
基于决策树的用户信用评分模型的构建
2019-07-08 03:32吴锦华王志生刘重阳胡龙彪
无线互联科技 2019年8期
吴锦华 王志生 刘重阳 胡龙彪

摘 要:信用评分系统在信用风险管理中发挥比较重要的作用,通过大数据分析技术构建评估分析模型来解决信用风险预测问题。文章在scikit-learn机器学习工具的基础上,通过利用特征选择方法生成有效特征集并结合决策树方法来构建信用评分模型,并在实际数据集得出评分结果,同时所得结果为评估人员提供信用决策建议。
关键词:信用评分;scikit-learn;特征选择;决策树
1 信用简介
“信用”是长时间积累的信任和诚信度,如“信用风险”是银行主要信用卡审批过程中常见的风险,是银行授信的最主要风险。过去对申请信用卡的申请人主要是依据于信贷员的评估,或者信贷决策委员会对申请人进行综合评价,而这种评估结果往往受其主观因素的影响。最近几年来,信用市场不断扩大,人工信用评估具有较大的局限性和不全面性。目前阶段的信贷问题较为严重,各行各业都面临着信用问题,欺诈时有发生,导致信用危机的发生。为了防范风险,最大限度地降低风险,减少坏账,提前预警不守信用的个人或企业,从而拒绝给其提供金融服务,如贷款、办理信用卡等业务[1]。在这种巨大的信用风险考验下,建立全面有效的信用评分系统是目前各大金融机构亟需解决的问题。
信用评分是评分技术在信用风险管理方面的应用,通过建立方法模型进行预测。以申请信用评分为例,利用海量的数据,借助机器学习相关方法模型给申请客户进行信用打分[2-3],并依据不同的分值划分客户信用等级,从而预测客户信用风险。
本文通过对Kaggle上的Give Me Some Credit數据的挖掘分析,结合信用评分卡的建立原理,对数据集进行预处理、特征选择以及利用scikit-learn平台中的决策树模型分别进行预测以及其结果相应对比分析,为个人信用评估工作人员提供参考。
2 数据分析与模型建立
2.1 数据预处理
对数据集中的数据进行分析,初步观察发现,Monthly Incom和Number of Dependents存在缺失值,另外部分age值为0,因此年龄值低于0均视为异常值。另外,对数据集的缺失率进行计算,得到Monthly Income和Number of Dependents数据存在缺失,monthlyIncome 缺失数据最多,缺失率最高。Number of Dependents变量缺失值比较少,直接删除,对总体模型不会造成太大影响,另外,对缺失值处理完之后,删除重复项。
因此,在本文中,对age异常值进行处理,认为>90岁或者≤0岁的为异常值,在此数据集中,使用单变量离群值检测判断异常值,异常的样本不多,则直接删除。
经过上面的数据预处理之后,就认为现在的数据均为正常数据,而不是脏数据。所以接下来就可以对数据进行一些各个变量之间的相关性分析来筛选一些重要的特征。首先,通过Python里面的seaborn包,调用heatmap()绘图函数进行绘制各个变量之间的相关性的热力,如图1所示。
从图1中可看出,各个特征之间的相关性还是比较小的,并不存在多重共线性问题,因此,不需要进行降维处理或剔除相关变量,为后面模型的稳定性提供了好的基础。
2.2 特征选择
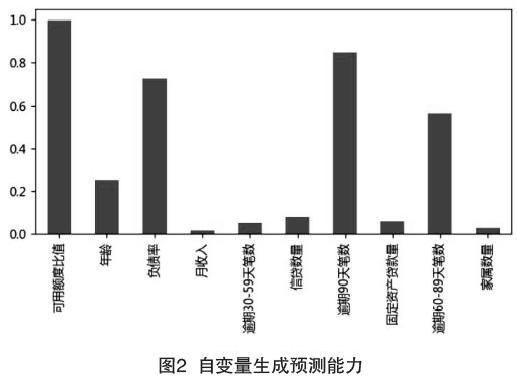
本文采用决策树来构建分类模型时,经常需要对自变量进行筛选。比如有40个特征量时,通常情况不直接把40个变量直接放到模型中进行训练,而是通过特征选择方法从40个自变量中挑选一些出来。挑选过程比较复杂,需要考虑的因素很多,比如变量的预测能力、变量之间相关性、变量的简单性、强壮性、变量的可解释性等。但是,最主要和最直接的衡量标准是变量的预测能力。通过将用户的信用卡数据进行证据权重(Weight of Evidence,WOE)分箱后,再计算数据中的10个自变量生成预测能力如图2所示。
2.3 特征变量的预测能力
从图2中可以看出,数据集中的“月收入”“逾期30~59天笔数”“信贷数量”“家属数量”和“固定资产贷款量”预测能力值均小于0.2,因此在信息价值(Information Value,IV)筛选的时候,IV值为0.1以上被认为具有一般预测能力,0.2以上算比较有预测能力。所以在接下来的模型建立的过程中将筛掉这些预测能力差的特征。
2.4 模型预测分析
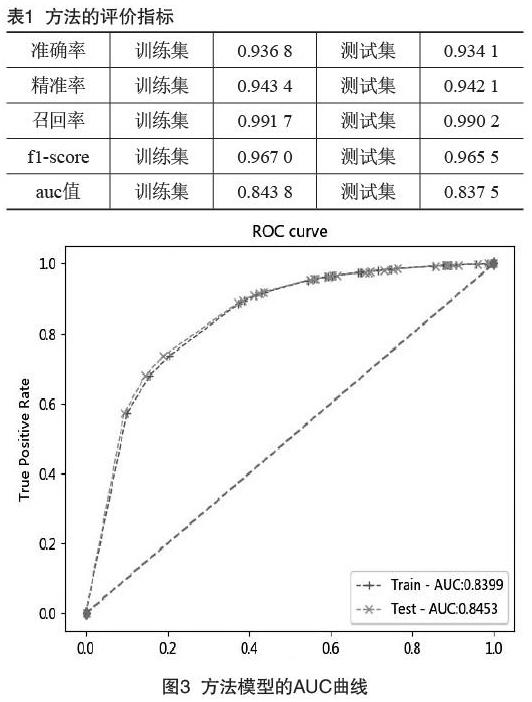
经过数据预处理以及特征选择之后,选择决策树对数据进行分类,在机器学习中,决策树是一个预测模型,它代表对象属性与对象值之间的一种映射关系[1]。本文通过使用scikit-learn平台中的决策树工具构建方法模型。另外,为了评估方法模型的有效性,采用交叉验证法来评价分类器性能,另外选择受试者工作特征(Receiver Operating Characteristic curve,ROC)曲线下的坐标轴围成的面积(Area Under Curve,AUC)值作为评分标准,对应AUC更大的分类器效果更好。绘制出的AUC曲线如图3所示。另外,训练模型以及调节相应参数,计算出方法模型的准确率、精确率、召回率、f1-score,具体如表1所示。
由表1看出,经过调参优化后的决策树方法模型,在测试集上召回率达到0.990 2,稍低于训练集,但结果所表现的性能比较优秀,能够较好地对用户的信用进行评分和预测。
3 结语
本文基于scikit-learn平台构建特征选择方法模型,并在真实数据集进行预测分析,最终调优出来的方法模型在预测数据的准确度、精确度等性能指标上表现良好,在实际场景中具有一定的研究意义。
[参考文献]
[1]王芝珺,吴纯志.P2P网络借贷平台的个人信用评估模型研究—基于决策树和Logistic回归[C].杭州:第十届海峡两岸统计与概率研讨会,2016.
[2]陈安.基于机器学习的信用卡风险评估研究[D].南昌:江西财经大学,2018.
[3]袁海瑛.大数据背景下的互联网融资信用评价体系构建[J].上海经济研究,2017(12):66-72.
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
成都信息工程大学学报(2018年6期)2018-03-21
电子制作(2017年23期)2017-02-02
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
电测与仪表(2016年2期)2016-04-12
电测与仪表(2016年23期)2016-04-12
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
郑州大学学报(医学版)(2015年1期)2015-02-27
