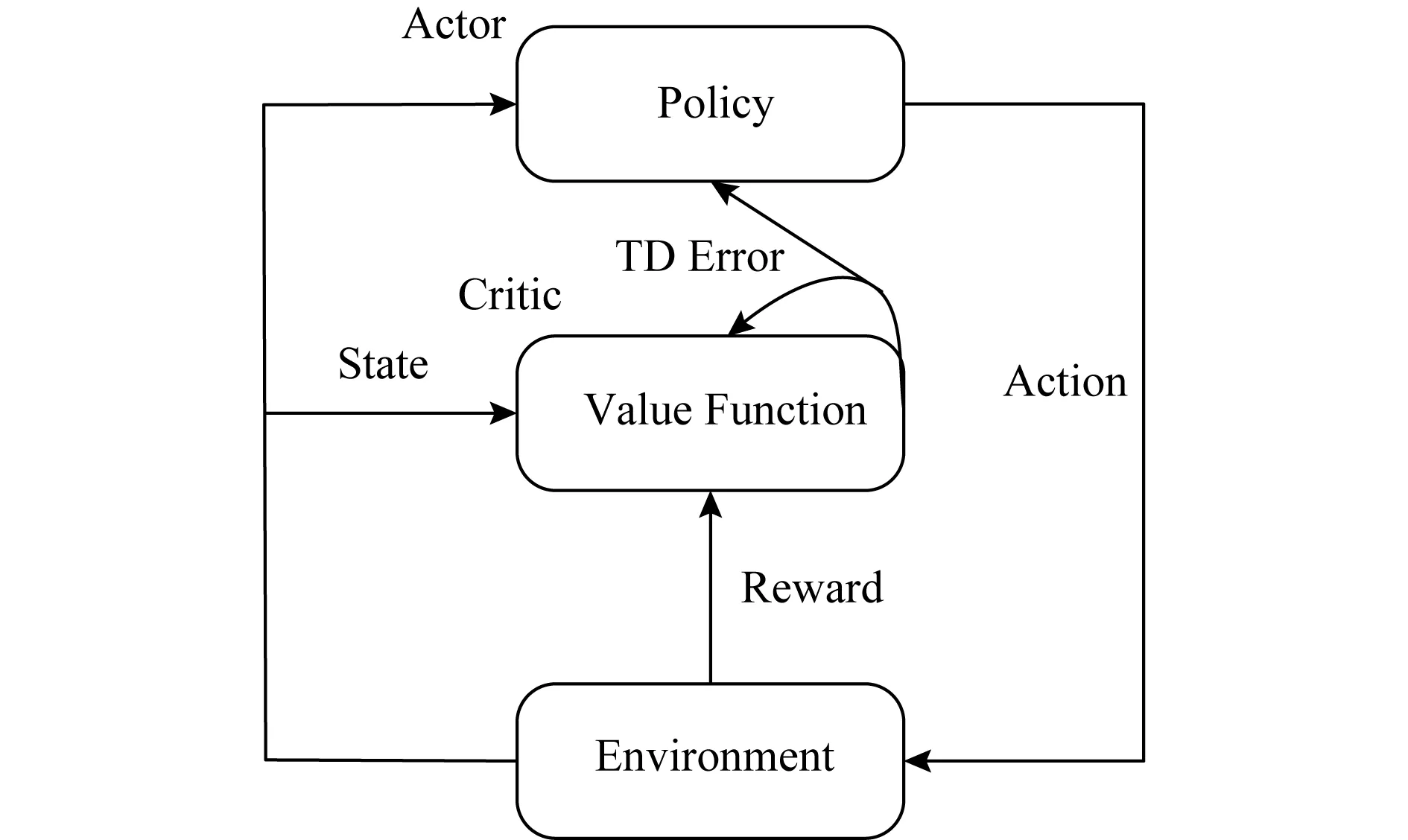
Fig. 1 The diagram of Actor-Critic framework图1 行动者-评论家算法
根据图1,算法首先初始化策略和值函数,进入循环,在每个时间步t,策略在状态st选择动作at并执行,环境给出下一个状态st+1和奖赏rt+1作为反馈,然后使用式(3)计算出TD误差,最后使用式(5)和(6)来更新策略和值函数参数,重复执行以上步骤直至收敛.
1.2 深度确定性策略梯度算法
强化学习使用深度神经网络来逼近值函数时,会表现得不稳定甚至会发散.因此同DQN中一样,深度确定性策略梯度算法(deep deterministic policy gradient, DDPG)使用了目标网络和经验重放2个机制.
深度确定性策略梯度算法是确定性策略梯度算法与行动者-评论家算法的结合.与随机策略梯度中定义的策略形式不同.在确定性行动者-评论家方法中用π(s|θπ):S→A表示行动者网络,注意S指向的是动作空间而不是动作空间的概率分布,用Q(s,a|θq)来表示评论家网络,这里θπ和θq表示网络参数.同时使用π(s|θπ′)和Q(s,a|θq′)表示目标行动者网络和目标评论家网络.
根据确定性策略梯度理论[23](deterministic policy gradient theorem),确定性策略的策略梯度可以表示为
(7)
DDPG评论家的优化目标是最小化损失函数:
L(θq)=Est~E,at=π(st|θπ),rt+1=R(st,at)
[(Q(st,at|θq)-yt)2],
(8)
其中:
yt=rt+1+γQ(st+1,π(st+1|θπ′)|θq′),
(9)
注意在yt中,动作是由目标行动者网络选择的,状态-动作对的值是由目标评论家网络评估的.
为解决探索问题,DDPG中使用的噪声是通过奥恩斯坦-乌伦贝克(Ornstein-Uhlenbeck, OU)过程[25]生成的时间相关噪声.这里使用参数φ和σ表示为
nt←-nt-1φ+N(0,σI).
(10)
最终动作为
at=π(st|θπ)+nt.
(11)
目标网络使用了“soft”的更新方式
θ′←τθ+(1-τ)θ′.
(12)
DDPG中使用的经验重放机制要求算法在每个时间步将得到的经验放入经验池.在训练时,算法从经验池中随机抽取批量经验用于训练.
2 算 法

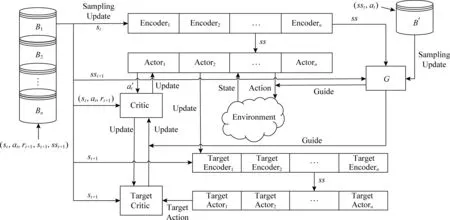
Fig. 2 An overview of EGDDAC-MA图2 EGDDAC-MA结构示意图
2.1 多行动者-评论家模型
一般来说AC方法中只会在同一个情节中使用一个行动者网络比如DDPG,或者是多个行动者网络分别并行执行不同的情节比如像A3C,又或者像MAAC[26](multi-agent actor-critic)一样通过多个agent之间合作学习.而EGDDAC-MA中定义的多个行动者网络,在情节之中不是并行的,也没有交流与合作,而是在同一个情节中针对不同阶段使用不同的行动者网络.对于学习任务,EGDDAC-MA将任务情节进行阶段划分,每个阶段配置单独的行动者网络和经验池.
某些任务在情节的不同阶段可能由于状态空间和动作空间之间的映射变化造成学习波动,对于单个行动者网络来说就会很难学习(3.4节部分进行实验说明).而多个行动者网络,它们在各自所控制的阶段学习,互不干扰,在一定程度上缓解了学习的波动.此外,单个行动者网络学习率是固定,但是对于多个行动者网络来说,其每个阶段的学习率是可以不同的.这样实际上对于每一个情节,EGDDAC-MA使用了多个策略进行控制.

模型中还有一个编码过程,这个过程是嵌入到行动者网络中的.其输入的是状态st,输出状态信号sst,对于具有较高维度的状态空间,sst的维度要比st的维度要低,sst会作为行动者网络和指导网络的输入.实际上在状态空间中,有许多状态是相似的,那么在进行动作选择时,它们的最优动作很可能是相同的.通过编码过程的降维,将状态空间映射到低维空间中,这样就可以使得相似的状态在一定程度上重合,减小了状态空间的大小.并且优秀的经验会以元组(sst,at)的形式放入经验池B′用于训练指导网络,从而加速G(ss|θg)的学习.
要注意的是,EGDDAC-MA中并没有把状态信号sst用于评论家网络,这是因为编码层的参数在不断更新,因此同一个状态在编码层中得到的状态信号会不断变化,这样就不利于评论家网络进行评估.此外,评论家网络也没有创建多个,因为评论家网络在进行网络参数更新时,使用了当前状态-动作对的值函数Q(st,at|θq)作为预测值,使用后继状态来计算目标值,然后通过反向传播进行参数更新.在预测值和目标值的计算之中不仅使用了前一个状态,还使用了后一个状态,而样本是从经验池中随机抽样的,无法判断样本中后继状态是否属于下一个阶段,这样在阶段连接处的状态,用其来进行训练时就不好计算评论家训练所需的目标值,因此模型中就没有使用多个评论家的结构.
EGDDAC-MA在学习过程中,每个时间步,首先判断该时间步属于的阶段,使用对应阶段的行动者网络来生成原始动作.更新网络参数时,只有对应的那一个行动者网络会被更新,并通过确定性策略梯度理论计算梯度:
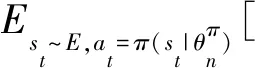
(13)
EGDDAC-MA的目标行动者网络的更新也是使用“soft”更新方式.其评论家网络的更新由于受到指导网络的影响,将在2.2节详细介绍.
2.2 基于经验的指导
连续动作空间的一个挑战是探索问题的解决.一般来说,离散动作空间问题的探索是通过改变动作的选择概率来实现的.而连续动作空间中由于动作的连续性不方便为每个动作分配相应的概率,因此通过改变选择概率来实现探索就不适用于连续动作空间.由于动作是连续变化的,因此可以通过直接改变动作来实现探索,通常是直接在动作空间中加上外部探索噪声,比如DDPG中使用的OU噪声.但是这种探索是盲目的,并不能有效地学习到优秀经验.与DDPG使用外部噪声不同,本文提出的EGDDAC-MA并不需要额外的噪声源,而是通过自身优秀经验指导学习.
在DDPG算法的学习过程中,agent会遇到一些具有高回报的轨迹,这些轨迹中包含有许多有用的信息,但是这些信息并没有被有效利用.因此,为了利用这些经验,EGDDAC-MA中定义了一个存储优秀经验的经验池B′.B′的大小是一定的,不同于普通经验池的是,其存放经验的过程是其本身的进化过程.此外基于这个经验池,定义了一个指导网络G(ss|θg).
对于普通的经验池,在每个时间步,根据该时间步所属的阶段,经验会以五元组(st,at,rt+1,st+1,sst+1)的形式放入相应的经验池中,这里的sst+1在式(19)中用于指导评论家更新.对于经验池B′,并不是在每个时间步放入经验,而是在每个情节结束时,先判断该情节是否是优秀的情节,若是,则放入B′中,否则舍去.注意放入经验时,是以情节经验[(ss0,a0),(ss1,a1),…,T]的形式放入的,T是情节结束标志.每个情节是否优秀是相对的,会随着学习进程而变化.其判断标准如下:

(14)
其中:

(15)
表示已经放入经验池B′中的最近k个优秀情节的回报均值,m表示第m个情节,Gm表示其回报.

指导网络G(ss|θg)是在B′上通过监督学习而来的,其训练所用的损失函数为
L(θg)=E[(G(sst|θg)-at)2].
(16)
指导网络G(ss|θg)在进化的经验池B′上通过监督学习学习,这样G(ss|θg)学习到的经验也是不断进化的.并且经验池B′中的经验是比普通经验池中的经验更好的,而经验网和行动网事实上都是状态到动作的映射,因此在进行动作选择时,可以使用经验网为动作加上一个指导项

(17)
其中,ξ是干扰系数,0<ξ≪1.通过式(17),指导网络会引导行动者网络向具有高回报的动作方向进行选择.
由梯度式(13)可知评论家网络也影响着行动者网络的学习.根据式(11),DDPG只在动作空间中加入探索噪声,而EGDDAC-MA中的指导网络G(ss|θg)不仅指导动作的选择而且还对评论家网络的更新进行指导.评论家网络更新所使用的标签值式(9)的改写为

(18)
qt+1=qt+1+ξ(Q(st+1,
G(sst+1|θg)|θq′)-qt+1),
(19)
yt=rt+1+γqt+1φ,
(20)
其中,φ是情节是否结束的标志,若情节结束则其值为0,否则为1.最终评论家网络更新所使用的损失函数表示为

(21)
每次在进行动作选择时,指导网络G(ss|θg)通过式(17)指导动作的选择,并且通过式(19)指导评论家网络的学习.由于经验池B′中的经验集合是普通经验池中经验集合的子集,所以当行动者网络收敛时,指导网络也就自然收敛了.此时,式(17)和式(19)中的指导也就不存在了.可以看出EGDDAC-MA与DDPG一样都属于异策略(off-policy)学习,即学习的策略和执行的策略是不一样的.整个算法的过程如算法1所示.
算法1.EGDDAC-MA.

② FOREPISODE=1,2,…,M
③ 情节回报G=0,空的情节轨迹Trace,获取初始状态s1;
④ FORt=1,2,…,T
⑤ 判断情节所属阶段n;
⑦ 加入指导:at=at+ξ(G(sst|θg)-at);
⑧ 执行动作at并获取奖赏rt+1和后继状态st+1;
⑨ 累积回报:G=G+rt+1;
⑩ 通过行动者网络中的编码层对st+1进行处理,得到sst+1;
更新评论家网络参数;
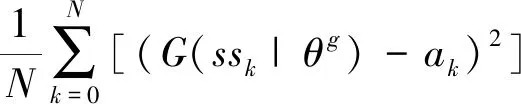
3 实 验
3.1 实验平台及实验介绍
本文采用了OpenAI GYM平台[27]上Mujoco物理模拟器[28]中的6个连续性控制任务作为实验环境.GYM是开发和对比强化学习的一个开源工具包,其提供了各种连续控制性任务的环境接口,旨在促进机器人、生物力学、图形和动画以及其他需要快速精确仿真的领域的研究和开发,为人工智能研究者提供了丰富的模拟实验环境.此外,为了进一步说明算法的适用性,本文还额外增加了2个PyBullet连续任务.PyBullet强化学习环境也是基于GYM平台的,使用的是Bullet物理模拟器.整体来说PyBullet强化学习环境要比Mujoco环境更难.
本文使用的6个Mujoco连续任务包括:
1) Ant.使3D四足蚂蚁形态机器人学会快速向前行走,如图3所示;
2) HumanoidStandup.使3D人形态机器人学会快速站立;
3) Humanoid.使3D人形态机器人学会行走;
4) HalfCheetah.使2D-猎豹形态机器人学会快速奔跑;
5) InvertedDoublePendulum.平衡具有2个关节的平衡杆;
6) Reacher.使2D手臂形态机器人伸向指定位置.

Fig. 3 Ant图3 四足蚂蚁形态机器人
使用的2个PyBullet连续任务包括:
1) AntBullet.是类似于Mujoco中Ant的连续任务,只是加重了Ant的重量,来鼓励其行走过程中以更多条腿接触地面;
2) Walker2DBullet.任务是使双足机器人学会行走,产生更加逼真的慢节奏动作,如图4所示:

Fig. 4 Walker2DBullet图4 Bullet中的2D行走任务
本文首先说明优秀经验筛选方法的效果,以及基于经验的指导机制和多行动者机制的效果,然后对比了EGDDAC-MA,DDPG,TRPO和PPO这4种算法的性能,最后研究使用专家经验取代自身优秀经验对EGDDAC-MA的影响.本文实验使用Intel®Xeon®CPU E5-2680处理器,使用NVIDIA Tesla P40图形处理器对深度学习运算进行辅助加速计算.
3.2 参数设置
本文实验中所使用的DDPG算法其网络结构和参数设置与参考文献中设置一样,TRPO和PPO算法来自是OpenAI baselines[29]的深度强化学习算法集.在EGDDAC-MA中,其使用的评论家网络与DDPG算法中的评论家网络设置一样.EGDDAC-MA的每一个编码层包含2层,第1层有300个神经网络节点,第2层有100个网络节点.每个行动者网络包含2层,第1层有200个神经网络节点,第2层有100个神经网络节点.EGDDAC-MA的指导网络也包含2层,第1层200个神经网络节点,第2层有100个神经网络节点.EGDDAC-MA的每一个普通经验池容量是300 000,而经验池B′的容量是100 000,是普通经验池1/3.干扰系数ξ=1×10-5,mini-bach的大小是64,τ=0.001,学习率γ=0.99,k=50.评论家网络的学习率是1×10-3,指导网络的学习率是0.000 2,行动者网络的学习率是1×10-5.每个Mujoco环境下每个算法训练的总时间步数是250万步,除了Reacher中是100万步,这是因为Reacher在100万步内可以学习到一个稳定的策略.此外,2个PyBullet环境下每个算法训练的总时间步数是400万步.由于实验中使用了多个不同环境,为了统一参数,EGDDAC-MA都是以60个时间步作为一个阶段来设置的.每个情节的最长时间步设置为1 000.
3.3 优秀经验筛选方法的效果
为了说明通过式(14)和式(15)的筛选,经验池B′中的经验在变好,这里通过均值μ=1,方差σ2分别为0.1,1,5,10,20的正态分布来做一个模拟实验.实验中会定义一个经验池B′,每个情节只是正态分布生成的一个随机变量,然后使用这个随机变量作为该情节的回报,同时情节经验也用这个随机变量表示,在B′存放经验时,就使用式(14)和式(15)来判断情节是否优秀,若优秀则将该情节经验也就是对应的随机变量(也表示情节回报)放入B′.模拟中k取的10,经验池容量为100,情节总数为100 000,模拟结果如图5所示.第1幅图显示的是放入经验池中的最近k个情节的平均回报随时间步数的变化.第2幅图显示的是放入经验池中的所有情节的平均回报随时间步数的变化.从图5可以看出,虽然均值是1,但是通过使用式(14)和式(15)对优秀经验进行判定,无论方差多大,最近k个情节的均值,和整个经验池的均值都是向着大于1的方向进化的,这说明经验池中的经验整体上在变得越来越好.

Fig. 5 The results of normal distribution simulating episodic return 图5 正态分布模拟情节回报值的结果
3.4 基于经验的指导和多行动者机制的优势
为了说明基于经验的指导和多行动者机制的优势,本文在InvertedDoublePendulum任务上对比了EGDDAC-MA,EGDDAC-One actor和DDPG的性能.首先为了说明基于经验指导的方法优于外部噪声探索,这里对比只使用一个行动者网络的EGDDAC-One actor和使用外部OU噪声探索的DDPG.对比结果如图6所示,图6中横坐标为训练时间步,纵坐标为平均回报.

Fig. 6 The average return in InvertedDoublePendulum图6 在Inverte-dDoublePendulum中的平均回报对比
可以看见DDPG在整个训练过程中,平均回报处于较低值,而且没有上升趋势,这说明基于外部OU噪声的探索,并没有探索到好的经验供agent学习.但EGDDAC-One actor可以获得更高的平均回报,即使整个训练过程中波动很大.这是因为基于经验的指导机制可以引导agent倾向选择具有高回报轨迹,而外部的OU噪声探索是没有方向性的盲目探索.
为了缓解图6中出现的波动,我们在基于经验的指导的基础上加上多行动者机制,如图6所示.这里对比EGDDAC-MA和EGDDAC-One actor 在InvertedDoublePendulum中的学习表现.可以看出EGDDAC-MA没有出现像EGDDAC-One actor中的剧烈波动,而是在一定程度波动内稳步上升.这说明多行动者机制可以缓解单个网络学习压力.而且可以看到经过200万步后网络学习的波动被控制在一定范围之内.

3.5 对比不同算法的性能
本文在Mujoco的6个连续任务和PyBullet 的2个连续任务中对比了EGDDAC-MA,DDPG,TRPO和PPO这4种算法的性能.其中TRPO和PPO也都是基于AC方法的改进,与DDPG和EGDDAC-MA不同的是,TRPO和PPO两者都使用高斯策略实现探索,并且没有使用经验回放,而是在线进行更新.实验结果如图7所示.
在Ant环境中,DDPG整体上呈现先上升后下降的学习趋势.TRPO和PPO的平均回报虽然随着学习的进行会有增长趋势,但是两者最终的平均回报值都维持在一个较低值.而EGDDAC-MA 的表现比其他3种算法都好,最终平均回报值维持在4 000左右.此外在HalfCheetah,HumanoidStandup和Reacher中,EGDDAC-MA也是明显优于其他方法.这是因为DDPG以及TRPO和PPO算法的探索是盲目的,而基于优秀经验的指导机制,会引导agent去选择具有高回报的轨迹,因此EGDDAC-MA会表现的更好.在Humanoid中,EGDDAC-MA前期表现不如TRPO和PPO,可能是因为TRPO和PPO这类方法直接是在线学习的不需要经验累积,而EGDDAC-MA的经验池B′中的优秀经验需要经历一定的时间步去收集,这个问题在Inverted-DoublePendulum中也可以看到.但是EGDDAC-MA最终在Humanoid和 InvertedDoubleP-endulum两个环境中都超过TRPO和PPO.
从图7的实验结果可以看出:EGDDAC-MA的性能很大程度上取决于经验池B′中经验的优秀程度,因此下一个实验我们将展现使用专家经验取代自身优秀经验后,EGDDAC-MA的学习效果.

Fig. 7 The average returns of four approaches in eight continues control tasks图7 4种方法在8个不同连续任务中的平均回报
3.6 使用专家经验的EGDDAC-MA
相比基于自身优秀经验的EGDDAC-MA,基于专家经验的EGDDAC-MA其指导网络的输入不再是状态信号而是状态,而且B′中直接装入的是预先训练得到的专家经验.
整个实验是在InvertedDoublePendulum环境中进行的,探索了不同干扰因子下,基于专家经验的EGDDAC-MA的学习效果.实验结果如图8所示,图8中的前5幅图片,分别是在ξ=0.9,0.7,0.5,0.3,0.1下,基于专家经验的EGDDAC-MA的行动者网络的学习表现.要注意的是,为了体现行动者网络的学习效果,图8中的每一个绿点都表示没有指导网络的指导时,只使用行动者网络来生成的情节回报.也就是在1 000 000时间步的训练过程中,每隔500时间步就会单独使用行动者网络来生成一个情节,因此每一个ξ下,都有2 000个绿点.图8中红线表示专家水平.图8中最后一幅图片对比训练过程中不同ξ下的只使用行动者网络生成的平均情节回报随时间步数的变化.
从图8可以看出,在ξ=0.9时,行动者网络的情节回报虽然有向上趋势,但是最终基本上维持在一个较低值.在ξ=0.7时,情节回报的向上趋势更加明显,但大部分回报值都很低.在ξ=0.5时,可以看见200 000时间步后,行动者网络很快学到一个不错策略,情节回报值基本上达到专家水平,只有少数情节回报值较低.在ξ为0.1和0.3时,随着ξ值的降低,情节回报值上升趋势会下降,而且大多数情节回报值在专家水平之下.

Fig. 8 The effect of using expert experiences图8 使用专家经验的效果
整体上来看,在ξ=0.5时,在基于专家经验的指导下,行动者网络可以快速学习到一个不错的策略,而在ξ高于0.5或低于0.5时,行动者网络学习的并不好.出现这种现象的原因是,若ξ值过高,高于0.5,此时行动的选择,主要取决于指导网络,而行动者网络对行动决策贡献较小,这样得到的经验是不利于行动者网络学习的.若ξ值过低,低于0.5,此时行动的选择,主要取决于行动者网络自身,指导网络对行动决策贡献较小,而行动者网络学习的方向并不一定是专家策略的方向,这样行动者网络的决策与指导网络的决策就可能出现冲突,而且指导网络同样会影响评论家网络的学习,因此也不利于行动者网络学习.只有ξ=0.5时,行动的决策受行动者网络和指导网络均等程度上的控制,评论家的学习也是这样,从而行动者网络可以快速的学习一个不错的策略.与基于专家经验的EGDDAC-MA在ξ=0.5时表现最好不同,基于自身优秀经验的EGDDAC-MA的ξ一定要是一个较小的值.这是因为指导网络所使用的经验是自身优秀经验,是行动者网络学习所使用的自身经验的子集,从而指导网络和行动者网络学习的策略的方向是一致的.因此,在选择动作和更新评论家网络时,指导网络只需要做一个微弱的指导就可以.
4 结束语
连续控制问题一直是强化学习研究的一个重要方向.确定性策略梯度方法和深度学习结合可以在一定程度上解决这类问题.但是这类方法在一些连续任务中的表现并不是很好,这很大程度上是由于探索不当造成的.本文提出了一种不需要外部探索噪声的基于经验指导的深度确定性多行动者-评论家算法(EGDDAC-MA).
EGDDAC-MA中通过定义多个行动者网络来应对情节的不同阶段,这样可以缓解情节内部波动对单个网络学习造成的压力,并通过在自身优秀经验上学习得来的指导网络为动作执行以及评论家网络更新提供指导.此外本文不仅使用自身优秀经验来训练指导网络,也尝试了使用专家经验来训练,并且发现使用专家经验,在ξ=0.5时EGDDAC-MA可以更快的学到一个不错的策略.最终,Mujoco上的模拟实验结果显示:相比于DDPG,TRPO和PPO,EGDDAC-MA在大多数连续控制任务上均取得更好的效果.
实际上,本文采用的是简单的阶段划分方法,也取得了不错的效果,未来的一些工作可以使用无监督方法来对情节进行自适应的阶段划分来提高阶段划分的有效性.
猜你喜欢
贵州社会科学(2022年8期)2022-10-12 05:36:00
中国音乐(2022年3期)2022-06-10 06:28:36
数学物理学报(2021年6期)2021-12-21 06:24:38
鸭绿江(2021年29期)2021-02-28 05:44:26
鸭绿江(2020年29期)2020-11-15 07:05:52
应用数学(2020年2期)2020-06-24 06:02:50
火花(2019年8期)2019-08-28 08:45:06
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52
绿色中国(2016年1期)2016-06-05 09:02:59
新闻传播(2015年3期)2015-07-12 12:22:28
