
机器学习课程案例设计与分析
——以舆情智能分析案例设计为例
2019-07-12 07:37姬名书
实验技术与管理 2019年6期
饶 泓, 姬名书, 朱 剑
(南昌大学 信息工程学院, 江西 南昌 330031)
机器学习(machine learning,ML)涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科,是人工智能领域中一个极其重要的研究方向,是数据挖掘、计算机视觉、语音识别、自然语言处理等研究的基础。机器学习与模式识别算法已经成功应用于现代互联网中的搜索引擎、社交网络、推荐引擎、计算广告、电子商务等领域中,成为当前研究的热点之一。
机器学习课程也是高校计算机专业硕士研究生、博士研究生的专业核心课程。本文设计了一个基于机器学习算法的舆情分析案例,以电影《战狼2》的影评分析为例,阐述使用机器学习方法解决实际问题的完整过程。
机器学习的过程通常包括数据获取、数据清洗、数据可视化分析、数据建模、数据分析、结果输出等步骤。本论文以《战狼2》影评为例,说明基于机器学习算法的舆情分析过程。
1 数据预处理
本案例从微博、论坛、朋友圈、贴吧等活跃社区获取评论,然后通过去重、索引等方法对源数据进行预处理后入库,再使用去停用词、自动聚类、SVM等方法进行建模分析,最后将所得到结果通过数据可视化方法展现。主要流程如图1所示。

图1 舆情分析流程图
(1) 数据获取。数据获取主要是利用网络爬虫(Web Crawler)或网络蜘蛛(Web Spider)类的程序自动爬取网页数据[1]。利用爬虫获取数据的大致流程如图2所示。
(2) 数据清洗与数据入库。数据清洗主要是删除原始数据集中的无关数据、重复数据,平滑噪声数据,筛选并删除与挖掘主题无关的数据,处理缺失值、异常值等[2]。
通过上述预处理步骤后将数据保存入库,即可进行舆情分析。
2 舆情分析方法
2.1 传统网络舆情分析技术
传统的网络舆情分析技术主要包括网络调查方法、基于统计规则的模式识别方法、内容分析法等[3]。

图2 数据爬取过程图
网络调查方法即在网络上进行问卷调查,该方法通过设计问卷、抽样调查、统计分析等一整套科学程序,能够客观地推测社情民意[3]。但由于网络调查方法主要是进行采样分析,要求抽样具有随机性,在大数据环境下抽样对象是海量的互联网用户,很难找到最优抽样的标准,所以不可能根据抽样的小样本得出能精确反映整体趋势的所有特征。
基于统计规则的模式识别是通过统计分析某段时间内用户所关注信息点的记录来构建互联网内容与舆情的热点/热度、频点/频度、黏点/黏度等10个分析模式和判据[4]。由于不同信息源的信息产生方式有较大的差异,在大数据环境下具有一定局限性,所以该方法只适用于特定对象。
内容分析法是一种有效的社会科学研究方法,主要在3方面得到应用:一是网络中的舆情信息;二是对网络舆情信息的态度和情绪进行推断;三是分析网络舆情信息并得出趋势变化[5]。该方法对原始材料的依赖性很强,而网络舆情信息难以辨伪,使得内容分析法不是很高效。但是随着网络技术的发展,分析软件的处理能力提高,内容分析法在网络舆情分析中仍然很重要,因此本文的文本聚类方法仍以此为基础。
2.2 基于机器学习的舆情分析方法
本案例从词云图出发,分析数据的一般规律,利用时间序列和文本聚类方法对舆情进行分析。通过制作词云图,观察数据特征,了解群众对于具体事件的关注点;然后利用时间序列分析法分析随着时间的推移群众对该事件的情感变化;最后利用文本聚类方法对该事件的所有舆论进行聚类,查看群众对该事件的话题有哪些,并判断其情感倾向。
2.2.1 基于词云图的舆情分析技术
在制作词云图阶段,利用TextRank方法进行关键词提取,然后进行舆情分析。TextRank算法是基于图论的文档关键词提取方法,可以理解为是PageRank在文本领域的应用[6]。关键词提取主要是从给定的文本中自动提取出有意义的词。TextRank算法是建立图模型并利用其局部词之间的关系(共现窗口)对词进行评分,然后对后续关键词进行排序。
TextRank算法主要步骤如下:
(1) 把给定的文本T按照完整句子进行分割,即:T=[S1,S2,S3,…,Sn];
(2) 对于每个句子Si,进行分词和词性标注处理,并过滤掉停用词;
(3) 构建候选关键词图模型G=(V,E),其中V为节点集,由步骤(2)生成的候选关键词组成,E为词与词之间的关系,采用共现关系构造任意两点之间的边,两个节点之间仅当它们对应的词汇在长度为K的窗口中共现时才存在边,K表示窗口大小,即最多共现K个单词,每个候选词Wi的评分计算公式为
(1)
其中,d为阻尼因子,即候选词i转到候选词j的概率,一般取值为0.85[6]。In(Wi)为候选词i的入度,Out(Wj)为候选词j的出度;
(4) 根据式(1),迭代计算各节点的权重,直至收敛;
(5) 对词权重进行倒序排列,从而得到T个最重要的单词,并将其作为关键词。
2.2.2 基于时间序列的舆情分析技术
在时间序列舆情分析阶段,利用SnowNLP库的情感分析技术进行情感倾向判断。SnowNLP算法的原理是基于贝叶斯模型的情感分析方法。SnowNLP涉及很多技术,例如中文分词(character-based generative model)、词性标准(其原理有TnT算法、3-gram模型与隐马尔科夫模型)、情感分析、文本分类(原理是NaiveBayes)、提取文本关键词(原理是TextRank算法)、提取文本摘要、tf-idf等。
2.2.3 基于文本聚类的舆情分析技术
在对文本聚类跟踪观众的话题及其情感倾向时,利用经典的K-Means方法聚类后进行分析,其中在特征提取阶段利用了逆文档频率(tf-idf)方法。其原理如下:
(1) K-Means算法
K-Means算法是经典的基于距离的非层次聚类算法,在最小化误差函数的基础上将数据划分为预定义的类数K,采用距离作为相似性的评价指标,即两个对象的距离越近,其相似度就越大[7-9]。K-Means的算法过程为:
① 从N个样本数据中随机选取K个对象作为初始的聚类中心;
② 分别计算每个样本到各个聚类中心的距离,将对象分配到距离最近的聚类中;
③ 所有对象分配完成后,重新计算K个聚类中心;
④ 与前一次计算得到的K个聚类中心比较,如果聚类中心发生改变,转②,否则转⑤;
⑤ 当质心不再发生变化时停止并输出聚类结果。
这里选择残差平方和(residual sum of squares,SSE)作为度量聚类质量的目标函数,计算公式为:
(2)
簇Ei的聚类中心ei计算公式如下:
(3)
其中,K为聚类簇的个数,Ei表示第i个簇,ei表示簇Ei的聚类中心,ni表示第i个簇中的样本数,x为样本。
(2) 逆文档频率(tf-idf)
某个词项在文本集合的多篇文本中出现次数越多,该词项的区分能力越差。计算每一个词项的tf-idf值,通常采用如下公式进行计算:
tf-idf(wi)=tf(wi)×idf(wi)=
(4)
其中,tfj(wi)表示词wi在文本j中出现的频率,N表示文本总数,df(wi)表示文本集合中有多少个文档中出现了该词wi。本文统计并计算最常出现的200个词的tf-idf值,并利用这200个词为每个文本建立向量模型,通过计算向量间的余弦相似度确定文本间的相似性,最后进行聚类分析。
3 电影《战狼2》的网络舆情分析
3.1 实验环境
本文以Python3.5为工具进行数据的获取、预处理、建模与分析工作。实验环境如下:
操作系统:Windows10
处理器:2.50 GHz,双核
内存:4 GB
Python版本:3.5
Python环境:jupyter notebook
Python包:urllib, beatifulSoup, pandas, numpy, jieba, operator, WordCloud, matplotlib, nltk,re, SnowNLP, ggplot, genism, sklearn等
3.2 爬取数据
本文利用urllib与BeautifulSoup,从豆瓣网和新浪微博爬取用户对电影《战狼2》的评论,并将获取的数据保存为Excel格式。数据的属性包括8个:评论者名称(authorname)、评论时间(commenttime)、评论内容(content)、电影评分(score)、评论回复数(replyNum)、评论有用数(info)、评论无用数(nonInfo)。获取的部分数据内容格式如表1所示。

表1 部分数据内容表
3.3 数据清洗
首先,读取数据。由于数据为Excel格式,所以利用read_excel函数读取数据:
zl_data=pd.read_excel(′zhanlang.xls′,′zl_data′)
将数值型数据为空的值替换为0,或者用该列的平均值代替,实现如下:
zl_data.ix[:,[5,6,7]].replace(np.nan,0)
将非数据类型的列提取出来与上述处理过的列进行合并,删除重复评论和空评论行,最后将得到的新数据表进行索引重排:
zl_data_txt=zl_data.ix[:,[0,2,3,4]]
zl_data=pd.concat([zl_data_txt,zl_data_num],axis=1).drop_duplicates([′content′]).dropna()
zl_data=zl_data.reset_index(drop=True)
3.4 基于词云图的舆情可视化分析
通过可视化分析,发现观众的关注点及情感倾向。这里以词云图为例,展示舆情的可视化分析方法。词云图中显示的词越大则表示该词在评论中出现的频率越高,观众越感兴趣。词云图制作步骤如下:
(1) 数据转换。将上述数据DataFrame对象转换为python对象:首先遍历zl_data每行数据,然后对每行数据的评论列进行遍历并将其放入一个comment列表中,最后将comment列表的元素逐个写入txt文件中,作为本节的文本关键词提取、词云分析的舆情分析数据。
(2) 基于python实现文本关键词提取。提取文本关键词需要jieba中文分词库,利用textrank函数进行关键词提取,选出最重要的200个词,并对这200个词的权重进行排序,得到10个权重最高的词,依次为:电影(1.0),战狼(0.486),中国(0.458),吴京(0.355),没有(0.307),觉得(0.210),爱国(0.206),剧情(0.175),动作(0.174),美国(0.168)。
(3) 基于python实现词云图。通过关键词提取得到观众对该电影影评最重要的200个词,利用WordCloud制作词云图,matplotlib库用来可视化词云图,得到如图3所示词云图。

图3 评论词云图
从词云图可以看出,观众对这部影片的评论基本是正面的,电影、中国、爱国、吴京、国家、战狼、主旋律这些词出现在评论里的频率最高;电影、战狼、中国等话题是观众谈论的焦点。关于中国、爱国等一系列词语,体现了观众在爱国主义上引起了共鸣;同时吴京出现频率也较高,可见吴京的演技受到了观众的热议。
3.5 基于时间序列的舆情可视化分析
通过对电影评论做时间序列上的舆情分析,获取观众对这部电影随时间迁移的情感变化,并从评论中挖掘出观众对这部电影喜爱与厌恶的原因以及电影的卖点。
首先计算每个评论的情感分析数值。利用情感分析工具包SnowNLP分析计算,得到的结果取值范围在0到1之间,代表了情感分析结果为正面的可能性。通过计算得到更新后的数据,如表2所示的部分数据。从情感数值来看,观众对这部电影的评价总体上是正面的。但少量数据会造成结论的片面性,所以将所有评论的情感分析结果数值进行平均,使用mean()函数,结果数值高达0.9,这体现了该影片的口碑。

表2 部分数据情感数值表
然后观察其中位数,结果为0.99,这意味着该电影符合大多数人的偏好。但是也存在着极少数观众对该电影有很大的意见,产生了严重的负面评价,从而拉低了整体的电影口碑水平。
通过时间序列可视化功能,直观查看这些负面评价出现在什么时间,及情感数值低的原因。利用ggplot绘图工具包绘制关于时间序列的舆情分析数值图,如图4所示。

图4 关于时间序列的情感数值分析图
从图4中可以看出,很大一部分评论的情感分析数值很高,即大部分观众对电影有着正面的评价,表示对电影非常满意。但是,也发现有一些数值极低的点,即其对应的观众评论的情感倾向是负面的。利用sort()函数对情感分析数值进行升序排列,结果显示前5条评论的情感分析数值几乎为0,并且发现其对应的负面评价内容主要是对该电影剧情逻辑的批评,认为该电影的剧情毫无逻辑。利用tail()函数查看情感分析数值最高的几条评论,发现对应的正面评价内容主要是对电影具有的爱国主义及吴京演技为焦点进行评价的,基于此,可以了解到观众喜爱该电影的原因。由于这部电影的上映时间距建军节仅差3天,且接连不断的国家大事出现,使得大众的爱国情绪高涨,而这部电影刚好符合当时大众的心理,所以导致电影受到欢迎。
3.6 利用python进行文本聚类的舆情分析
通过对评论文本聚类,将不同话题的评论归入不同的簇,并在需要的时候建立新的簇,从而快速发现有用的信息,有助于了解网络舆情概况。
(1) 将原文本进行分词、去除停用词。此部分主要对评论进行去除非中文字符、分词+标注、去除停用词。首先使用正则表达式除去非中文字符,然后进行结巴分词和词性标注(需要用到jieba库),最后去除停用词[10-12]。
其步骤是:返回结果是一个Series对象,即每条评论的分词结果,实现如下:
import jieba.posseg as pseg
def proc_text(raw_line):
filter_patter=re.compile(′[^u4E00u9FD5]+′)
chinese_only=filter_patter.sub(′′, raw_line)
words_lst = pseg.cut(chinese_only)
meaninful_words = []
for word, flag in words_lst:
if word not in stopwords:
meaninful_words.append(word)
return ′ ′.join(meaninful_words)
(2) 统计词频。首先,将评论的分词变成列表对象;然后,将数据集中的所有单词放入到一个列表中并计算词频;最后,统计词频取出最常用的200个词,most_common(200)函数,部分结果如表3所示:
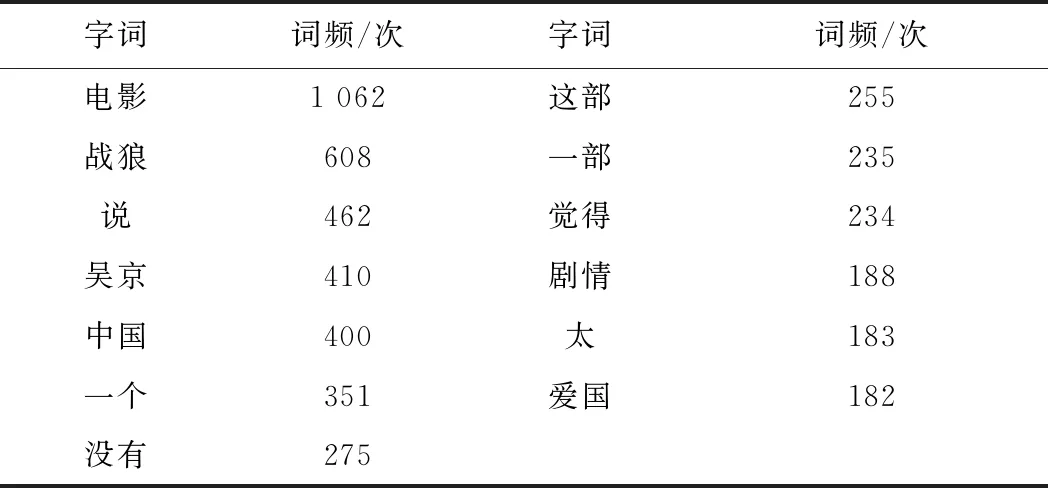
表3 最常用的部分词词频表
(3) 特征提取(tf-idf特征)。主要对评论进行特征提取。选用逆文档频率(tf-idf)进行特征提取[10],将每条评论向量化一遍后期聚类使用,定义一个特征提取函数,结果返回tf-idf矩阵,矩阵中行是评论数,列为200个常用词特征。
实现如下:
def extract_feat (text_df, text_collection,common_words_freqs):
n_sample = text_df.shape[0]
common_words = [word for word, _ in common_words_freqs]
tf_idf_X = np.zeros([n_sample, 200])
i=0
for r_data in text_df:
text = r_data
tf_idf_feat_val_list = []
if i <= n_sample:
for word in common_words:
if word in text:
tf_idf_val=text_collection
tf_idf(word, text)
else:
tf_idf_val = 0
tf_idf_feat_val_list.append(tf_idf_val)
tf_idf_X [i,:]=np.array(tf_idf_
feat_val_list)
i += 1
return tf_idf_X
(4) 计算评论文本间的相似度
计算评论间的相似度,直接使用python库中的函数cosine_similarity进行求解,得到相似度矩阵,其行列数均为评论条数。
(5) K-Means聚类原理及实现
实现过程中,利用sklearn的KMeans库,对上述产生的tf_idf矩阵进行训练,K取值10:
from sklearn.cluster import KMeans
num_clusters = 10
km = KMeans(n_clusters=num_clusters)
%time km.fit(tf_idf_X)
clusters = km.labels_.tolist()
利用 joblib.dump pickle 模型(model)对上述模型进行保存,起持久化作用:
from sklearn.externals import joblib
joblib.dump(km, ′comment_cluster.pkl′)
km = joblib.load(′comment_cluster.pkl′)
clusters = km.labels_.tolist()
选取n(n=10)个离聚类质心最近的常用词对聚类进行索引,得到如表4所示的结果:

表4 评论聚类结果表
由上述的聚类结果可知:聚类9中的关键词不错、情节、高等显示了该类中的观众对电影有着正面评价;聚类4中的关键词大都与爱国主义有关,这显示了该类中观众的关注点是该电影所具有的爱国主义情节;而聚类5、7中的关键词表示该类中的观众认为电影情节毫无逻辑性,对这部电影不太满意。
4 结语
本案例诠释了机器学习解决实际问题过程中的数据爬取、数据清理、特征提取、数据分析与处理的完整过程,通过对大数据环境下舆情分析的研究实现,使学生掌握如何使用机器学习方法从大量的无序数据中提取有用信息。该案例结合社会热点问题,体现课程特点,具有较好的深度和综合性,能帮助学生通过案例的学习,加深理解和掌握课程涉及的理论,并能在实际工作中正确应用。
猜你喜欢
中国农资(2019年44期)2019-12-03
铁道通信信号(2019年6期)2019-10-08
中国现代中药(2019年5期)2019-07-03
名家名作(2017年3期)2017-09-15
雷达学报(2017年6期)2017-03-26
消费电子(2016年12期)2017-01-19
中国民政(2016年16期)2016-09-19
中国民政(2016年10期)2016-06-05
互联网天地(2016年1期)2016-05-04
中国民政(2016年24期)2016-02-11
