
基于孤立森林模型的企业用水异常检测研究
2019-06-30 00:26巫朝星
企业科技与发展 2019年11期
关键词:公共安全
巫朝星


【摘 要】文章基于企业用水量,提出一种结合业务规则和无监督算法的企业用水异常检测方法。首先基于业务经验的凝练规则,将数据集分为含有显著异常的部分和含有潜在异常的部分。然后针对含有显著异常的部分,通过分类规则判定异常类型;针对含有潜在异常的部分,则利用孤立森林算法进行异常检测,并对异常进行聚类,判定异常类型。在企业用水量数据集上的实验结果表明,该方法能够找出存在异常的企业并把握异常的模式。
【关键词】公共安全;异常检测;孤立森林
【中图分类号】TP311.13 【文献标识码】A 【文章编号】1674-0688(2019)11-0061-03
0 引言
异常检测是一种数据挖掘技术,是指在从数据集中找出其行为不同于预期的过程[1],已经被应用于众多领域,如金融、医疗和图像处理等[2]。如今,这项技术也被一些电力公司和自来水公司所采用,主要目的是降低公司运营成本。如自来水公司会对城市水管网区用水进行监测,寻找其中的异常模式,这为公司实施科学化运行管理提供重要依据[3-5];电力公司检测异常用电模式降低非技术性损失,如监测用户窃电和欺诈行为,降低公司运营成本[6-9]。在公共安全部门,异常检测尚未得到广泛应用。企业用水量作为企业日常资源消耗的数据之一,一定程度上反映了企业运营的基本状况,如企业生产的规模和状态。对企业用水量的监测可以了解企业的生产运作状态,若能及时发现生产运作状态异常企业,对于保护公共财产和维护社会安全有十分重要的意义。然而,各种规模的企业和海量的用水数据为监测带来了挑战,且人工监测和频繁的现场探测消耗大量人力、物力,成本较高。因此,公共安全部门亟需一套行之有效、基于海量数据的异常企业检测方案,为部门管理决策提供支持。
目前,常见的异常检测方法主要有基于统计分布的方法[10]、基于距离的方法[11]、基于密度的方法[12]、基于聚类的方法[13]和基于树的方法[14]5种。本文从公共安全部门视角出发,针对企业每月的用水量,提出了一套结合业务规则和无监督算法的异常检测方案,并对检测出来的异常进行分类和聚类分析,为公共安全部门的管理决策提供建议。考虑到每种异常检测的算法都有难以解决的异常模式,本文在异常检测开始阶段结合了基于业务经验的规则,将数据集分为含有显著异常的部分和含有潜在异常的部分。综合考量算法的假设与数据集的匹配度和算法的复杂度,从上文提到的5种经典的异常检测方法中,选择iForest作为异常检测算法。针对含有显著异常的部分,通过规则判定异常的类型。针对含有潜在异常的部分,则利用iForest进行异常检测,并对异常进行聚类分析,找出异常的模式。最后针对不同类型的异常,给出对应的管理建议。
本文提出的方案作用体现在以下3个方面:一是有助于自动排查存在隐患的企业,缩小需现场检查企业的范围,降低人力、物力成本;二是通过挖掘企业异常背后的原因,为加强和优化管理提供依据;三是有助于加强对嫌疑企业的威慑力,降低企业异常行为的发生率。
1 企业异常检测的流程
1.1 数据预处理
本文的原始数据共计13 838家企业的每月用水总量。通过业务规则,发现不含用水值为0的企业分为一类,共6 128个企业,该类企业中仍存在潜在的异常。表1描述的是含有潜在异常的6 128家企业平均用水量的分类情况。然后对数据进行对数处理,取对数主要是为了消除不同规模企业之间用水量大小的差异。最后对数据做一阶差分,消除随机趋势,将每月之间用水量的波动作为企业是否异常的特征。至此,原始数据的预处理工作全部完成。
1.2 孤立森林算法
孤立森林算法[13]是一种无监督的异常检测方法,该算法主要通过从训练数据集中随机选取一个特征,在该特征的最大值与最小值之间随机选取一个分裂点,小于分裂点的进入左侧分支,大于或等于分裂点的进入右侧分支;不断重复上述过程直到只剩一个样本或相同样本(无法继续分裂)或达到树的深度限制。路径长度h(x)指样本点x从根节点到外部节点所经过的二叉树的边数,异常样本通常路径长度较小,而正常样本路径长度较大。以同样的方式构建包含多棵孤立树的孤立森林,异常事件即可基于路径长度被检测出来。数据异常的程度可以通过异常分值判断S(x,n)。定义如下:
式(1)中,n为样本个数,H(i)为谐波次数,c(n)为二叉搜索树的平均路径长度。
式(2)中,E(h(x))是样本点x在孤立森林中所有孤立树的路径长度的平均值。当异常分值s(x,n)越小,则其异常程度越高,是异常点的可能性越大。
1.3 异常值聚类分析
为了更好地探究異常及其背后的原因,本文利用K-means算法对检测出来的异常值进行聚类,并利用手肘法对合适的K值进行确定。K-means聚类算法[15]是一种迭代重定位方法,主要有两个步骤:第一步是依据最近邻原则将数据点分配到距离最近的簇中心点;第二步重新计算簇中心点。如此反复,直到指定的收敛条件,聚类结束。K-means算法流程如图1所示。
2 实验结果与分析
对于含有显著异常的数据集,可以根据0值出现的情况进行分类,本实验分类规则如下:①用水量数据全为0值的企业分为一类,记为I;②用水量数据和0值依次交替出现分为一类,记为II;③其他出现0值的情况分为一类,记为III。
通过表1可知,第I、II和III类异常分别包含298、4 456和2 956家企业。其中,第II类异常企业数量最多,也就是用水量数据和0值依次交替出现的情况,导致该异常出现的情况可能是抄表员2个月才进行一次抄表造成,公共安全部门应该及时提醒有关的自来水公司加强对相关人员的监督和管理,使企业用水量数据能够准确及时地记录;除此之外,还存在相当一部分第III类异常企业,即企业用水量序列中前部、中部或尾部出现几个0值的情况。类似这样从有用水量到无用水量或者从无用水量到有用水量的情况,有可能是企业从生产到停产或者从停产到生产的过程,这对一个正常运营的企业来说是比较罕见的。政府需要及时了解企业运营状况,查清停产和生产状态频繁切换的原因,将该类企业列入观察名单;最后一种数量最少的异常就是第I类异常,该类异常中的企业用水量全部为0值,该情况可能是企业已经停止运营或者已经倒闭,公共安全部门需做好核实。
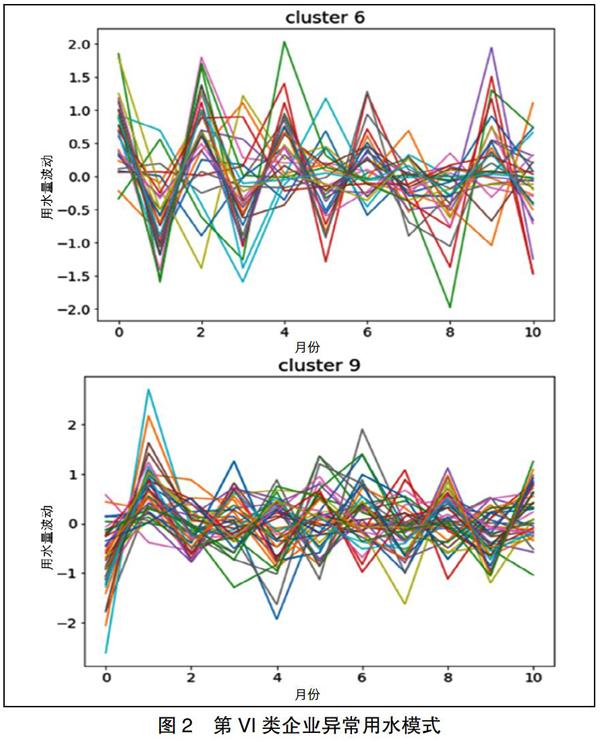
图2给出了某种类别的企业用水模式,从中可以发现用水量没有一致的模式,但至少在某个月的用水量波动较大。
综上所述,通过算法分析,可以观察到用水量存在大幅度连续波动的规律。在第VI类异常中,存在某些月份用水量发生较大波动。因此,公共安全部门要特别关注此类用水量具有大幅度波动的企业,可以进行现场实地排查,调查造成用水量波动巨大的具体原因。
3 结论
本文基于企业每月的用水量数据,提出了一套结合业务规则和无监督算法的异常检测方法。针对含有显著异常的部分,通过算法规则发现了3种异常模式。针对含有潜在异常的部分,利用孤立森林方法进行异常检测,并对异常进行聚类找到3种异常模式。在检测出的6种异常模式中,第I类异常可能是企业已经停止运营或者已经倒闭,公共安全部门需及时对企业状况进行核实;第II类异常出现的原因可能是抄表员2个月才进行一次抄表,公共安全部门应及时提醒相关的自来水公司加强对相关人员的监督和管理,使企业用水量数据能够准确及时地记录;第III类异常可能是企业从生产到停产或者从停产到生产的过程;第IV和第V类异常中企业用水量存在显著的连续大幅度波动,而第VI类异常中企业至少存在某一个特定月份用水量波动。
参 考 文 献
[1]Han J,KamberM,Pei J.Data Mining:Concepts and Techniques Third Edition[M].Elsevier Pte Led,2012.
[2]Chandola V,Banerjee A,Kumar V.Anomaly dete-ction:A survey[J].ACM Computing Surveys,2009,41(3):51-58.
[3]黄琛,李文婷,张旭,等,城市供水管网片区用水异常模式识别[J].云南大学学报(自然科学版),2018(5):879-885.
[4]Mounce R,Khan A,Wood AS,et al.Sensor-fusion of hydraulic data for burst detection and location in a treated water distribution system[J].Information Fusion,2003,4(3):217-229.
[5]Mounce R,Boxall J B,Mexhell J.Development and verification of an online artificial intelligence system for detection of bursts and other abnormal flows[J].Journal of Water Resources Planning and Management,2010,136(3):309-318.
[6]庄池杰,张斌,胡军,等.基于无监督学习的电力用户异常用电模式检测[J].中国电机工程学报,2016,36(2):379-387.
[7]León C,Biscarri F,Monedero I,et al.Variability and trend-based generalized rule induction model to NTL detection in power companies[J].IEEE Transactions on Power Systems,2011,26(4):1798-1807.
[8]Fontugne R,Tremblay N,Borgnat P,et al.Mining anomalous electricity consumption using ensemble empirical mode decomposition[C].//2013 IEEE International Conference on Acoustics,Speech and Si-gnal Processing(ICASSP).Vancouver,BC:IEEE,2013.
[9]NagiJ,Yap K S,Tiong S K,et al.Improving SVM-based nontechnical loss detection in power utility using the fuzzy inference system[J].IEEE Transac-tions on Power Delivery,2011,26(2):1284-1285.
[10]GoldsteinM.,DengelA.Histogram-based Outlier Score(HBOS):A fast Unsupervised Anomaly Detection Algorithm[C].In:Wolfl S,editor. KI-2012:Poster and Demo Track,2012.
[11]E M Knorr,R T Ng.A unified notion of outliers:properties and computation[C].In:Proceedings of the 3rd ACM international conference on knowledge discovery and data mining(KDD),Newport Beach,1997.
[12]BreunigM M.LOF:identifying density-based local outliers[J].2000,29(2):93-104.
[13]Ester M,Kriegel HP,Sander J,et al.Adensity-based algorithm for discovering clusters in large spatial databases[C].In:Proceedings of KDD' 96,Portland OR,USA,1996:226-231.
[14]Liu F T,Kai M T,Zhou Z H.Isolation-Based an-omaly detection[M].ACM,2012.
[15]王建仁,馬鑫,段刚龙.改进的K-means聚类k值选择算法[J].计算机工程与应用,2019(8):27-33.
猜你喜欢
中国信息化(2022年4期)2022-05-06
中国应急管理科学(2022年1期)2022-04-18
人民论坛(2019年8期)2019-04-24
新丝路(下旬)(2018年9期)2018-05-14
重庆行政(2017年1期)2017-06-24
电子技术与软件工程(2016年23期)2017-03-06
人民论坛(2017年4期)2017-02-23
艺术与设计·理论(2016年4期)2017-01-16
小康(2016年22期)2016-09-10
人民论坛·学术前沿(2009年7期)2009-10-22
