
基于FCN模型和选择性搜索的目标检测方法
2019-07-22 01:17:00林菁,杨楠,臧勤
雷达与对抗 2019年2期
林 菁,杨 楠,臧 勤
(1.海军装备部,北京 100841;2.中国船舶重工集团公司第七二四研究所,南京 211153)
0 引 言
目标识别算法是辅助驾驶和无人驾驶技术[1-2]中一个非常重要的研究方向。准确的获得交通目标位置信息能够让司机或者无人汽车对交通状况做出准确的判断,从而避免交通事故的发生。虽然学术界和工业界在过去的几十年里通过计算机视觉对检测算法研究已经取得了较大进展,但是目前的检测算法仍存在如下两个不可避免的问题,一个是由于噪声、运动模糊等因素造成的图像低分辨率,另一个是由于复杂的天气的条件如雾霾、可变光照、雨水天气等造成的干扰。
为了解决上述问题,一些专家学者提出了一系列的方法,如基于颜色与阴影模型[3]的方法、基于形状模型[4]的方法、基于滑动窗口[5]的方法、基于选择性搜索的方法[6]等。
基于颜色与阴影模型的方法引入了颜色变换和阴影检测方法[7],通过车辆颜色和车辆阴影模型对前方车辆的位置进行定位。但是,基于颜色或者阴影模型的方法容易受到天气情况的影响,在强光照、阴雨等天气情况下该检测方法的识别率较低。基于形状的方法,如文献[8]提出的基于边缘对称性的视频车辆检测算法,通过车辆边缘对称信息对前车位置进行匹配。然而,基于形状的检测方法容易受到运动形变、障碍物遮挡等问题的影响,在交通环境比较复杂的情况下检测性能并不理想。为了解决上述问题,一些研究人员提出了滑动窗口结合分类器的检测方法,利用多尺度滑动窗口提取大量的候选区域后通过分类器进行筛选从而对前方车辆位置进行定位。虽然上述方法可以有效地解决基于颜色和基于形状的方法因为环境干扰带来的误检和漏检,但是由于提取的候选区域较多,算法实际运算时间较长,在实际应用中效果并不理想。为了解决滑动窗口提取候选区域数量较大和提取候选区域存在大量冗余等问题,J.R.R. Uijlings等人[9]提出了基于选择性搜索的目标检测方法。该方法首先对图片进行超像素分割,通过合并超像素的方法选择性地提取候选区域,在一定程度上减少了候选区域的提取。
随着深度学习算法在目标的检测与分类中取得的良好表现,Girshick R等人[10]结合卷积神经网络分类模型改进了J.R.R. Uijlings等人方法提出了R-CNN目标检测方法。该方法通过结合选择性搜索算法与深度卷积神经网络分类模型提高了检测算法的检测精度。但是,该算法需要对非目标区域提取大量的候选区域并判决,所以该方法存在着检测速率慢、在复杂交通环境下精确率较低等问题。
Longjong等人在CVPR2015上提出了一种基于全卷积神经网络图像语义分割算法[11]。该算法通过训练能够进行像素级的分类从而高效地解决语义级别的图像定位问题。该方法能够快速地对交通场景进行初始语义分割从而得到前方车辆大致所在位置,但在经过卷积网络和反卷积网络过程中会丢失部分信息,所以对于复杂环境下的前方车辆检测效果并不理想。基于此,本文进一步提出了基于全卷积神经网络和选择性搜索的前车检测算法。该算法将全卷积神经网络语义分割算法与J.R.R.Uijlings等人提出的R-CNN算法相结合并应用于前车识别上。通过在LISA交通数据库[12]中进行试验对比,实验结果显示,与Girshick R等人提出R-CNN目标检测算法相比,本文所提出的算法的平均准确率、召回率和准确率均有提高。
1 算法结构
本文提出的前车检测方法分为候选区域提取、候选区域识别两个部分。算法结构如图1所示。算法第1部分首先通过训练好的全卷积神经网络模型对输入图像进行语义分割得到目标区域粗略位置,接着通过选择性搜索算法对分割后的粗定位图像提取候选区域。算法第2部分先将第1部分提取的候选区域放入训练好的神经网络分类器进行分类得到每个候选区域的置信度,然后通过非极大值抑制算法[13]去除冗余候选区域得到最优候选区域,即前方车辆所在位置。
2 候选区域提取
2.1 图像语义分割
由于全卷积神经网络在图像语义分割上具有良好表现,所以文本采用全卷积神经网络(fully convolutional neural network)对输入图像进行语义分割从而实现目标的粗定位。全卷积神经网络和卷积神经网络都是含有多隐层的神经网络模型。相对于经典的CNN网络在卷积层之后使用全连接层得到固定长度的特征向量进行分类,全卷积神经网络采用反卷积网络对最后一个卷积层的特征图进行上采样, 使原始图像恢复到输入图像相同的尺寸,从而能够对每个像素都产生了一个预测值,同时也保留了原始输入图像中的空间信息。
图2显示了本文选用的全卷积神经网络的详细配置。本文将整个网络分为卷积网络和反卷积网络。卷积网络用于将输入图像转换为多维特征,而反卷积网络用于从提取的多维特征生成分割图像。网络的最终输出为与输入图像大小相同的显示每个像素属于预定义类之一的概率的概率图。
本文采用去除softmax层的VGG16层网络[14]用于卷积网络部分。卷积网络有13层卷积层。卷积层与卷积层直接采用整形和池化操作用于降低卷积层输出的特征向量。卷积网络末端连接2个全连接层用于增强特定类的投影。反卷积网络采用的是卷积网路的镜像模型。与卷积网络相比,反卷积网络具有多个上池化层、反卷积层。
2.1.1 卷积网络
(1) 卷积层

(1)
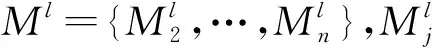
(2) 激活函数
卷积的结果经过激活函数后的输出形成这一层的特征图。每一个输出的特征图可能与前一层的几个特征图的卷积建立关系。本文采用Relu函数如公式(2)所示。
(2)
(3) 下池化(pooling)层
(3)
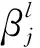
2.1.2 反卷积网络
(1) 上池化(Unpooling)层
由于池化操作不可逆,所以上池化操作是一种近似操作。本文通过将池化操作前的位置信息反向重新显示实现图像的上池化操作,从而达到还原图像的目的。
(2) 反卷积层
在对上池化操作后需要对特征图进行反卷积操作从而实现对图像不同层次特征的提取。反卷积操作通过多个可训练的卷积核进行卷积运算从而得到一个放大的稀疏响应特征图。
选取LISA数据库中3种不同交通环境下的测试图片作为输入,图像语义分割后的输出结果如图3所示。
2.2 选择性搜索法提取候选区域
2.2.1 选择性搜索算法流程
对初始输入图片进行语义分割以后,能够得到前方车辆大致的所在位置。为了对前车所在位置进行更精确的定位,需要对初始分割图片进行候选区域提取。本文采用选择性搜索算法对图像进行候选区域提取,使算法能够适应不同尺度的图像,并且减少提取候选区域的量。选择性搜索算法通过计算目标区域的相邻联通子区域的相似度,不断合并图像子块并提取子块外接矩的方式选取候选区域。本文在进行选择性搜索作相似性判断时采用多策略融合的方法进行合并。根据实际需求本文使用图像分割后子块的颜色、纹理、大小的相似度进行合并。选择性搜索算法提取候选区域流程如下所示:
(a) 对语义分割图像(图4(a)列所示)进行超像素分割得到超像素分割图(如图4(b)列所示);
(b) 将得到的超像素分割图分为若干初始图像子块,设子块集合为R={r1,r2,…,rn},对区域集合R中的子集取其对应的外接矩作为候选区域;
(c) 计算临近图像块区域之间的相似度s(rm,rn),所有图像块之间的相似度集合为S={s(rj,rk),…};
(d) 将集合S中相似度最大值max(S)对应的两个区域(rj,rk)合并为一个新的区域rnew=rj∪rk,从集合中去除区域rj和rk,并且在相似度集合中去除与其他区域的相似度。
(e)重复步骤(c)和步骤(d)直到相似度集合S为空集,得到全部候选区域(如图4(c)列所示)。
2.2.2 子块合并策略
本文根据实际需求采用基于颜色、大小和纹理特征融合的相似度融合策略对相邻的子块进行融合判别。
(1) 颜色相似度

(4)
(2) 纹理相似度

(5)
在区域合并过程中对新的区域的SHIFT-LIKE特征直方图进行更新,计算方法如下:
(6)
(3) 大小相似度
本文采用区域中包含像素点的个数进行判别,计算方法如下:
(7)
其中,size(im)为整个输入图片的总像素点数。
将纹理特征、颜色特征、大小特征相似度计算方式组合到一起,得到相似度量公式:
s(ri,rj)=a1scolour(ri,rj)+a2stexture(ri,rj)+a3ssize(ri,rj)
(8)
3 候选区域识别
3.1 候选区域分类
在提取候选区域以后,需要通过分类器对提取的候选区域进行分类从而去除非车辆位置区域。相比于传统的基于人工特征因子(如BP、HOG、LBP等)加分类器(如SVM、adoost等)的分类方法,基于深度卷积神经网络(CNN)分类算法具有较好的鲁棒性与准确率,并且可以得到每幅候选区域图像的置信度。因此,本文采用深度卷积神经网络模型对提取的候选区域图像进行分类。
本文的深度卷积神经网络框架中采用7层网络(如图5所示)将提取的候选区域分为车辆和背景2种类别。首先将提取的候选区域尺度归一化为32×32大小的图像,然后经过2层卷积层加2层池化层、2层全连接层和softmax层输出图片所属类别的概率。本文从KITTI数据库[15]中选取1 000张图片,选取标注好的2 341张车辆区域作为正样本集,截取选取图片中不同尺度下的背景区域作为非车辆样本,最终构建的非车辆样本集共有6 400张图片。

表1 深度卷积神经网络参数表
3.2 最优候选区域提取
当提取选取的候选区域经过卷积极神经网络分类器会得到每个候选区域属于车或者背景的置信度,保留候选区域属于车辆且大于0.8的所有候选区域。根据非极大值抑制法求得最优候选区域,即最优候选区域为前方车辆的精确位置。
非极大值抑制法提取最优候选区域过程如下所示:
(1) 选取单帧图片中所有的候选区域{s1,s2,…,sn},假设最大概率候选框为smax,分别计算{s2,…,sn}与s1的重叠度(IOU)是否大于0.5。假设候选框的重叠度超过0.5的区域有si和sj,去除si和sj,并标记第1个候选框smax。
(2) 从剩下的候选框中{s2,si-1,si+1,…,sj-1,sj+1…,sn},选取概率最大候选框ssecond,重复步骤1并标记ssecond。
(3) 重复步骤2,直到候选区域集合为空,从而得到单帧图片中所有最优候选区域。
4 实验结果分析
为了验证本文算法,本文采用LISA交通数据库作为测试数据。LISA车辆检测数据库包含白天不同光照条件、不同道路环境(城市、高速公路)的车辆行驶。该数据集能够较好地对前车检测算法进行评价。本文算法在基于Linux下的caffe框架[16]实现,硬件平台为英特尔至强E5、TIANX 显卡、内存12 GB的计算机上运行。部分检测结果如图5所示。
本文采用以下评价指标对不同算法在前车检测中的效果进行评价:精确率(即车辆识别率)tp、召回率(即虚警率)fp,其定义公式如下所示:
(9)
其中,NTP、NFP、NTN和NFN分别表示测试样本中正确检测到的前车数目、将车辆误差误识别为车辆的个数、正确识别的非车辆数目和将车辆误识别为非车辆的个数。
本文将文献[10]所提出的R-CNN算法与与所提出的改进算法在LISA数据集3种不同环境下的准确率和召回率进行了比较,见表2、表3。

表2 算法准确率与召回率对比

表3 算法检测速率对比
根据实验结果,本文所提出的改进算法与R-CNN算法相比在3种不同的道路和天气环境下的交通场景下的准确率与召回率均有所提高。相比于R-CNN算法,本文算法的准确率提高了5.9%,召回率提高了7.1%,单张识别时间减少了0.51秒/张。
5 结束语
本文提出了一种基于全卷积神经网络和选择性搜索算法的前车检测方法。针对R-CNN算法提取精确率低、召回率低、检测速率慢等问题,本文引入了全卷积神经网络语义分割的粗定位的方法对其进行改进。相比于原有的R-CNN算法,本文算法在复杂交通环境下(如运动模糊、复杂的天气)的前方车辆检测具有更好的准确率、召回率和检测速率。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年19期)2019-11-23 08:42:00
第一财经(2019年8期)2019-08-26 17:53:46
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
哈尔滨医药(2015年2期)2015-12-01 03:57:13
学习月刊(2015年14期)2015-07-09 03:37:48
物理化学学报(2015年5期)2015-02-28 17:34:47
