
基于Hadoop 的数据云盘的设计与实现
2019-06-27 00:38:58解腾刚马毓杰
现代计算机 2019年13期
解腾刚,马毓杰
(西京学院信息工程学院,西安710123)
0 引言
随着互联网产业的飞速发展以及大数据技术的广泛应用,目前已有许多网盘类似百度网盘、华为网盘等均采用大数据技术实现了用户日常的数据上传、存储、下载等功能。但是在网盘内提供在线数据分析功能的网盘少之又少,使得用户想要从大量的数据中获取到有用的信息以及从数据中发现规律变得较为困难,数据的潜在价值难以被挖掘出来。
目前国内外比较常见的分布式文件系统有Google的GFS、Apache 的HDFS、SUN 的Lustre、MongoDB 的GridFS、IBM 的GPFS、淘 宝 的TFS 和 国 人 开 发 的FastDFS 等,各个分布式文件系统适用于不同的领域,其中HDFS 是Google GFS 的开源实现,通过网络实现文件在多台机器上的分布式存储,HDFS 提供了在廉价服务器集群中进行大规模分布式文件存储的能力,具有很好的容错性和扩展性,可以以较低的成本利用现有机器实现大流量和大数据量的读写,较好地满足了大规模数据存储的需求[1]。
本文提出了基于Hadoop 的数据云盘设计与实现方法,使用者可以将其数据上传存储至该云盘中,并且可以随时从云盘中下载数据,保证了数据存储的安全性,又极大提高了数据的应用效率[2]。同时云盘中的数据分析功能可以帮助用户分析数据的规律,让数据的潜在价值被挖掘出来,为使用者带来极大的价值和便利。
1 系统设计
1.1 功能模块设计
本云盘系统按功能可分为两大模块——用户模块和文件管理模块。其中,用户模块包含两个功能实现:用户注册和用户登录;文件管理模块包含五个功能实现:查看文件、上传文件、下载文件、删除文件和数据分析。本系统的功能模块图如图1 所示。
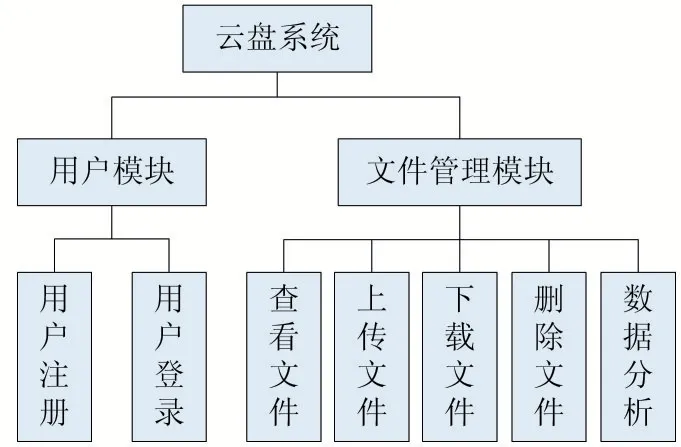
图1 系统功能模块图
1.2 运行流程设计
本云盘系统由最初的登录界面开始,用户需要判断是否拥有账户,如果没有即跳转到注册界面进行注册,如果有则进行登录操作。在注册界面中用户需输入用户名和密码,在检查用户名是否重复、输入两次密码是否相同后判断是否注册成功,成功即进入登录界面,否则重复注册操作。在登录界面中,用户需输入用户名和密码,判断是否登录成功后进行下一步操作,成功则进入主界面,否则重新登录。在主界面中,用户可进行文件管理操作(查看文件、上传文件、下载文件、删除文件、数据分析),在操作结束后退出云盘即为结束使用。本系统的系统流程图如图2 所示。
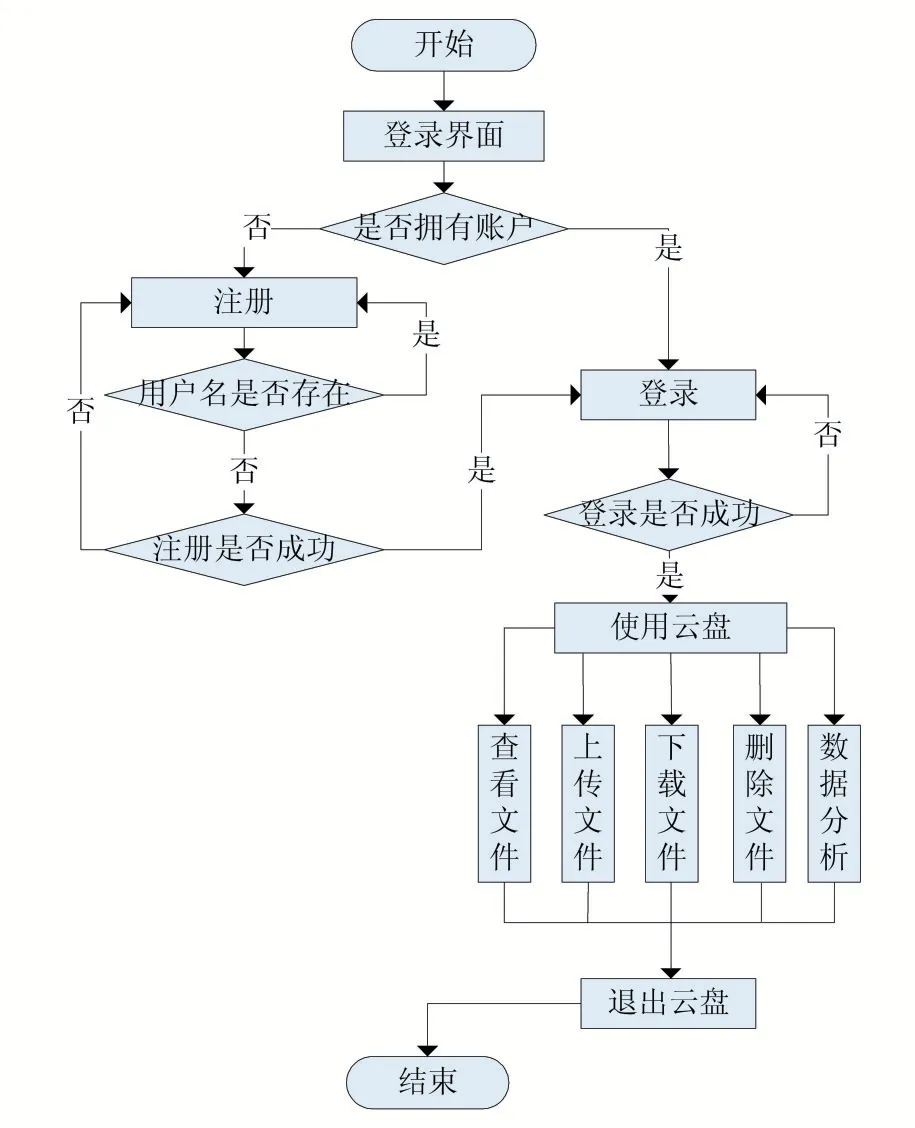
图2 系统运行流程图
2 系统实现
本系统采用全分布式Hadoop 集群作为运行平台,使用HDFS 分布式文件系统作为底层存储,系统分为前台和后台两部分,前台采用JSP 编写界面,后台使用MySQL、HDFS Java API、MapReduce、AJAX 等实现云盘用户注册功能、用户登录功能,用户在云盘主界面中对文件实现查看、上传、下载、删除以及数据分析功能。
2.1 注册功能
在本云盘注册界面中主要完成用户注册操作。用户在进入注册界面中可以完成如下功能:①要求输入需要注册的用户名。②要求输入两次密码,且输入的两次密码的长度和内容相同,否则需要重新注册。③注册成功后跳转至登录界面。④用户注册成功会同时在HDFS 文件系统下创建名为该用户的目录。
2.2 登录功能
在用户拥有账号之后,进入登录界面进行登录云盘操作。登录界面可以实现如下功能:①可以判断用户是否拥有账号,如果没有可以跳转至注册界面。②输入用户名和密码。③判断用户名和密码是否正确,如果不正确则重新登录。④登录成功后跳转至云盘主界面。
2.3 文件管理功能
(1)查看文件
用户登录成功后,系统的主界面会显示该用户的文件列表,实现过程是,系统提取到当前登录用户的用户名,以此用户名创建Path 对象,传入此Path 对象并调用FileSystem 的getFileStatus()方法,得到一个FileStatus 对象,FileStatus 对象封装了文件系统中文件和目录的元数据,包括文件的长度、块大小、备份数、修改时间、所有者以及权限等信息[3]。最后,格式化File Status 对象传到前端页面展示。关键代码如下:public FileStatus[]ls(String folder)throws IOException{
Path path=new Path(folder);//根据当前登录用户名创建Path 对象
FileSystem fs = FileSystem.get(URI.create(hdfsPath),conf);//获取FileSystem 实例
FileStatus[]list=fs.listStatus(path);
if(list!=null)
for(FileStatus f:list){
System.out.printf("%s,folder:%s,大小:%dK ",f.getPath().getName(),(f.isDir()?"目录":"文件"),f.getLen()/1024);
}
fs.close();
return list;
}
(2)上传文件
用户点击“选择文件”按钮后,在弹窗中选择需要上传的文件,点击“上传文件”按钮即完成上传操作。实现过程是,调用FileSystem 的copyFromLocalFile 方法,该方法需要传入两个参数,分别是本地文件的路径和所需上传到HDFS 文件系统的目标路径。关键代码如下:
public void copyFile(String local,String remote)throws IOException{
FileSystem fs = FileSystem.get(URI.create(hdfsPath),conf);//获取FileSystem 实例fs.copyFromLocalFile(new Path(local),new Path(remote));//调用copyFromLocalFile 方法实现上传
System.out.println("copy from:"+local+"to"+remote);
fs.close();
}
(3)下载文件
用户在主界面选择需要下载的文件,单击文件后的“下载”字样,向服务器提出下载请求,服务器找到该文件即将文件下载到本地默认目录中。实现过程是,调用FileSystem 的copyToLocalFile 方法,该方法需要传入两个参数,分别是HDFS 文件系统中的该文件的路径和所需下载到本地的目标路径。关键代码如下:
public void download(String remote,String local)throws IOException{
Path path=new Path(remote);
FileSystem fs = FileSystem.get(URI.create(hdfsPath),conf);//获取FileSystem 实例
fs.copyToLocalFile(path,new Path(local));//调 用copy-FromLocalFile 方法实现文件下载
System.out.println("download:from"+remote+"to"+local);
fs.close();
}
(4)删除文件
用户在主界面选择需要删除的文件,单击文件后的“删除”字样,系统会将此文件从HDFS 文件系统中该用户的目录下删除。实现过程是,调用FileSystem的deleteOnExit 方法,该方法需要传入的参数为所需删除文件的路径。关键代码如下:
public void rmr(String folder)throws IOException{
Path path=new Path(folder);
FileSystem fs = FileSystem.get(URI.create(hdfsPath),conf);//获 取FileSystem 实 例fs.deleteOnExit(path);//调 用deleteOnExit 方法实现文件删除
fs.close();
}
(5)数据分析
用户在主界面选择待分析文件,单击“分析”字样,系统会提交该文件到MapReduce 程序,分析完成后会弹窗提示用户查看分析结果,用户点击确认后,将分析结果用Echarts 进行可视化呈现。数据分析功能是通过MapReduce 技术实现的,根据系统需求编写Map 阶段和Reduce 阶段的相关代码即可,使用JSON 数据格式和AJAX 等技术实现分析结果的可视化。以流量统计为例,根据用户流量数据文件,统计出每个用户的上行总流量、下行总流量以及总流量。在流量统计案例中,Map 阶段由map task 读文件,通过TextInputFormat一次读一行,返回(key,value),其中key 代表用户手机号码,value 代表对应手机号码的流量信息;Shuffle 阶段是从Map 结束到Reduce 开始之间的过程,Shuffle 阶段完成了数据的分区、分组、排序的工作[4];Reduce 阶段将与一个key 关联的一组中间数值进行归约,即对同一手机号的流量数据进行归约。关键代码如下:
protected void map(LongWritable key,Text line,Context context)throws IOException,InterruptedException{
String lineStr=line.toString();//返回字符串
String[]values=lineStr.split(" ");//以空格进行切割并存入数组
String upStr=values[values.length-3];
String downStr=values[values.length-2];
int up=Integer.parseInt(upStr);
int down=Integer.parseInt(downStr);
FlowBean flow=new FlowBean(up,down,0);//创建Flow-Bean 对象
context.write(new Text(values[1]),flow);}
protected void reduce(Text key,Iterable<FlowBean>flows,Context context)
throws IOException,InterruptedException{
int totalUp=0;//上行流量
int totalDown=0;//下行流量
for(FlowBean flow:flows){
totalUp+=flow.getUpFlow();
totalDown+=flow.getDownFlow();
}
int totalUpAndDown=totalUp+totalDown;//总流量
FlowBean flow=new FlowBean(totalUp,totalDown,totalUpAndDown);
context.write(key,flow);
}
3 系统运行效果
该系统注册界面的运行效果如图3 所示。

图3 系统注册界面运行效果图
该系统登录界面的运行效果如图4 所示。

图4 系统登录界面运行效果图
该系统主界面的运行效果如图5 所示。显示当前登录用户网盘内的文件信息,包括文件名、文件类型、文件大小和相应的操作,单击文件名后的“删除”、“下载”字样,即可将对应文件进行删除和下载。

图5 系统主界面运行效果图
点击“选择文件”按钮,系统会弹出选择文件的窗口,用户选择需要上传的文件,点击“上传文件”按钮,即可将文件上传至云盘。上传文件效果如图6 所示。
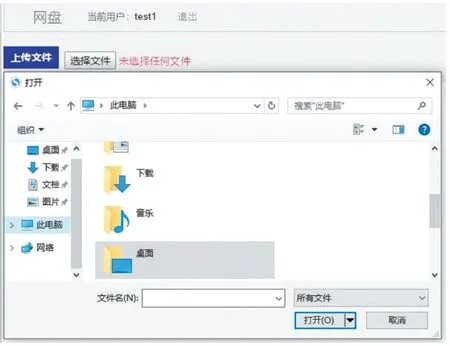
图6 上传文件效果图
单击文件名后的“分析”字样,系统会提交该文件到MapReduce 程序,分析完成后会弹窗提示用户查看分析结果,用户点击确认后,分析结果会进行可视化呈现,以流量统计为例,可视化运行效果如图7 所示。
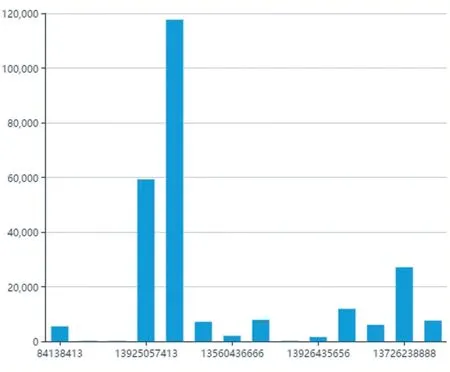
图7 分析结果可视化运行效果图
4 结语
本文提出了基于Hadoop 的数据云盘的设计与实现详细过程,为使用者提供了数据存储以及数据分析的功能,在一定程度上为使用者带来了极大的价值和便利,同时又将数据的潜在价值挖掘出来,具有一定的实际意义。随着大数据技术的不断发展,云存储必然会被广泛应用,云盘系统相比于传统的存储方式优势也会更加明显,也将会是未来主流的存储方式。
猜你喜欢
电脑报(2023年13期)2023-04-11 10:25:31
护士进修杂志(2022年1期)2022-12-31 13:22:48
计算机应用文摘·触控(2021年4期)2021-03-24 11:25:40
当代陕西(2020年13期)2020-08-24 08:22:02
制造技术与机床(2017年5期)2018-01-19 02:49:17
故事会(2017年17期)2017-09-04 17:36:42
潍坊学院学报(2016年2期)2016-12-01 13:00:11
电脑爱好者(2015年19期)2015-09-10 07:22:44
中国信息化周报(2015年28期)2015-08-06 22:05:35
新闻传播(2015年11期)2015-07-18 11:15:04
