
理解大众报告安全漏洞的可重现性
2019-07-19 09:35慕冬亮
中国教育网络 2019年6期
文/慕冬亮
大众报告漏洞现状
现如今,软件系统中的安全漏洞对个人用户、组织甚至国家都是严重的威胁。2017年,WannaCry勒索软件利用未修复的漏洞在全球范围内关停了30多万台电脑。
然而,安全漏洞的识别越来越具有挑战性。 高度复杂的现代软件,使得内部团队不再能够在软件发布之前识别所有可能的漏洞。因此,越来越多的软件供应商开始依赖于“大众(The Crowd)的力量”来进行漏洞识别。大众可以是任何在互联网上的人(白帽黑客,安全分析师,甚至普通的软件用户),他们都可以识别并报告一个漏洞。现在很多公司,例如谷歌和微软都花费了数百万美元建立“漏洞赏金”(Bug Bounty)项目,以奖励漏洞报告者。报告者还可以为自己发现的漏洞向CVE(Common Vulnerabilities and Exposures)申请一个编号,以进一步提高社区对这个漏洞的认识,并将对应的漏洞条目归档到各种在线漏洞数据库中。截至2019年2月,CVE网站已存档超过11.2万个安全漏洞。
尽管大众报告(Crowd-Reported)的漏洞数量众多,但漏洞报告与漏洞修补之间仍有很长的路要走。最新数据表明,从最初被报告开始,一个漏洞需要很长时间,甚至是很多年才能被修复。究其原因,除了安全意识的缺乏,也有不少证据表明,这种众包方式获得的报告的质量很差。例如,曾有Facebook用户发现一个漏洞,允许攻击者在任何人的时间轴(Time Line)上发布消息。然而,由于“缺乏足够的细节来重现漏洞”,这份报告被Facebook工程师忽略,直到Facebook CEO 的账号遭到黑客攻击。
随着大众报告漏洞的数量越来越多,这些漏洞的可重现性,对于软件供应商快速定位和修复问题变得至关重要。令人担忧的是,一个不可重现的漏洞更有可能被忽略,从而留下隐患。到目前为止,相关研究工作主要集中在漏洞通知(Vulnerability Notifications)和生成安全补丁方面。而漏洞重现,作为漏洞风险缓解的一个关键早期步骤,尚未得到充分理解。
为了弥补这一空缺,在本文中,我们对大众报告的漏洞的可重现性进行首次深入的实证分析。我们的研究试图回答以下三个问题。首先,仅使用漏洞报告中提供的信息,这些漏洞的可重现性如何?第二,使得某些漏洞难以重现的原因是什么?第三,软件供应商(以及漏洞报告者)可以采取什么行动来系统地提高重现的效率?
这份工作的最大挑战是:重现一个漏洞不仅需要大量的手工工作量,还需要“重现者”具有丰富的相关知识和专业技能。这使得一个研究很难同时达到深度和比较大的规模。因此,我们优先考虑深度,同时保持相当的规模。具体来说,我们只关注内存错误漏洞。这是最危险的软件错误之一,并已造成重大的现实影响(例如Heartbleed,Wanna Cry)。我们组织了一组经验丰富的安全研究人员,并进行了一系列的控制实验,基于报告中的信息重现漏洞。通过精心设计的工作流程,我们保证重现的结果反映的是报告中信息的价值,而不是分析人员的个人技术。
实验花费了3600个工时,涵盖了从过去17年报告的漏洞中随机抽取的368个内存错误漏洞(291个CVE漏洞和77个非CVE漏洞)。对于有CVE编号的案例,我们抓取了CVE网站上列出的4694篇引用链接(比如技术报告,博客)作为重现的信息来源。我们将这些引用视为众包漏洞报告,其中包含了可用于漏洞重现的详细信息。我们有理由认为这是一个比较大的数据集。对比来看,之前的工作在也会使用这些大众报告的漏洞对其漏洞检测和补丁工具进行基准测试。大部分数据集包含的漏洞在10个以下,或者几十的范围内,因为构建漏洞的Ground Truth数据需要大量的手工工作。
我们得到了如下重要观察结果。首先,由于信息的缺失,来自主流安全论坛的单个漏洞报告的重现成功率极低(4.5%~43.8%)。其次,通过“众包”的方法即从所有可能的引用中收集信息,可以恢复部分但不是所有缺失的信息字段。信息聚合后,368个漏洞中的95.1%仍然遗漏了至少一个必需的信息字段。第三,妨碍重现的并不总是最常被遗漏的信息。大多数报告都没有详细介绍软件安装选项和配置(87%+),或受影响的操作系统(OS)(22.8%),这些信息通常可以使用“常识”知识进行恢复。不过当漏洞报告遗漏了概念验证(PoC)文件(11.7%)或者更常见的触发漏洞的方法(26.4%)时,重现将会变得很有挑战。这种情况下,仅有54.9%的被报告漏洞可以根据汇总的信息和常识知识得到重现。
由于能得到的反馈很有限,恢复缺失的信息极具挑战性。通过大量的手工调试和故障排除,我们总结出一些有用的启发式方法,使得重现率提高到95.9%。一个发现是,在测试哪些缺失的信息字段不是“标准配置”时,按照一定的优先级顺序进行,可以提高恢复信息的效率。我们还发现可以利用“相似”漏洞报告之间的相关性,利用“相似”漏洞的报告为一些信息缺乏的漏洞提供参考。尽管有这些启发式方法,但我们认为,如果报告系统强制指定一些信息字段,可以为重现者节省大量的手工工作。
研究方法和数据集
我们只关注一种影响严重的漏洞(内存错误漏洞),使我们能够组织一个专门的领域专家小组进行实验。我们设计了一个系统的重现工作流程,根据既有的信息(而不是专家的个人能力)来评估漏洞的重现性。
漏洞报告数据集
本研究中,我们收集了近17年的被报告的漏洞。总的来说,我们形成了两个数据集,主数据集包含了291个有CVE编号的漏洞,另一个包含了77个没有CVE编号的漏洞作为补充数据集。(参见表1)。
我们主要关注内存错误漏洞。除了著名的例子如Heartbleed和Wanna Cry,CVE网 站 上 还列出了超过10,000个内存错误漏洞。我们抓取了当前95K+条目(2001~2017)的页面,并分析了它们的严重程度评分(CVSS)。我们的结果显示,内存错误漏洞的CVSS平均得分为7.6,明显高于总体平均值(6.2),证实了它们的严重性。
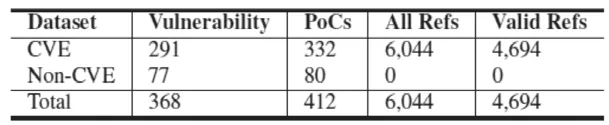
表1 数据集
重现实验设计
在得到以上漏洞数据集的基础上,我们设计了一个工作流程来评测其可重现性。我们的实验试图确定影响重现成功的关键信
CVE条目
我们将CVE网站上每个漏洞的网页称为CVE条目(CVE entry)。在每个CVE条目的reference部分中,被引用的网站我们称为信息源网站或简称为源网站。源站点提供相应漏洞的详细技术报告。我们将源网站上的这些技术报告作为众包漏洞报告进行评估。息字段,同时找出现有报告中通常缺失的信息字段。此外,我们还研究了CVE条目引用的常见信息源及其对重现的作用。
重现工作流程
为了评估漏洞的可再现性,我们设计了一个工作流程,将漏洞重现描述为一个4阶段的过程(如图1所示)。在“报告收集”阶段,安全分析人员收集与漏洞相关的报告和信息源。在“环境设置”阶段,需要识别漏洞软件的目标版本,找到相应的源代码(或二进制文件),并为该软件配置操作系统。在“软件准备”阶段,安全分析人员按照报告或软件规范中给出的编译和配置选项编译和安装漏洞软件。有时,还需要确保漏洞软件所需的库被正确安装。在“漏洞重现”阶段,利用漏洞报告中提供的PoC触发并验证漏洞。
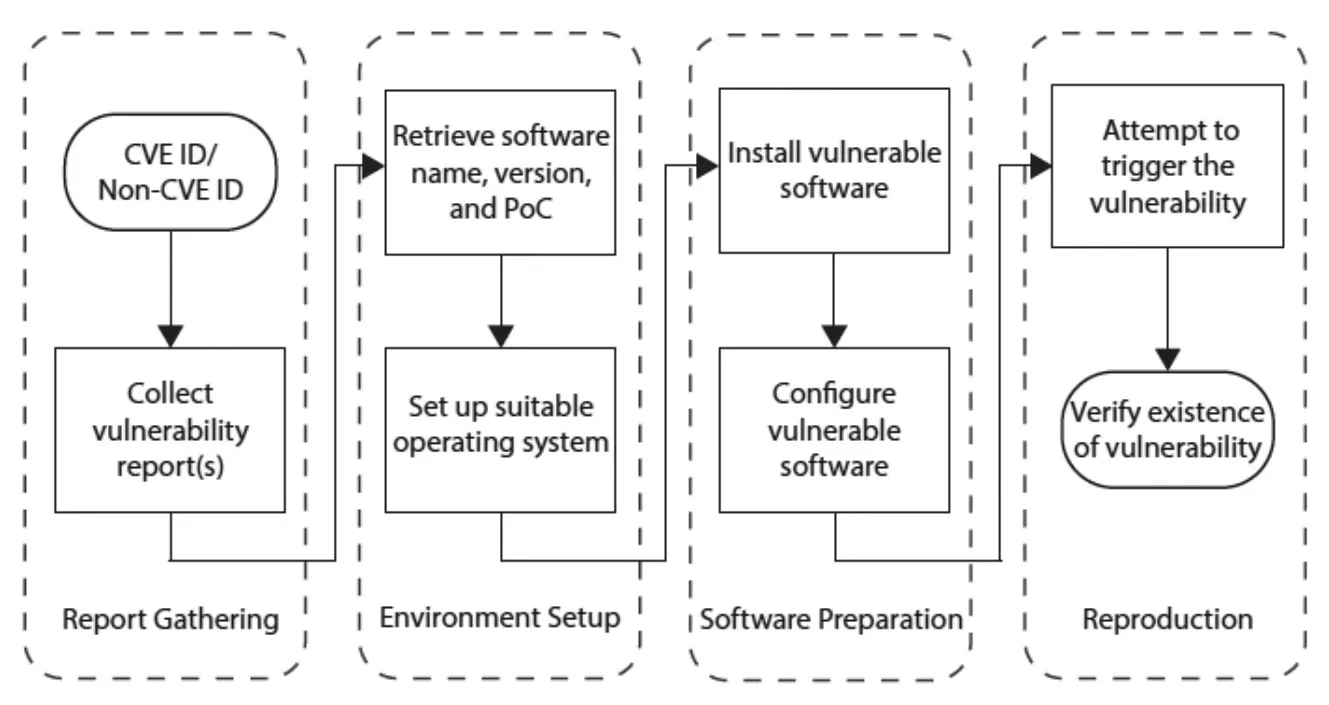
图1 评估漏洞工作流程
分析师团队
我们组建了一支由5名安全分析师组成的团队来进行实验。每个分析人员不仅对内存错误漏洞有深入的了解,而且具有分析漏洞、编写漏洞利用和开发补丁的第一手经验。
默认设置
理想情况下,漏洞报告应该包含成功重现所需的所有信息。然而,在实践中,漏洞报告者可能会假设这些报告将由安全专家或软件工程师阅读,因此可以省略某些“常识”信息。例如,如果一个漏洞不依赖于特殊的配置选项,报告程序可能认为没有必要在报告中包含软件安装细节。为此,当原始报告中没有相应的详细信息时,我们会提供一组默认设置。
举例来说,表2和表3分别展示了默认的PoC文件触发方法和软件安装选项,其余的默认配置请参阅我们的论文。
可控信息源
对于给定的CVE条目,技术细节通常可以在外部引用中获得。我们试图检查来自不同信息源的信息的质量。
在我们的数据集中被引用最多的5个网站是:Security Focus、Redhat Bugzilla、ExploitDB、Open Wall和 Security Tracker。表4显示了在我们的数据集中每个源网站覆盖的CVE漏洞的数量。在291个CVE条目中,共有287个(98.6%)引用了至少一个前5大源网站。

表2 默认的PoC文件触发方法

表3 软件安装选项
给定一个CVE条目,我们按照上述工作流程,使用不同的信息源模式进行3个实验。
CVE单信息源模式(Single-source)。我们逐个测试前5大来源网站的信息(如果有的话)。我们不使用外部引用中包含的信息。这部分包含849个实验。
CVE合并Top5模式(Combined-top5)。综合所有前5大源网站的信息。与单源设置类似,我们不参考它们的外部链接。这部分包含287个实验。
CVE全信息模式(Combined-all)。最后,综合所有引用信息。这部分包含291个实验。
非CVE条目通常不包含引用链接。我们不进行对照分析。我们直接进行“全信息模式”实验(77个实验)。我们的安全分析师总共进行了1504次实验来完成这个研究过程。
评估结果
本章介绍评估结果,我们把关注点放在漏洞重现的时间、重现成功率以及影响重现成功的关键因素。
时间消耗
这三个实验花费了5名安全分析师大约1600个工时完成。平均下来,每个CVE案例的漏洞报告需要大约5小时来完成所有测试,而非CVE案例的漏洞报告平均需要大约3小时。根据我们的经验,最耗时的部分是设置环境并使用正确的选项编译漏洞软件。对于没有直接可用的PoC的漏洞报告,阅读PoC文件中的代码并测试不同的触发方法将花费更多的时间。在结合所有可用信息并应用默认设置之后,我们成功地重现了368个漏洞中的 202 个 (54.9%)。
可重现性
从表4可以看到重现结果的分类结果。我们还评估了漏洞报告和引用链接中信息缺失的程度。我们考虑两个关键指标:“真实成功率”和“总体成功率”。“真实成功率”是成功重现的漏洞数量与给定信息源覆盖的漏洞数量之比。“总体成功率”是成功案例与数据集中漏洞总数的比值。如果一个漏洞有多个与之相关的PoC,只要其中一个PoC成功,我们就认为这个漏洞是可重现的。基于表4,我们有以下观察结果:
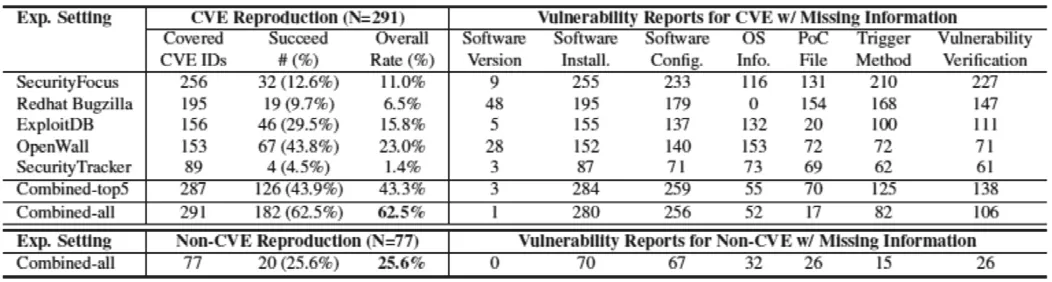
表4 数据集中网站覆盖的CVE漏洞的数量
首先,单信息源模式真实成功率较低,总体成功率更低。
其次,综合Top5网站的信息,可以明显提高真实成功率(43.9%)。整体成功率也提高了(43.3%),这是因为Top5的网站合起来覆盖了更多的CVE条目(291个网站中有287个)。两种成功率的显著增加表明, 5个源网站之间的冗余度相对较低。
第三,我们可以通过迭代地阅读所有的参考链接,将总体成功率进一步提高到62.5%。提取有用的信息需要大量的手工工作。据我们所知,对于NLP算法来说,准确地解释技术报告中的复杂逻辑仍然是一个开放问题。
在我们对CVE和非CVE案例的结果进行汇总后,总的成功率只有54.9%。鉴于在每个案例上花费的大量精力,结果表明众包漏洞报告的可用性和可重现性较差。
缺失信息
我们注意到,漏洞报告遗漏关键信息字段是非常常见的。在表4的右边,我们列出了遗漏给定信息的CVE条目的数量。我们发现单个信息源更可能有不完整的信息。此外,组合不同的信息源有助于检索缺失的部分。
在表5中,我们发现,即使将所有信息源组合在一起,368个漏洞中至少95.1%的漏洞仍然遗漏了一个必需的信息字段。大部份的报告并没有包括软件安装选项及配置的详细信息(87%+),或受影响的操作系统(22.8%);这些信息通常可以使用“常识”知识进行恢复。还有相对少一些的漏洞会缺失PoC文件(11.7%)或漏洞触发方法(26.4%)。
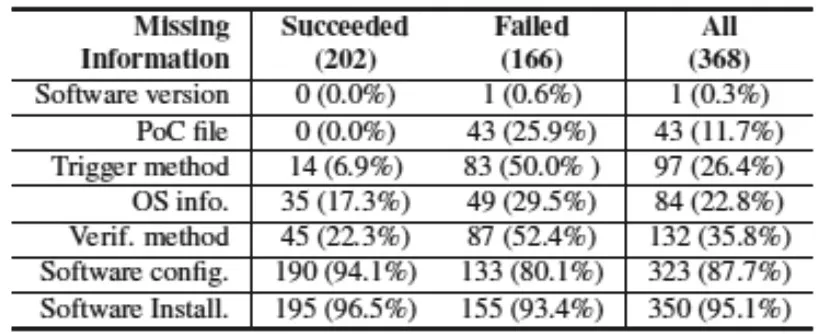
表5 不同信息源组合漏洞信息
研究发现
我们的研究结果表明,漏洞报告遗漏重要信息的情况非常普遍。通过使用我们的默认设置(所谓的“常识”信息),我们只能重现54.9%的漏洞。在本节中,我们将重新讨论失败的案例,并尝试通过额外的手工故障排除来重现它们。我们通过分析特定案例来讨论如何有效地恢复缺失信息。
方法与结果概述
对于给定的“失败”案例,我们的目标是了解重现失败的确切潜在原因。我们根据每个案例的需要使用不同的专用技术,包括调试软件和PoC文件,检查和修改源代码,在多个操作系统和版本中测试案例,以及在互联网搜索相关提示。
通过大量的手工劳动(额外的2000工时),我们成功地重现了94个CVE漏洞和57个非CVE漏洞,使总成功率从54.9%提高到95.9%。结合之前的实验,5位分析师总共花费3600工时(大于3个月的时间)。对多数被报告的漏洞来说,成功重现依赖于正确地推断出缺失的重要信息。遗憾的是,仍然有15个漏洞在所有分析人员尝试之后没有成功。
案例研究
我们提供了一些有趣的案例研究,详情请参考我们的论文。
观察和经验
根据报告的信息重现漏洞类似于做拼图——缺失的碎片越多,拼图的挑战性就越大。在进行第一次有根据的猜测(例如,我们的默认设置)时,重现人的经验起着重要的作用。在不同的案例中,我们发现了一些有用的启发式方法可以提高效率。
1. 信息的优先级
给定一个失败的案例,关键问题是找出哪条信息是有问题的。与其选择随机的信息类别进行深入的故障排除,不如先对信息类别进行优先排序。根据我们的分析,我们推荐以下顺序:触发方法、软件安装选项、PoC、软件配置和操作系统。
当然,鉴于我们已经成功地重现了95.9%的漏洞(groundtruth),我们可以验证哪些信息字段在使用默认设置后仍然缺失/错误,详见表6,这对我们排查出问题的信息提供了指导。
2.不同漏洞的相关性
通过读取其他“类似”漏洞的报告来恢复缺失的信息是非常有用的。这包括同一软件上不同漏洞的报告和不同软件上类似漏洞类型的报告。它特别有助于推断触发方法或在PoC文件中找出错误。

表6 信息字段在使用默认设置后仍然缺失/错误
总结
在本文中,我们对Real World的安全漏洞进行了深入的实证分析,来量化它们的可重现性。我们的实验表明,对于安全分析人员来说,仅使用主流安全论坛的单份报告来重现与漏洞相关的Failure通常比较困难。通过利用众包的方式收集报告,可以提高可重现性,但还需要复杂的故障排除来解决失败的案例。我们发现,除了在互联网是搜索(互联网规模的众包)和一些启发式技巧,基于经验的手工工作(例如调试)是从报告中恢复缺失信息的唯一方法。我们的发现与我们调查的黑客、研究人员和工程师给出的回答一致。通过这些观察,我们认为有必要引入更有效和自动化的方法来收集报告中常见的缺失信息,并通过硬性规范和激励制度来提高漏洞报告的质量,以此健全现有的漏洞报告系统。
数据共享
为了方便今后的研究,我们将公开经过我们完全测试和注释过的数据集,其中包含368个漏洞(291个CVE和77个非CVE)(https://github.com/Vuln Reproduction/Linux Flaw)。基于我们的调研经验,我们为每个案例提供了详尽的报告,补充了所有缺失的信息,附加了正确的PoC文件,并创建了对应的Docker镜像以帮助快速地重现漏洞。相信它可以成为研究人员需求的大规模评估数据集。(责编:杨燕婷)
猜你喜欢
今日农业(2022年13期)2022-09-15
思维与智慧·下半月(2021年11期)2021-11-23
活力(2019年19期)2020-01-06
神州·下旬刊(2019年1期)2019-02-11
中国神经再生研究(英文版)(2017年10期)2017-11-08
中国卫生(2016年5期)2016-11-12
儿童时代(2016年6期)2016-09-14
中国卫生(2015年12期)2015-11-10
图书与情报(2014年3期)2014-02-27
黑龙江史志(2010年4期)2010-08-15
