
全维知识图谱概述及知识表示框架研究
2019-07-16 03:17黄细凤
电脑知识与技术 2019年14期
关键词:知识图谱
黄细凤

摘要:针对不同的信息品类在信息转换、处理、展示时出现的失真、损伤或偏差的问题,提出了全维知识图谱的概念,对全维知识图谱的原理、关注内容、用法和好处进行了概述;然后针对全维知识表示,提出了统一的知识表示框架,采用分级的信息特征和特征属性进行信息内容的描述,并以文本类信息为例对表示框架进行实例化,形成了信息特征表示模型。
关键词: 知识图谱;全维知识图谱;全维知识表示;知识表示框架;信息特征
中图分类号:TP18 文献标识码:A
文章編号:1009-3044(2019)14-0145-02
Abstract: Aiming at the problems of distortion, damage or deviation in information conversion, processing and display of different information categories, the concept of full-dimensional knowledge graph was proposed, and the principle, content, usage and advantages of full-dimensional knowledge graph were summarized. A unified knowledge representation framework was proposed for full-dimensional knowledge representation, which is based on hierarchical information features and feature attributes of descripting information content. Taking text information as an example, the representation framework was instantiated and an information feature representation model was formed.
Key words: knowledge graph; full-dimensional knowledge graph; full-dimensional knowledge representation; knowledge representation framework; information feature
世界多姿多彩,信息丰富,描述方式与信息品类多种多样,有文字、声音、图片、视频等等。而不同信息品类在信息转换、处理、展示时会失真或损伤,甚至出现偏差与错误。例如,将声音转成文字时,仅仅记录了声音的语义,却忽略了说话人的语种、语气、语调、情感、修辞、倾向、风格等等信息,从而丢失了很多维度的信息,对于理解声音就可能产生歧义、不到位、甚至错误的理解。
用全维知识图谱的方法来进行信息解析与知识表达,不失真、不降维地对知识进行采集、存储等。一方面,可以完整地高保真地对信息进行记录,在转移时使受众不产生歧义;另一方面,统一一种处理方法,可以将文字、声音、图像、视频等进行大融合,为跨专业、跨领域的知识交互与融合提供基础。因此,本文提出采用全维知识图谱来构建一种知识表达的框架和标准,规范不同品类信息的描述方法,以便在信息采集、存储、解析、转换、处理、融合等等过程中不失真、不降维。
1 全维知识图谱概述
本文将从三个方面来对全维知识图谱进行阐述,包括其关注内容、怎么用和有什么出好处。
1.1 关注内容是什么?
全维知识图谱需要关注的内容有:
(1)全维知识图谱基础理论研究;
(2)跨学科知识表达标准体系,知识分类体系;
(3)知识表达统一框架构建,全维知识图谱基本架构和顶层模型梳理;
(4)垂直领域全维知识图谱构建;
(5)全维知识图谱的效能统一表征方法与效能评估;
(6)基于全维知识图谱的跨品类、跨专业、跨学科知识融合。
1.2 怎么用?
现阶段以Knowledge Graph为主的一系列知识图谱为精细化的查询奠定了基础,随着智能信息服务应用的不断发展,知识图谱已被广泛应用于智能搜索、智能问答、个性化推荐、可视化决策支持等领域。而当前知识表达方法,不管是基于怎样的学习原则,都不可避免地产生语义损失。符号化的知识一旦向量化后,大量的语义信息被丢弃,只能表达十分模糊的语义相似关系。全维知识图谱以知识图谱的概念为基础,构建知识表达统一框架,多视角、多维度地对信息或对象进行描述,应用于军事领域,可为作战指挥人员提供更为“真实”的情报,提高作战效率。应用方向有:
(1)用于规范素材、信息的采集,提升海量半结构化、非结构化数据的有效获取能力;
(2)促进领域知识体系的构建;
(3)基于全维知识图谱,构建领域知识库,在接入、处理、分析、服务等各个环节提供统一的数据空间,将不同品类、不同对象的数据统一存储、处理、使用;
(4)特别地,应用于目标识别领域,可以给目标识别提供更加丰富的视角和特征;
(5)同样地,支持基于知识图谱的应用,如智能搜索、智能问答、个性化推荐、可视化决策支持等。
1.3 有什么好处?
作用和好处包括:
(1)全维知识图谱可以指导信息的采集、存储、处理、转移、解析、理解;
(2)可以根据用户的实际情况实现合理的剪裁,得到精准服务的效果,是人工智能的主要研究方向;
(3)可以完整地高保真地对信息进行记录,在转移时使受众不产生歧义;
(4)信息利用更充分,可以将文字、声音、图像、视频等进行大融合;
(5)全面地、多视角地、多维度地描述信息、目标等对象;为目标识别提供更多维度、更多视角、更多特征;
(6)可以提供深度的知识关联及语义层的知识推理,更深层地理解信息;
(7)为跨领域、跨专业的交互、协作与统一融合提供了基础。
2 全维知识表示框架
“全維”是指采用尽量多的维度和侧面来描述信息,以使采集的信息尽量完整和准确。本文针对文本、语音、图像、视频、结构化数据等多种类型的信息,采用分级的信息特征和特征属性进行信息内容的描述,形成基本的知识表示框架,如图1所示。
信息特征由其语义特征、背景特征和关联特征组成。其中语义特征由包括语义特征的向量化表达、浅层语义及深层语义;背景特征包括时间背景、地域背景、事件背景、人物背景等;关联特征包括人物关联、时间关联、事件关联、地域关联等特征。
特征属性中所有的属性内容都有其模型,例如人物模型、时间模型、语气模型、情感模型,也就是说每增加一项属性内容就对该属性内容进行描述,即知识对象模型。而当这些模型进行实例化时,知识数据就来自各种信息素材,从而与知识图谱进行关联,这样就构建出了知识世界的框架。
3 信息特征表示模型
在信息特征表示框架中,按文本、语音、图像、视频等类型,对各自的特征属性进行实例化,就构建成了文本、语音、图像、视频的信息特征表示模型了。下面以文本信息为重点进行详细阐述。
3.1 文本信息特征表示模型
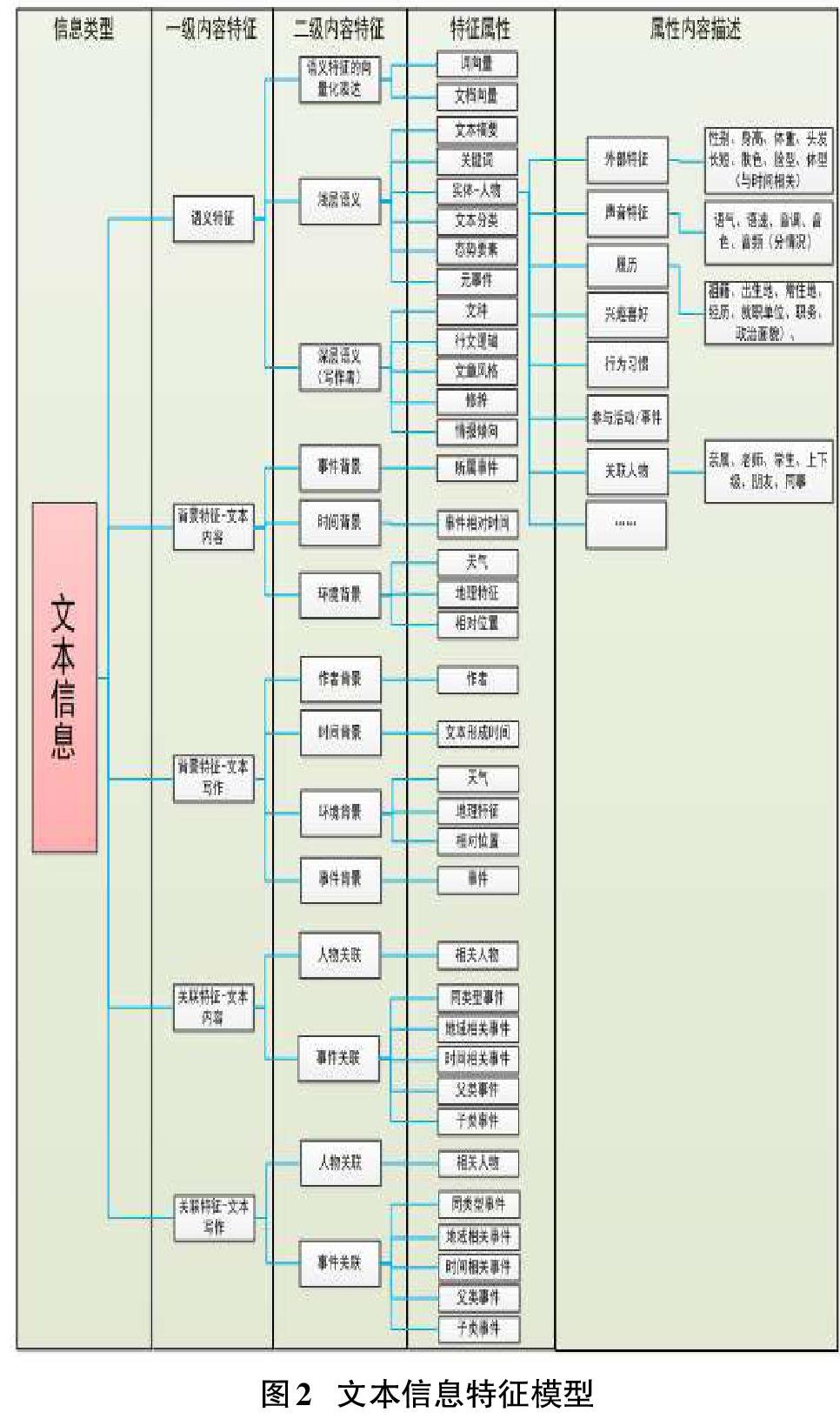
文本信息特征表示模型如图2所示。
文本信息特征由语义特征、文本内容和文本写作的背景特征和关联特征等一级内容特征组成。其中,语义特征由语义特征的向量化表达、浅层语义、深层语义等二级内容特征组成;背景特征由事件背景、时间背景、环境背景、作者背景、时间背景、环境背景、事件背景等二级内容特征组成;关联特征由人物关联、事件关联等二级内容特征组成。二级特征又由一系列的特征属性组成,如浅层语义特征由文本摘要、关键词、实体、文本分类、态势要素、元事件等组成。每个特征属性又具有相应的描述信息,如浅层语义中的人物实体对应的描述信息包括人物的外部特征、声音特征、履历、兴趣爱好、行为习惯、参与事件活动、关联人物等,其中每个描述信息又包括系列具体的属性,如人物的外部特征包括性别、身高、体重、头发长短、肤色、脸型、体型等外部特征描述和语义、语速、音调、音色等声音特征组成。
3.2 其他信息特征表示模型
语音特征表示模型:基于信息特征表示框架,构建语音特征表示模型,其中背景特征和关联特征与文本信息类似,重点对语义特征进行建模。其中,浅层语义主要指语音转成的文字以及语音中的关键词,深层语义主要指语音本身所携带的声纹特征、语气、语调、音色、音频等特征。
图像特征表示模型:图像的语义特征,从向量化表达的角度,一般使用图像特征来表达,如统计特征、纹理、结构等;图像的浅层语义主要指从图像中获取的文本化内容,如图像所描述的物体、人物、姿态以及位置关系等;图像的深层含义主要指从图像中描述的内容所表达的意图信息、心理活动等。
视频特征表示模型:视频可以看成是连续的图像加上声音,其语义特征可以参照图像特征及语音特征进行构建。
4 结论
在本文中,我们提出了全维知识图谱的概念,采用尽量多的维度、统一的知识表示框架来规范不同品类信息的描述方法,能够使采集的信息尽量完整和准确。本文对全维知识图谱的概念内涵进行了阐述,并给出了一种知识表示的框架,说明在领域应用中是可行的,而通过分析可知,全维知识图谱能够在多个环节发挥实际的好处,因此,很有必要进行继续深入的研究。
参考文献:
[1] 徐增林, 盛泳潘, 贺丽荣. 知识图谱技术综述[J].电子科技大学学报,2016,45(4): 589-606.
[2] 马创新.论知识表示[J]. 现代情报,2014,34(3):21-24.
[3] 刘峤, 李杨, 段宏. 知识图谱构建技术综述[J].计算机研究与发展,2016,53(3):582-600.
[4] 虞盛康. 面向互联网数据的知识表送与推理[D].浙江:浙江大学,2016.
[5] 陈宏. 基于本体的知识表示研究[D].长沙:长沙理工大学,2006.
[6] 党洪莉. 知识科学视角下我国知识融合研究现状解析[J].情报杂志,2015,34(8):158-162.
[7] 周芳, 王鹏波, 韩立岩. 多源知识融合处理算法[J].北京航空航天大学学报,2013,39(1):109-114.
[8] 王锦, 王会珍, 张俐. 基于维基百科类别的文本特征表示[J].中文信息学报,2011,25(2):27-31.
[9] 许鹏飞. 图像结构化特征表达方法研究[D].哈尔滨: 哈尔滨工业大学,2013.
【通联编辑:唐一东】
猜你喜欢
