
一种基于域名请求伴随关系的恶意域名检测方法
2019-06-26 10:05彭成维云晓春张永铮李书豪
计算机研究与发展 2019年6期
彭成维 云晓春,3 张永铮 李书豪
1(中国科学院计算技术研究所 北京 100190)2(中国科学院大学 北京 100049)3(中国科学院信息工程研究所 北京 100093)
域名系统(domain name system, DNS)是当今互联网中重要的基础核心服务之一,负责提供统一的域名地址空间映射服务,主要将易于人类记忆的域名翻译为易于机器识别的IP地址.然而,伴随着域名系统提供正常服务的同时,近年来越来越多的网络非法活动也开始滥用域名系统以达到其恶意目的.例如,僵尸网络利用域名生成算法(domain generate algorithm, DGA)批量生成大量用于僵尸网络命令与控制(command & control, C&C)信道通信的域名,来逃避权威安全防御机构的封杀和屏蔽[1-2].网络诈骗犯注册外观极其相似于知名合法域名(如alipay.com)的新域名(如al1pay.com),并搭建钓鱼网站来欺骗网络用户,达到窃取账户信息、信用卡密码等目的[3].2016年思科年度安全报告[4]中指出,高达91.3%的恶意软件均会对域名系统进行一定程度的滥用,造成大量的经济损失.
近年来出现了大量利用DNS流量检测恶意域名的研究工作,其主要目的是为了在用户访问这些恶意域名之前进行防御和预警,从而缓解攻击活动带来的威胁和损害.常见的方法[5-7]是从DNS流量、网页信息等数据中为每一个域名人为手动提取特征(例如TTL(time to live)大小、域名请求模式、解析的IP地址数目、涉及到的国家等),随后利用机器学习算法构建分类器.然而,这类基于特征的检测方法能够有效地检测恶意域名的前提是提取特征的有效性,即能否有效地区分黑白域名的行为,并且攻击者不去修改恶意域名的行为来规避这些特征.实际上,之前提出的很多特征已被证实不具有很好的鲁棒性,攻击者可以通过简单地调整来改变这些特征,从而逃避检测.
本文提出CoDetector算法,一种基于域名请求之间内在的时空伴随关系(co-occurrence relation)进行恶意域名检测的算法.本文发现域名请求之间不是彼此独立,相反存在时空相似、伴随共现的特性.针对一次域名查询,触发这次查询的底层应用程序同时会触发其他相关的域名查询,这些域名相互伴随出现,协同完成此次网络活动.例如使用浏览器打开链接,如http:www.baidu.com会先触发对该页面域名www.baidu.com的DNS查询,当网页内容开始呈现时,则会进一步触发对页面嵌入内容(如图片、广告等)的链接进行额外的DNS查询.这些域名请求是为了共同完成这次页面展示而触发的请求,在DNS请求上表现为伴随共现的特性.于此同时,本文发现恶意域名请求之间同样存在时空伴随关系,不同的恶意域名会在一次恶意网络活动中共同伴随地出现.例如一次路过式下载(drive-by download)行为通常由一个长长的URL重定向链条来逐步导向到最终的恶意软件.网络黑产中,恶意的搜索引擎优化技术通过构建重复循环的URL链条,让搜索引擎的爬虫持续停留在被敌手设计的页面中.
本文的假设是伴随出现的域名之间存在紧密的关联,性质上具有同态性,即和恶意域名伴随出现的域名偏向于是恶意域名,反之亦然.基于以上假设,本文提出CoDetector恶意域名检测算法,其主要思路是从DNS流量中挖掘域名之间时空伴随关系,然后借鉴深度学习中张量化表示算法(如word2vec[8])在保留域名彼此时空伴随关系的基础上将每一个域名映射为低维空间的特征向量,最后结合机器学习分类算法构建恶意域名检测分类器.为实现以上目标,本文主要面临2个挑战:
1) 如何从DNS流量提取彼此具有时空伴随关系的域名?
2) 如何在保留域名彼此时空伴随关系的同时张量化地提取域名特征?
针对挑战1,本文提出基于域名请求时间间隔的切割算法,将原始DNS流量中的DNS请求根据时间顺序切割成不同长度的时空伴随域名序列.本文认为在时间上同时触发的域名请求彼此存在伴随关系,存在明显的时间间隔的请求则不具有伴随关系.实际上,通过对真实DNS数据分析,本文发现每个用户所触发的DNS请求在时间上存在明显的分块聚簇现象,即DNS请求一批接着一批触发,不同批次之间存在明显时间间隔.例如在打开下一个网页之前,会在上一个网页停留一定的时间,从而导致这2次页面行为触发的域名请求之间也存在明显时间间隔.因此,如果2个域名请求之间的时间间隔大于给定的阈值(例如5 s),则很有可能是不同网络活动所触发的DNS请求,本文便将这2个域名划分到不同序列中,反之则划分到同一个序列中.每一个序列有1个或者多个域名组成,近似认为是由一次网络活动所触发的DNS请求集合,彼此具有时空伴随关系.
针对挑战2,本文借鉴Skip-Gram[9]的词向量表示算法,将每一个域名投影成d维实数空间中的一个点(向量),目标是使得具有伴随关系的域名映射成空间中距离相近的点;反之,把不具有伴随关系的2个域名映射到空间中相隔较远的位置.考虑到挑战1中提取的时空伴随域名序列可能会存在噪声干扰和由序列长度过长带来的计算复杂度问题,本文采用滑动窗口的方式,进一步从时空伴随域名序列中提取具有时空伴随域名对.每个时空伴随域名对由2个域名组成,彼此之间具有时空伴随关系,同时,本文采用负采样技术[8]构建不具有时空伴随关系的域名对作为负样本数据,最后结合优化目标迭代地调整每一个域名在Rd空间的位置.优化结束后,本文便可得到每一个域名特征向量.
与前人工作对比,本文工作主要有3点不同之处:
1) CoDetector自动地从DNS流量中挖掘潜在的域名伴随关系,并映射为特征向量,无需人工专家经验,省去人工设计特征的繁杂工作.
2) CoDetector仅利用域名请求的时间顺序挖掘伴随关系,无需额外的附加信息.因此,本文的方法更加轻量实时,能够处理不具有正常应答的恶意域名,例如DGA生成的NXDomain域名.
3) CoDetector将具有伴随关系的域名进行了聚类,因此可以用于恶意域名团伙发现.
最后,本文采集一个企业网下近2个月的DNS流量数据,结合3种主流的机器学习分类算法(随机森林、XGBoost和深度神经网络)来评估CoDetector模型的检测效果.实验结果表明,CoDetector平均能够达到91.64%的检测精度和96.40%的召回率.因此,CoDetector能够有效地通过DNS流量挖掘域名请求之间时空伴随关系,并用于检测恶意域名.
总体来说,本文工作具有4点贡献:
1) 提出一种基于时间间隔的域名序列切割算法,能够有效地从DNS流量中提取具有伴随关系的域名序列.
2) 提出一种无监督的域名张量化表达算法,能够将每一个域名映射为低维空间的特征向量并且保留域名彼此之间的伴随关系.
3) 提出一种基于域名请求之间时空伴随关系的恶意域名检测算法——CoDetector.该模型自动地从原始DNS流量挖掘潜在的域名时空伴随关系,并用于检测恶意域名.
4) 结合真实DNS数据,对CoDetector的可行性和有效性进行评估,实验验证CoDetector能够有效地检测恶意域名.
1 相关工作
近年来出现了大量利用DNS流量检测恶意域名的研究工作.Antonakakis等人[5]提出了Notos动态域名打分系统.Notos主要提取3种类型的特征:1)基于网络位置的特征(历史上与域名关联的IP数量、地理位置的多样性、它们驻留的不同自治系统的数量等);2)基于域名Zone文件的特征(如域名不同gram分布的平均长度、不同顶级域名的数量、字符频率等);3)基于历史证据的特征(如域名解析的IP地址中有多少曾经在恶意样本中出现、该域名是否在蜜罐系统中捕获等).Bilge等人[6]提出了Exposure恶意域名检测系统.Exposure克服了Notos的部分限制,它能够识别之前从未在恶意活动中看到的恶意域名和地址,并且只需要较短时间的训练数据.Bilge等人从DNS流量中为每一个二级域名提取了15个特征,其中包括新颖的基于时间的特征(短生命周期、每日访问相似度、重复模式、访问成功的比率等)、基于DNS应答的特征(不同IP地址的数量、不同国家的数量、共享IP地址的域名的数量、反向DNS查询结果)、基于TTL值的特征(TTL的平均值、TTL的标准偏差、不同的TTL值的数量、TTL变化的数量)和基于域名词法的特征(数字字符的百分比和最长有意义的子字符串的标准化长度).Antonakakis等人[7]提出Kopis系统.与Notos和Exposure相比,Kopis使用了DNS系统中更高层次域名流量数据(顶级域名服务器和权威域名服务器采集到的DNS流量).因此,Kopis从更加全局的角度来提取每一个域名的行为,其中包括基于请求来源分布的统计特征(例如与递归DNS服务器相关联的IP地址的多样性)和请求来源在每个时期结束时向给定域名的DNS流量,递归DNS服务器的相对查询量以及与域名指向的IP空间相关的历史信息.这些方法主要是通过针对每一个域名的提取局部特征,并利用机器学习分类器来构建检测模型.可能存在的问题是:如果这些检测方法(特征)被敌手了解之后,很容易通过合理的调整来规避这些特征,逃过检测.本文提出的CoDetector模型是考虑了域名之间的潜在时空伴随关联特性.如果敌手想要绕过CoDetector的检测,需要消除其使用的恶意域名之间的时空伴随特性.例如每次只使用一个域名,然而这极大地降低了恶意活动的灵活性.
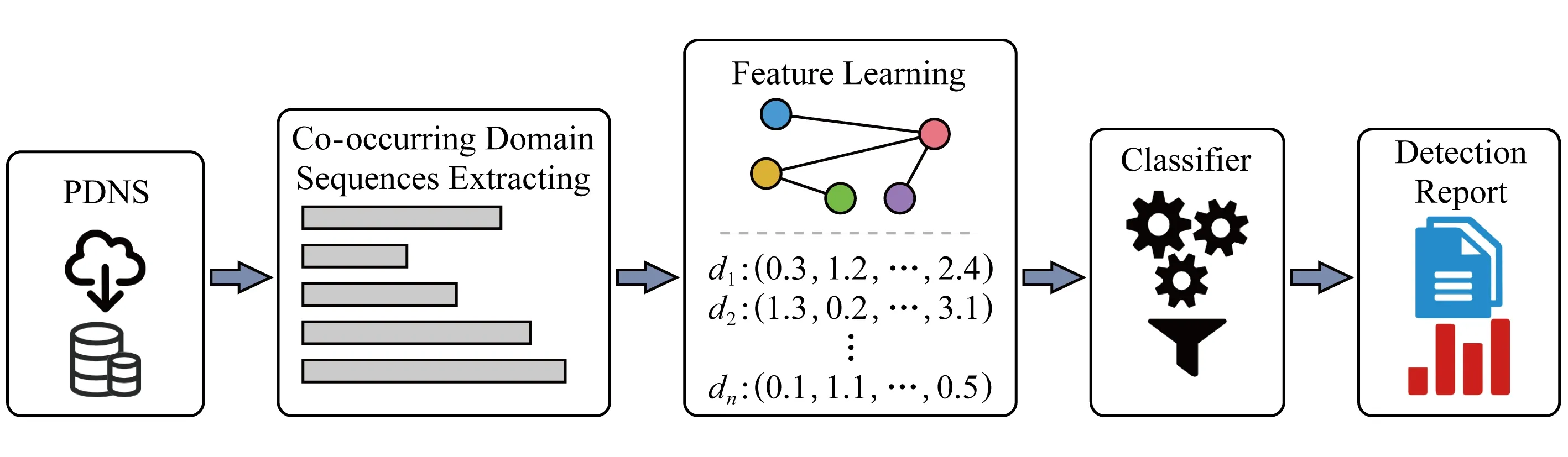
Fig. 1 The workflow of CoDetector图1 CoDetector模型工作流程图
Khalil等人[10]提出利用域名和IP之间的全局关联来检测恶意域名.其主要思路是利用(域名、IP)映射数据构建域名关联图.如果2个域名映射到相同的IP,则在2个域名之间添加关联边.随后,在域名关联图使用基于图上路径搜索的机制来推断未知域名的恶意分数.Peng等人[11]提出了一种基于DNS CNAME记录的恶意域检测方法,该方法专注于没有解析到IP地址,但出现在DNS CNAME记录中的域名.该方法是基于CNAME记录连接的2个域名存在内在紧密关系,并且偏向于处于同样的性质(即同时是恶意域名或者同时是正常域名).他们提出一种基于置信传播的图推理方法,通过计算未知域名与其他已知恶意和正常域名的全局关联来计算其恶意概率.他们的实验结果表明,该方法可以有效揭露被以往研究工作所忽略的恶意域名.Manadhata等人[12]提出了一种基于图推断方法的恶意域名检测模型.该模型首先利用企业网络中的DNS数据构建了一个主机-域名二分图,其中如果一台主机访问了某个域名,便在该主机和该域名之间添加关联边,最后利用置信传播(belief propagation)算法在图上进行推断.文献[13]提出了利用DNS服务器与用户之间通信的DNS数据来构建域名主机二分图,其主要假设是访问恶意域名的机器更有可能是感染的机器,反过来感染的机器访问的域名也更有可能是恶意域名.然而,上述方法利用DNS服务器与用户之间的DNS数据,会带来隐私问题.文献[14]提出利用DNS数据检测长周期下APT中隐蔽可疑的DNS行为.
本文并不是第1个提出利用域名请求伴随关系来检测恶意域名的研究工作.Gao等人[15]提出了一种基于域名请求伴随关系来检测恶意域名团伙的算法.该工作利用部分已知的恶意域名作为种子,统计域名和种子伴随出现的关系,采用TF-IDF算法和XMeans聚类算法来提取域名团伙.然而,该工作首先未考虑域名请求之间的时间间隔,因此会将属于不同网络活动触发的域名划分到一个团伙中,存在严重的噪声干扰.本文提出的模型能够自动地挖掘域名的伴随关系,且具有线性的时间复杂度,适合在大规模数据上运行.
2 CoDetector检测模型
本文发现主机层面的域名请求之间存在伴随共现关系,并非互相独立.因此,通过考虑一个域名经常和哪些域名伴随出现能够有效地协助决策该域名是否是恶意域名.本文的基本假设是具有时空伴随关系的域名之间存在紧密的关联,在性质上(恶意性质或者正常性质)具有同态性.具体来说,如果一个域名经常和恶意域名伴随共现,那么该域名偏向于是恶意域名,反之亦然.CoDetector模型首先从DNS流量中提取彼此具有时空伴随关系的域名,形成时空伴随域名序列集合;随后利用深度学习算法在保留域名彼此伴随关系的同时将每个域名投影成低维实数空间的特征向量;最后结合部分已知的黑白域名,利用机器学习分类算法构建恶意域名检测分类器,用于识别未知的恶意域名.
图1展示了CoDetector检测模型的工作流程,其主要分为3个模块.
1) 时空伴随域名序列提取模块.利用域名请求的先后时间顺序将原始域名数据进行粗粒度的聚类,划分为不同的序列,使得每一个序列中的域名彼此具有时空伴随关系.
2) 特征学习模块.构建映射函数f:D→Rd将每一个域名x∈D映射为d维空间的特征向量vi,同时保留域名之间的时空伴随关系,即将具有伴随关系的域名映射到Rd空间中距离相近的点,把不具有伴随关系的域名映射到距离遥远的点.
3) 恶意域名检测模块.利用特征学习模块中学习到的每个域名的特征向量,结合部分黑白域名列表,采用有监督的机器学习算法训练恶意域名分类器,并应用于对更多未知属性的域名进行检测.
详细介绍每一个模块的设计,最后给出模型时间复杂度分析.
2.1 时空伴随域名序列提取
本模块首先针对原始DNS流量进行粗粒度的聚类操作,将彼此具有伴随关系的域名划分在同一个域名簇中,形成时空伴随域名序列结合.通过对真实的DNS流量分析,本文发现每个用户的DNS请求具有明显分块聚簇的特点,在时间顺序上存在聚类的现象.用户的域名请求一批接着一批发起,不同批次之间的DNS请求具有明显的时间间隔.
图2展示了本文采集到的部分用户在10 min时间段内的域名请求时间散点分布图,x轴为时间,图2中每个点代表一次DNS请求,不同直线代表不同用户的DNS请求随着时间的散点分布.本文发现,每一个用户的域名请求在时间线上呈现成块行为.例如用户u7,u8,u9的域名请求数据存在明显的聚簇现象,同簇之间的请求几乎同时发起,簇与簇之间存在明显时间间隔.因此,本文近似地按照域名请求时间进行粗粒度的聚类,认为每簇中的域名彼此伴随出现,形成一个时空伴随域名序列.
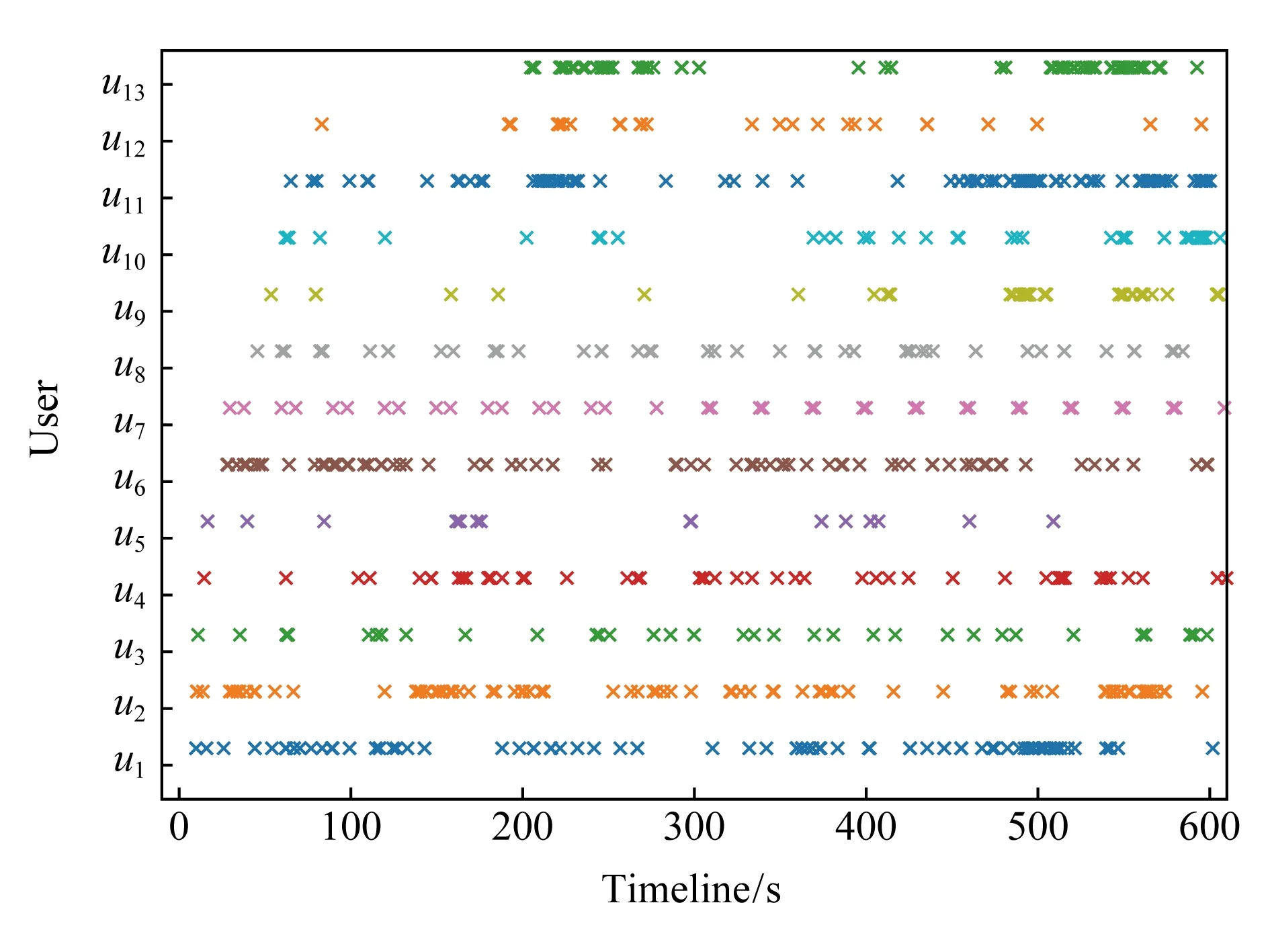
Fig. 2 The scatter of DNS queries in 10 min图2 10 min内部分DNS数据请求散点图
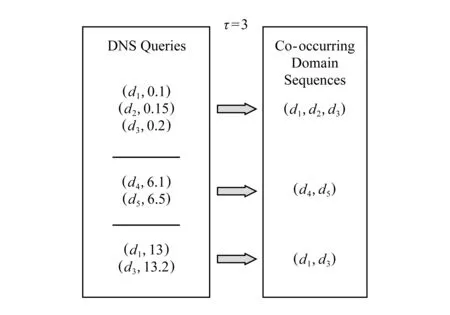
Fig. 3 An illustration for generating co-occurring domain sequences图3 时空伴随域名序列生成说明图
2.2 特征学习
假设S={S1,S2,…,Sn}为提取到的时空伴随域名序列集合,其中Si={d1,d2,…,dni}是由ni个域名构成的序列.本模块的目标是在保留域名彼此之间的伴随关系的同时,将每一个域名映射成低维空间的特征向量.本文把映射操作形式化为似然概率最大化问题:
首先,每一个时空伴随域名序列Si的概率P(Si)=Pr(d1,d2,…,dni)为这ni个域名联合出现的概率.因此,映射操作的基本优化目标是最大化序列集合S的概率,即:
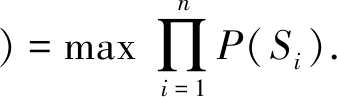
(1)
然而,最大化该目标函数在现实计算中存在问题,尤其是当序列长度ni过大而带来的联合概率计算呈指数增长的复杂度.近年来,Skip-Gram[9]语言模型在自然语言处理问题上取得了极大的成功,其主要思想是通过一个单词来预测其上下文出现的单词.启发于Skip-Gram模型,本文提出基于滑动窗口的思想来将长度为ni的序列Si分解为多个短小的子序列,即只保留域名和其窗口内域名的时空伴随关系,而忽略其和更远位置的域名关系,从而极大地降低了计算复杂度.本文假设:
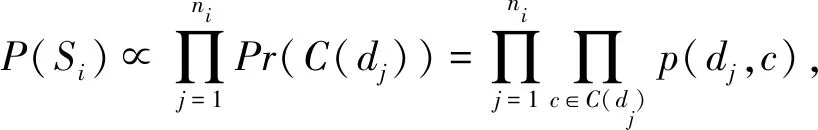
(2)
其中,C(dj)为域名dj的上下文.假设窗口大小为w,则C(dj)=(dj-w,dj-w+1,…,dj-1,dj+1,dj+2,…,dj+w),更进一步分解为2w组具有时空伴随关系的域名对{(dj,dj-w),(dj,dj-w+1),…,(dj,dj-1),(dj,dj+1),(dj,dj+2),…,(dj,dj+w)}.
图4展示了利用滑动窗口从时空伴随序列S生成时空伴随域名对的示意图,其中该序列S是由7个域名组成,滑动窗口w=2.采用滑动窗口的方式将时空伴随域名序列分解成时空伴随域名对的操作能够带来2点改进:1)滑动窗口的引入成功地消除了由于序列长度过长而带来的计算复杂度增长的问题,使得在现实中计算成为了可能;2)滑动窗口能够有效地减少噪声伴随关联(将本身不具有时空伴随的域名错误地认为具有时空伴随关系).窗口滑动的方式保证了每一个域名只和其固定窗口大小内的域名具有伴随关系,保证了域名伴随关系的质量.
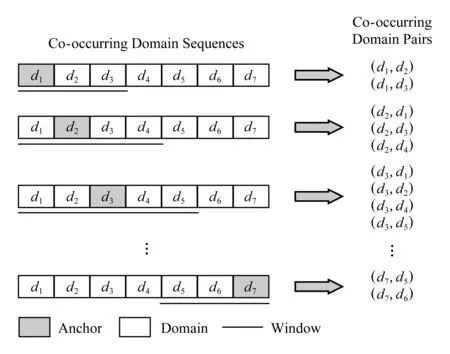
Fig. 4 An illustration for generating co-occurring domain pairs (w=2)图4 基于滑动窗口(w=2)的时空相似域名对生成示意图
基于以上改进操作,优化目标函数式(2)为
(3)
其中,P为基于滑动窗口操作提取的所有具有时空伴随关系的域名对集合.
假设f:D→Rd为映射函数,将每一个域名di∈D投影成实数空间Rd中的一个向量vi.本文采用Sigmoid函数来衡量这2个域名di和dj的联合概率,即
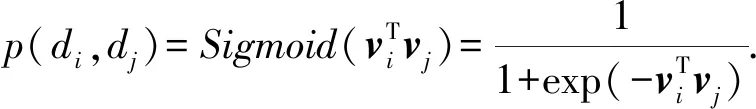
(4)
更进一步,由于式(3)中只考虑了具有时空伴随关系的域名对之间的映射关系,而忽略了将不具有时空伴随关系的域名投影成Rd空间中距离较远的向量,因此一个通用的映射方式是将全部域名映射到一个点上.为此,本文采用负采样技术[8]构建不具有时空伴随关系的域名对,并最小化这部分域名对的联合概率.所以,最终本文的目标函数是:
(5)
其中,P是所有具有时空伴随关系的域名对集合,N是通过负采样技术生成的不具有时空伴随关系的域名对集合.本文通过随机梯度下降(stochastic gradient descent, SGD)[16]算法来最小化目标函数.迭代结束之后,本文便得到每个域名di在Rd空间中的特征向量vi.
2.3 恶意域名检测模块
通过最小化式(5),本文将S中每个域名表达成d维空间的特征向量.本文通过提前采集的黑白域名列表匹配S中的域名,从而获取部分有标签的数据,再结合机器学习分类算法构建恶意域名检测分类器,用于检测未知的恶意域名.
2.3.1 训练阶段
结合域名黑白名单,匹配数据集中出现的域名,本文获得部分标记的恶意域名和正常域名.利用成熟的有监督的机器学习分类算法(如随机森林),结合这部分域名在特征学习阶段学习到的特征向量,最终得到恶意域名检测分类器π:v→s,其中v为域名对应的特征向量,s∈[0,1]为该域名的恶意打分.
2.3.2 检测阶段
针对其余部分未知属性的域名,本文利用训练阶段学习的分类器进行分类,从而检测未知的恶意域名.对于域名待检测域名di,假设其在特征学习阶段对应的特征向量为vi,则其恶意打分为si=π(vi).如果si>0.5,则判定域名di为恶意域名,其分数越高,则代表域名di为恶意域名的可能性越大.
2.4 模型时间复杂度分析
CoDetector共分为3个阶段.
阶段1. 将DNS流量切割,按照采集到的DNS的先后顺序根据时间便可以切割,因此时间复杂度为O(n),其中n是DNS流量中域名请求的数量.
阶段2. 可以细分为3个部分:
1) 利用滑动窗口的方式生成时空伴随域名对,针对每一个域名,最多形成2w个伴随域名对,因此,本文最多共有2wn个域名对,且时间复杂度为2w×O(n).
2) 利用负采样技术生成和正样本同数量级的负样本,假设针对每一个域名通过随机的方式(如Hash采样)生成K个负样本(本文中K=5),因此,最多有2Kwn个负样本域名对,且时间复杂度为K×2w×O(n).
3) 式(5)可以分解为对每一个时空伴随域名对进行优化调整.结合正负样本,最多有2w×(K+1)×n个域名对.针对每一个时空伴随域名对优化迭代一次的复杂度为d,假设迭代M次,那么式(3)最终的复杂度为M×2w×(K+1)×d×O(n).
由于M,K,w,d均远小于n,因此第2阶段的时间复杂度为O(n).
阶段3. 利用已知的黑白域名和其在Rd空间的特征向量来训练模型分类器.其复杂度与分类器算法的选取和黑白域名的样本数量有关系.例如,本文选择随机森林算法作为分类器算法,共m棵树,训练样本数量为N,则复杂度为O(m×d×NlogN),由于N为训练样本数量,相对于全部域名数量n是很少的一部分,因此这部分的复杂度相对于第1阶段和第2阶段均为常数.
因此,CoDetector模型的计算量主要集中在第1阶段和第2阶段中,综合起来复杂度为O(n),其中n是DNS流量中域名请求的数目.
3 实 验
3.1 数据集
1) 域名黑名单.本文通过采集网络公开的黑名单列表来构建本文中的域名黑名单,其中包括Malware Domains List[17],Phishtank[18],Openphish[19],AbuseList[20].本文从2017-01-03—2017-10-14,持续不断地收集这些来源的黑名单,最后保留去重的域名列表.除此之外,本文还采集了宙斯(Zeus)病毒中使用的恶意域名和著名的蠕虫病毒飞客(conficker)[21]中通过DGA算法生成的恶意域名.这些黑名单列表包含了形式多样的恶意域名,如僵尸网络命令与控制通道的域名、偷渡式下载域名、网络钓鱼、垃圾邮件、网络诈骗勒索等域名,能够很好地覆盖各种不同类型的网络攻击.更进一步,为了保证本文中使用的黑名单列表的可靠性,本文采用Google Safe Browsing[22]来进一步针对从Phishtank和Openphish采集到的域名做2次筛选,只有当Google Safe Browsing也认为该域名是恶意域名,本文才将该域名保留.
2) 域名白名单.本文根据Alexa[23]每天提供的全球访问量最多的100万域名(例如google.com)列表来构建本文的白名单域名列表.本文筛选那些长时间(如1年)持续排名在Alexa Top 20000的域名作为本文的正常域名.通过持续排名的条件可以有效地删除噪声域名,例如僵尸网络的域名在攻击活动发生时会存在短暂的访问量爆发,从而有可能出现在Top 20000列表中.实验中,本文收集了2015-01-16—2017-03-05共计513天的Alexa Top 100万域名列表,本文共发现9216个域名持续地出现在这513天的Top 20000域名中.
3) DNS数据.本文中使用的DNS数据集是在一个企业网内部网关捕获的2个月(2017-10-13—2017-12-18)的DNS流量,其中共包含12 291 055条DNS请求数据包.表1列举了本文的实验数据,其中包括采用基于时空时间的切割算法生成的时空伴随域名序数目、基于滑动窗口生成的时空伴随域名对数目,以及匹配到的正常域名和恶意域名的数目.
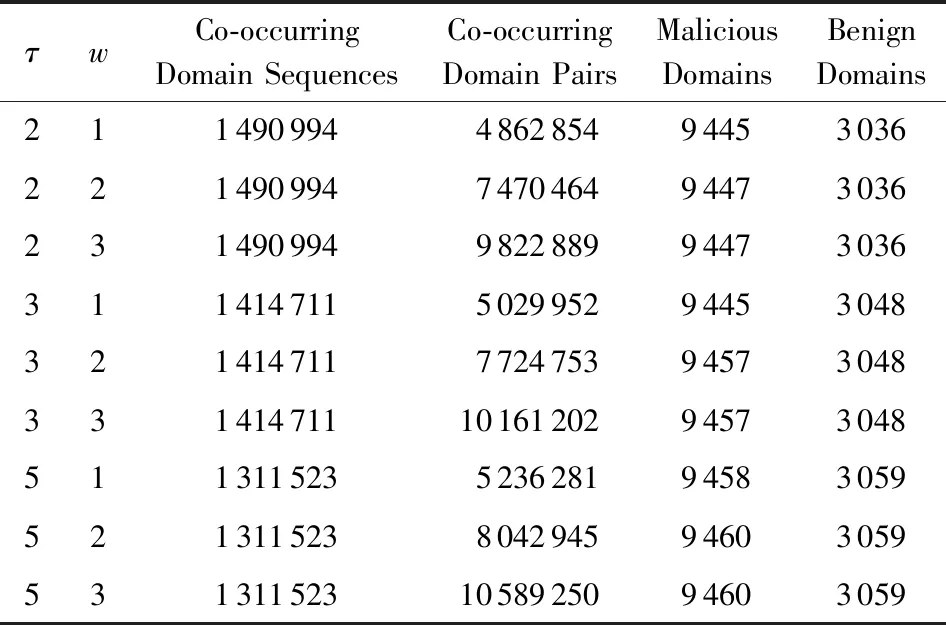
Table 1 Description of Experimental Data表1 实验数据描述
3.2 评价指标
为了定量化地衡量CoDetector模型对恶意域名检测的效果,本文采用3个指标.
1) 召回率(Recall,R).测试集中所有的恶意域名样本,CoDetector能成功识别出恶意域名的比例.
2) 检测精度(Precision,P).在测试集数据中,CoDetector判定为恶意域名的样本中确实是恶意域名的比例.

3.3 域名伴随关系分析

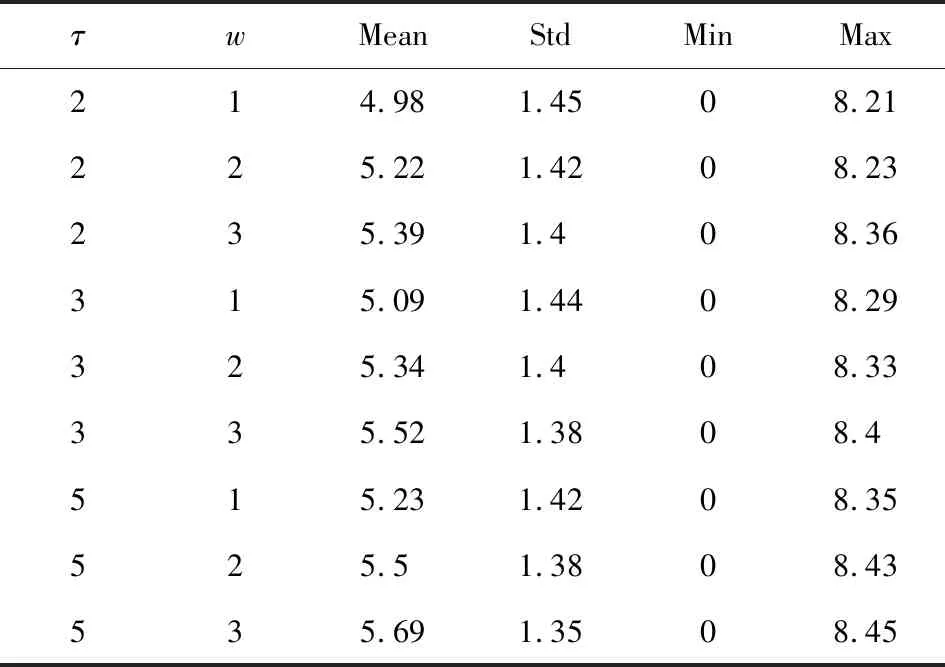
Table 2 Statistic Results of Shannon Entropy Under Different Parameters表2 不同参数下的香农熵统计结果
表2列举了这1 315个域名在不同切割时间间隔τ={2 s,3 s,5 s}和不同窗口大小w={1,2,3}下生成的伴随分布及其对应的香农熵统计特征.注意到如果伴随分布是安全随机的,则伴随分布的香农熵应该为lb 1 315=10.36.第1列代表时间间隔τ和窗口大小w的选择,第2~5列列举了在该组参数下1 315个域名香农熵的统计特征(平均值、标准差、最小值和最大值).
在这9组参数下,这1 315个域名的香农熵均远小于10.36,其中平均值不到10.36的一半,最大值约为10.36的80%.数据结果表明:域名的伴随分布并不是均匀分布,而是存在偏向性.因此验证了用户层域名请求之间具有时空伴随关联关系.
3.4 模型假设验证
CoDetector模型的基本假设是具有时空伴随关系的域名之间具有强关联,偏向同时属于恶意域名或者正常域名,即同态性.实验中,本文首先利用采集到DNS流量对模型假设的合理性进行验证.本文主要从2个方面进行验证:1)在包含恶意域名的时空伴随域名序列中,其他域名是否更加偏向于是恶意域名;2)在滑动窗口生成的时空伴随域名对中,如果一个域名是恶意域名,另外一个域名是否偏向于是恶意域名.注意本文只对和恶意域名伴随出现的域名的性质分布进行统计来评估同态性.因为本文的主要目的是为了检测恶意域名.
3.4.1 时空伴随域名序列同态性验证
给定切割时间间隔τ,本文将原始DNS流量切割成具有时空伴随关系的域名序列集合S.利用采集到的域名黑名单,本文标定序列中每一个域名是否是恶意域名.本文定义q(S)为序列S中恶意域名的个数,记Sn={S|q(S)≥n,S∈S},为S中包含恶意域名个数大于等于n的序列子集合.本文记包含恶意域名的时空伴随域名序列为可疑时空伴随域名序列.统计集合Sn(n≥1)中,恶意域名所占的比例为δ,如果δ>0.5则说明在Sn中的域名更多的是恶意域名,从而验证假设.选择3种不同的时间间隔τ={2 s,3 s,5 s}生成时空伴随的域名序列集合,并针对4种粒度的包含恶意域名的时空伴随域名序列子集,n={1,2,3,4}统计恶意域名所占的比例δ.
图5展示了包含恶意域名的时空伴随域名序列中恶意域名所占的整体比例δ,其中横坐标代表S中的不同子集S1,S2,S3,S4.首先,注意到所有子集中恶意域名比例均大于50%,且使用相对较小的时间间隔τ切割生成的时空伴随域名序列中恶意域名所含比例越高.另一方面,结果表明随着序列中包含的恶意域名数目增加,序列在整体上是恶意序列的概率也在变大.
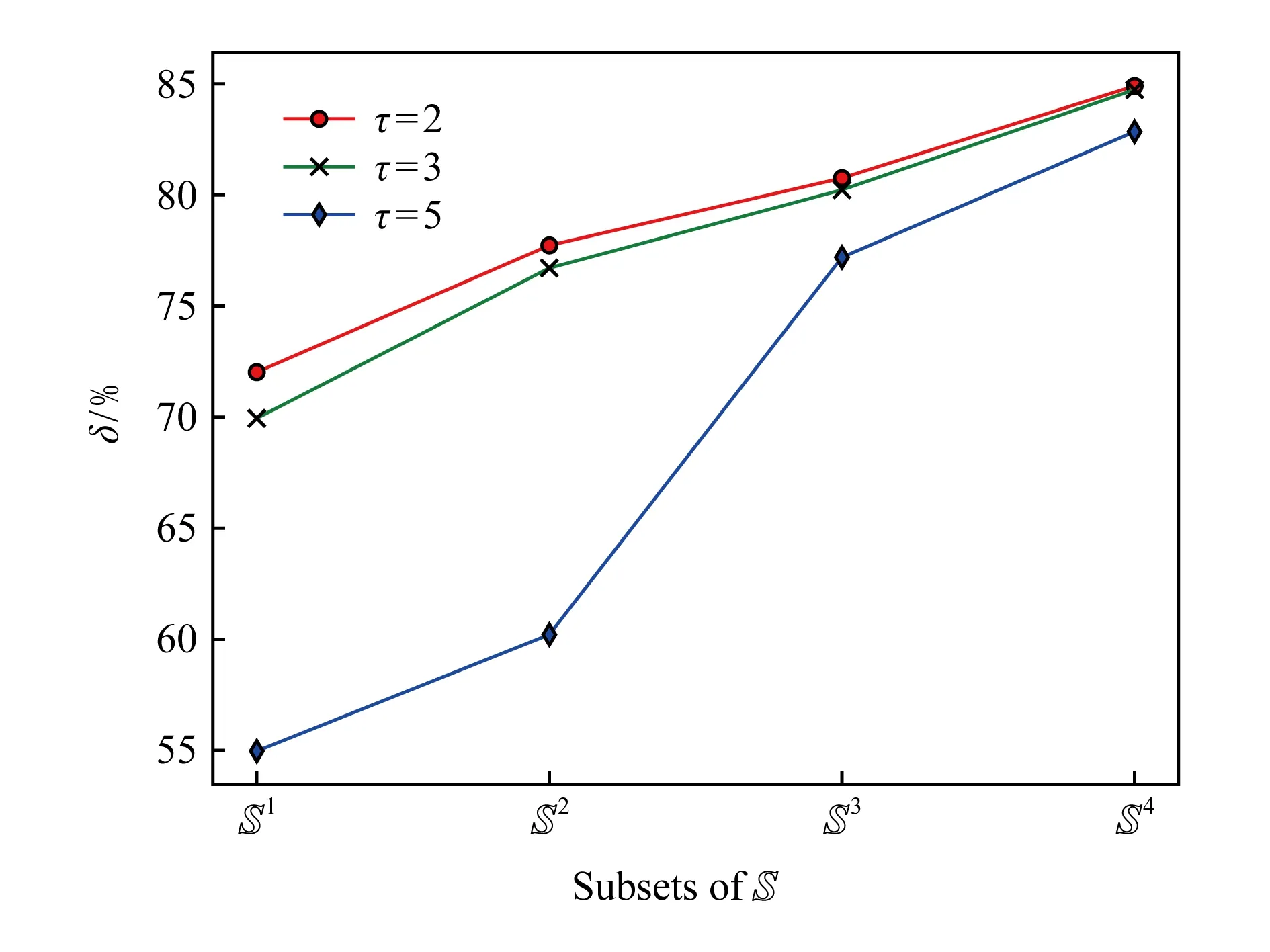
Fig. 5 Homomorphic ratio of malicious property in co-occurrence domain sequences图5 伴随域名序列中恶意属性同态比例
3.4.2 时空伴随域名对同态性验证
基于滑动窗口的方式,本文从时空伴随域名序列集合S生成时空伴随域名对集合P.针对集合P中每一个域名对(di,dj),本文统计当域名di是恶意域名时dj同样是恶意域名的比例δ.实验中,本文选择时间间隔参数τ={2 s,3 s,5 s},滑动窗口大小w={1,2,3},针对生成的9个时空伴随域名对集合P分别计算δ.结果如图6所示,其中横坐标w为滑动窗口的大小,纵坐标为当域名对(di,dj)同时是恶意域名的比例δ.
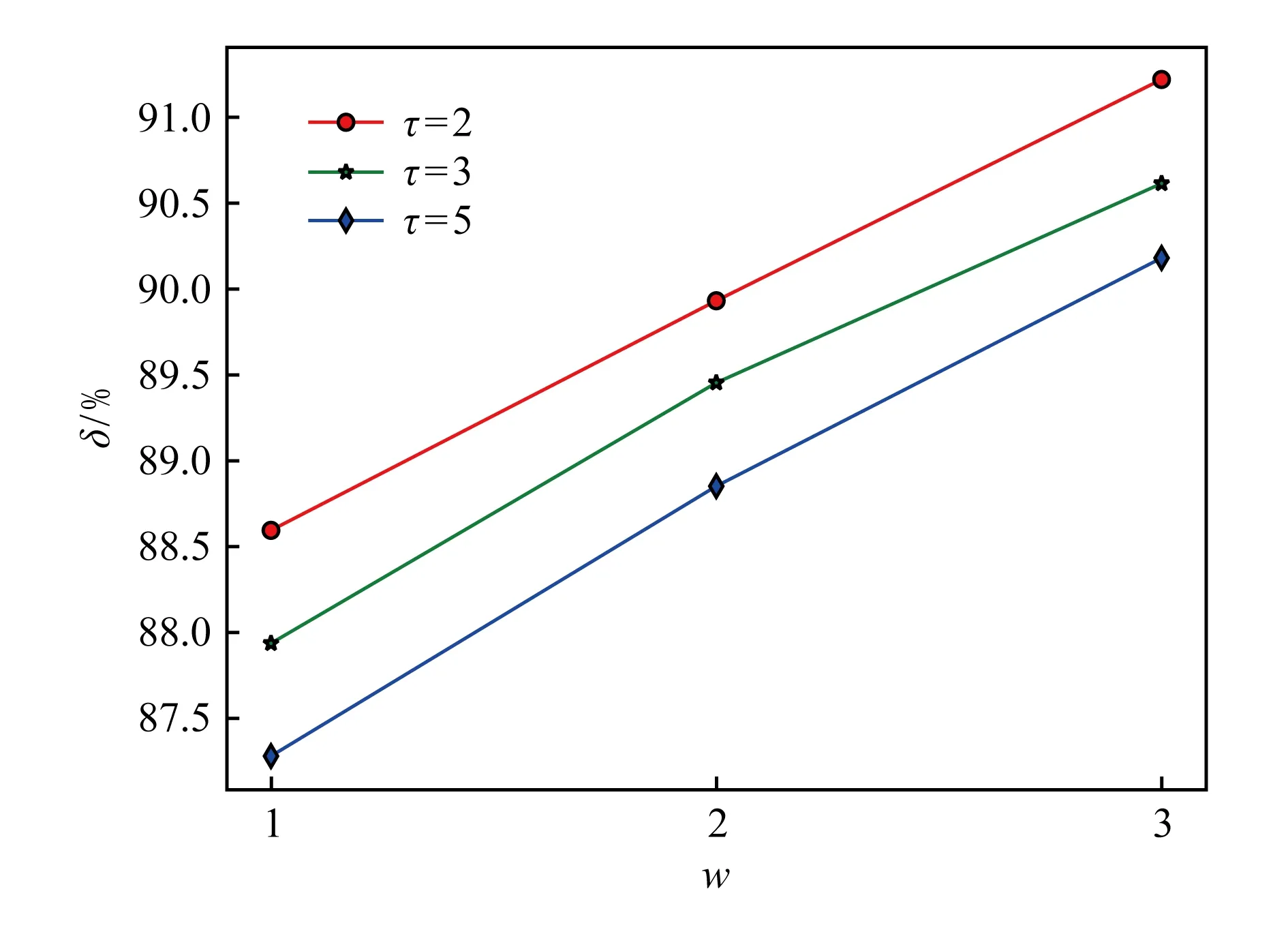
Fig. 6 Homomorphic ratio of malicious property in co-occurrence domain pairs图6 伴随域名对中恶意属性同态比例
本文发现:1)在时空伴随域名对中,如果一个域名是恶意域名,另外一个域名也是恶意域名的比例平均为89.34%,即域名在时空伴随域名对中同样保持同态性;2)通过滑动窗口生成的时空相似域名对能够有效地提高域名之间的同态性.例如当w=1时,如果di是恶意域名,dj是恶意域名的概率高达88%,且随着窗口w的变大,同态性也有所提升.这一结果进一步验证了本文实验的假设,即具有时空相似性的域名之间同时在域名性质上具有同态性.
3.5 模型检测效果
CoDetector模型涉及到3个主要参数:1)序列切割时间间隔τ;2)滑动窗口大小w;3)每个域名的特征的维度d.实验中本文选取τ={2 s,3 s,5 s},w={1,2,3}和d={100,200,300},共27种参数组合.针对每一组参数θ=(τ,w,d),本文采用标准的10-Fold交叉验证的方式来评估实验效果.首先,本文将训练数据集随机平均地分为10份,其中9份作为训练集,剩下1份作为测试集,获取在测试集上的检测效果.如此重复10次,并将10次的平均结果作为这组参数的最终实验结果.本实验全部运行在一个具有8核Inter®CoreTMI7-6700K CPU@4.00 GHz、内存为32 GB的服务器.
本文选用3个主流的有监督的机器学习算法作为恶意域名检测的分类器.
1) 随机森林(RandomForest).随机森林是通过集成学习的思想将多棵决策树集成的一种算法.本文利用scikit-learn[24]机器学习库来实现随机森林分类器.主要参数设定为:n_estimator=200,min_samples_split=11.其他参数默认.
2) XGBoost.XGBoost[25]是一种面向基础的GradientBoosting算法的优化版本,具有高效的运行效率、灵活性和可移植性.本文采用其公开的Python库来训练本文的分类器模型,参数设置为max_depth=6和num_boost_round=100,其他参数默认.
3) 深度神经网络(deep neural network, DNN).本文构建了一个4层的深层感知机模型.第1层是输入层,接受通过时空相似表达模块学习的向量;第2层是隐藏层1,包含nh1个神经元;第3层是隐藏层2,包含nh2个神经元;第4层是输出层,输出1个2维的向量,第1个元素代表是正常域名的概率,第2个元素代表是恶意域名的概率.层与层之间采用全连接网络进行连接,并采用Relu非线性激活函数来增加模型的非线性能力.最后1层本文采用softmax函数来对最终的结果进行归一化.本文结合人为经验设定nh1=128和nh2=64,采用交叉熵损失cross_entropy函数来衡量模型的效果.最后,本文通过随机梯度下降SGD[16]算法来最小化损失函数.
表3列举了CoDetector模型在这27组参数设置下利用3种分类器算法在训练集数据上通过10-Fold交叉验证得到的检测效果.RandomForest平均能够达到93.97%的F-Measure、91.80%的精度和96.30%的召回率.XGBoost平均能够达到94.06%的F-Measure、91.41%的精度和96.90%的召回率.DNN平均能够达到93.85%的F-Measure、91.76%的精度和96.05%的召回率.因此,在3种不同的分类算法下,CoDetector模型均能够有效地检测恶意域名.
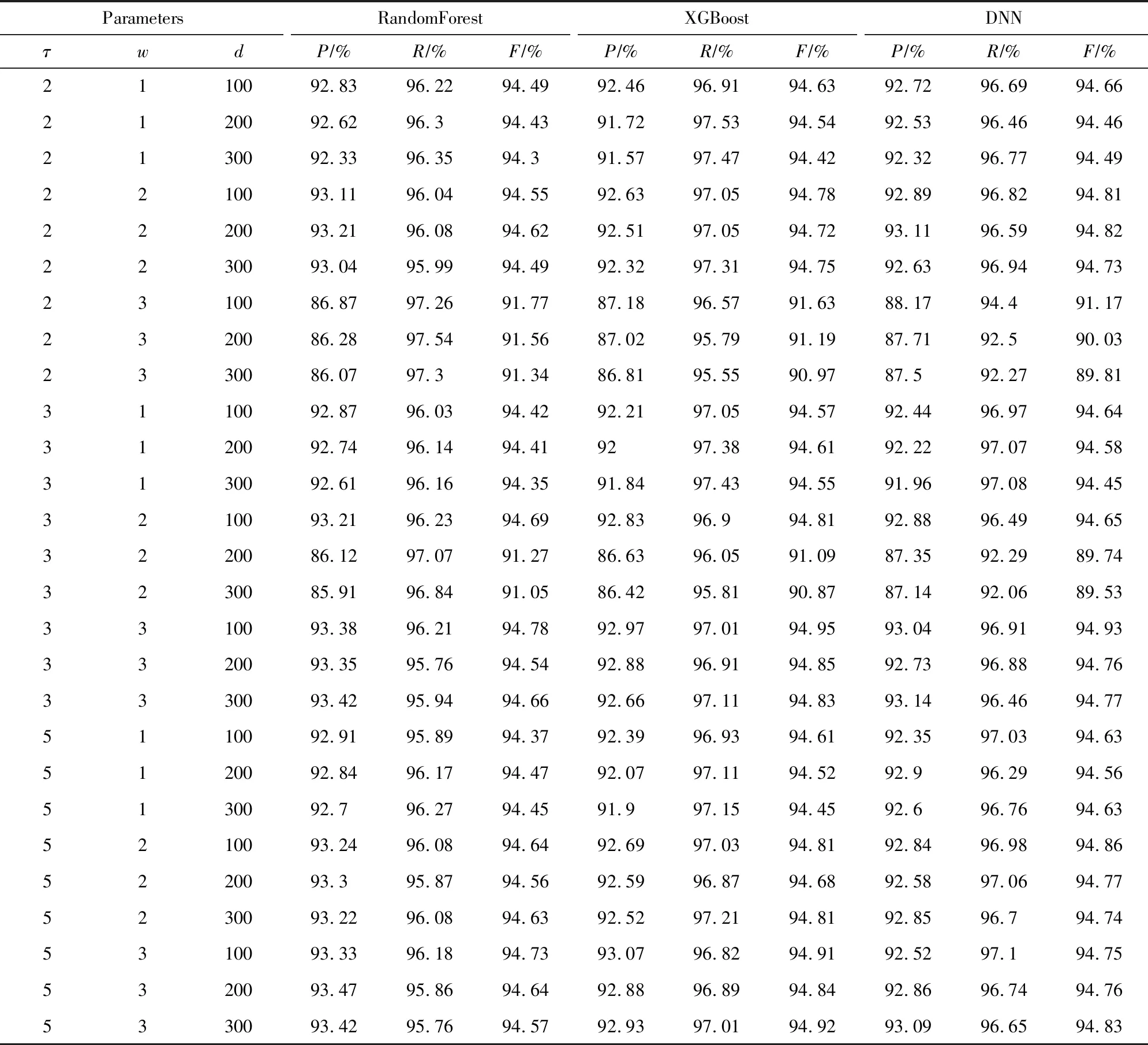
Table 3 Detail Performance of CoDetector under the 27 Parameter Settings Using 3 Classifiers with 10-fold Cross Validation表3 27组参数下CoDetector基于3种分类器算法10-fold 交叉验证的检测效果
4 讨 论
CoDetector通过挖掘域名请求之间的伴随关系来进行恶意域名判定.因此,对本文的模型可能会存在的问题进行讨论.
1) 噪声伴随.本文通过基于时间间隔的切割算法来获取具有时空伴随的域名序列,然后通过滑动窗口的方式提取时空伴随域名对.其基本的原理是基于域名请求的先后时间顺序,因此后台网络活动触发的DNS请求可能会和当前的网络活动触发的DNS请求在时间上存在重叠,从而带来噪声干扰.然而,噪声干扰是属于小概率事件,通过长时间的数据累积,即可逐渐消除噪声带来的影响.
2) 攻击绕过.攻击者通过在其网络活动所必需的DNS请求中混杂其他非必需的DNS请求,从而制造虚假伴随关联关系.例如,在恶意网页中添加虚假外链,链接到已知的正常网站(如qq.com),从而制造其恶意域名和正常的域名伴随出现的假象.
3) 检测时空.CoDetector只能检测当前时空下采集到的DNS流量中的恶意域名.对于未来出现的未知域名,本文没有提前训练该域名的特征表示,CoDetector无法对其恶意性质进行判定.本文将在后续的工作中进行补充.
5 结 论
恶意域名是网络攻击活动中主要的基础设施.本文提出一种基于域名请求之间存在时空伴随关联的恶意域名检测算法,想法是如果一个域名经常和恶意域名伴随出现,那么该域名很大可能是恶意域名.本文首先提出基于时间间隔的时空伴随域名序列提取算法,从原始DNS流量中提取具有时空伴随关系的域名,接着采用深度学习算法将每一个域名映射为低维空间的特征向量,最后结合分类算法训练模型分类器.实验结果表明:CoDetector模型能够有效地检测恶意域名,具有91.64%的检测精度和96.04%的召回率.
猜你喜欢
电子产品世界(2022年4期)2022-04-21
密码学报(2021年4期)2021-09-14
计算机系统应用(2021年2期)2021-02-23
成都信息工程大学学报(2021年6期)2021-02-12
江苏教育研究(2020年2期)2020-04-10
江苏教育研究(2020年1期)2020-04-10
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
计算机应用与软件(2020年1期)2020-01-14
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
计算机测量与控制(2019年4期)2019-05-08
