
Multi-Atlas Based Methods in Brain MR Image Segmentation
2019-07-12 10:02:40LiangSunLiZhangDaoqiangZhang
Chinese Medical Sciences Journal 2019年2期
Liang Sun, Li Zhang, Daoqiang Zhang*
1College of Computer Science and Technology, Nanjing University of Aeronautics and Astronautics, MIIT Key Laboratory of Pattern Analysis and Machine Intelligence, Nanjing 211106, China
2Department of Geriatrics, the Affiliated Brain Hospital of Nanjing Medical University, Nanjing 210029, China
Key words: multi-atlas; brain; segmentation; magnetic resonance
Abstract Brain region-of-interesting (ROI) segmentation is an important prerequisite step for many computeraid brain disease analyses. However, the human brain has the complicated anatomical structure. Meanwhile, the brain MR images often suffer from the low intensity contrast around the boundary of ROIs, large inter-subject variance and large inner-subject variance. To address these issues, many multi-atlas based segmentation methods are proposed for brain ROI segmentation in the last decade. In this paper, multi-atlas based methods for brain MR image segmentation were reviewed regarding several registration toolboxes which are widely used in the multi-atlas methods, conventional methods for label fusion, datasets that have been used for evaluating the multiatlas methods, as well as the applications of multi-atlas based segmentation in clinical researches. We propose that incorporating the anatomical prior into the end-to-end deep learning architectures for brain ROI segmentation is an important direction in the future.
B RAIN ROI segmentation is an essential prerequisite step for the computer-aid brain disease diagnosis. Accurate segmentation of brain MR images provides quantitative analysis of brain anatomical structures, which can be further used in pathology detection and brain disease diagnosis.1-5For instance, in the brain-network methods for brain disease diagnosis, the brain images are firstly segmented into multiple ROIs, then segmented images are used to construct the brain network for the subsequent analysis and brain disease diagnosis. In addition,the landmark based methods also need to segment some specific ROIs from the whole brain MR images for diagnosis of brain diseases. For example, according to prior knowledge that the hippocampus is related to the Alzheimer’s disease, the landmark based method for diagnosis of Alzheimer’s disease first locates the hippocampus in whole brain MR images, and then uses the located region for Alzheimer’s disease classification.However, it is time-consuming and error-prone for medical imaging experts to manually segment large number of brain MR images. Therefore, it is practical to develop automatic method for brain ROI segmentation.
Since MR images often suffer from low intensity contrast around the boundary of ROIs, large inter-subject variance and large inner-subject variance, as well as human brain has complicated anatomical structure,ROI segmentation with the brain MR image is a diffi-cult task for conventional machine learning methods.To solve these issues, multi-atlas based methods are proposed for brain ROI segmentation by using the anatomical prior of brain. The basic idea of multi-atlas is that the voxels should share the same label if they have similar local patterns or appearances. According to the basic idea, the multi-atlas based methods typically include two steps, 1) image registration, and 2)label fusion. In the step of registration, the atlas images are registered onto the common space of to-be-segmented image; in the step of label fusion, the label of voxels in atlases are propagated to the to-be-segmented image to determine the final label.
In this paper, we first present several registration toolboxes which are widely used in the multi-atlas methods, and describe some conventional methods for label fusion. Also, we introduce some datasets for evaluating the multi-atlas methods, as well as the applications of multi-atlas based segmentation in clinical researches. Finally, a brief conclusion is given in the Section Conclusion.
REGISTRATION
In multi-atlas based segmentation methods, the label fusion is based on the similarity of local pattern or appearance between the voxels in the to-be-segmented images and the candidate voxels in the atlas images. Hence, the segmentation performance of multi-atlas method relies on the image alignment results. In multi-atlas based segmentation method, the atlas images and to-be-segmented image are firstly registered onto the common space. The registration methods commonly include the affine registration and deformed registration. In this section, we present several widely used registration toolboxes in literature for multi-atlas based segmentation with brain MR images.
F MRIB’s Linear Image Registration Tool
FMRIB’s Linear Image Registration Tool (FLIRT)6,7in the FMRIB Software Library (FSL)a. https://fsl.fmrib.ox.ac.uk/fsl/fslwiki/8is an affine registration method, which provides a standard framework for MR images registration based on the image intensity. FLIRT can handle multi-modality medical image (e.g., functional MRI, structure MRI and PET).FLIRT uses the global optimization strategy for modifying the cost functions to down-weight voxels at the edge of the common overlapping field-of-view, and fuzzy-binning techniques for histogram estimation to reduce the local minimization value of the cost function. Hence, FLIRT is more efficient for searching the parameters, and further speeds the registration process. FLRIT provides many cost functions for optimization, such as normalized correlation, correlation ratio, mutual information, normalized mutual information and least square, etc.
ANTS Symmetric Normalization (SyN) algorithm9in ANTs Normalization Toolsb. http://stnava.github.io/ANTs/is a deformed registration method, which developed for the subject with the brain disease, such as frontotemporal dementia (FTD) and Alzheimer’s disease (AD). Hence, the ANTS Syn could process not only the normal subjects, but also images with large distance from the template images. The diffeomorphism is a differentiable map with differentiable inverse. The ANTS Syn restricts the proposed method into the diffeomorphic with homogeneous boundary conditions and assume the rigid and scaling transformations are factored out and the image border maps to itself. The proposed method uses the geodesic distance to obtain the shortest paths between subjects in the diffeomorphic space. The method aims to find a spatiotemporal mapping to maximize the cross-correlation between the pairwise images in the space of diffeomorphic, then use the Euler-Lagrange equations necessary to optimize the cost function.
Efficient non-parametric image registration method
Vercauteren et al. proposed an efficient non-parametric image registration methodc. http://www.insight-journal.org/browse/publication/15410based on the Thirion’s demons algorithm.11The non-parametric image registration can be seen as an optimization problem, which aims to find the displacement of each voxel to obtain an alignment of images. Vercauteren et al. introduce the diffeomorphisms into the demons algorithm to preserve the topology of the objects in the image and prohibit the physically impossible folding. Due to the diffeomorphic image registration method often suffers from the computational burden, the authors also introduced a non-parametric diffeomorphic method into the demons algorithm. Vercauteren et al. used the Newton methods for Lie groups to optimize the process of diffeomorphic image registration.
LABEL FUSION
The aim of multi-atlas based segmentation method is to segment the target images according to the anatomical priors from a set of atlas images. In last decade, many label fusion strategies12-40are proposed for prorogating the labels from atlases to determine the final label of the to-be-segmented image. In this section, we introduce several classic label fusion methods for segmenting the ROIs with brain images.
Major voting
Intuitively, the major voting (MV) strategy41can be used for determining the label of to-be-segmented voxel. Specifically, the MV adopts the label with the greatest number of labels at the same location of the to-be-segmented voxel in the atlases as the final label of the to-be-segmented voxel.
Locally-weight voting
As the simplest strategy, MV does not consider the similarity of the local appearance or pattern between the to-be-segmented voxel and the voxel in the atlas image. Based on the assumption that the voxels should share the same labels if the voxels have the similar local appearance or pattern, locally-weighted voting (LWV)14method propagates the labels on the atlas images at the same location of to-be-segmented by the weight sum strategy. Specifically, the similarity between the to-be-segmented voxel y and the voxel xiin the atlas image Aican be calculated as follows,
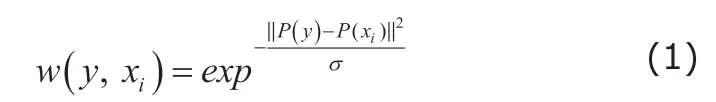
where P(y) and P(xi) are the vectorized intensity of local image patch, which sit at the center of voxel y and voxel xi. Also, the term σ=mixin‖P(y)-P(xi)‖+ε, where ε is a small constant to ensure numerical stability. Then,the LWV uses the calculated similarity as the voting weight to calculate the soft label of to-be-segmented by the weight sum,
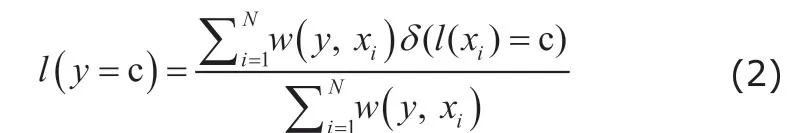
where δ(l(xi)=c) is a Dirac function, which equals to 1 when l(xi)=c and 0 otherwise. Hence, patches that are more similar to the target patch have greater voting weight. Finally, we use the maximum a posteriori (MAP)criterion to obtain the label of y,

Joint label fusion
Base on the Eq. (3), the similar patches on the atlases often have the similar voting weights, which increase the risk of the different atlases produce the similar label errors. To address this issue, the joint label fusion(JLF)25method is proposed for reducing the expectation of labeling errors between the pairwise atlases,

where wy={w(y,xi)|i=1,…,N}. Myis a matrix of expected pairwise joint label differences between atlas images and to-be-segmented image. In literature, the element My(i,j) in Mycan be calculated by the local image intensity information between two images to predict their label difference,

where v is a voxel belonging to the local region of the to-be-segmented voxel y. F*(v) is the intensity of the voxel . Hence, if both patches in the atlases have large intensity differences from the patch in the target image, the two patches are expected to produce different labels. Finally, use the learnt voting weight wyfor label fusion by Eq. (2) and Eq. (3).
Non-local mean patch-based method
Although the LWV and JLF consider the local pattern similarity between the to-be-segmented voxel and the voxel in the atlas image, JLF also considers the difference between atlas images.
The registration step often leads to the registration errors. To alleviate the possible registration errors, the non-local mean patch-based method (PBM)22is proposed for label fusion. As shown in Figure 1, the PBM propagates the labels not only from the voxel sitting in the same location of the to-be-segmented images in atlases, but also from its neighboring locations in the atlases. Specifically, PBM seeks multiple candidate patches from a certain region in each atlas for label fusion based on the pairwise similarity between the target and candidate patches within the certain region via
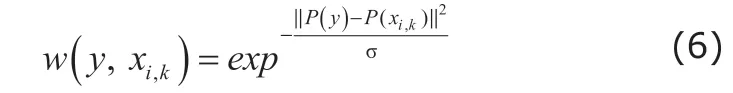
where xi,kis the k-th voxel in y’s neighboring region N(y) in the i-th altas image. Also, the term σ=mixin‖P(y)-P(xi)‖+ε. PBM uses the calculated pairwise similarity between the target patch and the selected candidate patch within the certain region as the voting weight to calculate the soft label of to-be-segmented by the weight sum,

where δ(l(xi,k)=c) is a Dirac function, which equals to 1 when l(xi,k)=c and 0 otherwise. Also, PBM obtain the final label of to-be-segmented voxel by Eq. (3).Due to the non-local strategy, the PBM can select the candidate patch in the atlases within the local regions of to-be-segmented voxel, and is more robust to the possible registration errors than LWV. Based on the non-local strategy, JLF also has been extended with non-local strategy.42Instead of only selecting the candidates at the same location of the to-be-segmented voxel, the extended JLF also selects the candidate patches within a certain region in atlases.
Sparse patch-base method
Sparse learning methods are widely used in the field of image processing, e.g. face recognition.43,44To take advantages of the sparse learning method, sparse patchbased method (SPBM)24is proposed for multi-atlas segmentation. In SPBM, the target patch is reconstructed by the linear superposition of the selected candidate patches in the atlas images with sparsity constraint,

where wy={w(y,xi)|i=1,…,N}. Myis the reconstruction coefficient vector, and D(y)=[P(xi,k)|xi,kϵN(y)] is a region-specific dictionary. The ||*||1is a l1-norm sparsity constraint, where λ controls the sparsity of the reconstruction coefficient vector wy. Due to the l1-norm constraint, only a small number of candidate patches in the atlas images with high similarity to the target patch will be selected for the subsequent label fusion process. Specifically, most of learnt reconstruction coefficients are zero. Then, the reconstruction coefficients are used as the voting weights to calculate the soft label of to-be-segmented voxel by Eq. (7) and get the final label by Eq. (3).
Other state-of-the-art methods
In the last decade, lots of label fusion methods are proposed. For example, several spare dictionary-based methods are proposed for label fusion.The sparse discriminative dictionary learning segmentation (DDLS) method28is proposed for segmenting MR images. In DDLS, the dictionaries and classifiers are learnt simultaneously based the atlases, and


Figure 1. Illustration of non-local strategies. The green and blue squares are target patch and the candidate patch, respectively. The blue boxes are the search region in the atlas images.

where P extract patches in the atlases image, D is the learned dictionary, and α sparse coding coefficient matrix.H is the labels of the central voxels of the patches in P, and W represents linear classifier. Finally, using the learnt dictionary and classifier for predicting the label of target voxel,

where lyis the label vector of the target voxel. Also, the MAP criterion is used to obtain the final label of y.
A multi-scale feature representation and label-specific patch partition hierarchical model is proposed for label fusion.32In this method, the patches are represented with multiple scale, also the patches are divided into multiple pattern based on the label map of patches. As shown in Figure 2, the vectorized patches are divided into two group based on the label,the new vectors use 0 to replace the intensity values,if the voxel not belong to the label. Then, a sparse dictionary model with -norm and -norm constraints are used for learning the voting weight. Moreover, an iterative hierarchical method is used for label fusion, which gradually reduces the size of the patches to learn the voting weight by using the patches with non-zero voting weights in the last learning process.
A progressive dynamic dictionary method is proposed for label fusion in a layer-by-layer manner.35Considering the gap between the image domain and the label domain, the authors use multi-layer dynamic dictionary to learn the representation of patches from image domain to label domain. As shown in Figure 3,this method uses a set of intermediate dictionaries to represent the image patches. By a sequence of intermediate dictionaries, the gap between the image domain and the label domain is reduced gradually. Finally, the method used the latest leant intermediate dictionary to learn the voting weights for determining the final label of the to-be-segmented images. Notably, this method can be extended by most of multi-atlas methods.
A deep dictionary learning method is proposed for multi-atlas.36The authors convert the conventional dictionary into a deep tree-like structure. Figure 4 shows a deep tree-like dictionary that consists of the candidate patch in the atlases. Specifically, the patches from the atlas are first divided into several groups based on the label of the center in the image patch.Then, a hierarchical k-means method is applied for each group to construct the remaining tree-like structure. Finally, the constructed deep tree-like dictionary is used for learning voting weight to determine the label of to-be-segmented by a hierarchical sparse patch label fusion.
In recent years, the deep learning methods achieve the success in many fields. The main advantage of the deep learning method is that it learns the feature representation from data without any pre-defined rules. Hence, several methods introduce the deep learning technique for learning the feature representation of image patch, and then use these learnt features for calculating the voting weight and label fusion. For instance, a high-order Boltzmann machine45is introduced for learning the high-order representation of image patch.37As shown in Figure 5, the high-order Boltzmann machine consists of two hidden units, i.e.,the mean hidden units and covariance hidden units.Mean hidden units represent the mean intensity information of the image patch, while the covariance hidden units denote pair-wise dependencies information among voxels in the patch. In the training stage, the mean-covariance restricted. http://adni.loni.usc.edu/Boltzmann machine (mcRBM) is trained based on the sampled image patches in the target images and atlas images. Then, in the segmentation stage, the patches are first represented by the mean feature and the covariance feature, then using these learnt high-order features for label fusion.

Figure 2. The illustration of the label-specific atlas patch partition.

Figure 3. The framework of progressive dynamic dictionary based label fusion.
Also, the deep neural network is used for learning the representation of patches.41As shown in Figure 6,this method extracts patches around the boundary of ROI, then uses the sampled image patches to train the neural network. Meanwhile, to learn the discriminative feature of the image patches, the deep neural network model also includes a discriminative term for making the learnt features discriminative for label fusion. In the test stage, the target patch in the target image and candidate patches in the atlas images are firstly converted to the learnt feature space by the learnt network, then the learnt features are used to calculate the voting weights for label fusion.
DATASETS AND EVALUATION MATRICS
There are several datasets that have been widely used in the study of multi-atlas based segmentation for brain ROI segmentation. We give a brief introduction of these dataset and also illustrate the evaluation metrics for assessing the segmentation performance of brain ROIs. Finally, we summarize the evaluation results of the state-of-the-art methods on the ADNI dataset.
Alzheimer’s Disease Neuroimaging Initiative(ADNI) dataset
The ADNId. http://adni.loni.usc.edu/dataset46includes 1.5T structural MRI and 3T structural MRI for hippocampus segmentation.There are three types of subject in the ADNI dataset,i.e., the Alzheimer’s disease (AD), the mild cognitive impairment (MCI) and the normal control (NC).

Figure 5. The pipeline of the High-order Boltzmann machine-based unsupervised feature learning for multi-atlas segmentation.

Figure 6. The pipeline of deep discriminative neural network-based label fusion.
Non-rigid Image Registration Evaluation Project(NIREP) dataset
NIREPe. http://www.nirep.org/dataset47consists of 16 T1-weighted brain MR images, acquired from 8 normal male adults and 8 female adults. These MR images were obtained in a General Electric Signa scanner operating at 1.5 Tesla, using the following protocol: SPGR/50, TR 24ms, TE 7ms, NEX 1, matrix 256x192, FOV 24 cm. In this dataset, each MR image has been manually segmented into 32 ROIs.
LONI Probabilistic Brain Atlas (LPBA40) dataset
The LPBA40f. www.loni.usc.edu/atlases/dataset48is provided by the Laboratory of Neuro Imaging (LONI) at UCLA. This dataset contains 40 brain images, and each image has 54 manually labeled ROIs. Specifically, these labeled ROIs were created manually to annotate brain structures of images in the LONI-LPBA40 dataset, and all MRI volumes were rigidly aligned to the MNI305 template.49
IXI
The IXIg. http://brain-development.org/brain-atlases/adultbrain-atlases/dataset provides three type adult brain atlases, i.e., 30 subjects with 95 regions, 20 subjects with 83 regions and 20 subjects with 67 regions.
There are two common evaluation metrics used in assessing performance of segmentation. Specifically,the Dice ratio (DR) measures the performance of segmentation as follows:
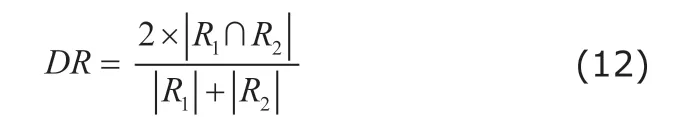
where the ∩ denotes the overlap between automatic segmented regions R1and ground truth of region R2, and |·| denotes the number of voxels belonging to each ROI. The DR measures the degree of overlap between the segmented label map of image and the ground truth. The high value of DR can provide more precise quantitative of brain ROI volume.
Average surface distance (ASD) is also used to measure the performance of segmentation algorithms.

where d (·, ·) measures the Euclidean distance, and n1and n2are the numbers of vertices in surface S(R1)and surface S(R2), respectively. The ASD reflects the morphology similarity of between the segmented label map of image and the ground truth.
Based on the same dataset, performance of methods for segmenting brain MR images can be accessed with the above metrics. Table 1 shows the performance assessment results of the Dice ratio and average surface distance of the state-of-the-art methods using ADNI dataset for hippocampus segmentation. JLF25considers the relationship between difference atlas,and reduces the possible risk of similar images. Hence,compared with LWV, JLF achieves better performance for hippocampus segmentation. Also, for the DDLS,28leveraging the discriminative terms, it achieved better results than SPBM. The hierarchical model with multiscale feature and label-specific patch partition32reflects that using the multi-scale features and label information is helpful for multi-atlas segmentation. Progressive multi-atlas label fusion method35shows that reduce the gap between image domain and label domain will increase the power of multi-atlas segmentation. The deep dictionary method36uses deep tree-like dictionary to hierarchically organize the patch, and improve the representation power of sparse representation. The deep learning method38also shows that using the learnt deep features will improve the segmentation performance of multi-atlas segmentation methods.
APPLICATIONS AND PERSPECTIVES
Segmentation is an important prerequisite step for medical image analysis. The multi-atlas based brain MR image segmentation aim to segment the whole brain into multiple ROIs and provide quantitative analysis of brain MR image. Makropoulos et al.50segmented neonatal brain MR images into 50 ROIs based on multiple atlases, which provided a quantitative analysis of anatomical structure for subsequent researchANDI, Alzheimer's disease neuroimaging initiative;DR, dice ratio; ASD, average surface distance.on the development of neonatal brain. Aljabar et al.51segmented brain MR images via multi-atlas based segmentation method, then extracted the morphology features of brain anatomical structures based on the segmentation results, which were used in diagnosis of dementia. Additionally, the multi-atlas segmentation method is often applied in single ROI segmentation.For example, the hippocampus is related to the Alzheimer’s Disease (AD). Hence, to explore the relationship between the hippocampus and the AD, Pipitone et al.52proposed a multi-atlas segmentation method for hippocampus segmentation by using few atlases, and provide a quantitative measurement of hippocampus.

Table 1. The performance assessment results of the state-of-the-art methods on ADNI dataset for hippocampus segmentation
During the last decade, a great amount of multi-atlas based methods have been proposed for brain ROI segmentation. The previous works have demonstrated that using the anatomical prior knowledge could help to segment the brain images which contain complicated structure, low intensity contrast around boundary of ROIs, large inter-subject variance and large inner-subject variance. However, the main disadvantage of multi-atlas based methods is the high computational cost. The voxel-by-voxel segmentation is very time-consuming for the high-dimension brain MR image, especially in the dictionary-based methods.The dictionary-based methods often construct the region-specific dictionary for each to-be-segmented voxels, which is very time-consuming.
In recent years, the deep learning methods have achieved great success in many fields. Although the deep learning methods are used in brain ROI segmentation, there are more researches that using the deep neural networks for learning the feature representation of the patches,37,38or use the patch-based network53to predict the label map of patches directly. Hence, these methods also encounter the time-consuming issue.Meanwhile, due to the complicated structure of brain and the low intensity contrast around the boundary of ROI in brain MR images, the patch-based networks do not achieve a competitive result when compared with the multi-atlas methods. In the future, incorporating the anatomical prior into the end-to-end deep learning architectures, i.e., fully convolutional networks,54,55for brain ROI segmentation is an important direction.
Conflict of interest disclosure
All authors declared no conflict of interests.
 Chinese Medical Sciences Journal2019年2期
Chinese Medical Sciences Journal2019年2期
- Chinese Medical Sciences Journal的其它文章
- Integrative Analysis Confirmed the Association between Osteoprotegerin and Osteoporosis
- A Survey of Surgical Patient’s Perception about Anesthesiologist in a Large Scale Comprehensive Hospital in China
- Medical Knowledge Extraction and Analysis from Electronic Medical Records Using Deep Learning
- A Survey on Intelligent Screening for Diabetic Retinopathy
- Application of Mixed Reality Technology in Visualization of Medical Operations
- Constructing Large Scale Cohort for Clinical Study on Heart Failure with Electronic Health Record in Regional Healthcare Platform: Challenges and Strategies in Data Reuse