
江苏大学图书推荐系统让学生借书“不迷路”
2019-07-19 09:35:32吴云龙
中国教育网络 2019年6期
文/吴云龙
高校图书馆图书推荐现状
随着社会的发展,国内高校之间百舸争流,图书馆作为高校的文化载体,也发生了巨大的变化,主要体现在馆藏量和服务方式上。在如今这个信息爆炸的时代,高校图书馆作为学生获取知识的主要来源,自然图书藏量也飞速递增,甚至出现了信息过载的情况[1]。对于学生来说,可以在如此多的图书中获取多方面的知识,本身是一件令人兴奋的事。但如何寻找感兴趣或者想要的书籍,对于学生和图书馆来说,都是一个亟需解决的问题。
传统的高校图书馆系统提供基于图书信息检索的方式,学生根据想要寻找的图书名或者作者姓名等信息进行检索,从大量的图书中找到对应的书籍。这种方式,针对明确知道图书信息的学生来说,尚能够解决问题,但更常见的情况是学生面对如此大量的书籍,不知道哪本书适合自己目前的阶段,不知道什么书能提高自己的成绩。那如何将图书馆中的书籍推荐给适合它的学生,或者为学生找到有助他的书籍成为了图书馆书目推荐的本质目的。
目前在高校图书馆中较流行的图书推荐大致分为两种。一种是基于图书相似度的推荐,根据图书的借阅历史记录,为学生推荐其感兴趣的相似的图书;第二种是根据学生基本信息和行为,挖掘出具有相同特征信息的学生,从而推荐互相的感兴趣的书目。
系统需求分析
目前图书推荐存在的问题
当前高校常见的图书推荐,很大程度上与电子商务领域的推荐系统类似,这种模式的推荐不一定适合高校这样的特殊环境,继而推荐效果上可能大打折扣;其次因为数据源较多、推荐算法复杂和数据量庞大等问题,在推荐系统的可行性上也存在疑问。比如基于图书相似度的推荐,由于高校图书馆藏书量大,并且每年会采购新的书籍,在计算图书相似度上会建立一个庞大的矩阵,导致推荐成本变大;另外将相似的图书推荐给学生,也不一定是学生满意的书目。再比如基于学生行为的推荐,传统的基于行为的推荐是分析学生的日常生活轨迹数据,得到兴趣爱好相同的学生,从而进行图书的推荐。学生的行为数据源多且数据量大,增大了数据分析的难度;而且兴趣爱好相同的学生在课程和学业上所需要的书籍也不一定是相同的。
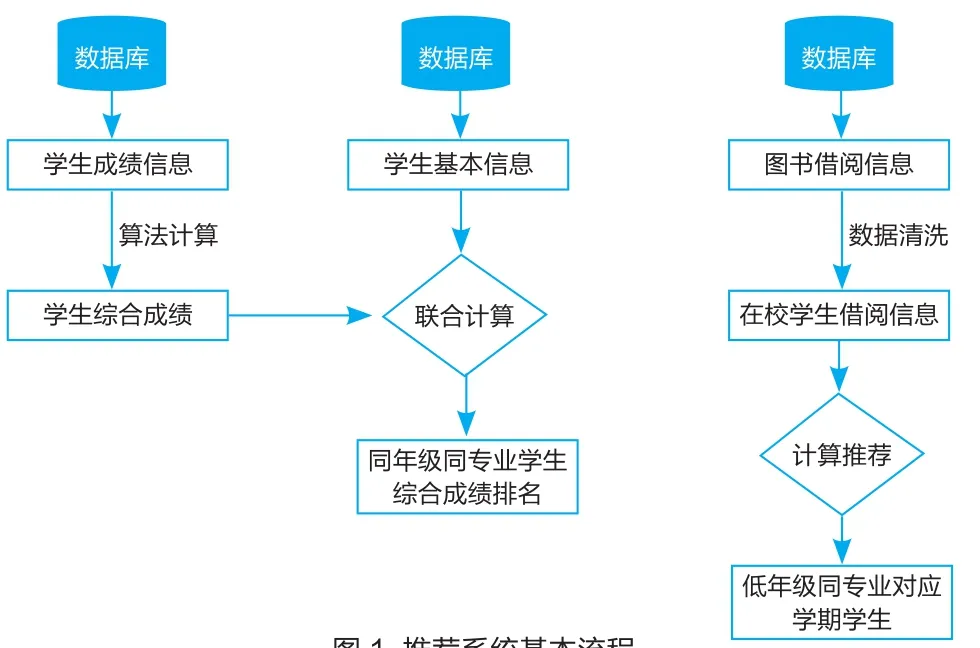
图1 推荐系统基本流程
推荐系统架构
本系统结合高校的特点和学生的需求,并结合学生成绩数据、学生基本信息数据和图书馆借阅数据,利用分布式文件系统HDFS和大数据计算引擎Spark进行计算,将专业综合成绩优秀学生的借阅书目,推荐给相同专业低年级同时期的学生。本推荐系统的基本业务流程如图1所示。
整个系统的流程主要由三块构成,第一是从数据库中获取某学期的学生成绩信息,清洗后用自定义的算法计算出每个学生当前学期的综合成绩;第二是从数据库中抽取学生的基本信息,然后联合第一步中的成绩数据,计算出同年级同专业学生的综合成绩排名情况;第三从数据库中清洗出在校学生的图书借阅历史数据,联合第二步中的成绩排名数据,将当前学期优秀学生的借阅图书,推荐给低年级同专业的学生。
推荐方法过程
计算工具介绍
本文提出的图书推荐方法涉及到多个数据源,特别是学生成绩数据和图书借阅历史数据,随着高校的不断发展和图书馆规模的不断扩大,这两项数据量也越来越大。特别是处理过程中还涉及到多次多种数据源之间的联接操作,传统的数据计算框架会遇到一定的挑战。
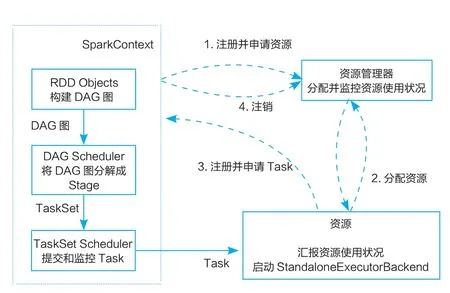
图2 Spark运行流程
Hadoop的Mapreduce是一种并行处理大数据的计算框架,它的核心思想是采用分而治之的策略,其中Map将要处理的任务分成很多子任务,交给各个不同的进程进行计算;最后的计算结果由Reduce进行统计[2]。但是因为Mapreduce的计算过程中采用的是多进程模型,这样会导致在反复迭代计算的任务中花费太多时间在启动进程上,同样在执行中需要内存和磁盘不断进行数据交互,也很大程度上影响计算性能。
Spark诞生于伯克利大学的AMPLab,起初是该大学的一个研究项目,后被正式开源并成为Apache的顶级项目[3]。Spark与Mapreduce相同,也是作为近年常用的大数据计算框架;不同的是Spark采用分布式内存计算和弹性分布式数据集RDD[4](如图2所示),将计算中需要重复使用的数据缓存在内存中,使大规模数据的处理速度和容错率相较Mapreduce提升了很多。
学生综合成绩计算
数据库中存放的学生成绩信息包含有14个字段,包括XH(学号),XM(姓名),XN(学年),XQ(学期),KCDM(课程代码),KCMC(课程名称),KCXZ(课程性质),KCGS(课程概述),XF(学分),CJ(成绩),BKCJ(补考成绩),CXCJ(重修成绩),BZ(备注),CXBJ(重修标记)。从成绩字段信息可以发现,计算学生一学期的综合成绩,将会面临以下问题:学生的成绩因为课程性质分为必修课和选修课,不同课程性质的要求可能不一样;有些课程的成绩是等级制,很难做到量化;不同课程可能对应不同的学分;有些学生的课程可能存在补考或者重修现象,那同一门课程可能有两个分数等等。
针对以上问题,首先将课程成绩和等级成绩量化成具体分数,具体量化方式为:优秀=90,良好=80,中等=70,及格=60,不及格=40;然后根据不同课程性质划分权重(必修课权重为1.0;选修课权重为0.8),结合学分计算每门课程的最终成绩。计算方法为:
最终成绩 = 课程权重 ×学分 × 原始成绩
计算得到每个学生每门课程的最终成绩,接下来根据学号和课程代码为键,找到有多个成绩的课程即补考或重修的课程,取最大分数为当前学生该课程分数。最后以学号为键,调用groupByKey后将该学生所有成绩进行求和计算,则得到了该学生在当前学期的综合成绩。
同专业学生成绩排名
通过对教务成绩数据计算得到学生一学期的综合成绩,接下来将结合学生基本信息数据,得到同专业学生综合成绩排名。学生的基本信息存在bzks表中,该表有69个字段,截取其中以下字段:XM(姓名),XBDM(性别代码),YXDM(院系代码),XZNJ(现在年级),XZZYDM(现在专业代码)。学生基本信息数据和成绩数据进行join操作,然后以现在年级和现在专业代码作为联合键,将同级同专业的学生数据聚集后,利用spark对相同键的学生成绩进行降序排序。
优秀学生借阅推荐
图书借阅信息中包含了全部的借阅信息,数据量较大,首先需要过滤掉已经毕业学生和非学生的借阅信息。然后结合上述已经计算得到的同级同专业学生一学期综合成绩排名数据,选取排名靠前的优秀学生(可配置,本文选取各个专业成绩排名前15),得到这些优秀学生在当前学期的图书借阅信息。接下来对这些优秀学生的图书借阅信息进行分析,统计借阅次数降序排序和借阅时长降序排序。最后选取借阅次数超过两次的书籍,如果该数量超过15,则选前15的书目;如果该数量未超过,则按借阅时长排名自前往后筛选补充至15本。最后我们将这15本书目做为往届优秀学生的借阅书目,推荐给对应低一级同专业且对应学期的学生。
综上所述,本文结合高校学生的基本数据、教务数据和图书借阅历史数据,分析得到每个专业综合成绩优异学生借阅的书籍;再将这些书籍经过一定的分析统计后推荐给对应借阅学期和同专业的低年级学生。这样的图书推荐方式不同于目前主流的应用于电子商务领域的推荐,更加符合高校学生的需求,推荐的指向性和目的性也更加明确[5]。但是也存在一定的缺点,比如可能会因为优秀学生借阅的局限性而错过一些优秀书籍;也可能因为优秀学生借阅的一些兴趣类的书籍而因此做了低质量的推荐。当然基于高校图书馆的图书推荐因为面向群体的针对性,将会是一个长期值得研究和优化的课题,希望能通过本文为此提供一定的参考价值。
猜你喜欢
公民与法治(2022年10期)2022-10-12 07:46:48
少先队活动(2021年9期)2021-11-05 07:31:12
中学生数理化(高中版.高二数学)(2021年2期)2021-03-19 08:54:10
南风(2020年22期)2020-09-15 07:47:08
小学生优秀作文(低年级)(2019年5期)2019-04-25 13:13:40
经济技术协作信息(2018年28期)2018-11-22 05:26:22
新产经(2018年6期)2018-07-04 00:39:24
小学阅读指南·低年级版(2017年12期)2017-12-26 17:01:14
中学生数理化·八年级数学人教版(2017年2期)2017-03-25 16:44:17
公民与法治(2016年22期)2016-05-17 04:20:32
