
一种改进的整机系统实时功率建模方法
2019-07-09 11:57:48杨良怀戚加欣范玉雷
小型微型计算机系统 2019年7期
杨良怀,戚加欣,徐 卫,范玉雷
(浙江工业大学 计算机科学与技术学院,杭州 310023)
1 引 言
能效是现代数据中心的重要议题[2],而峰值功率是数据中心的一个重要因素,对峰值功率的封顶控制是相关研究的热点问题之一[3-6].本文针对其中的整机功率感知问题开展研究.
通常有两种获取实时功率的方法:物理测量和软件评估.使用仪器来测得功率较为精确,但其成本高;软件评估灵活、成本低,且功率与系统状态关联的特性可以用于优化功耗敏感的系统或程序.但后者需要解决测得功率的准确度,以及额外资源、功耗开销的问题.
在计算机系统中,处理器、内存与磁盘是最主要的耗能部件,且随着部件负载量的增加,其功率占比也随着提高.本文基于这三个部件来构建整机实时功率模型.本文的贡献在于不仅利用硬件性能事件和部件利用率,同时利用处理器C-States来构建通用型的整机系统实时功率模型.其主要思想是利用CPU性能事件与功耗之间存在的内在联系构建功率模型,通过特征选择算法选取模型的性能事件子集,依据不同C-States状态把处理器和内存部分的实时功率分为两个阶段:高功耗状态与低功耗状态,分别建立功耗模型;基于利用率构建磁盘的功率模型;结合两者构建整机功率模型.实验结果表明所提方法明显提高了功耗计算准确性.
2 相关工作
从带有一组性能计数器的奔腾系列起,英特尔引入了性能监控机制,并在之后不断完善该机制,同时增加新的性能监控事件,研究人员可通过这些计数器获得更为全面且详细的架构信息和性能事件,从而构建功率模型.
Bellosa[7]最先利用整数操作、浮点数操作、二级寻址和内存访问性能事件计数与功率近似线性相关进行建模;但其性能事件的选择方法、模型的准确性都有待提升.
Isci等[8]为奔腾4处理器分成22个子单元,分别为每个子单元选择合适的事件构建功率模型.Bertran[9]定义了超过25个处理器微架构组件,最终选择了处理器前端(FE)、整数单元、浮点数单元、SIMD算术单元、分支预测和执行单元、一级缓存、二级缓存、前端总线(FSB)这八个处理器微架构组件,共使用20个性能事件,基于处理器组件的活跃比例,针对不同DVFS配置分别构建了单核和多核的处理器功率模型.不同处理器架构中,性能计数器的可访问性和可用程度均有差异;为此,Rance等[10]寻找出可被任意处理器架构使用的性能事件子集,且使用该子集所构建的功率模型具有良好的准确性.所建模型中,最多的使用了6个性能事件,最少使用了1个性能事件,相对误差在4%~13%之间.刘辛等[11]通过筛选处理器的硬件事件对多核处理器进行功耗建模,使用逐步多元线性回归分析建立实时功耗模型.利用PARSEC和SPLASH2基准测试程序集对模型进行了验证,估算误差分别为3.01%和1.99%.不同于本文整机功率建模,以上模型均是处理器功耗模型,整机系统中则涉及CPU外围电路、磁盘、主板其他部件等功率;由于其他部件不像CPU有许多可用性能事件来表征功耗,整机功耗模型的构建有一定挑战性.
Bertran[12]等人将基于计数器的建模方法分为两种类型:自顶向下和自底向上.这两种方法的主要区别在于对计数器的选择.自顶向下构建的模型平台移植性较强,模型也相对简单;而自底向上功率模型对平台的依赖性较强,移植性较差,复杂度相对高,但模型更为准确.本文提出的模型综合两种方法的优点,通过特征选取,选择最合适的硬件性能事件,简化了模型,缩短了训练时间,便于模型被理解,也改善了通用性、降低过拟合的可能.
Zhu[13]等讨论了非线性回归方法模型在功耗模型上的应用,与多变量线性方法相比,非线性回归方法仅具有轻微的准确性优势,但其需要更长的训练时间以及具有较差的可移植性.Powell等[14]利用运行时微处理器在内核以及微架构中的独立结构的功率消耗以及各个部件活跃度进行功率建模.但在实际应用中,由于商用处理器和模拟器之间的细微差别,以及不同处理器之间的微小差异,难以用模拟器精确地描述实际系统.
本文结合性能事件与部件利用率,同时利用CPU的功耗状态来构建整机功率模型,并与传统模型进行比较.
3 功率模型的理论分析
3.1 影响CPU功率的因素
处理器的功耗与负载相关,处理器的负载状态可以通过计算处理器的利用率近似获得,也可以使用处理器的性能计数器监测处理器内部的性能事件更为精确地获得.现代的处理器芯片都提供性能计数器,CPU性能计数器或性能监控单元(PMU)是可以计数低级CPU活动的特定模块寄存器(MSR).通常包括下列计数器:CPU周期,CPU指令,L1、L2、L3缓存访问,浮点单元,内存I/O,资源I/O.与功率相关的事件包括:执行指令数、分支预测单元、指令周期(cycle)、高速缓存缺失、处理器暂停、页表缓存缺失、每周期指令数(IPC).可以通过获取UNHALTED-CORE-CYCLES和INSTRUCTIONS-RETIRED来计算得到每周期指令数IPC,公式如下:
(1)
3.2 影响内存功率的因素
内存功耗包括背景功耗、操作功耗、读写功耗和I/O功耗.背景功耗描述了没有存储器访问时DRAM芯片的功率.操作功耗指DRAM芯片上电时执行预充电操作的功耗.当数据被读出或写入芯片时,读写功耗被消耗.最后,I/O功耗是用于驱动数据总线的功耗,现有的内存功率模型研究发现影响内存消耗的主要因素是内存读写吞吐量[16].因此,想要知道内存消耗的功率,除了直接通过仪器测量,也可以通过内存的读写吞吐量建模获取内存实时功率.内存本身并不是一个高能耗的组件,单独的SDRAM芯片的功耗取决于很多因素,包括速度、使用类型、电压等.4G大小的DDR3/1600 DIMM的内存功率一般为2W~3W,此外还有功耗更低的DDR3L、DDR4内存.但是在服务器上,由于使用的内存条数较多,内存功耗也比较可观.
3.3 影响磁盘功率的因素
磁盘功率也是整机功耗的重要部分,特别是一些服务器拥有数目众多的磁盘.磁盘功率主要由驱动盘片旋转的电机功率、磁头驱动电路和逻辑电路部分功率组成.当磁盘没有读写时,电机和逻辑电路仍然需要消耗电力来维持磁盘的运行,这部分功率被认为是恒定的.当磁盘空闲时,磁头不寻找,一旦有读写操作,磁头开始寻道并开始读写盘片,逻辑电路同时开始处理并传输数据,这部分功率随着不同的I/O操作而变化.一般来说,磁盘的利用率越高,功率就越高.
4 整机功率建模过程
4.1 基于利用率的整机功率模型PM1
整机系统功率(P)由两部分组成:静态功率(Pstatic)和动态功率(Pdyn).因此有:
P=Pstatic+Pdyn
(2)
本文主要考虑CPU、磁盘和内存这三个部件,动态功率由这三部件在系统有负载运行时额外产生的功率:
Pdyn=Pcpu+Pdisk+Pmem
(3)
注意,Pcpu、Pdisk、Pmem是指相应部件的动态功率部分,静态功率全部记入Pstatic中.
能耗是功率与时间片乘积的积分,如果时间Δt时间片足够小,可以看作功率与时间的乘积.在时间Δt内,CPU、磁盘和内存分别运行了Δt1、Δt2和Δt3秒,则在这段时间Δt内,系统消耗能量P×Δt,这些部件消耗的动态能量分别为:Pcpu×Δt1、Pdisk×Δt2和Pmem×Δt3.故有:
P×Δt=Pstatic×Δt+Pcpu×Δt1+Pdisk×Δt2+Pmem×Δt3
(4)
等式两边同除时间Δt,得到式(5):
(5)
根据组件的利用率定义,Ucpu=Δt1/Δt表示CPU在时间Δt内的使用率,Udisk=Δt2/Δt表示磁盘的利用率,Umem=Δt3/Δt表示内存的利用率.代入式(5)得到:
P=Pstatic+Pcpu×Ucpu+Pdisk×Udisk+Pmem×Umem
(6)
将式(6)中Pcpu用α代替,Pdisk替换为β,Pmem替换为γ,并用S替换静态功率Pstatic,得到功率模型(7)式.
P=S+α×Ucpu+β×Udisk+γ×Umem
(7)
对于CMP单芯片多处理器,假设有n个内核,每个内核记为ci,i∈[1,n];最后得到如下的模型原型:
(8)
其中S为待测机的静态功率,Uci表示第i个执行核的利用率.假设各个核的执行能力等价,则可以认为每个核所对应的系数αi相等,记为α.公式(8)即变为
(9)
称为模型PM1,其中系数S、α、β和γ由多元线性回归模型训练得到.
4.2 基于性能事件、C-States与利用率的整机功率模型
4.2.1 性能事件选择
由于系统中的所有活动都会产生一定的能量消耗,因此任何与之相关的性能事件都可以作为功率模型的输入参数.一般情况下,处理器都会提供至少几十个性能事件,选取合适的性能事件是构建功率模型面临的首要问题.如果选择的性能事件过多,会导致模型过分复杂,开销大,并且不利于模型移植到其他平台,因为选择的性能事件多了,涉及到的非架构兼容性的事件可能性也大了.反之,性能事件过少,信息不够完全,可能不足以用来反映功率.同时也需要考虑性能事件之间的关联性和性能事件存在冗余的情况.
同时,当监测的性能事件个数超过性能计数器个数时,通过使用时分复用,以便每个事件都有机会访问监视硬件.在运行结束时,根据总的计数启动时间与运行时间来缩放计数值.最终输出的计数值为:
Cfinal=Craw*Tenabled/Trunning
(10)
其中Cfinal为最终输出的计数值,Craw为实际性能计数器获取的计数值,Tenabled为性能计数器总的计数启动时间,Trunning为性能计数器的运行时间.可见,监测的性能事件越多,则每一个事件进入性能计数器的时间越短,而最终缩放得到的计数值越不准确,而数据的准确性直接影响模型的准确性.因此不能将所有的预定义事件进行监测,而应当选择适当的性能事件.
如何选择用于建模的性能事件.首先本文通过公式(11)计算每个性能事件与功率之间的相关系数,即皮尔逊相关系数,计算所得的相关系数越接近0,表示两者的相关性越差;越接近1,表示两者的正相关性越好;越接近-1表示两者的负相关性越好.约定皮尔逊相关系数绝对值小于0.3时相关性低,排除与功率相关性低的事件.
(11)
从剩余的性能事件中选取与功率密切相关的性能事件,得到用于建模的性能事件的初步选择范围.利用数据挖掘工具Weka进行属性选择,使用子集评估器CfsSubsetEval和搜索算法BestFirst选择性能事件集.在皮尔逊相关系数的基础上进一步使用子集特征选择,是因为皮尔逊相关系数在特征选择中属于过滤(filter)方法,它关注单个特征属性与目标属性的相关性,没有考虑特征之间的相关性,可能存在冗余的特征;另外,某些属性的组合可能达到最佳的回归效果.目标是使选择的性能事件数与CPU提供的性能计数器数目大体一致,当搜索算法BestFirst的搜索方向选择为向后,指定在终止搜索之前允许的连续非改进节点的数量为8时满足目标,得到建模所用到的预定义性能事件如表 1所示,表左侧为perf提供的预定义事件,表右侧为预定义事件在Haswell架构处理器中对应的原生事件.英特尔在性能计数器中没有包含明确的事件来区分对LLC的访问,对于表格中的OFFCORE-RESPONSE原生事件,使用DMND-DATA-RD请求类型计算加载未命中数,通过设置MSR寄存器的Response Supplier和Snoop Info字段,可以区分缓存命中和失败[注]64-ia-32-architectures-optimization-manual[EB/OL]. http://www.intel.com /content/www/us/en/architecture-and-technology/64-ia-32-architectures-optimization-manual.html. 2017 Nov..
表1 建模所用到的性能事件
Table 1 Performance events used in modeling
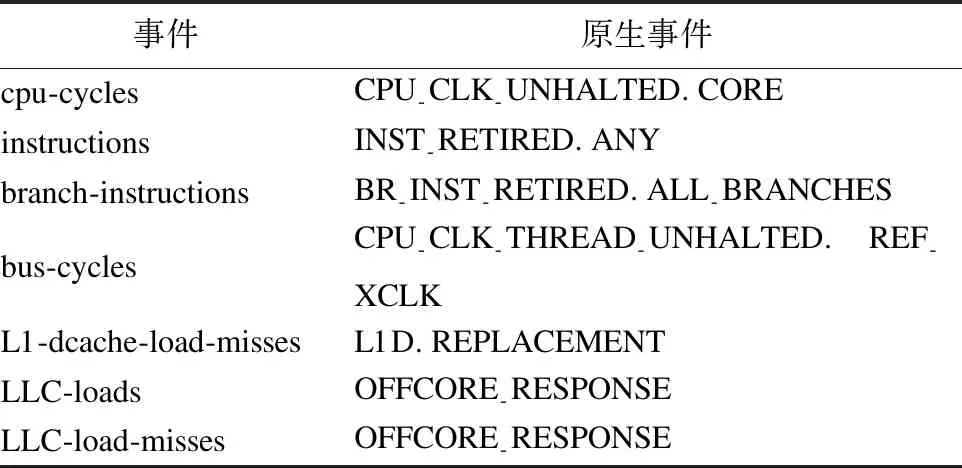
事件原生事件cpu-cyclesCPU-CLK-UNHALTED.COREinstructionsINST-RETIRED.ANYbranch-instructionsBR-INST-RETIRED.ALL-BRANCHESbus-cyclesCPU-CLK-THREAD-UNHALTED.REF-XCLKL1-dcache-load-missesL1D.REPLACEMENTLLC-loadsOFFCORE-RESPONSELLC-load-missesOFFCORE-RESPONSE
4.2.2 处理器与内存功率模型
由于内存相关性能事件功率在整机功率中所占不大且变化不明显(在下文所进行的实验中,内存所占功率为整机功率的2%以下,内存功率标准差为0.38W),因此,本文把处理器和内存作为一个整体考虑,即
(12)
其中n为处理器核数,向量ωi为每个处理器核每个性能事件对应的待估参数向量,X为所选择的性能事件计数向量,S为常量.假设各个核的执行能力等价,那么可以认为每个核所对应的系数ωi相等,记为ω,令向量α表示nω.公式(12)可进一步简化为:
Pcpu+Pmem=S+αTX
(13)
目前的处理器利用CPU功耗状态C-States描述处理器当前的功耗和热管理状态,具体可分为C0到C*(*为整数,取决于CPU类型),代表当核心空闲时可以进入的睡眠级别.C0状态下CPU正常运行;CPU运行于更高的C状态意味着消耗更低的功率,但从此状态返回到C0需要更长延迟.处理器只有在空闲状态下,才有可能进入非C0的C-States.ACPI规范描述了C0-C3,但最近的CPU支持更多的C状态.以Haswell架构的桌面Intel处理器为例,其拥有的各个C-States如表 2所示.
当处理器处于空闲状态时,大部分时间都处于最深的C-States.Linux的内核启动参数intel-idle.max-cstate可以控制处理器可进入的最深C-States,通过设置不同的intel-idle.max-cstate参数,可得如图 1所示的C-States与CPU功率的关系.可见,同样在空闲状态下,当处理器处于不同的C-States时,其所消耗的功率不同,在实时功率建模过程中引入C-States十分有必要.需要注意的是,由于Linux内核的限制,当允许进入最深的C-States为C6时,实际已经启用C7,此时CPU大部分时间实际处于C7状态.
在采样间隔内,进入深层C-States的次数越多,处理器在该时间段的功率就越低.可以把处理器与内存功率分为两段,第一个阶段为高功耗状态,此阶段中在每个采样间隔内处理器基本都处于C0状态,处理器与内存的功率模型只需要使用各个性能事件计数作为参数;第二个阶段为低功耗状态,此阶段中在每个采样间隔内处理器有一定几率进入深层C-States,所以处理器与内存的功率模型除了使用性能事件作为参数,还需要使用各个C-States的计数作为额外的模型参数.在实验中,本文进行计数的C-States为C3、C6、C7.根据以上分析,可以进一步细化公式:
(14)
其中,C3,C6,C7=0表示处理器处于C0状态,这时处理器处于高功耗状态,而“其他”表示处理器有一定几率进入深层C-States,处理器有几率进入低功耗状态;S1、S2是模型在不同阶段相应的待估常量,用于反映静态功率;向量α1、α2为模型不同阶段对应的待估参数向量;参数向量X1、X2为模型不同阶段所选取的性能事件的计数,两者有所不同,如下所示:
待估系数通过多元线性回归方法获得,由此构建了基于性能事件与C-States的处理器和内存实时功率模型.
4.2.3 整机功率模型
据前述,整机功率由静态功率和动态功率组成,静态功率由功耗仪测量所得,动态功率主要考虑处理器、磁盘和内存执行任务时额外产生的功率.由公式(9),磁盘功率为待估系数乘以磁盘的利用率βUdisk.因此,结合公式(14),最终整机功率可以表示为:
(15)
待估系数也是由多元线性回归方法获得.基于性能事件、C-States和部件利用率所构建的整机实时功率模型称为PM2.
表2 C-States各个状态
Table 2 C-States states
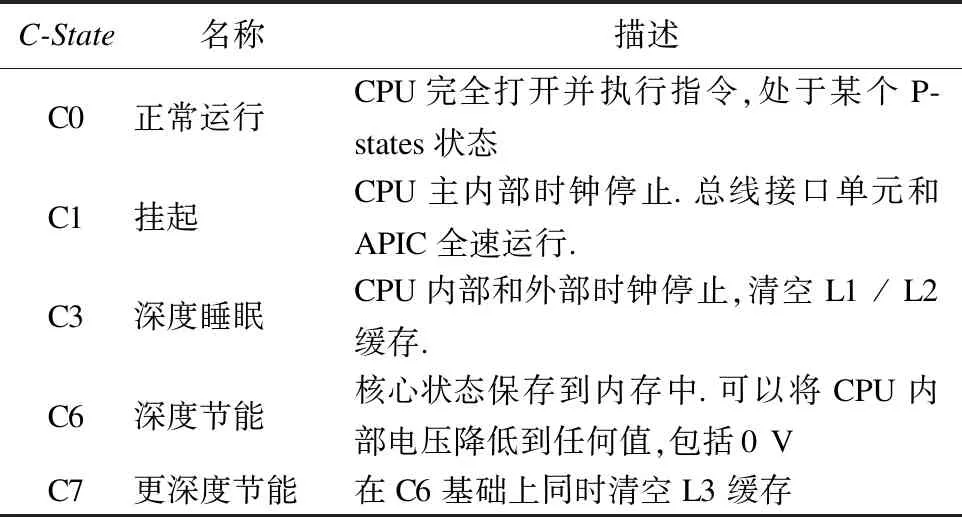
C-State名称描述C0正常运行CPU完全打开并执行指令,处于某个P-states状态C1挂起CPU主内部时钟停止.总线接口单元和APIC全速运行.C3深度睡眠CPU内部和外部时钟停止,清空L1/L2缓存.C6深度节能核心状态保存到内存中.可以将CPU内部电压降低到任何值,包括0VC7更深度节能在C6基础上同时清空L3缓存
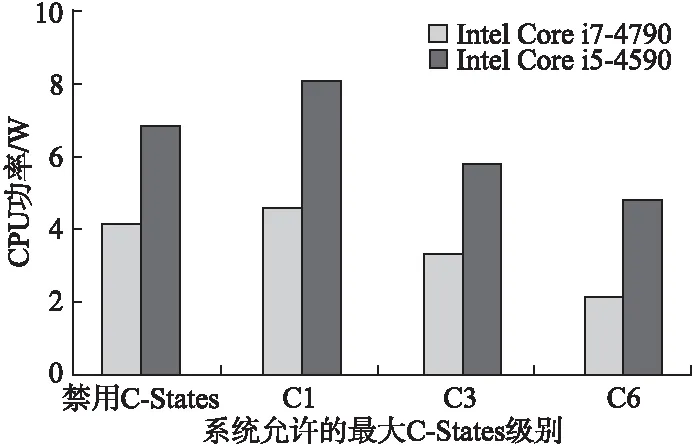
图1 空闲状态下C-States与CPU功率的关系Fig.1 Relations between C-States and CPU power in idle state
5 实验与评价
5.1 实验环境
实验中主机采用Intel Core i5-4590处理器、两条DDR3 1600MHz 4GB 1600MHz内存、西数5400转1TB机械硬盘,Ubuntu 16.04系统作为实验环境,并使用C语言实现模型架构.系统使用杭州远方光电信息股份有限公司的PF9808B数字功耗仪,搭建了实验环境.为了避免功耗仪采样程序对实验的影响,功耗仪采样程序在另一台主机上运行,两台主机之间通过交换机相连,被测系统正常运行,监控测量系统记录采样功率.其中,数字功耗仪以一秒为周期进行采样,监控测量系统通过串口得到相应数据.此外在实验中尽量保证在相同温度时段开展实验,减少其他因素对功耗模型的干扰.
5.2 基于利用率的整机功率建模结果
5.2.1 数据采集
Linux中存在/proc与/sys目录,他们是提供内核统计信息的文件系统接口,包含许多目录与文件./proc与/sys目录由内核动态创建,通过proc与sysfs文件系统直接在内存中存储,多数文件是只读的,使用标准的POSIX文件系统调用即可访问数据.由于数据已经由内核计算出并在内存中存储着,因此读取这些数据产生的开销非常小.CPU利用率通过测量一段时间内CPU忙于执行负载的时间比例获得,磁盘使用率可以通过某段时间内磁盘运行工作的忙时间的比例计算得出,这些信息可以从proc与sysfs文件系统中获取.
5.2.2 训练集合与过程
本文基于利用率构建的整机功率模型主要针对数据库系统.针对数据库常用四种连接算法,编写人工负载用于产生模型的训练集.同时,为使模型具有普适性,考虑处理器同时执行的内核数对模型的影响,分别按照单核、双核、三核以及四核运行模式构建人工负载,且人工负载产生的CPU利用率在0-100%内呈阶梯分布.实验中CPU频率由intel-pstate驱动根据负载控制.鉴于数据库连接操作的磁盘利用率都很高,实验负载产生50%,75%与100%这几种利用率.内存负载不人为控制,仅由系统运行时自然产生.
为了获得足够多、更稳定的数据,训练集合中的负载重复运行了10次,最后获得10次训练聚合后的数据,通过CPU利用率、磁盘利用率和整机实时功率,使用多元线性回归模型训练就得到了利用率构建的整机功率模型PM1为
5.3 基于性能事件、C-States与利用率的整机功率模型
5.3.1 数据采集
在Linux下,有多种工具或库可以用于性能计数器的采集,流行的有OProfile、PAPI、perf.本文采用perf[15]获取性能事件.perf是Linux平台下的性能分析工具,封装了底层perf-events接口,向上层提供了丰富的功能:可以指定需要监测的性能事件;提供线程级、core级、CPU级、系统级的事件计数;可以指定监测性能事件在用户态、内核态或两者同时进行监控;当监测硬件性能事件多于性能计数器,自动通过时分复用继续提供监测,同时由于内核开发者的良好设计与开发,perf采样时开销很低.本文基于perf的用户层工具代码,增加了一些实验需要的修改,以此作为数据采集程序.
对于建模需要的处理器和内存的功率,可以使用RAPL(Running Average Power Limit)[16]获得,Intel处理器使用RAPL接口提供了目前的能源消耗量的测量,分为PKG、PP0、PP1、DRAM四个值,其分别代表整个处理器的能源消耗、所有核的能源消耗、核芯显卡的能源消耗、内存的能源消耗.存放于四个特殊的性能计数器中,可以直接通过perf读取.使用RAPL获取的功率值具有较为良好的准确性,但该方案目前还没有完全普及,有些处理器不具有能量寄存器,不支持该功能.
Intel处理器提供两类MSR寄存器:MSR-CORE-C*-RESIDENCY用于计数每个物理内核处于特定C-State的计数;MSR-PKG-C*-RESIDENCY用于计数每个物理封装处于特定C-State的计数1,其中C*为特定的C-States,可以使用perf直接读取该MSR寄存器,由于实验机只有一个处理器,本文只关心前一个计数.
本文使用功耗仪采集整机系统的功率值,使用RAPL采集处理器和内存部分的实时功率,使用perf采集性能事件与C-States计数,本文由于需要获得整机的实时功率,因此同时监测性能事件处于用户态和内核态的计数.
5.3.2 训练集合与过程
本文所构建的基于性能事件、C-States和利用率的功率模型独立于具体负载,为此选用了SPEC CPU2006[17]作为处理器基准测试.SPEC CPU2006基准测试是一个标准的测试集合,包括SPECint整型数测试和SPECfp浮点数测试,共31项测试.各种测试可以模拟处理器遇到的各种情景.SPEC CPU2006是计算密集型负载,可以适应处理器和内存功率模型的训练,对于磁盘功率模型部分,需要增加I/O密集型的训练集合,同样在模型PM2上,也使用了按照单核、双核、三核以及四核运行,CPU利用率在0-100%内呈阶梯分布,I/O利用率在 50%,75%与100%分布的人工负载.
同基于利用率的整机功率模型的训练过程一样,为了获得足够多、更稳定的数据,训练集合中的I/O密集型的负载重复运行了10次,而SPEC CPU2006在运行过程中,每个测试项目运行的次数被配置为3次,通过程序汇总性能事件的计数值、C-States计数与对应的处理器与内存功率值或整机功率值后,本文使用多元线性回归计算出模型PM2公式(16)的待估参数、待估常量如下所示.
S1=11.6157854129S2=2.15105333269
β1=3.06718196e-03β1=6.45502333e-03.
5.4 测试集合
为了验证两种功率模型的准确性,本文使用了与训练集合不相交的程序作为测试集合.基于利用率的整机系统实时功率模型是针对数据库系统的,而结合性能事件和利用率的整机系统实时功率模型是通用型的,本文将比较这两类模型对块嵌套循环连接算法(BNL)、排序归并连接算法(SMJ)、Grace哈希连接算法(GHJ)、混合哈希连接算法(HHJ)这四类连接算法的估测情况,同时使用Eureqa与TPC-H负载对结合性能事件和利用率的模型进行验证.Eureqa使用进化搜索来确定以最简单的形式描述数据集的数学方程式,是计算密集型负载.TPC-H基准测试旨在衡量数据仓库工作负载的性能,同时属于计算密集型和I/O密集型负载.在实验中,TPC-H的查询运行在PostgreSQL数据库上,比例因子设为100,即所有表的数据量为100GB,TPC-H基准测试提供了22条查询,实验选取了查询时间较短的查询Q14、Q19和查询时间较长的查询Q1、Q2、Q5与Q21.
5.5 实验结果比较
表3表示两类整机功率模型对各种负载功率估测的相对误差.在所进行的所有实验中,基于性能事件与C-States的处理器与内存功率模型一致优于基于性能事件的处理器与内存功率模型,实验表明加入C-States状态计数确实提高了功率模型的准确性.对于整机功率模型,总体来说,模型PM2对数据库系统构建的模型和通用型的模型都有着良好的准确性,绝大部分情况均优于模型PM1.从表3看出,在处理器与内存功率模型方面,对于四类连接算法,其在加入C-States后,预测准确性有提升,最高提升值1%,对Eureqa以及TPC-H查询而言,加入C-States后,预测准确性最高提升值为5%;而在整机模型方面,其准确性除了SMJ算法中PM2略逊色之外,对于其余算法模型PM2均不同程度优于PM1,最高提升超过7%.
表3 各模型对几种测试负载的相对误差表
Table 3 Relative error for models against several test loads
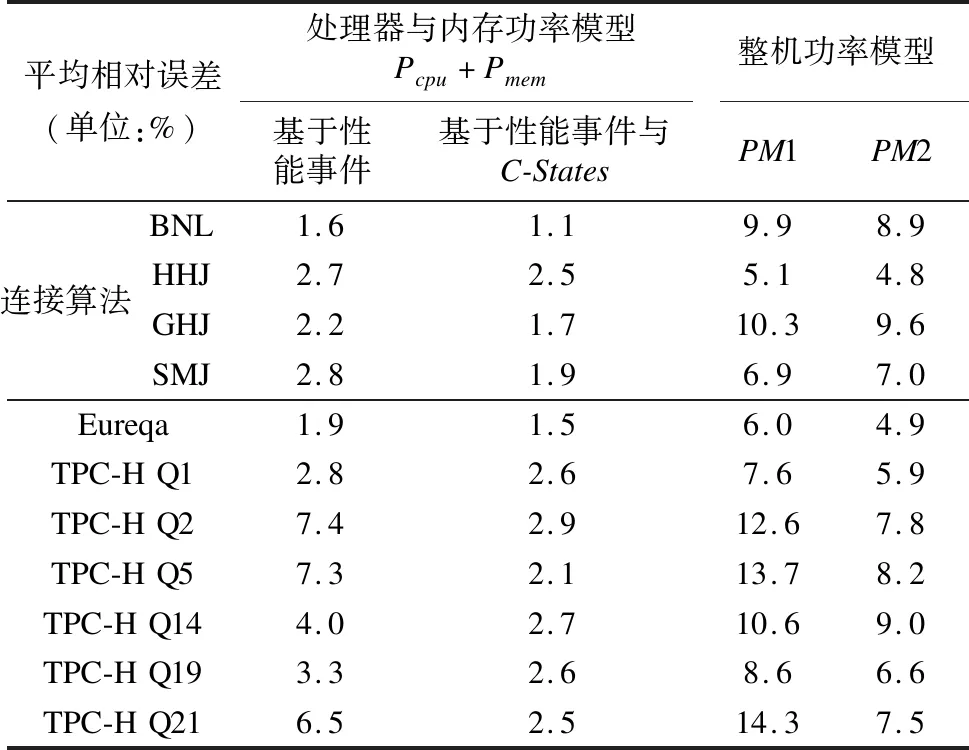
平均相对误差(单位:%)处理器与内存功率模型Pcpu+Pmem整机功率模型基于性能事件基于性能事件与C-StatesPM1PM2连接算法BNLHHJGHJSMJ1.62.72.22.81.12.51.71.99.95.110.36.98.94.89.67.0Eureqa1.91.56.04.9TPC-HQ12.82.67.65.9TPC-HQ27.42.912.67.8TPC-HQ57.32.113.78.2TPC-HQ144.02.710.69.0TPC-HQ193.32.68.66.6TPC-HQ216.52.514.37.5
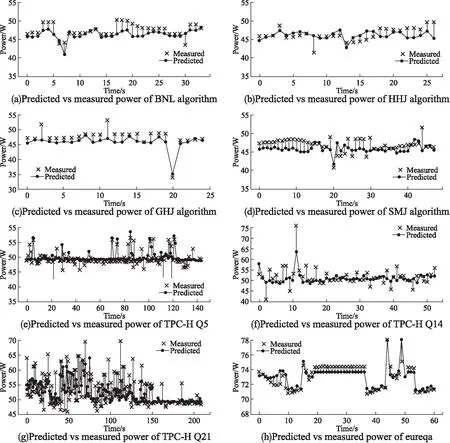
图2 功率模型估测图Fig.2 Predicted vs measured power
图2(a-d)描绘了四类连接算法在运行过程中的功率测量值和模型PM2估测值的关系.图2(e-h)描绘了Eureqa和TPC-H基准在运行过程中的功率测量值和模型PM2估测值的关系.图2(h)是Eureqa运行时的功率估测图,同时观察表3可以发现,对于Eureqa这种CPU密集型的计算,所选性能事件已经可以非常准确地对处理器与内存功率建模,相对误差不到2%;但在整机模型中,模型PM2估测准确性优于PM1,仍有约5%的相对误差.图2(e-g)呈现的是三个TPC-H基准查询在PostgreSQL数据库系统中运行时的模型PM2功率估测图.其中图2(f)为查询时间较短的查询Q14,图2(e)和图2(g)为两个查询时间较长的查询Q5和Q21.观察表3可以发现,对于TPC-H负载,加入C-States后处理器与内存功率模型的提升非常大,在整机模型中,模型PM2估测准确性也都优于PM1.同时从图2(a-h)中可以发现有时因不可预知因素(如底层操作系统进程等任务)的影响,个别点的功耗会产生突变,导致改点绝对误差变大.
6 结束语
本文构建了两种整机系统实时功率模型.本文使用了真实系统Eureqa建模和PosgreSQL系统运行TPC-H负载对两种功率模型进行验证,其中结合性能事件、C-States和利用率的通用整机功率模型优于基于利用率与处理器核频率所建模型.在今后的工作中,为了进一步提高整机系统实时功率模型的精度,可以考虑在CPU、内存和磁盘外增加其他部件的功率模型,比如电源、网络、主板和风扇.
猜你喜欢
煤气与热力(2022年2期)2022-03-09 06:29:30
电脑爱好者(2019年2期)2019-10-30 03:45:31
网络安全和信息化(2018年2期)2018-11-09 01:16:18
网络安全和信息化(2017年3期)2017-03-10 07:45:51
个人电脑(2016年12期)2017-02-13 15:24:40
网络安全和信息化(2016年8期)2016-11-26 06:42:50
电子制作(2016年19期)2016-08-24 07:49:54
湖北师范大学学报(自然科学版)(2015年1期)2016-01-10 08:41:20
电子世界(2015年22期)2015-12-29 02:49:44
电源技术(2015年11期)2015-08-22 08:51:02
