
基于改进堆叠泛化算法的电信套餐预测
2019-07-12 06:13包志强胡啸天赵媛媛黄琼丹
西安邮电大学学报 2019年2期
包志强, 胡啸天, 赵 研, 赵媛媛, 黄琼丹
(西安邮电大学 通信与信息工程学院, 陕西 西安 710121)
电信套餐预测是指电信运营商根据资费套餐和用户的使用行为,掌握对某种套餐的偏好,根据用户历史消费信息预测消费者行为选择,为用户推荐合适的套餐产品[1]。为抓住电信市场机会,电信运营商提出了针对个人的精准预测分析策略,消费者也逐渐追求“一对一”的个性化套餐推荐服务[2]。个性化、智能化的电信套餐预测分析显得重要[3]。
目前,关于电信套餐预测方面的研究比较少,文献[4]从客户细分角度出发,运用聚类算法对客户进行了粗略的价值细分,与达到客户的精准化要求还有一定的差距[5]。文献[6]利用协同过滤推荐算法,实现用户到套餐及套餐到用户的推荐,但是单纯地利用套餐或用户之间的相似性进行套餐推荐,并没有实现对客户使用套餐种类的预测[7]。文献[8]通过分类和预测算法来建立套餐升级模型,由于套餐种类多,不能实现一一建模和对众多套餐变更的预测[9]。文献[10]将信息融合与数据挖掘相结合,根据不同客户群,采用不同算法构建电信客户流失预测模型,但是仅仅预测了客户是否流失,并没有实现对电信套餐种类的预测[11]。
为实现多种不平衡电信套餐的预测,本文拟采用合成少数类过采样算法(synthetic minority oversampling technique,SMOTE)[12]使套餐数量达到基本平衡,结合改进后的堆叠泛化(stacking)算法来实现电信套餐的两层分类,第一层被粗分为高低价值两种套餐中的一类,第二层在第一层预测结果条件下将套餐细分,实现对套餐的预测。
1 电信套餐预测及堆叠泛化算法
1.1 电信套餐预测
电信运营商为了吸引消费者,不断推出繁多的套餐服务种类,如201505天翼e家4G融合169元档系列中的B类30M 、H类50M和非光纤传输方式的套餐类型(简称非光纤类)8M套餐,使用某种挖掘算法进行分类,根据客户的实际套餐消费记录(即套餐流量、语音等属性)对客户使用的套餐种类进行预测[13]。但是在套餐种类预测过程中,产生了套餐多样性及不平衡性两个问题。套餐中的多样性问题是指分类任务中训练样例的种类繁多且复杂的情况。如201505天翼e家4G融合系列的套餐种类有6种,其中169元档的套餐有B类、H类、非光纤类3种,209元档的套餐有B类、H类、非光纤类3种。在种类繁多的数据集中,利用单个分类方法解决此问题时,分类器对多种套餐的预测不能达到良好的效果[15]。套餐中的不平衡性问题,是指分类任务中不同类别的训练样例数目差别很大的情况。如有2 092个用户使用169元套餐,只有327个用户使用209元套餐,训练样本时只需要返回一个,将新样本预测为169元套餐的学习器,就能达到99.8%的精度。这样的学习器不能预测出任何209元套餐,是没有价值的。因此,在此类不平衡问题的数据集中,利用传统的分类方法解决此类问题时,分类器的性能更加偏向于多数类样本,稀有样本往往被错分为多数类。
由于电信客户使用的套餐之间存在多样性及不平衡性,导致电信运营商对客户套餐的预测出现了困难[14]。为了解决电信套餐的预测问题,各种套餐之间存在的多样性及不平衡性是考虑的关键问题。
1.2 堆叠泛化算法的电信套餐预测
利用堆叠泛化算法[16]对电信套餐进行预测,通过组合多个分类器的结果来减小算法的泛化误差,实现电信套餐预测结果优越的泛化性能,其算法结构如图1所示。
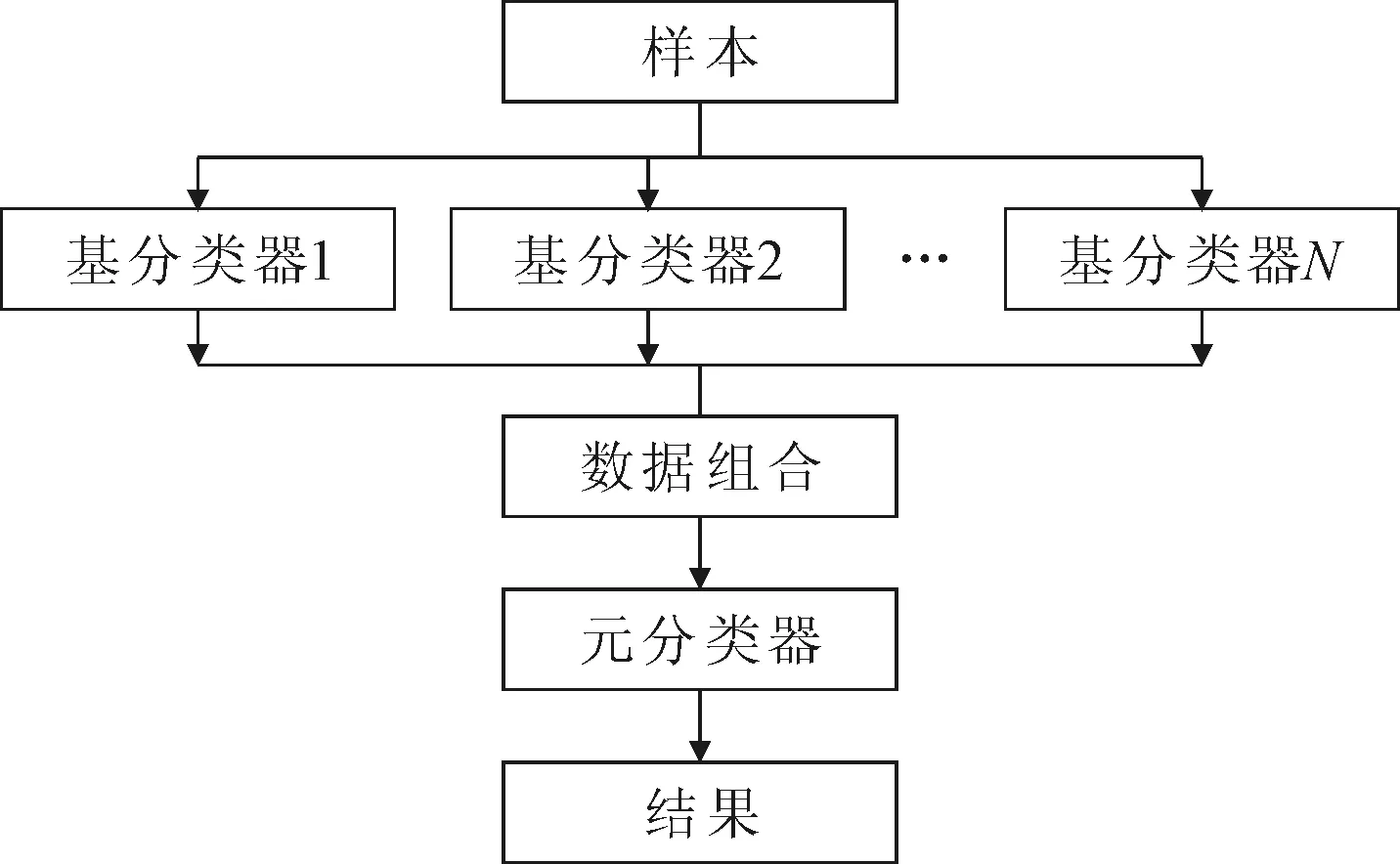
图1 堆叠泛化算法框架结构
在图1中,设N为基分类器的个数,n为输出结果的个数。堆叠泛化算法基于不同分类器算法产生多个异构分类器,一般为两层结构,在0层训练集上使用N个不同的学习算法,对应N个基分类器。同时,为了有效地避免过学习以及欠学习状态的发生,使用10折交叉验证[17],在整个数据集上得到n个输出结果,把n个输出结果作为1层分类器的训练集,训练一个分类器,对应一个元分类器。在1层训练集中并没有使用原始的输入属性,而是使用基分类器的输出标签作为输入属性,得到最后的分类结果。根据图1算法结构可以得到,一个输入样本,即一个电信客户的套餐属性集合,首先经过N个基分类器分类,输出N个套餐预测类别,然后将输出N个套餐预测类别进行数据组合,作为1层训练集,最后经过元分类器输出最终的套餐预测结果。此堆叠泛化算法在重构1层训练集时没有充分利用套餐属于不同类别之间的预测信息,忽略了输出信息的重要性和差异性,导致有些泛化效果明显下降。因此提出改进的堆叠泛化算法的电信套餐预测。
2 改进堆叠泛化算法的电信套餐预测
改进堆叠泛化算法是在原堆叠泛化算法基础上构建的,对每一类取所有基分类器的最大最小后验概率,并融合原数据集中某些特征作为1层新的输入向量,由1层分类器预测套餐的种类。
2.1 改进堆叠泛化预测流程图
基分类器的输出类型,可采用类概率的方式,与采用类标签作为新数据的属性方法相比,采用类概率的方式不仅有基分类器的预测值,还有置信度。采用类概率的方式输出的堆叠泛化算法,在生成1层特征值的个数时,利用每个基分类器对所有类预测的后验概率,容易造成维度过高,降低泛化的时间效率[18]。因此,针对电信客户套餐的预测,提出改进堆叠泛化算法。改进堆叠泛化算法套餐预测流程如图2所示。

图2 改进堆叠泛化算法套餐预测流程
改进堆叠泛化算法具体预测步骤如下。
步骤1设N为基分类器的个数,K为被预测的类别个数,i为基分类器的序数,输入样本X的第i个(i=1,2,…,N)基分类器的后验概率集合为
Ci(X)=[Pi1(X),Pi2(X) …PiK(X)]。
(1)
其中Pij(X) 表示每个输入样本X的第i个基分类器对类别j(j=1,2,…,K)输出的后验概率。
步骤2设m为样本的个数,由m个Ci(X)构成所有基分类器的后验概率,如表1所示。其中PNK(Xm)表示第m个输入样本X的第N个基分类器对类别K输出的后验概率。
步骤3改进堆叠泛化算法中对表1中的某个样本,每一个类别j取最大后验概率表示为
max[P(X)]={max[P11(X)P21(X)…PN1(X)],
…,max[P1K(X)P2K(X)…PNK(X)]}。
(2)
改进堆叠泛化算法中对表1中的某个样本,每一个类别j取最小后验概率表示为
min[P(X)]={min[P11(X)P21(X)…PN1(X)],
…,min[P1K(X)P2K(X)…PNK(X)]}。
(3)
步骤4在改进堆叠泛化算法中,由m个最大后验概率,最小后验概率构成的1层训练集,如表2所示。其中类别下的元素表示对某个样本X可能所属的各个类别,取所有基分类器的最大和最小后验概率,产生的特征值的个数为2×K。
步骤5由元分类器对1层训练集预测,输出套餐的预测类别。

表1 基分类器的后验概率

表2 基分类器输出的最大最小后验概率
改进堆叠泛化算法在1层分类学习中利用所有基分类器中对每一类预测的最大最小后验概率,重点考虑各个0层分类器中预测效果对最终判决的贡献信息,有效地降低了0层的预测维度。最大后验概率决定了该样本所属的类,而最小后验概率决定了该样本最不可能条件下所属的类,对于一个样本可能所属的某一类,选择两列具有明显差异的最大最小后验概率作为新的特征,融合样本的一些重要特征信息,使得元分类器可根据重要的输入信息来预测分类结果,在一定程度上控制了维度灾难,同时降低了重要信息损失的代价,有效的提升了预测的精度及整体效果。
2.2 预测步骤
针对电信套餐预测中的种类不平衡及多样性问题,提高电信套餐的预测精度,将电信套餐预测步骤分为数据预处理阶段和预测阶段。
2.2.1 数据预处理阶段

步骤1对于少数类中每一个套餐样本T,以欧氏距离为标准计算它到少数类套餐样本中所有样本的距离,得到其u近邻。
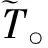
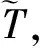
(4)
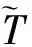
2.2.2 预测阶段
针对套餐类别种类多样性问题,预测算法阶段将采用改进堆叠泛化算法。为了提高整体的预测精度,将在改进堆叠泛化算法的基分类器和元分类器中,使用集成技术。集成技术通常由一组独立训练的同构分类器组成,在种类繁多及不平衡问题中,它能够组合各个弱分类器的分类结果提高元分类器的预测精度[19]。采用随机森林(random forest,RF)算法[20],极端梯度提升树(extreme gradient boosting,XGboost)算法[21],梯度提升树(gradient boosting decision tree,GBDT)算法[22],作为改进堆叠泛化算法中的基分类器,由XGboost算法作为元分类器输出最后预测类别,以提高电信套餐的预测效果。
3 实验结果及分析
针对西安市某公司2016年7月至10月4个月的电信客户的真实消费和缴费情况,选用201505天翼e家4G融合系列的6种套餐,套餐包含2 419条数据集,包括宽带时长、宽带网龄、宽带流量、近3个月宽带流量、累计欠费、欠费月份、欠费账龄、移动设备总流量、移动设备总语音、套餐名称、客户群、宽带接入层方式、4个移动设备的激活状态、4个移动设备的流量、4个移动设备的语音等24个属性。在改进堆叠泛化算法1层训练集中融合了宽带时长、宽带网龄、宽带流量等15个属性信息。在Windows7 IntelCore i3 2.40 GHZ的硬件环境下采用Python3.5平台实现改进堆叠泛化算法。详细套餐计数如表3所示。
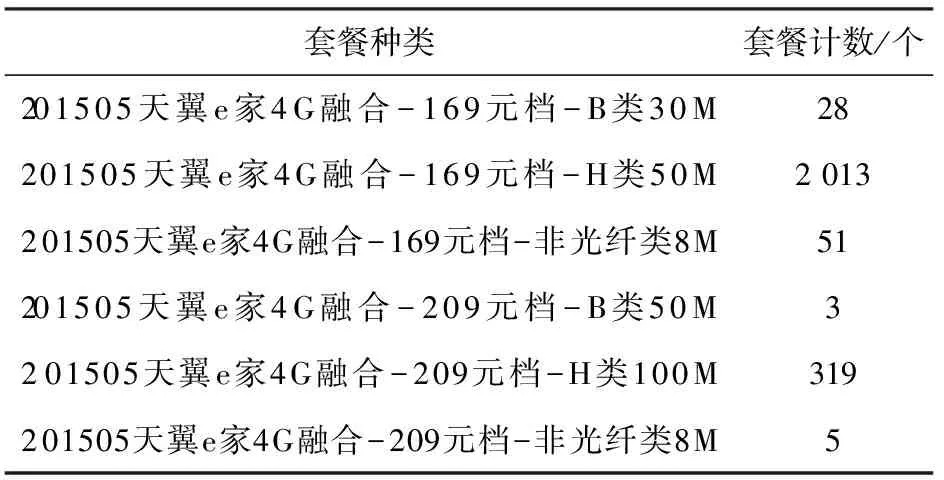
表3 201505天翼e家4G融合系列套餐的计数
对表3中的6种电信套餐进行预测,需将套餐进行两层分类,第一层预测用户的169元档和209元档两种高低价值选择,第二层在高价值或低价值套餐内进行套餐B类、H类、非光纤类3种套餐预测。
3.1 第一层预测指标对比分析
为了评估提出的改进堆叠泛化算法,使用正确率A、平均查全率R、平均查准率P、调和平均数F等4个指标[23]对预测效果进行评价。
第一层169元档和209元档二分类预测中,为了验证数据预处理阶段采用SMOTE算法后对堆叠泛化算法预测指标的影响,由实验所得堆叠泛化算法和采用SMOTE算法后的RF算法(SMOTE-RF)、采用SMOTE算法后的XGboost算法(SMOTE-XGboost)和采用SMOTE算法后的GBDT算法(SMOTE-GBDT)的效果比较,如表4所示。
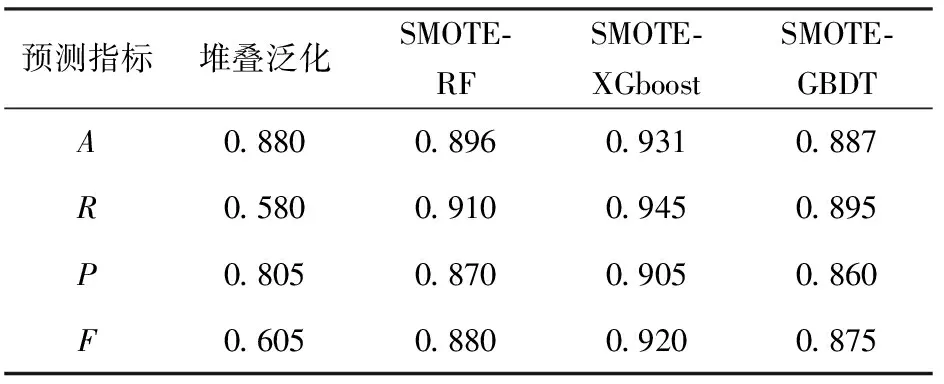
表4 第一层二分类堆叠泛化算法与SMOTE算法后基分类器算法效果比较
从表4中可以看出,对于不平衡数据集采用堆叠泛化算法,预测后的A为0.880,但R和F分别为0.580、0.605,说明套餐预测时更加偏重于套餐数较多的169元档,忽略了套餐数较少的209元档。采用SMOTE算法使169元档和209元档这两种套餐达到平衡时,SMOTE-RF算法、SMOTE-XGboost算法、SMOTE-GBDT算法3种基分类器的4个评价指标都得到提升,说明第一层数据预处理阶段采用SMOTE算法后各个基分类器能明显提高传统的堆叠泛化算法预测效果。尤其是SMOTE-XGboost算法中,指标A达到0.931,比传统堆叠泛化算法的A提升5.1%,说明基分类器中SMOTE-XGboost算法在2种电信套餐预测问题中效果最好。
第一层169元档和209元档二分类预测中,为了验证数据预测阶段采用改进后的堆叠泛化算法对堆叠泛化算法预测指标的影响,由实验所得堆叠泛化算法与采用SMOTE算法后的堆叠泛化算法(SMOTE -stacking)、基于后验概率且融合重要特征的堆叠泛化算法(P-stacking)、改进后的堆叠泛化算法(I-stacking)的效果比较,如表5所示。

表5 第一层二分类堆叠泛化算法与改进堆叠泛化算法效果比较
从表5中可以看出,SMOTE-stacking算法的4个评价指标,都高于堆叠泛化算法的4个评价指标,说明采用SMOTE算法能明显提升不平衡数据集的预测效果。P-stacking算法的预测效果要优于SMOTE-stacking算法,但是对套餐预测效果提升并不明显。改进I-stacking算法中,指标A达到0.954,比堆叠泛化算法A提升7.4%,说明采用改进的I-stacking算法,套餐效果相比堆叠泛化算法有明显提升。
3.2 第二层预测指标对比分析
第二层客户169元档套餐内B类、H类、非光纤类3类套餐预测中,为了验证数据预处理阶段采用SMOTE算法后对堆叠泛化算法预测指标的影响,由实验所得堆叠泛化算法和SMOTE-RF算法、SMOTE-XGboost算法和SMOTE-GBDT算法的效果比较,如表6所示。
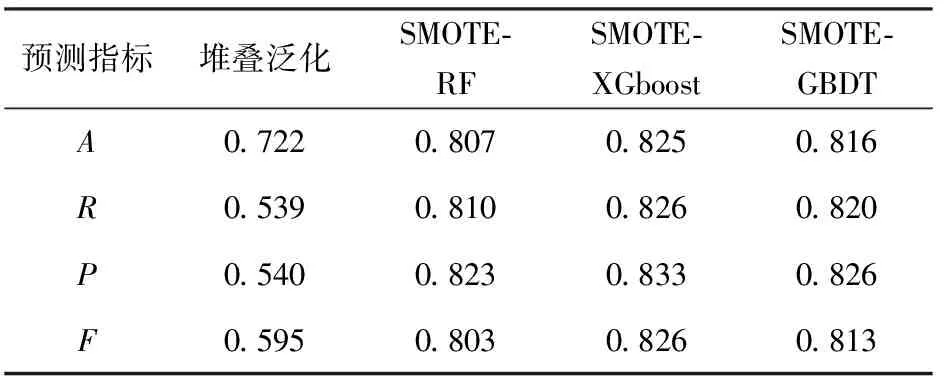
表6 第二层三分类堆叠泛化算法与SMOTE算法后基分类器算法效果比较
从表6中可以看出,对于不平衡数据集采用堆叠泛化算法后,R为0.539,P为0.540,F为0.595,这3个评价指标很低,说明对于第二层的3类套餐,堆叠泛化算法整体识别效果和区分效果较差。采用SMOTE算法使B类、H类、非光纤类3类套餐达到平衡时,SMOTE-RF算法、SMOTE-XGboost算法、SMOTE-GBDT算法3种基分类器的4个评价指标都得到提升,说明采用SMOTE算法能提升不平衡数据集的预测效果。SMOTE-XGboost算法中A达到0.825,比堆叠泛化算法的A提升9.4%,说明基分类器中SMOTE-XGboost算法在3种电信套餐预测问题中效果最好。
第二层客户169元档套餐内B类、H类、非光纤类3类套餐预测中,为了验证数据预测阶段采用改进堆叠泛化算法对堆叠泛化算法预测指标的影响,由实验所得堆叠泛化算法与SMOTE-stacking算法、P-stacking算法、I-stacking算法的效果比较,如表7所示。
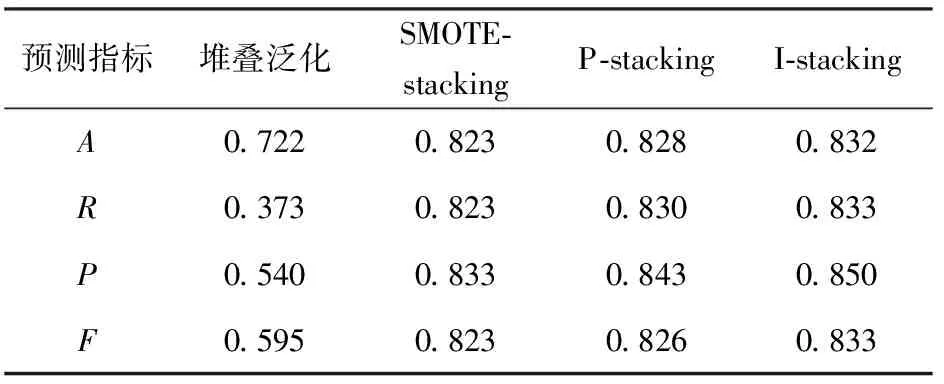
表7 第二层三分类堆叠泛化算法与改进堆叠泛化算法效果比较
从表7中可以看出,SMOTE -stacking算法的4个评价指标都高于堆叠泛化算法的4个评价指标,说明采用SMOTE算法能提升第二层不平衡套餐数据的预测效果。P-stacking算法的预测效果要优于Smote-stacking算法,提升并不明显。改进的I-stacking算法相对堆叠泛化算法,A提升11%,说明电信套餐预测效果有明显提升,且4个评价指标的效果更加稳定。
实验结果表明,在电信套餐预测中使用改进堆叠泛化算法,提高了少数类套餐预测的正确率,与SMOTE -stacking算法、P-stacking算法整体预测结果比较,改进堆叠泛化算法具有更优的效果,评价指标的效果更加稳定,可根据客户的消费行为实现电信套餐的预测。
4 结语
为了提升不平衡电信套餐分析中的整体预测效果,首先将套餐进行两层分类,第一层被预测为某一类,第二层在第一层分类结果中的条件下再将套餐细分,使用SMOTE算法来提高少数类套餐样本来达到套餐平衡;然后提出改进堆叠泛化算法,对每一类取所有0层分类器的最大最小后验概率,并融合重要的消费信息作为1层训练集,选择效果最优的XGboost算法作为元分类器预测最终的套餐种类。实验结果表明,改进后的套餐预测模型可实现多种不平衡套餐的预测。
猜你喜欢
小猕猴学习画刊(2021年6期)2021-08-05
幽默大师(2019年6期)2019-06-06
统计与决策(2019年6期)2019-04-22
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
雷达学报(2017年6期)2017-03-26
海峡姐妹(2016年4期)2016-02-27
南风窗(2015年7期)2015-04-03
郑州大学学报(医学版)(2015年2期)2015-02-27
航天返回与遥感(2014年5期)2014-07-31
