
结合注意力与特征融合的目标跟踪
2019-07-15 07:27:26高俊艳刘文印杨振国
广东工业大学学报 2019年4期
高俊艳,刘文印,杨振国
(广东工业大学 计算机学院,广东 广州 510006)
单目标跟踪是计算机视觉中的基本且具有挑战性的任务. 给定目标在视频序列第一帧中的初始状态(如目标的中心位置坐标,尺寸大小),跟踪的目的是自动估计目标物体在后续帧中的状态. 单目标跟踪在视频监控、视频会议、道路驾驶[1]和人机交互[2]等场景中都发挥着至关重要的应用价值. 过去几十年以来,目标跟踪的研究取得了长足的发展,尤其是在引入各种机器学习算法之后,跟踪器的性能得到了很大的提高. 2013年之后,深度学习的方法被引入目标跟踪领域,并逐渐在性能上超越传统方法,取得极大的突破. 然而,在照明不足、尺度变化、剧烈变形、遮挡和快速运动等具有较大外观变化时,跟踪任务仍然面临非常大的挑战,在达到实时的跟踪速度和足够高的跟踪准确度方面还有待新的提高. 现有的单目标跟踪方法大致可分为两个分支.
一个分支是基于相关滤波(Correlation Filters,CF)的方法. 最经典的是核相关滤波算法(High-Speed Tracking with Kernelized Correlation Filters,KCF)[3],使用循环矩阵对样本进行采样,提取图像的HOG特征,利用快速傅里叶变化对算法进行加速计算,其跟踪时运行速度约为每秒172帧. 随着图像深度卷积特征的引入,一定程度上提高了跟踪的准确度. 文献[4]和文献[5]探索了使用多层卷积特征对跟踪目标进行学习和表达. 文献[6]和文献[7]提出了一种跟踪目标尺度自适应解决方案.
另一个分支是基于深度学习的方法,它通过多个卷积层学习非常强大的深层特征,端到端实现目标跟踪. 文献[8]训练了一个端到端的学习多域通用目标表示的CNN框架. 文献[9]利用全连接层回归当前帧目标的位置,最终模型以约100 fps的速度在线预测目标边界框. 全卷积孪生网络是实现目标跟踪的比较流行的基础框架之一. 孪生网络由两个分支组成:一个分支用于提取目标模板的特征,另一个分支用于提取后续帧图像的特征. 将目标模板特征与当前预测帧的候选区域特征进行相似性比较,获得相似性得分最高的位置即为跟踪目标的预测位置.文献[10]训练了一个端到端的全卷积孪生网络框架,用于视频中的实时目标跟踪. 文献[11]引入了语义分支来提取图像的语义特征. 它通过结合外观分支和语义分支来提升跟踪性能. 文献[12]在全卷积孪生网络之后增加区域推荐网络来预测目标的位置和大小. 通过在大型视频序列数据集上离线端到端地训练网络模型,深度学习的方法凭借强大的特征学习和表征能力实现了比CF算法更好的性能.
本文在全卷积孪生网络的基础上进行了如下改进.
(1) 针对全卷积孪生网络的模板帧不更新问题,设计了第一帧和当前帧的前一帧结合作为目标模板的方法,实时更新目标模板.
(2) 提取输入图像的多个卷积层的特征,融合目标的表观信息和语义信息.
(3) 将通道注意力机制与目标模板的多层卷积特征相结合,赋予对跟踪目标影响大的通道特征更高的权值,提升目标模板特征的判别力.
1 动态更新目标模板
对于单目标跟踪任务,不少跟踪算法选择视频序列的第一帧作为跟踪目标的模板帧,在第一帧给出跟踪目标所在位置的矩形框(人工标注或目标检测算法的结果),然后利用跟踪算法在后续帧中确定目标的位置. 因为第一帧中的目标模板通常可以清楚地区分目标,例如正脸、行人的正面、汽车头部或尾部等,都可以作为识别目标的有判别力的特征,所以,为了提升跟踪网络的速度,传统的孪生网络[10]只使用第一帧作为固定模板. 然而,视频中的目标是实时动态变化的,仅使用第一帧作为固定模板限制了跟踪准确度的提高.
视频中经常会出现当前帧中的目标与第一帧中的目标相似度很小甚至不相似,比如第一帧模板给定跟踪的目标人的正脸,而当前帧只有目标人的侧脸或背面,此时,极其容易跟踪错误,尤其是在人数较多的场合,而使用当前帧的前一帧或连续前几帧作为目标模板便可以成功捕获目标的运动变化[13-14].然而只使用当前帧的前一帧[3]或连续前几帧实时更新模板,又会带来模板漂移的问题,一旦跟踪错误,将无法弥补,无法再跟踪到正确的目标.
针对文献[10]和文献[3]跟踪算法的缺点,本文设计了将第一帧和当前预测帧的前一帧结合作为目标模板的方法,同时考虑目标的判别力特征和运动变化特征,在实时更新目标模板的同时避免模板漂移问题. 如图1中所示,模型在孪生网络两个分支的基础之上增加一个分支,虽然会损失一些速度,但在出现较大变形和遮挡时,网络也可以实现长期的动态视觉跟踪.
本文设计的目标跟踪网络模型的输入由3张图片组成:视频序列第1帧中裁剪的目标模板区域图像,当前帧的前1帧(第t-1帧)中裁剪的目标模板区域图像和当前帧图像(第t帧),分别使用符号xfirst、xlatest和z代表这3张图片. 模型的两个跟踪分支分别使用(xfirst,z)和(xlatest,z)作为输入.
2 特征融合
由于语义特征具有良好的不变性,一般的跟踪模型采用特征提取网络最后一层的输出作为目标特征,然而这一层特征不能很好地捕捉目标的空间细节信息,而这些细节信息对于目标的定位非常关键,并且语义信息的偶尔指导错误也会导致模板漂移或错误预测. 卷积神经网络学习的浅层特征含有更多目标的表观信息和空间细节,而深层特征学习了目标的语义信息. 所以,为了获得更好的跟踪性能,本文设计的孪生网络模型融合了多层卷积特征,同时考虑目标的表观特征和语义特征进行跟踪.
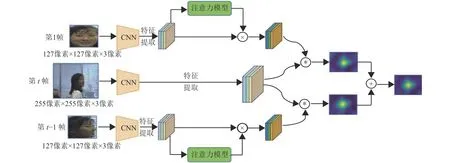
图1 本文提出的目标跟踪模型框架Fig.1 The object tracking model framework proposed in this paper
本文采用的特征提取网络是加载ImageNet[15]上预训练的AlexNet[16]网络模型. 输入的图像通过AlexNet网络提取特征,如图1中显示,模型提取了3种类型的特征,即conv3、conv4、conv5的卷积特征,它们是对图像的不同层次的特征表达. 本文使用符号φ(·)表示提取的3卷积特征的整合,其中提取xfirst的卷积特征可表示为φ(xfirst),提取xlatest的特征可表示为φ(xlatest),提取z的特征可表示为φ(z). 融合多层的卷积特征在一定程度上增加了特征的多样性,提高了模型的鲁棒性.
对目标模板特征φ(xfirst)和φ(xlatest)的处理与对当前帧特征的处理稍有不同. 在目标跟踪任务中,目标模板作为参考的标准,其特征的判别性尤其重要,丰富的目标姿态变化以及不同程度的背景干扰等都对提取具有判别力的目标模板特征提出了更高的要求,如何获得更有判别力的目标模板特征成为跟踪模型性能提升的关键. 融合多层的卷积特征可以看做是在广度上提升特征的判别力,而在深度上,对跟踪目标影响力大的特征赋予更大的权重,可以大大增强图像特征的判别力和模型的鲁棒性. 在文献[4]和文献[7]等跟踪方法中,由于语义信息的主导作用,深层特征被赋予了比浅层特征更高的权重. 不同的目标、不同的背景以及不同的运动变化等都会导致跟踪时对不同的特征的依赖程度不同,所以使用固定的权重来衡量多个特征之间的关系是不可行的,不能够处理多样的具有挑战性的情形,甚至可能会限制模型的跟踪性能. 在本文中,针对目标模板的特征提取问题,采用将特征融合与通道注意力机制结合的方法,在广度和深度方面同时增强目标特征的判别力.
3 注意力机制
近年来,注意力机制已广泛用于各种深度学习领域,例如图像处理,语音识别和自然语言处理(Natural Language Processing,NLP)等. 注意力机制的核心是从广泛的信息中学习最重要的信息. 理解注意力机制是如何工作并将其应用于某些任务对于研究人员来说是非常必要的. 文献[11]提出了通道注意力机制,为更有判别力的通道赋予更高的权重. 由于不同的跟踪目标激活不同的特征通道,该通道注意力机制对不同通道自适应计算不同权重. 文献[13]提出一种时空注意力机制,可以自适应地聚合跟踪目标的历史特征图和当前特征图,以改善目标特征表示和模型跟踪精度. 文献[17]引入了3种注意力机制来提高模型的判别能力:一般注意力机制,通道注意力机制和残差注意力机制.
由文献[11]和文献[17]中得到启发,本文设计了通道注意力机制,赋予那些影响大的通道特征更高的权值,解决不同的通道特征对跟踪目标的重要性不一样的问题. 模型通过将特征融合与通道注意力机制相结合,在广泛融合目标的多种层次表征的同时,更细粒度地学习不同通道特征的重要性,有效地提升目标特征的判别力.
图2展示了注意力模型从编码到解码的整个过程,以第1帧目标模板作为注意力模型的输入为例,编码过程包括从图像输入到提取目标模板的3层卷积特征,解码过程则为对提取的卷积特征的每个通道进行处理,计算得到每个通道特征对跟踪目标影响力的权重系数. 解码过程通过对每个通道特征进行最大池化层处理,两层的多层感知机(Multi-Layer Perception,MLP),采用Sigmoid函数来计算得到每个通道特征的最终权重系数.
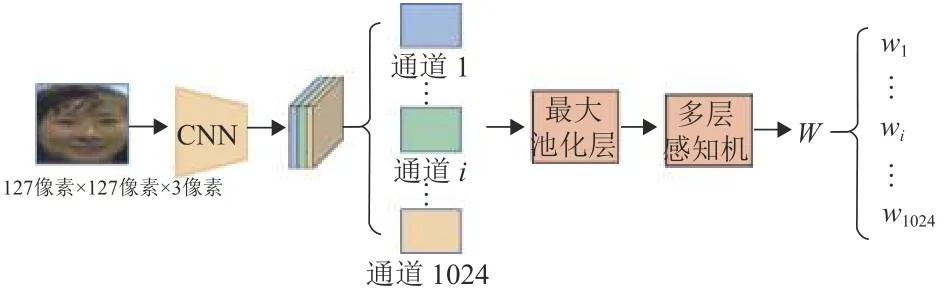
图2 注意力模型框架Fig.2 Attention model framework
注意:本文利用大型视频序列数据集离线训练注意力模型的参数,而在测试跟踪阶段直接计算权重系数,其参数不会更新.
通道加权后的目标模板xfirst的特征可表示为Wfirstφ(xfirst),通道加权后的目标模板xlatest的特征可表示为Wlatestφ(xlatest),其中Wfirst和Wlatest的维度与目标模板特征的通道数相同且(·)是元素级别的乘法.
第1帧的目标模板xfirst与当前帧z的多层卷积特征分别对应进行互相关计算,得到相应的预测目标的位置响应图,公式为:
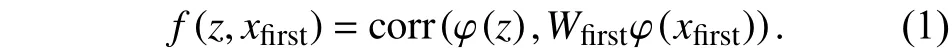
同理,当前帧的前一帧的目标模板xlatest与当前帧z的多层卷积特征分别对应进行互相关计算,得到相应的预测目标的位置响应图,公式为:
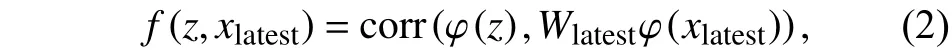
其中corr(·)为卷积互相关操作. 注意:当前帧图像z的特征提取过程只执行1次.
则最终在当前帧中预测的目标位置的响应图由两个跟踪分支的响应图加权平均得到:
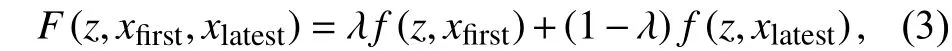
其中,λ是平衡两个跟踪分支重要性的超参数. 经过实验得知,当λ设置为0.3时,模型效果最优.
4 实验
本章将介绍实现细节、评估方法,以及在OTB50[18]、OTB100[19]和VOT2017[20]数据集上与几个先进的跟踪模型进行比较的实验对比结果.
4.1 实验细节
本文设计的目标跟踪模型使用TensorFlow编码实现,并在ILSVRC2015[21]视频数据集上进行了线下预训练. 模型训练阶段,图像特征提取网络是加载ImageNet[15]上预训练的AlexNet网络模型框架及其参数,并在保持其参数不变的情况下,训练通道注意力模块,最终选取最优的注意力模块参数来探索不同通道特征的重要性. 评估和测试阶段,针对尺度估计问题,模型仍延续文献[10]的3个尺度,最终选择跟踪目标的最佳尺度大小.
数据维度:对于整个跟踪模型的输入,目标模板xfirst和xlatest有共同的输入大小127像素×127像素×3像素,而当前帧z的输入大小是255像素×255像素×3像素. AlexNet网络提取的当前帧的conv3、conv4、conv5的卷积特征大小分别为15像素×15像素×384像素、15像素×15像素×384像素、15像素×15像素×256像素;提取的目标模板xfirst和xlatest的conv3、conv4、conv5的卷积特征大小分别为7像素×7像素×384像素、7像素×7像素×384像素、7像素×7像素×256像素.经过互相关后得到的响应图大小为9像素×9像素.
本文的实验环境是Intel Core i7-6850K 3.60 GHz CPU和NVIDIA TITAN X(Pascal)GPU. 一般来说,超过25 fps的跟踪速度被认为是实时的,而本文模型在线跟踪时达到了实时的效果,平均速度为45 fps.
4.2 实验对比
(1) 在OTB50和OTB100数据集上的实验对比.OTB(Visual Tracker Benchmark)是一个针对单目标跟踪的主流测试平台. OTB50数据集包含50个完全注释的视频序列,OTB100数据集将OTB50数据集扩展为100个视频跟踪序列. OTB50/100数据集涉及到目标跟踪的11个属性:光照变化、尺度变化、遮挡、形变、运动模糊、快速运动、平面内旋转、平面外旋转、出视野、背景干扰、低像素. 对于OTB数据集,选取两种评价标准:中心误差和区域重叠. 将本文设计的跟踪模型与ECOhc、SiamFC、CFNet[22]、KCF、STAPLE[23]在OTB50/100数据集上进行比较,图3展示了各个模型在不同错误阈值下中心点的定位精度的结果和在不同区域重叠阈值下跟踪的成功率的结果,以及各个算法在本文实验环境下的运行速度的对比. 实验结果表明,本文设计的跟踪模型在中心误差和区域重叠两个标准上都获得了不错的性能. 针对近几年基于全卷积孪生网络的多个改进算法,在OTB50/100数据集上,表1显示了各算法的对比结果.实验结果证明了本文改进方法的有效性,尤其是在OTB100数据集上的性能胜过其他对比算法. 本文设计的跟踪模型是在SiamFC的基础上进行的改进,所以在OTB100数据集中选取了几个典型的视频序列与其进行对比实验,图4显示了比较结果.
(2) 在VOT2017数据集上的实验对比. VOT(Visual Object Tracking)也是一个针对单目标跟踪的主流测试平台. VOT数据集的序列每年更新1次,注释的准确性逐年提高. 对于VOT数据集,选取准确率(Accuracy,A)、鲁棒性(Robustness,R)和期望平均重叠率(Expect Average Overlap Rate,EAO)作为评估标准. 表2显示了本文设计的跟踪模型与C-COT,ECOhc,SiamFC,Staple在VOT2017数据集上的实验结果. 结果证明本文设计的跟踪模型获得了比较有竞争性的效果.
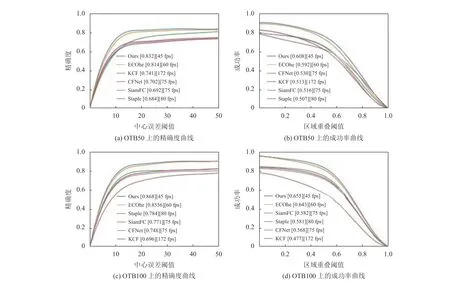
图3 各个模型在OTB50/100数据集上的跟踪精确度曲线和成功率曲线Fig.3 Precision curve and success rate curve of tracking for each model on OTB50/100 benchmarks
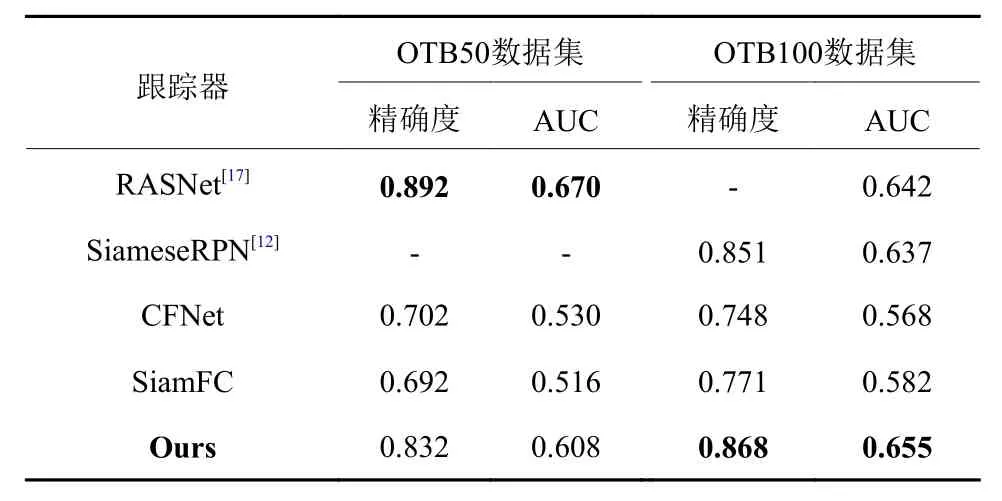
表1 在OTB50/100数据集上基于全卷积孪生网络改进算法的对比Tab.1 Comparison of improved algorithms based on full convolution siamese networks on OTB50/100 benchmark
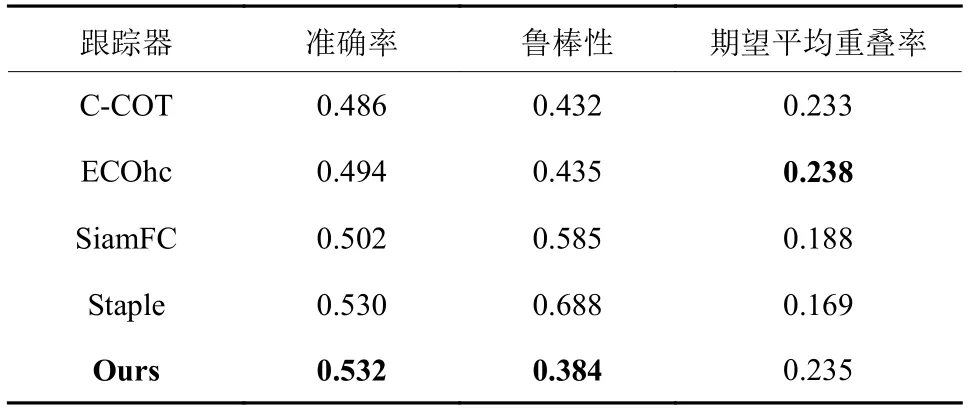
表2 VOT2017数据集上各个模型的实验结果Tab.2 Experimental results for each model on the VOT2017 benchmark

图4 在OTB100数据集的几个视频序列上的跟踪结果展示,其中红色框是本文设计的模型的跟踪结果,黄色框是SiamFC的跟踪结果Fig.4 The tracking results on several video sequences of the OTB100 benchmark, in which the red box is the tracking result of the model proposed in this paper, and the yellow box is the tracking result of SiamFC
5 结论与展望
本文设计了结合注意力机制和特征融合的目标跟踪模型,实现了端到端的实时在线跟踪. 模型提取图像的多层卷积特征,融合了目标的外表信息、空间细节和语义信息,再结合通道注意力机制进一步提升目标模板特征的判别力,从而有效地提高了模型跟踪的准确性. 实验证明,本文设计的跟踪模型在
OTB50/100和VOT2017数据集中都获得了比较有竞争力的性能. 在未来的工作中,将会继续探索提升目标特征的判别力的有效方法.
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
数学物理学报(2017年5期)2017-11-23 07:51:31
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
CHIP新电脑(2016年3期)2016-03-10 14:22:03
