
稀疏多元逻辑回归问题优化算法研究
2019-06-21 02:24雷大江李智星
重庆邮电大学学报(自然科学版) 2019年3期
雷大江,杜 萌,李智星,吴 渝
(1.重庆邮电大学 计算机科学与技术学院,重庆 400065;2.重庆邮电大学 软件工程学院,重庆 400065;3.重庆邮电大学 网络智能研究所,重庆 400065)
0 引 言
逻辑回归算法(logistic regression, LR)作为一种经典的分类算法,被广泛应用于诸如医学检测、地质测量、文本分类等领域。它针对二分类问题被提出,用于估计事件发生的可能性,例如某用户购买某商品的可能性,某病人患有某种疾病的可能性等。它是一种线性的分类算法,具有求解速度快、预测结果的可解释性强的特点。同时,由于其实现简单,在大规模数据的分类学习算法中也有不错的表现,因此,在学术界和工业界都有广泛的应用。然而,直接使用原始逻辑回归进行求解容易产生过拟合现象,更常见的做法是引入正则项。正则化逻辑回归,尤其是l1正则化逻辑回归,也称作稀疏逻辑回归(sparse logistic regression, SLR),SLR是近几年的研究热点[1-3]。使用正则化模型可以防止过拟合,有着重要的研究意义。此外,由于l1正则可以产生稀疏解,在高维数据处理中具有优势。
传统逻辑回归无法直接应用于多分类问题,通常有2类方法可以将逻辑回归拓展到多分类:①将k分类问题分解为多个二分类问题并采用one-vs-rest或者one-vs-one的策略进行分类[4];②称为多元逻辑回归(multinomial logistic regression, MLR),它是逻辑回归模型在多分类问题上的推广。对于多分类问题来说,类别之间通常是互斥的。因此,使用多元逻辑回归相较于逻辑回归通常能得到更高的分类精度[5]。同时,多元逻辑回归只需要训练一次即可,因此,它也具有较快的运行速度[5]。同理,引入了l1正则项的多元逻辑回归称作稀疏多元逻辑回归(sparse multinomial logistic regression, SMLR)[6], 在继承了稀疏逻辑回归稀疏解的同时也较好地处理了多分类问题。SMLR已经被广泛应用在图像中的多类物体识别[7]、高光谱图像分类[8]、生物信息学[9]等领域。可见,对SMLR问题进行求解具有重要的现实意义。B. Krishnapuram等[6]首次提出了采用迭代重加权最小二乘法(iterative reweighted least squares, IRLS)来求解SMLR问题,但该算法在处理高维数据集或者类别数过多的数据集时具有较高的计算复杂度[10],且近年来未有学者针对IRLS算法计算复杂度高的问题而展开研究。随着凸优化技术的发展,近年来也出现了很多新的优化算法,这为本文采用多种高级优化算法求解SMLR问题提供了更多的选择。
本文将首先介绍SMLR问题的原始求解算法IRLS[6],之后介绍几种近几年的稀疏优化算法,包括以下几种:①快速迭代软阈值收缩算法(fast iterative shrinkage-thresholding algorithm, FISTA)[11];②快速自适应收缩阈值法(fast adaptive shrinkage/thresholding, FASTA)[12];③交替方向乘子法(alternating direction method of multipliers, ADMM)[13],并会对上述几种优化算法进行拓展以求解SMLR问题。另外,考虑到SMLR在大规模场景下的应用,本文实现了SMLR问题的分布式求解,提升了算法的适用性。最后,将对各算法的性能进行比较,给出如何根据不同的场景来选择合适的优化算法的一些建议。本文的贡献如下。
1)提出了3种高效的SMLR问题的优化求解算法。
2)针对大规模数据的场景,提出了一种SMLR问题的分布式优化算法。
3)对本文提出的几种SMLR算法进行了实验,总结了在不同场景下使用SMLR算法的经验。
1 稀疏多元逻辑回归
稀疏多元逻辑回归算法基于多元逻辑回归,并在多元逻辑回归的基础上引入了拉普拉斯先验,使得它能够自动进行特征选择并识别出最优表达能力的特征子集,这让稀疏多元逻辑回归在一定程度上缓解了维度灾难的问题。因此,它很适合应用在多类别及多特征的场景中。下面将对稀疏多元逻辑回归算法进行简单的回顾。
假设,数据集D={X,Y}包含m个样本,n个特征,其中,X∈Rm×n,Y∈Rk×m,k为类别数。Y为One-Hot编码后的标签矩阵,即每个标签对应一个k维向量,该向量中仅有1个元素取值为1,其他元素取值均为0。对于给定一个样本X(i)∈R1×n和标签Y(i)∈Rk,样本X(i)属于类别j的概率可以表示为
(1)
且有
(2)
(1)—(2)式中:W=[w1,w2,…,wk]∈Rn×k;wi∈Rn为稀疏多元逻辑回归的参数矩阵。当类别数k=2时,稀疏多元逻辑回归就退化为经典的二分类模型,也即逻辑回归。
假设m个样本独立生成,则可以使用极大似然估计(maximum likelihood, ML)对模型参数W进行求解,即
(3)
在图像分类或者需要处理高维数据等特定领域中,人们通常期望求得的解具有一定的稀疏性。通常的做法是在损失函数中引入l1正则项,也等价于为参数W引入拉普拉斯先验p(W)。其中,p(W)∝exp(-λ‖W‖1)。此时,(3)式变为
L(W)=l(W)+log(p(W))=
(4)
(4)式中,λ>0为正则项超参数。
极大化对数似然函数等价于最小化负对数似然函数(negative log likelihood, NLL)。参数W的负对数似然函数如(5)式
(5)
将矩阵XW看作新的变量,第i个样本属于第j类的概率的对数可表示为
(6)
那么,所有样本属于某一类别的的概率可以由(7)式表示为
(7)
此时,(5)式可以重写为矩阵形式,有
(8)
且有
L(W)=l(XW)+λ‖W‖1
(9)
(9)式中,L(W)称为多元逻辑回归的损失函数。
求解带有l1正则项的目标函数通常可以得到稀疏解,这意味着参数W中的大部分元素取值为0,即有助于最小化代价函数的是参数中的非零项,这意味着l1正则化项起到了特征选择的作用。由于(9)式在原点不可微,无法求得解析解,因此,通常采用迭代的方式对稀疏问题进行求解,例如IRLS,FISTA,FASTA以及ADMM优化算法。
2 稀疏多元逻辑回归求解算法
2.1 迭代重加权最小二乘法
迭代重加权最小二乘法最早由D. Rubin等[14]于1983年提出,用于求解鲁棒性回归问题的回归系数。其优化求解的过程采用了极大似然法,新的解基于旧的解并不断迭代更新,因此,称为迭代重加权算法。而B. Krishnapuram等[6]在2005年提出的SMLR问题的原始求解算法[6]采用了类似的重加权方式来对参数进行求解,因此,文中将其称之为IRLS算法,后文中提到的IRLS也指SMLR问题的原始求解算法。
由于(2)式的存在,使得SMLR问题包含了一维冗余参数。在B. Krishnapuram等提出的求解方法中,IRLS算法的参数被表示为非冗余形式,也即w∈Rn(k-1)。为了统一符号,在本节中,l(w)表示为(3)式所示的SMLR问题的对数似然函数形式。
IRLS法通过以下方式对参数w进行估计,即
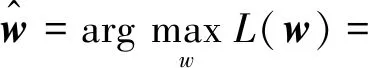
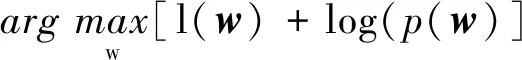
(10)
由于(10)式中包含拉普拉斯先验,无法直接使用迭代重加权的方式进行求解。B. Krishnapuram等借用边界优化算法的思想,通过引入代理函数Q,并对代理函数Q进行迭代最大化以达到优化L(w)的目的,那么有
(11)
且有
(12)
由于L(w)为凸函数,一种获得代理函数Q的方法是利用海森矩阵的下界。记B为负定矩阵且对所有的w都有H(w)≥B。那么,可以找到一个合法的代理函数,即
(13)
(13)式中,
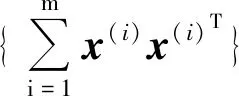
(14)
(14)式中:符号⊗称为克罗内克积(Kronecker product)且有1=[1,1,…,1]T。
l(w)的梯度可以表示为
⊗x(i)
(15)
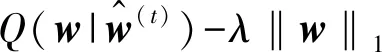
(16)
(16)式中,
(17)
最大化(17)式中的w有
(18)
(18)式的另一种等价形式为
(19)
(19)式中,
(20)
此时,参数w就能以迭代的方式进行更新。SMLR问题的IRLS求解算法步骤如算法1所示。
算法1:SMLR问题的IRLS求解算法
输入:
• 初始化参数:w∈Rn(k-1)
• 最大迭代次数:Iter
• 正则项参数:λ
输出:
• 算法最终的参数:wk+1
迭代步骤:
1: 初始化计数器k←0
2: 初始化参数wk←w
3: 使用公式(19)更新变量w
4: 当迭代到指定次数时算法终止,执行步骤5。否则,令k←k+1,返回步骤3。
5: 返回更新完成的算法参数wk+1
2.2 迭代阈值法
2.2.1 迭代软阈值收缩法
对于等式(5),ISTA的优化目标可以写为
(21)
(21)式中,W∈Rn×k。直接对(21)式进行求解并不容易,因此,可以先将其转换为比较容易求解的形式。将l(W)在Wt处做二阶泰勒展开,则有
(22)
取海森矩阵Hl(Wt)=I/τ,其中,I∈Rn×n的单位矩阵,变量τ为步长。则
(23)
那么,ISTA的目标函数为
(24)
此时,最小化问题变为
(25)
通过简单的代数变换,最小化(25)式可以被重写为以下形式,即
(26)
(26)式忽略了与最小化W无关的常量。对于最小化问题(26),可以快速的进行求解。记
W′t=Wt-τl(Wt)
(27)
则(26)式的解可以表示为Sλτ(W′t)。其中,软阈值操作Sλ:Rn→Rn被定义为
(28)
(28)式中,下标i表示逐元素执行软阈值操作。
步长通常可以取固定值τ=1/L,其中,L为利普希茨常数(Lipschitz constant)。但使用固定步长的一个缺点是利普希茨常数L不总是已知的,在大规模问题下其值也不易计算[11]。因此,A. Beck等给出了一个简单的线性搜索策略,步长τ的取值可以通过线性搜索(line search)的方式确定。SMLR问题的回溯ISTA算法的迭代步骤如算法2所示。
算法2:SMLR问题的回溯ISTA算法
输入:
• 初始化步长:τ=1/L,L>0
• 初始化参数:W∈Rn×k
• 最大迭代次数:Iter
• 回溯参数:β∈(0,1)
输出:
• 算法最终的参数:Wt+1
迭代步骤:
1: 初始化计数器t←0
2: 初始化参数Wt←W
3:Wt+1=pτ(Wt)
4:τ=βτ
6: 返回更新完成的算法参数Wt+1
2.2.2 快速迭代软阈值收缩法
FISTA通常被称为快速近端梯度法(fast proximal gradient method, FPGM)。它是一种应用广泛的快速一阶训练方法[11]。通过使用Nesterov加速策略对原始ISTA算法进行加速,能够将ISTA算法在最坏情况的收敛率由O(1/T)优化为O(1/T2),其中,T为迭代次数。
ISTA算法使用I/τ来近似估计海森矩阵,而FISTA算法则利用了梯度l(Wt)的最小利普希茨常数来近似估计海森矩阵。FISTA与ISTA的另一个区别在于,FISTA在最小化(26)式时并不是只使用了Wt,而是使用了前2次参数{Wt-1,Wt}的线性组合。基于同样的原因,FISTA也给出了带有回溯的版本。SMLR问题的回溯FISTA算法迭代步骤如算法3所示。
算法3:SMLR问题的回溯FISTA算法
输入:
• 初始化步长:τ=1/L,L>0
• 初始化参数:W∈Rn×k
• 最大迭代次数:Iter
• 回溯参数:β∈(0,1)
输出:
• 算法最终的参数:Wt+1
迭代步骤:
1: 初始化计数器t←0
2: 初始化参数Wt←W
3:Wt+1=pτ(Wt)
4:τ=βτ
6: 返回更新完成的算法参数Wt+1
2.3 快速自适应收缩阈值法
快速自适应收缩阈值法[12]是T. Goldstein等提出的一种快速优化算法,它对ISTA算法做了进一步的优化。由于梯度的优化算法通常对步长变化较敏感,FASTA采用了自适应步长的策略来自动调整步长大小。另外,它还使用了非单调的回溯线性搜索策略和混合的停止准则来进一步提高算法的收敛性。
2.3.1 自适应步长
FASTA算法采用了自适应的步长选择策略,可以通过实时的自动调整步长来实现快速收敛。它使用了谱方法(Barzilai-borwein, BB)[15]来自动选择步长τ=1/a,其中,a满足下面的条件
a(Wt+1-Wt)≈l(Wt+1)-l(Wt)
(29)
令△Wt+1=Wt+1-Wt,△gt+1=l(Wt+1)-l(Wt),那么有下述最小化问题:
(30)
(31)
求解最小化问题(30)和(31),并取τt+1=1/a,那么每一次迭代的步长大小为
(32)
(33)
最终的步长更新规则为
(34)
2.3.2 回溯线性搜索
在ISTA中,其回溯线性搜索的策略要求在每一次迭代中目标函数都要有充分的下降。但对于谱方法来说,即使是凸问题也不能保证收敛[16]。因此,在FASTA中采用了非单调的回溯线性搜索策略,该策略允许目标函数在有限的迭代次数内增加,而不是每一次迭代中都要求目标函数严格下降。其策略如下。
定义M>0为线性搜索的参数,且有
(35)
非单调的回溯线性搜索策略在每一次迭代中检查以下条件
(36)
当在迭代中违反了(36)式中的条件时,FASTA算法将会减小步长,直到条件满足。
2.3.3 停止准则
FASTA算法采用了基于残差的停止准则,其定义为
(37)
(37)式中,W′t+1由(27)式所定义。残差度量了目标函数l的梯度与l1正则项的负次梯度的差异。基于(37)式,FASTA算法定义了2种缩放不变型残差,一种是相对残差(relative residual),定义为
(38)
(38)式中,εr为取值较小正常数。
另一种是归一化残差(normalized residual),定义为
(39)
(39)式中,εn为取值较小正常数。
算法4:SMLR问题的FASTA求解算法
输入:
• 初始化步长:τ
• 初始化参数:W∈Rn×k
• 最大迭代次数:Iter
• 回溯线性搜索变量:M,β∈(0,1)
• 初始化收敛阈值:εr>0,εn>0
输出:
• 算法最终的参数:Wt+1
迭代步骤:
1: 初始化计数器t←0
2: 初始化变量Wt←W
3:Wt+1=pτ(Wt)
4:τ=βτ
5: 当满足条件(36)时,执行步骤6。否则执行步骤3。
6: 使用公式(34)更新步长
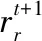
8: 返回更新完成的算法参数Wt+1
2.4 交替方向乘子法
2.4.1 串行SMLR求解算法
原始ADMM算法最早由D. Gabay等在70年代中期提出,主要用来解决一般形式的凸优化问题[17]。由于其简单性和可扩展性,S. Boyd等在2011年将其拓展到分布式机器学习领域。ADMM算法整合了对偶上升法(dual ascent)的可分解性和增广拉格朗日乘子法(augmented lagrangians and the method of multipliers)优秀的收敛性质[13],可以看作是在对偶上升法和增广拉格朗日乘子法基础上发展出的新算法。
采用ADMM求解SMLR问题时,主要考虑以下形式的凸优化问题,即
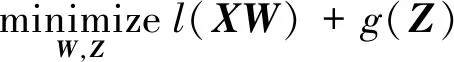
s.t.W-Z=0
(40)
(40)式中,W∈Rn×k和Z∈Rn×k为需要优化的变量。采用增广拉格朗日法来求解最小化问题(40),则其增广拉格朗日函数可以表示为
Lρ(W,Z,Y)=l(XW)+g(Z)+
(41)
(41)式中,l(XW)为(8)式所示的负对数似然函数,g(Z)=λ‖Z‖1为l1正则项。变量Y为对偶变量,ρ>0为惩罚参数。对于(41)式,ADMM的变量迭代更新公式为
(42)
(43)
Yk+1∶=Yk+ρ(Wk+1-Zk+1)
(44)
通过缩放(41)式中的对偶变量Y并合并后2项,可以将其写为更紧凑的形式为
(45)
(45)式中,U=Y/ρ。此时,ADMM的变量迭代更新公式为
(46)
(47)
Uk+1∶=Uk+Wk+1-Zk+1
(48)
由于ADMM具有可分解性,因此,通过将目标函数分解为l(XW)和g(Z)2项,迭代地对2个变量W和Z进行交替地更新,通过(40)式中的约束项保证2个变量趋于一致,直到收敛到最优解。ADMM算法通过使用原始残差rk+1和对偶残差sk+1来确定ADMM算法的收敛情况[13],2类残差分别定义为
rk+1=Wk+1-Zk+1,sk+1=ρ(Zk+1-Zk)
(49)
在ADMM算法的迭代过程中,(40)式中的线性约束逐渐满足,因此,原始残差逐渐趋于零。同时,目标函数接近最小值,即对偶残差趋于零。一种较合理的检测收敛性的方法是原始残差和对偶残差必须很小,迭代可以在以下情况下终止,即
(‖rk‖2≤ε); (‖sk‖2≤ε)
(50)
(50)式中,ε>0是控制收敛精度的参数。SMLR问题的ADMM求解算法的主要迭代步骤如算法5所示。
算法5:SMLR问题的ADMM求解算法
输入:
• 训练集:D={X,Y}
• 初始化参数:W,Z,U
• 最大迭代次数:Iter
• 收敛阈值:ε=10-4>0
• 超参数:λ,ρ
输出:
• 算法最终的参数:Zk+1
迭代步骤:
1: 初始化计数器k←0
2: 初始化变量Wk←W,Zk←Z,Uk←U
5:Uk+1∶=Uk+Wk+1-Zk+1
6:rk+1←Wk+1-Zk+1
7:sk+1←ρ(Zk+1-Zk)
8: 当满足‖rk+1‖2<ε且‖sk+1‖2<ε,或迭代到指定次数时算法终止,执行步骤9。否则,令k←k+1,并返回到步骤3。
9: 返回更新完成的算法参数Zk+1
2.4.2 并行SMLR求解算法
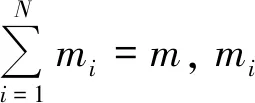
为了独立地对多个数据块进行处理,可以轻易地将(40)式所示的SMLR问题的原始优化目标写为(51)式的形式从而进行分布式优化,形式为
s.t.Wi-Z=0,i=1,…,N
(51)
(51)式中,
(52)
第i部分的目标函数li使用来第i个数据块来优化局部模型参数Wi,不同计算结点优化不同的局部变量。通过引入全局变量Z来保证局部变量与全局变量趋于一致。
最小化问题(51)的增广拉格朗日形式为
(53)
基于样本划分的SMLR问题可以采用迭代的方式进行求解,其变量迭代公式为
(54)
(55)
(56)
使用原始变量和对偶变量来判定算法的收敛情况,原始变量rk+1和对偶变量sk+1可以表示为
(57)
在(54)—(56)式中,第1步和第3步的计算可以分布在不同的计算结点。在第2步中,将会对各计算结点求得的局部变量Wi进行聚合并对全局变量Z进行更新。Z的更新问题可以看作Lasso问题,可以使用任何一种Lasso求解算法进行求解。上述步骤不断迭代以保证局部变量和全局变量趋于一致。SMLR问题的分布式ADMM求解算法的主要迭代步骤如算法6所示。
算法6:SMLR问题的分布式ADMM求解算法
输入:
• 经分区后的数据集:D={(X1,Y1),…,(XN,YN)}
• 初始化的算法参数矩阵:W1,…,WN,Z,U1,…,UN
• 最大迭代次数:Iter
• 收敛阈值:ε=10-4>0
• 超参数:λ,ρ
输出:
• 算法最终的参数:Zk+1
迭代步骤:
1: 初始化计数器k←0
2: 初始化全局参数矩阵Zk←Z
3: 初始化局部和对偶参数矩阵Wik←Wi,Uik←Ui
i=1,2,…,N
4: 各分区并行地执行步骤5和步骤6
10: 当满足‖rk+1‖2<ε且‖sk+1‖2<ε,或迭代到指定次数时算法终止,执行步骤11。否则,令k←k+1,并返回步骤4。
11: 返回更新完成的算法参数Zk+1
3 实验与结果分析
本节将比较不同优化算法求解SMLR问题的性能。此外,为了评价ADMM的分布式优化求解性能,本节还在大规模数据集上进行了相关的并行实验。
3.1 实验设置
串行实验所使用的机器具有Intel (R) i7-7700HQ(2.8 GHz)的处理器和16 GByte的随机存取存储器。并行实验所使用的大数据平台部署在由11台服务器搭建的真实物理集群上。单台服务器的中央处理器为12核、主频为2.0 GHz的Intel(R) Xeon(R) E5-2620,并且具有64 GByte的随机存取存储器。并行SMLR优化算法基于Spark分布式计算框架实现,其中,Spark的版本号为1.5.1。
为了有效地比较不同优化算法的性能,实验选取了多个领域的不同大小的数据集,包括鸢尾花卉数据集Iris;肺部基因数据集Lung;图像分割数据集Segment;多类物体识别数据集COIL20;小规模和大规模的手写体数字识别数据集MNIST-S和MNIST以及人脸识别数据集Yale-B。为了验证分布式SMLR优化算法的性能,本节还选取了较大规模的数据集,包括路透社英文新闻文本分类数据集RCV1;经典二分类数据集Realsim;仿真数据集Synthetic。表1列出了各数据集的描述信息。
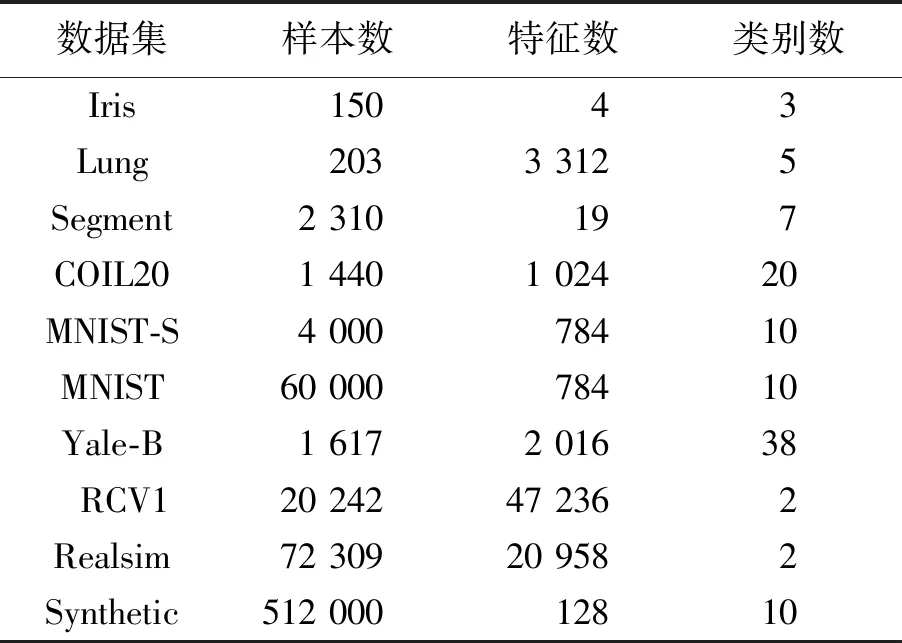
表1 实验数据集描述信息Tab.1 Experimental dataset information
表1中,COIL20包含20个物体以5度间隔拍摄的灰度图像,每个物体包含72张图像,每张图像被下采样为32×32像素大小。MNIST数据集包含了0-9在内的10类不同的手写体数字,训练集和测试集分别包含60 000张和10 000张28×28像素的灰度图像。小规模的MNIST数据集来自全量MNIST数据集的子集,包含了按类别均匀采样的4 000张训练样本。Yale-B数据集由38个人的人脸构成,每张人脸由64张图像组成,部分人脸不足64张,原始图像大小为192×168像素大小,本文将其下采样为48×42像素大小。RCV1和Realsim数据集获取自LIBSVM页面[18]。Synthetic数据集为人工仿真的具有稀疏特性的数据集,包括了特征稀疏性和解的稀疏性。数据集采用如(58)式生成,即
y=argmax(xTW+εT)
(58)
(58)式中,样本x∈Rn和参数矩阵W∈Rn×k都生成于稀疏的标准随机正态分布N~(0,1)并且具有50%的非零元素,ε∈Rk是采样自标准正态分布N~(0,1)的噪声数据。argmax(x)操作返回x中最大值的索引。
此外,为了进一步探索不同算法在不同数据规模下的性能,本节还生成了不同样本规模及特征规模的仿真数据,仿真数据的生成使用了scikit-learn(scikit-learn: machine learning in python)[19]工具包中的make_classification方法。同样的,在进行算法性能比较时,使用了相同的随机种子以保证仿真数据和实验结果的一致性。
值得注意的是,当处理高维数据时,(53)式中XiWi的计算开销非常大。为了解决数据存储和计算上的瓶颈,数据集Xi被组织成稀疏格式来存储,而参数矩阵Wi仍然表示为密集矩阵的形式,XiWi的计算采用稀疏矩阵乘积操作。在实验中,数据集RCV1,Realsim,Synthetic-SP均被表示为LIBSVM[18]的稀疏格式。
3.2 实验与结果分析
为了保证实验的公正性,不同算法的实验结果均在最优的超参下求得,实验分别比较了不同算法在各数据集上的分类准确率和运行时间,实验结果如表2和表3所示,表中的“-”符号表示算法运行时间过长,无运行结果。
根据表2与表3的实验结果,可以得出以下结论。
1)SMLR问题的原始求解算法IRLS在Iris或者Segment等小规模数据集上运行才能得到结果,当样本数或者特征数增加时,其算法的运行时间会显著增加。例如,在规模不大的Segment数据集上,其样本数、特征数以及类别数分别为2 310,19,7,但IRLS算法的运行时间却超过了900 s。在Lung或者COIL20数据集上,算法的运行时间甚至已经超过1 000 s以上。当数据集规模更大时,例如在MNIST或者Yale-B数据集上,IRLS算法因为迭代时间过长而无法得到结果。由于对于特征数为n的k分类问题中,IRLS算法的计算复杂度为O((nk)3),IRLS也不适合处理类别数较多的数据集。因此,使用IRLS算法对SMLR问题进行求解时,对数据集有很高的要求。
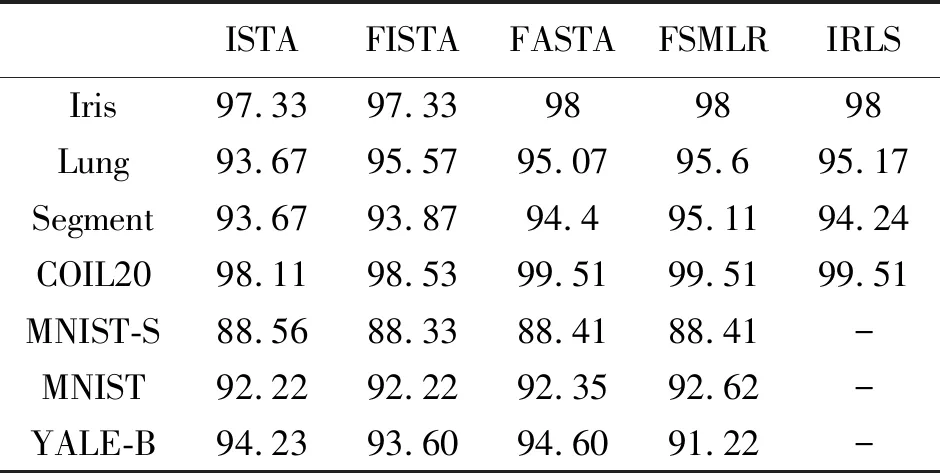
表2 各优化算法在不同数据集下的分类准确率Tab.2 Classification accuracy of each algorithm under different datasets %
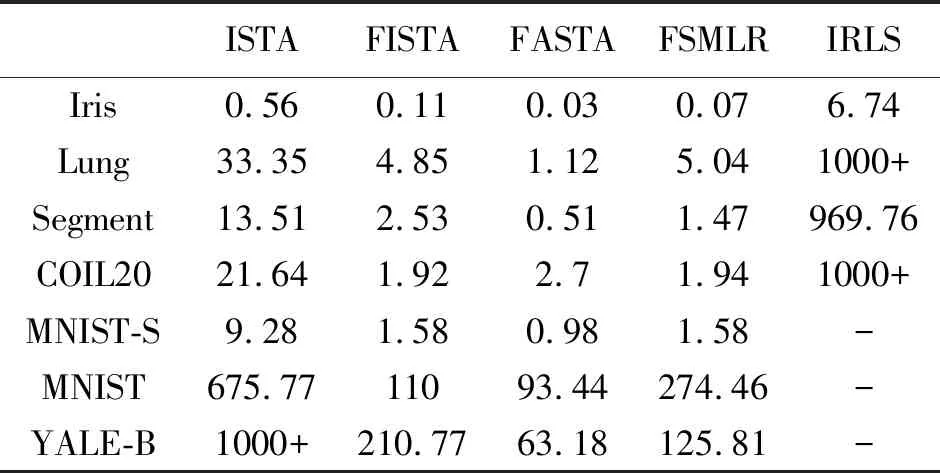
表3 各优化算法在不同数据集下的运行时间Tab.3 Running time of each algorithm under different datasets s
2)ISTA和FISTA的分类准确率在不同数据集的表现相当,在多数数据集上都没有取得最优的结果。而在算法迭代时间上,FISTA要远快于ISTA算法,是由于FISTA在每一次迭代时并非只使用了Wt,而是使用了前2次参数{Wt-1,Wt}的线性组合,因此,其迭代速度要远快于ISTA算法。
3)对于ADMM算法,它在Iris,Lung,Segment,COIL20以及MNIST等不同规模的数据集上都取得了最优。另外,虽然ADMM算法没有在运行时间上取得最优,但可以看到它在小规模数据集上如Iris,Lung,Segment数据集上的运行时间与FISTA和FASTA算法相差不大。当应用于较大规模数据集时,ADMM算法与FISTA算法运行时间相当,但都略慢于FASTA算法。
4)FASTA算法在数据集规模不大时,其在运行时间上具有一定的优势,并在7个数据集中的5个中都取得了最优。而从分类准确率的角度来讲,FASTA算法的准确率仅在Iris,COIL20,Yale-B数据集取得了最优。因此,当数据集较大时,采用FASTA能够在损失一定精度的同时以较快速度求解。
为了进一步验证各算法在不同数据集下的性能,本文在不同样本和特征规模的仿真数据下进行了实验,实验结果如图1。由于在仿真数据集下各算法的分类准确率较接近,因此,这里只对各算法的运行时间进行了绘制。在图1a中,选取特征数为10,类别数为3,通过改变样本大小从28到218,得到各算法在不同样本规模下的运行时间。在图1b中,选取样本数为214,类别数为3,通过改变特征维度从10到500,得到各算法在不同特征规模下的运行时间。其中,IRLS算法在各数据集下的运行时间均较长,因此,在绘制结果时省略了IRLS的结果。
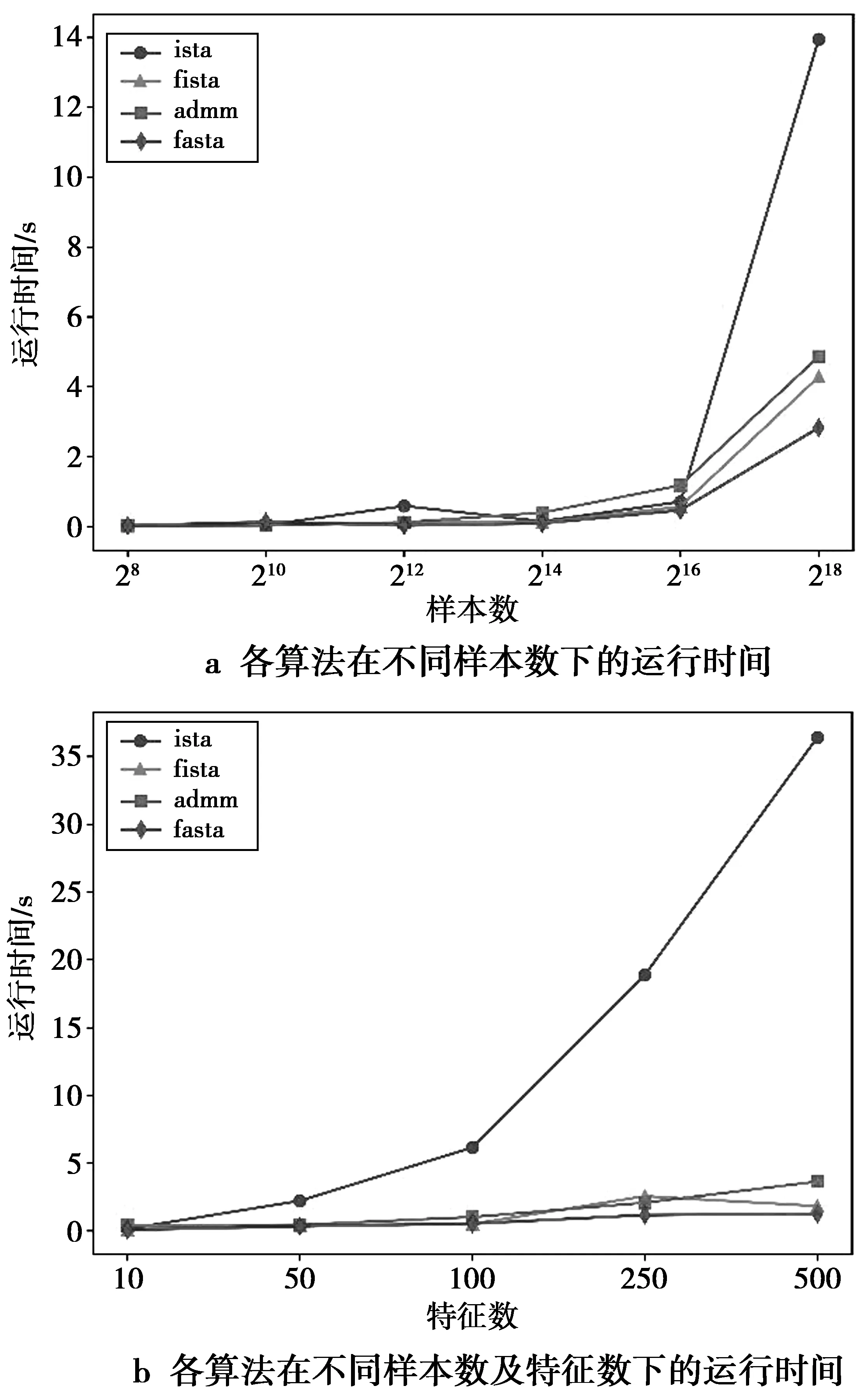
图1 各算法在不同样本数及特征数下的运行时间Fig.1 Running time of each algorithm under different example sizes and feature sizes
从图1a中可以看到,当样本规模较小时,各算法在时间性能上的差异较小,而当样本量逐渐增大时,ISTA算法的运行时间显著增加。在图1b中,随着特征规模的增加,除了ISTA算法外,各算法的运行时间差异较小。FISTA,ADMM以及FASTA算法在不同样本规模与不同特征规模的数据集上的运行时间较接近,当样本规模或者特征规模增加时,ADMM算法的时间性能较差,而FASTA算法则在大规模样本和较大规模特征的数据集下的时间性能更优。
在实际中,人们不可避免地会遇到大规模的数据集,因此,有必要探讨SMLR的分布式优化问题。选取RCV1,Realsim以及仿真的Synthetic数据集作为分布式优化数据集,图2—图4显示了在不同数据集下,ADMM的分类准确率、运行时间及加速比随分块数的变化情况。
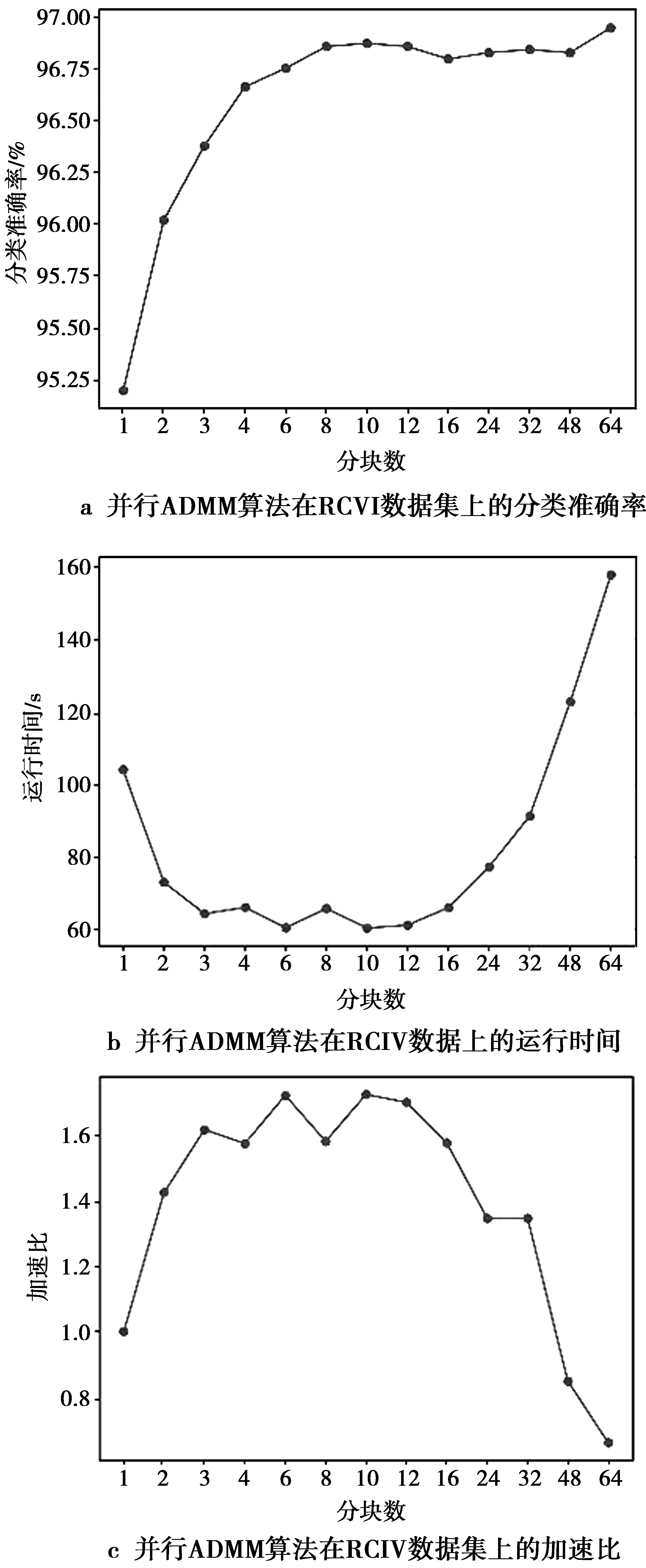
图2 并行ADMM算法在RCV1数据集上的实验结果Fig.2 Results of the parallel ADMM algorithm on RCV1 dataset
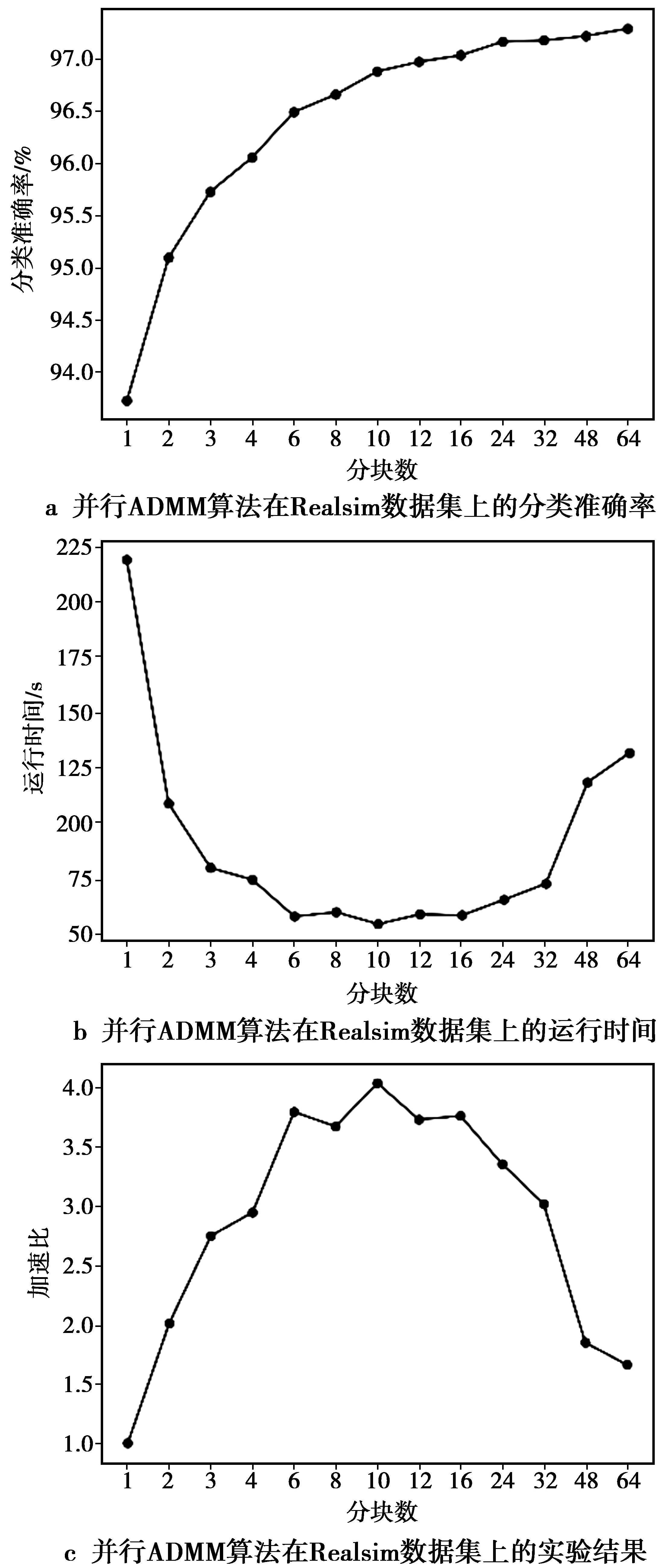
图3 并行ADMM算法在Realsim数据集上的实验结果Fig.3 Results of the parallel ADMM algorithm on Realsim dataset
从图2—图4左侧的分类准确率随分块数变化的曲线中可以看到,分布式ADMM算法在Synthetic数据集上的分类准确率呈现先增后减的趋势,而在RCV1和Realsim数据集上,其分类正确率则随分块数目的增加而增加。分布式ADMM算法的实验结果可以从集成学习角度去理解,即基分类器为一个ADMM模型,每个模型使用不相交的子训练集进行训练,最终的预测结果为多个模型预测结果的平均。当分块数不是很多时,各计算节点有足够的训练数据来训练基分类器,分块数越多则集成的效果越明显。当分块数达到某一临界值时,各计算节点用于训练的数据变少,过拟合的风险增加,这也使得模型泛化能力降低从而导致分类准确率下降。从RCV1和Realsim数据集的实验结果中可以看到,当分块数达到128后,算法的分类准确率仍呈现增加的趋势。一种可能的解释是这2个数据集的特征具有很好的表达能力,即使训练数据很小时也可以训练的很好。
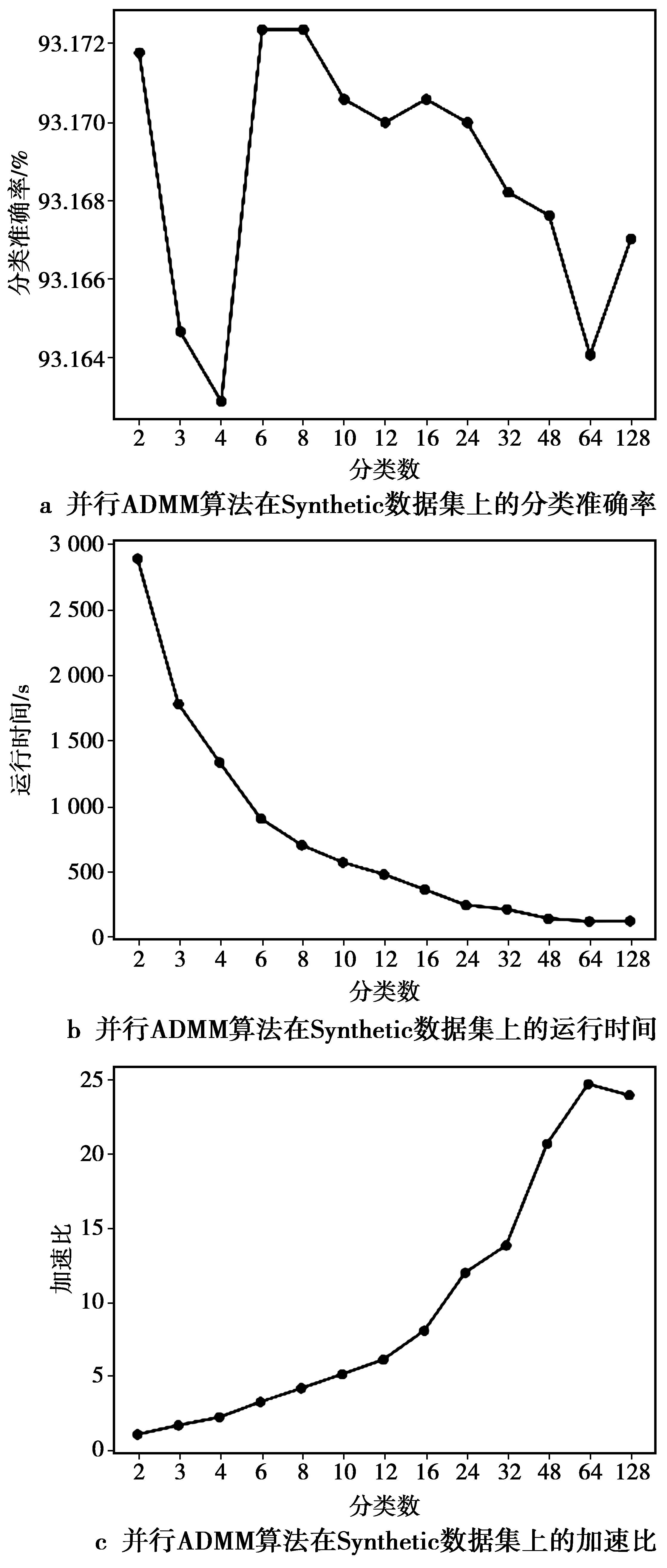
图4 并行ADMM算法在Synthetic数据集上的实验结果Fig.4 Results of the parallel ADMM algorithm on Synthetic dataset
图2—图4的中间部分显示了算法运行时间随分块数变化的曲线。可以看到,分布式ADMM算法算法在RCV1,Realsim以及Synthetic数据集上的运行时间呈现出随着分块数增加而减少的趋势。当分块数,也即并行度,逐渐地增长到某个饱和点时,集群上节点之间的通信时间增加,算法的时间性能趋于平缓,甚至出现运行时间随并行度增加的情况。
另外,可以看出,当分块数为1时,分布式ADMM算法实际是以串行方式运行,因此,可以据此画出算法在不同分块数下的加速比,如图2—图4的右侧图像所示。结合分类准确率曲线可以发现,当选择合适的并行度时,分布式ADMM算法能够在保持分类准确率的同时极大地加速训练过程。
4 结束语
本文回顾了几种经典的稀疏优化算法,如ISTA,FISTA,FASTA和ADMM,并将其推广应用于求解SMLR问题。在不同数据集上的实验结果表明,ADMM算法在小规模数据集上具有较好的分类精度和运行时间,而FASTA算法在中小规模数据集上具有较快的求解速度。然而,FASTA算法在处理大规模数据集时不能充分发挥其优势。本文将ADMM扩展到分布式优化领域,这使得SMLR的分布式优化求解成为可能。通过选择合适的分块数,分布式ADMM算法可以在很短的时间内求解,并保持较高的分类准确率。
因此,本文建议,如果研究者对算法的准确率要求不是特别高,但是期望算法具有较快的运行速度,那么可以选择FASTA算法。当处理较大规模数据集时,根据上面的分析,本文更建议使用FASTA算法。当数据集规模很大,甚至无法由单机处理时,则采用并行ADMM算法则具有更大的优势。
猜你喜欢
肇庆学院学报(2022年5期)2022-09-29
成都信息工程大学学报(2021年5期)2021-12-30
四川大学学报(自然科学版)(2021年6期)2021-12-27
中国惯性技术学报(2020年2期)2020-07-24
唐山师范学院学报(2018年6期)2018-12-25
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
北京航空航天大学学报(2016年12期)2016-02-27
雷达与对抗(2015年3期)2015-12-09
文苑(2015年9期)2015-09-10
