
基于PLS和组合预测方法的冬小麦收获指数高光谱估测*
2019-07-03 05:51徐新刚杜晓初杨贵军赵晓庆魏鹏飞王玉龙范玲玲
中国农业信息 2019年2期
陈 帼 ,徐新刚 ,杜晓初 ,杨贵军 ,赵晓庆 ,魏鹏飞 ,王玉龙 ,范玲玲
(1. 湖北大学资源与环境学院,武汉430062;2. 农业部农业遥感机理与定量遥感重点实验室/北京农业信息技术研究中心,北京100097;3. 国家农业信息化工程技术研究中心,北京100097)
0 引言
收获指数(Harvest Index,HI)指收获时作物籽粒产量和地上部生物量的比值,又名经济系数,是选择作物品种和品种改良研究中的重要参考因子[1]。收获指数通常可以通过田间取样获得,但需要耗费较大的人力、物力,并具有一定滞后性。遥感技术拥有动态、快速和准确获取地表作物参数信息的优势,随着遥感监测技术的快速发展,通过遥感手段获取收获指数将成为未来收获指数评价的发展趋势[2]。
当前,基于遥感技术的作物收获指数遥感估算已开展了初步研究。杜鑫等[3]利用遥感技术监测作物收获指数的可行性分析研究,基于HI的形成过程总结归纳出3类利用遥感技术实现HI估测的方法,为如何利用遥感方式估算收获指数提供了借鉴思路。Moriondo等[4]基于时间序列NDVI(归一化植被指数)遥感信息,利用小麦开花前后NDVI均值比作为指示特征,开展小麦的收获指数遥感提取研究,但是该方法需要首先确定提取区域内最大收获指数和其可能会有的变动幅度,不同的取值一定程度会影响收获指数估算结果。基于Moriondo等的研究,任建强等[5]做了方法改进,利用MODIS卫星遥感影像获取冬小麦生长期内时间序列NDVI数据,以小麦开花前的NDVI累计值与花后NDVI累计值的比值作为指示HI的遥感指数,很好地估测了区域冬小麦的收获指数,反演结果与实测结果的R2达到了0.49。上述方法,尽管很好地实现区域尺度作物HI的遥感估测,但需要作物生长季内逐日或者短周期间隔的时间序列卫星遥感影像,数据处理工作量巨大。
另一方面,由于作物收获指数反映了作物光合产物在籽粒和营养器官上的分配比例,它与作物不同生育期植株体内光合产物的形成、运转过程息息相关,并受到诸多因素的影响,因此,作物不同生育期的生长对作物最终收获指数的形成都具有或多或少的影响,如何来刻画不同生育期对作物HI的影响贡献,组合预测方法提供了一种可能途径。文章通过获取的冬小麦多生育期多时相地面冠层高光谱数据,开展小区田块尺度的作物收获指数高光谱估测研究,通过引入最优组合预测方法,将基于不同生育期光谱信息建立的不同冬小麦收获指数光谱估测模型进行组合,通过优化算法赋予最优权重,从而构建组合估测模型实现冬小麦收获指数的高光谱估测,相关的研究并不多见。该文提出的作物收获指数遥感光谱估测方法,尝试利用权重最优组合算法,以达到充分利用作物多个生育期有用信息进而改善收获指数估算精度的目的,以期为基于多时相光谱信息的HI遥感估算提供新的方法参考。
1 研究区与研究方法
1.1 研究区域
实验区位于北京郊区的顺义区和通州区,该区域属于暖温带半湿润大陆性季风气候。年平均温度11.3℃,年平均降水量在620 mm左右。气候宜人,地形平缓,适宜耕种。为展开研究,在顺义区和通州区种植基地中随机挑选出27个采样点,采样选取大田块、生长具有代表性冬小麦地块进行实验获取数据。
1.2 冬小麦冠层光谱测定
实验于2009—2010年冬小麦生长季开展,分别选取冬小麦起身期、拔节期、孕穗期、开花期和灌浆期,对冬小麦冠层进行光谱测定。测定日期分别为:2010年4月1日、4月17日、4月29日、5月17日和6月2日。测量光谱仪选用ASD Field Spec FR2500,光谱范围350~2 500 nm,采样间隔为1 nm。尽量选择在天气晴朗时测定,测定时间为北京时间10: 00~14: 00。测定时,探头始终垂直向下且保持与地面约为1 m的距离,探头视场角为25°。在每个采样点测量10次,取平均值为光谱测定的结果。在每个采样点测定前、后立即进行标准白板矫正。在进行植被指数计算时,为排除干扰波段,仅仅选用敏感度较高的400~1 100 nm作为有效分析数据。
1.3 收获指数测定
选取研究区内共27个实测样区。其中,通州区、顺义区样区数分别为15个和12个。样区位置的选择充分考虑了冬小麦生长状况和区域分布的代表性,且样区面积均不小于100 m×100 m。采用五点取样法进行取样,拷种称量后,剪掉根部,只保留地上生物量部分进行晾晒,之后称量5采样点冬小麦干重记录为M。随后进行脱粒处理,称取籽粒的重量记录为M′,这样每个采样点的实测收获指数HI即为两者重量的比值。该实验测得的结果HI,即为试验区域内冬小麦收获指数的实际测量值。该值将被用于构建单个生育期的预测模型以及验证组合预测模型所计算结果的精度。计算公式为:

式(1)中,HI为收获指数,M′为小麦籽粒重量,M为小麦干重。
1.4 植被指数选择
到目前为止,植被指数的种类已经达到了100多种,并在各个领域得到了广泛应用。由于关于收获指数的研究成果有限,能够明显反映收获指数大小的植被指数还在探索中,但是收获指数的大小与作物光合作用关系密切[6],在选择植被指数构建模型时,可以将对光合作用有关的因素列入考虑范围,如叶面积大小、温度、施氮水平、叶绿素含量等。
在挑选出的植被指数中,NDVI(归一化差值植被指数)、DVI(差值植被指数)、RVI(比值植被指数)、EVI(增强植被指数)、OSAVI(优化土壤调整植被指数)等均属于常用的植被指数,而后学者们为了估测水稻大叶面积指数,在NDVI的计算公式上进行了改良,提出了GBNDVI(绿蓝波段归一化植被指数)、GRNDVI(红绿波段归一化植被指数)、RBNDVI(红蓝波段归一化植被指数)、BNDVI(蓝波段归一化植被指数),这些改良的植被指数也被挑选为反演参数。常用于监测叶绿素含量的植被指数有:NPCI(归一化色素叶绿素植被指数)、TCARI(转化叶绿素吸收反射指数)、MCARI 2#(改进叶绿素吸收比率指数II)、GVI(绿度植被指数)等;植被含氮量估测常用的植被指数有:NDRE(归一化红边指数)、MTCI(MERIS陆地叶绿素指数)、SIPI(结构不敏感色素指数)、PPR(植被色素比率)等;除此之外,该研究还引入了一些新型的植被指数作为对比参考,如DPI(双峰值指数)、REP-li(线性内插法红边位置指数)、PSRI(三波段比值指数)、MSR(改进比值植被指数)等。
综合以上,共计44种植被指数被列为反演参数。计算时,分别选择620~760 nm、492~577 nm、400~450 nm、700~1 100 nm的波段范围内平均反射率作为红光(R)、绿光(G)、蓝光(B)和近红外(NIR)波段的反射率值。其详细的计算公式和引用文献如表1所示。
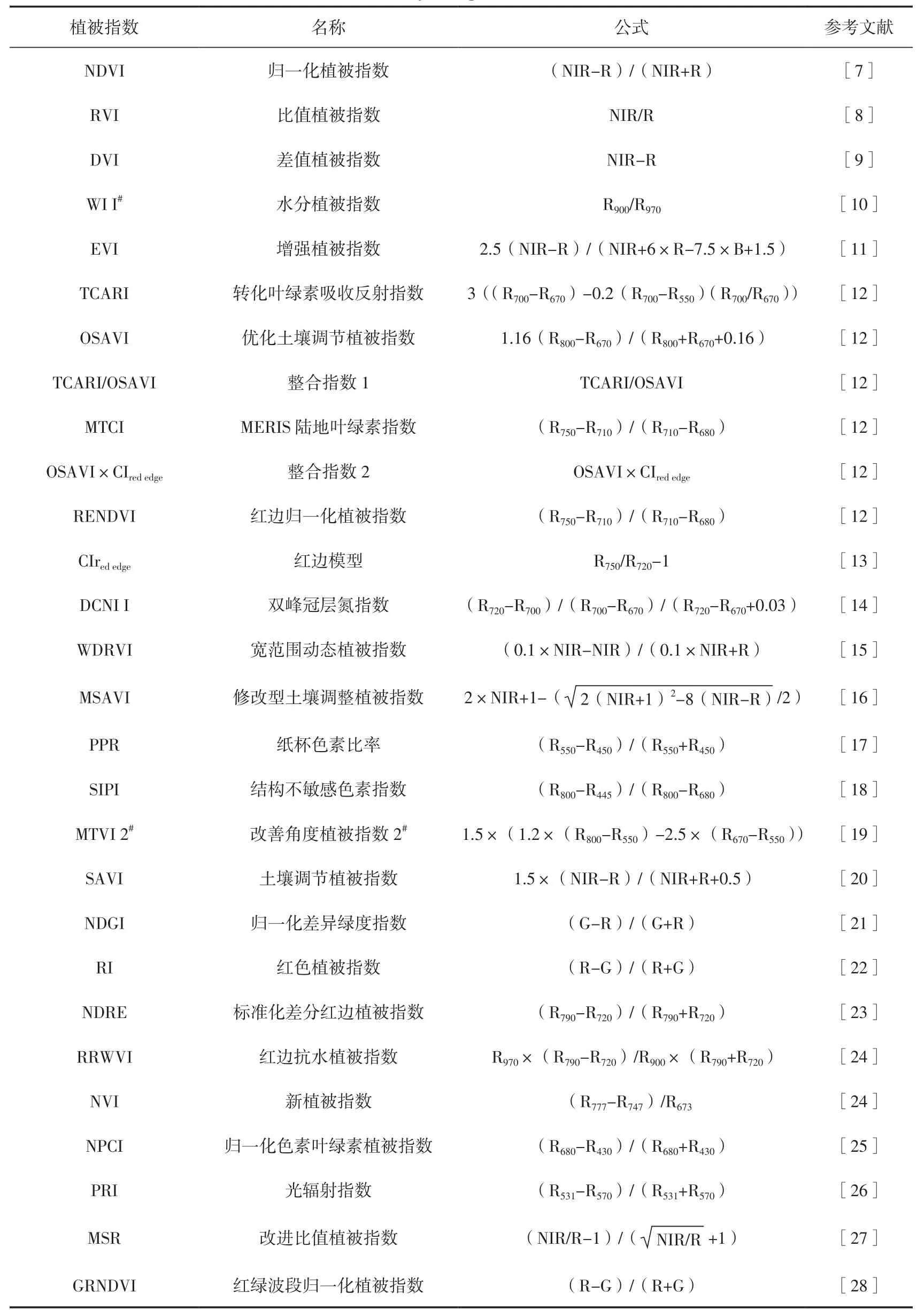
表1 采用的植被指数Table 1 Summary of vegetation indices studied
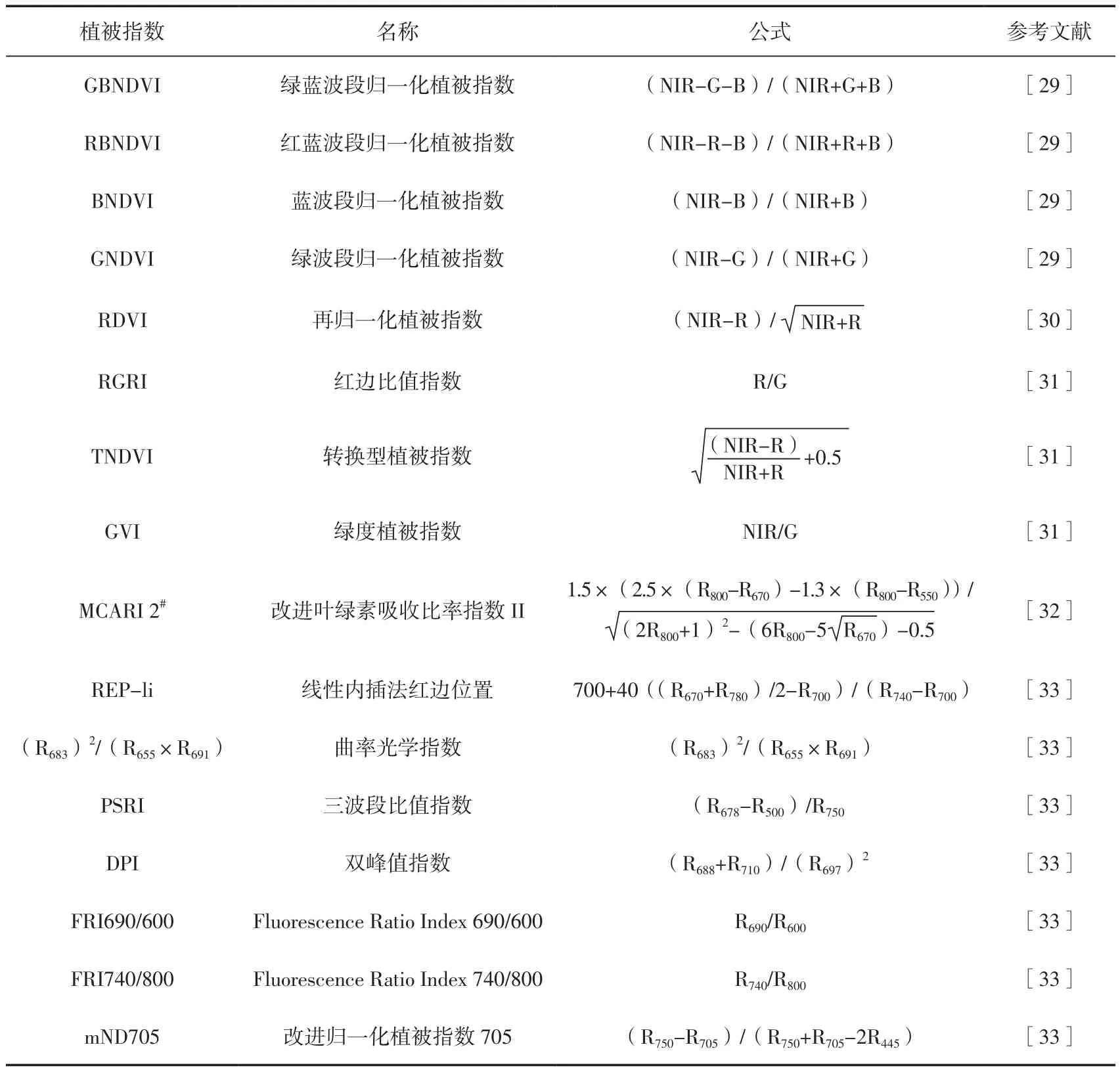
续表
1.5 统计分析
将测定出的冬小麦5个生育期的冠层光谱数据,代入表1所列公式进行计算。按照不同生育期,排列出27个取样点对应的44个植被指数值,并将每个生育期的44种植被指数与冬小麦实测收获指数HI之间建模,进行相关性计算。选择决定性系数(R2)和均方根误差(RMSE)作为指标,将所计算的结果进行排序,挑选R2较大同时RMSE尽量较小的5个植被指数作为筛选结果。
1.6 偏最小二乘建模
偏最小二乘法(Partial Least-Square,PLS)是一种多元统计分析法,具有计算简单、建模预测精度高、解释性强等优点。PLS通常用于解决对于多个因变量和多个自变量的回归建模等问题,当解释变量的个数远超过样本个数或者解释变量内部存在多重共线性时,PLS能运用成分提取的方法,解释变量与因变量的相关性[34]。研究中筛选出的植被指数即为解释变量,实测收获是因变量,将二者利用PLS结合后,得到每个生育期的单个预测方程。与其他线性模型一样,PLS的最终结果也是一个线性模型,其方程为:
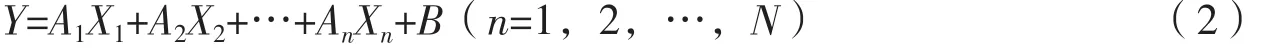
式(2)中,Y是因变量,即实测收获指数;X1~Xn是用于构建模型的植被指数;A1~An是对应植被指数的系数;B是残差参数。使用PLS得到A1~An和B的值,即可得到单个生育期的预测方程。
1.7 组合预测法
组合预测法是采用两种或者两种以上不同的预测方法,对同一对象进行预测,对各单独的预测结果适当加权综合后作为其最终结果[35]。这种方法能聚集各个预测方法的有用信息,使得组合模型的精度优于其中任意一个单一模型的模拟精度,从而达到提高预测收获指数精度的目的。研究采用组合预测法确定每个生育期对于最终收获指数值的贡献程度,即计算出每个生育期对应的权重。确定权重的算法很多,该文采用最优加权算法,评价最优的标准为使组合预测偏差值之和最小。公式为:

式(3)中,ft代表第i种预测方法在t时刻的预测值,为第i种预测方法的权系数,且满足

根据最小二乘法,当残差平方和达到最小,变权系数达到最佳。设et为t时刻组合预测的偏差,则计算最佳变权系数的方程组为:

式(4)中,k1~kN是需要求解的系数,代表单个生育期的预测方程在组合预测中的权重。最后,用实测的数据和组合方程预测出的收获指数值进行验证。
2 研究结果
2.1 相关性分析
将5个生育期内的植被指数和实测植被指数进行相关性分析,计算出R2和RMSE,并进行排序,选取每个时期中R2尽可能大和RMSE尽可能小的5个最优植被指数,结果如表2所示。每一项植被指数与收获指数的R2都非常低,均没有超过0.3,拔节期内所有植被指数与实测收获指数的相关性几乎趋近于0,且RMSE也出现了非常巨大的值。可以看出,单个生育期的单个植被指数与实测收获指数的相关性太低,因此筛选5个最优植被指数与收获指数构建模型。

表2 不同生育期最优植被指数Table 2 Optimal vegetation indices in different stages
2.2 单生育期与收获指数的PLS建模
利用5个生育期中的最优植被指数与PLS结合,建立冬小麦收获指数的估算模型,可以得到经过建模后,单生育期的预测模型。将模型中得到的预测值与实测的收获指数进行相关性分析,按照生育期进行顺序排列,结果如表3所示。相对于单个植被指数拟合,单生育期的多个植被指数拟合的结果在相关性方面有了明显提高,能明显看出单个生育期预测方程对于最终结果的影响大小。但是,只有灌浆期拟合结果的R2超过了0.4,其余4个时期与实测值的相关性都不明显;5个RMSE相较于单个生育期拟合而言,结果有了明显优化,且结果相对稳定,没有太大起伏。说明在经过PLS建模之后,单个生育期的拟合已达到最优状态,但是精度并不足以支持预测方程成立,需要进一步提高。
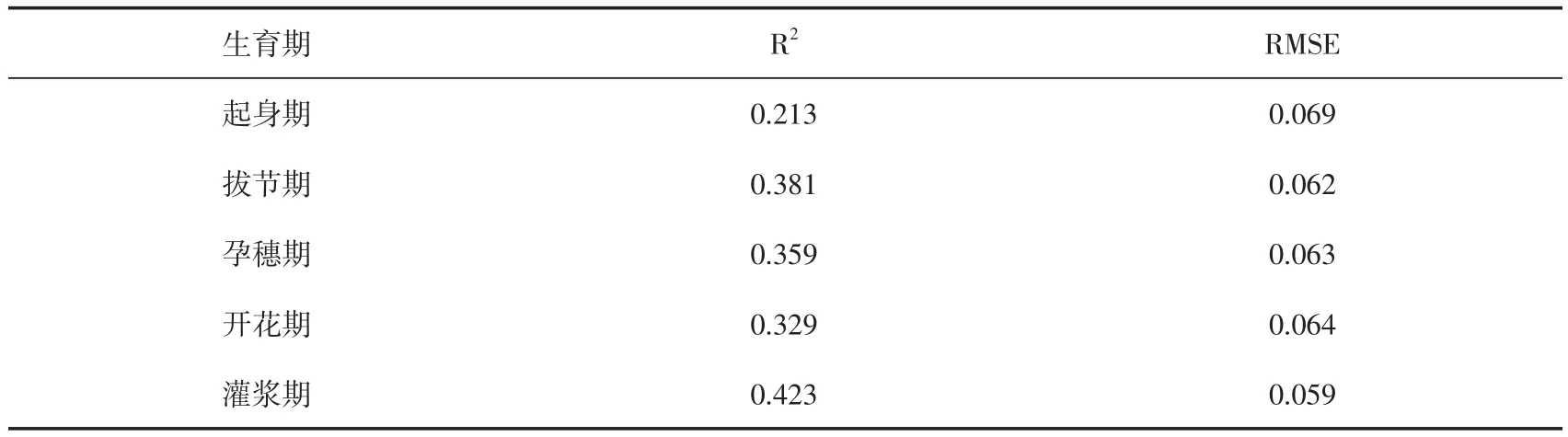
表3 植被指数与PLS结合预测收获指数的结果Table 3 Performance of the combination of vegetation indices and PLS for predicting harvest index
2.3 组合预测建模
利用组合预测的方法,计算出了最优变权系数,将系数得到组合预测的方程为:

式(5)中每个单生育期预测方程前的系数,代表单个生育期对最终结果的贡献程度,即在组合预测方程中,单生育期预测方程的权重系数。这些系数根据前文中式(4)所列出的方程计算而出。
将各生育期的预测结果带入组合预测方程中,得到最终的预测结果。建立实测地面冬小麦收获指数与组合预测结果的关系为:

式(6)中,x为组合预测得到的参数,y为预测出的收获指数,详细结果由图1所示。由图可以看出,相较于单个生育期的预测结果而言,RMSE的变化不大,比单个预测模型中的最小值只降低了0.003,但是R2有了显著提升,较单个预测模型的最大值提升了0.13。根据前文所述,组合预测法具有提取单个预测模型中有效信息的功能,单个预测模型的有效信息越多,代表单个模型的贡献度越大,在组合预测中被赋予的权重就越大,反之则越小。由式(5)可以看出,开花期和灌浆期的单个预测模型在组合中权重最大,这与冬小麦栽培种植的特征基本吻合。由于前3个生育期的时间较短,作物光合产物的累积量不及后两个生育期的累积量充足,而收获指数的确定与光合作用累计的生物量密切相关,所以时间间隔最长的开花期相较于其他生育期对于收获指数的影响力最大,因此相关性最高,权重最大。因此,运用组合预测的算法,可以成功筛选出单个预测模型中的有效信息,利用最优加权组合预测模型的精度比起单个模型预测的精度提升明显。表明组合预测的方法能够为利用遥感数据信息估算收获指数提供有效的方法途径。
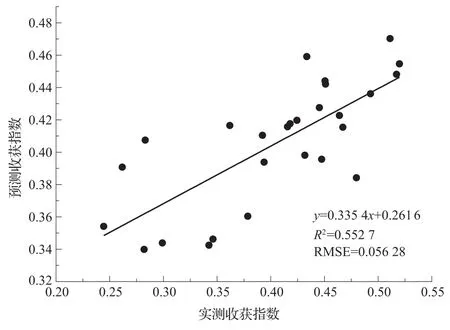
图1 组合预测值与冬小麦收获指数关系Fig.1 Relationship between combination predicted value and winter wheat harvest index
3 结论
单一生育期的植被指数与实测收获指数相关性较低,在挑选出每个生育期中相关性最合适的5个植被指数后与PLS建模,相关性有所提高但依然很低,值最高的R2来自灌浆期为0.42,对应的RMSE为各生育期预测值中最低为0.06,说明PLS的确具有能提升预测精度的能力,可是在该研究中,PLS与单一生育期建模并不能达到理想的预测标准。在利用组合预测法构建方程以后,预测值与实测值的相关性有了明显提高。研究结果表明,在多种不同的方法进行预测时,使用组合预测法可以有效起到提取有用信息的作用,从而可以提高对冬小麦收获指数的估算精度。利用组合预测法得到的预测结果与实测结果的R2能达到0.55,对应的RMSE为0.06。
猜你喜欢
今日农业(2022年4期)2022-06-01
中国油料作物学报(2022年2期)2022-05-13
农业灾害研究(2022年1期)2022-05-07
草业科学(2022年3期)2022-03-26
中国农业气象(2022年1期)2022-02-11
少儿科学周刊·儿童版(2021年21期)2021-12-11
中国土壤与肥料(2021年5期)2021-12-02
农业机械学报(2021年8期)2021-08-27
今日农业(2021年4期)2021-06-09
水利规划与设计(2020年1期)2020-05-25
