
基于决策树的远程控制协议字典攻击检测
2019-06-14 07:29许鸿坡
计算机技术与发展 2019年6期
许鸿坡,陈 伟
(南京邮电大学 计算机学院,江苏 南京 210023)
1 概 述
随着互联网的快速发展,计算机漏洞频频被曝光,安全技术急需跟上互联网发展的步伐。但是针对有些传统的网络攻击方式,依然没有较好的解决办法。与此同时,越来越多的企业及用户利用云端实现业务或者远程操作物联网设备,此时需要通过远程控制计算机去实现,这就涉及到远程控制协议的使用。远程登录协议能提供多种功能,例如远程登录、文件传输、TCPIP转发[1],而且这些协议有助于完成自动化批量操作[2]。而传统的远程控制协议如TELNET、RDP、RLOGIN、RSH、REXEC等都是采用明文传输,相对较安全的SSH协议则采用加密传输,但是为了方便与用户进行交互,这些协议都采用用户名、密码的认证方式远程登录。但是用户担心密码复杂容易忘记,往往选择设置相对简单记忆的密码,攻击者可以将用户普遍使用的弱密码和设备的缺省密码组合成密码字典对远程控制协议的密码认证进行暴力破解,通过尝试每个弱密码,一旦认证通过,则暴力破解成功,黑客将控制设备,用户信息将会泄露,更危险的是设备可能成为僵尸网络的一部分,成为跳板感染攻击其他设备。
虽然字典攻击由来已久,但是近些年由于互联网的快速发展,计算机设备快速增长特别是物联网设备,所以存在弱密码的设备也呈上升趋势,导致字典攻击被使用更加频繁。2011年12月21日,黑客在网上公开了知名程序员网站CSDN的用户数据库,高达600多万个明文的注册邮箱账号和密码遭到曝光和外泄,之后有人统计这些密码中有至少90%的用户设置了弱密码,黑客将可以利用它们制备更健壮的弱密码字典。2016年9月30日,Mirai[3]制造者将源码放到Github以来,Mirai及其变种感染的物联网设备快速增加。据统计,Mirai僵尸网络已累计感染超过200万台摄像机等IoT设备,而其中感染模块使用的就是传统的字典攻击,感染设备的数量让人叹为观止,主要原因还是众多设备采用弱密码或者缺省密码。在此之后针对弱密码的字典攻击更多被僵尸网络所使用,开放远程控制协议端口的弱密码设备将可能沦为肉鸡。所以对远程控制协议的字典攻击检测尤为重要。
字典攻击检测有两种基本方式:一种是依赖于日志信息[4],另一种是依赖网络流量[5]。通过监视和分析网络层面或主机层面的相关网络流量,可以检测甚至阻止字典攻击;然而,高速网络和加密流量数据的使用使得这种检测具有挑战性。基于主机的检测使用安装在主机上的内部软件来监控该主机的接收流量。该主机使用的攻击检测软件还可以访问内部日志,如用户的登录活动,正在运行的进程和应用程序以及其他可用于攻击检测相关数据。基于主机检测的一个主要缺点是无法检测到在计算机环境中当今互联网普遍存在的分布式攻击。检测此类攻击需要更广泛的视图和网络流量检查。基于网络的检测提供了这种功能。与仅部署在特定主机上的检测软件相比,它不依赖于主机的操作系统,且基于网络流量的检测方案更具可扩展性。在没有直接访问特定主机的情况下,只有基于网络的检测才能做到为没有保护机制的主机提供安全防护[6]。
因此,文中提出基于网络流量的字典攻击检测。以SSH协议为例,通过分析SSH协议的通信原理和网络流量指纹后,发现对远程控制协议认证的字典攻击流量与正常用户登陆流量呈现不同的指纹特征,针对这些不同的指纹特征,将从校园网入口提取的数据包标记好标签,生成训练数据集,通过系统的机器学习,最终能够在校园网上检测针对这些协议的字典攻击。该系统是在网络层面上对有字典攻击的数据包进行检测拦截,不需要在主机上部署,在保证主机的安全条件下,减少了主机的计算内存消耗并保证了主机的性能,同时管理员不需要通过日志查看分析是否发生字典攻击,大大减少了管理员的工作量。
文中的主要工作包括:
(1)在不直接检查数据包的有效载荷的情况下,通过观察暴力破解与用户正常登录的流量特征,运用机器学习的方法可以有效地将两者区分出来;
(2)设计了一种简单高效的流量处理算法,可以快速提取大量数据流的特征数据;
(3)在网关层面上对数据进行采集、分析,不需要主机参与,且若发现字典攻击行为,即可在网关中阻止异常IP访问主机。
2 相关文献
暴力破解攻击是指攻击者通过系统地组合并尝试所有的可能性以破解用户的用户名、密码等敏感信息。攻击者往往借助自动化脚本工具来发动暴力破解攻击。传统上防御方往往采用基于主机日志的统计IP出现的频率来检测是否发生暴力破解行为,如今防御方更多采用基于网络流量的检测方式,一方面可以提高检测精度和防御效果,另一方面可以减少管理员的工作量。
魏琴芳等[7]通过分析登陆用户名密码的正常流量与暴力破解的流量差异,提取引起差异的流量特征,然后分别对TELNET、SSH、RDP、FTP四种协议进行检测,但是文中只提取两种流量特征,当其中一种特征失效时,严重依赖另一种特征,容易导致误报、漏报,而且数据需要在离线状态下处理,不具有实时性,没有对数据包过滤,可能导致数据包过多时耗费的时间线性增加。Jonker等[8]指出许多入侵检测系统采用平稳的网络流量识别攻击行为的存在,这种方法存在一定的偏差,提出基于流量检测来分析重传和控制信息对SSH入侵检测的影响,从而将入侵检测结果大幅度提高16个百分点。Studiawan等[9]在主机层面上应用图论来分析SSH字典攻击生成的日志并提出k-clique渗透以对auth.log文件进行聚类,可以协助系统管理员检查此事件,但是该方法仅适用于分布式SSH暴力破解情况,管理员还需处理日志聚类的结果,不能实时检测和防御,而且在主机上部署系统一定影响主机性能。
当前,越来越多的研究者将机器学习运用到流量检测中。Najafabadi等[10]提出将聚合数据包所呈现的数据包平均包数、字节数等信息,作为机器学习的特征以训练从校园网中获得的数据,从而区分SSH字典攻击和正常流量。Satoh等[2]针对传统识别SSH字典攻击的恶意流量方法存在将用户正常的访问流量误认为攻击流量的情况,提出一种检测SSH字典攻击的新方法,该方法基于字典攻击的非击键行为流量有别于用户身份认证的击键行为流量。Najafabadi等[6]针对主机层面检测暴力破解攻击的不足,提出一种在网络流量层面基于机器学习的暴力破解攻击方法,并比较了朴素贝叶斯等四种机器学习方法检测的结果。Sangkatsanee等[11]提出一种基于机器学习的实时在线入侵检测方法,他们从网络流量中提取十二种特征,并计算每种特征的信息增益作为特征选择的标准,使用多种机器学习的方法相比较,最终设计出高检测率、低虚警率的入侵检测系统,但是这个系统主要针对DDoS攻击和恶意扫描行为,不能解决远程控制协议的字典攻击。Satoh等[12]发现网络流量无法区分SSH字典攻击与正常的自动化SSH登陆行为,利用SSH连接协议存在和认证包到达时隙的长短,从SSH协议结构原理的角度,提出基于流量分析的SSH字典检测的方法,但是没有从骨干网或者校园网获得真实数据集,而是自己使用模拟构造生成的数据集,所以在真实网络环境下的检测效果没有得到验证,方法也仅局限于SSH字典攻击检测。
3 字典攻击检测方法
SSH协议由三种子协议构成,自下而上分别是SSH传输协议、SSH用户认证协议和SSH连接协议。无论用户是否认证成功都将经过传输协议,传输协议保证数据传输的机密性和完整性,所以之后的传输数据包是无法获得载荷信息的,而只有用户认证通过才能进入连接协议,连接协议需要耗费2~5 s的时间,所以可以作为判别用户认证是否成功的标志。文中的创新点在于可以在不直接检查数据包的有效载荷的情况下通过观察暴力破解与用户正常登录的流量特征并运用机器学习的方法可以有效地将两者区分出来。检验方法基于两个标准:
(1)SSH用户认证采用基于口令认证的验证方式,用户只有输入正确的用户名和密码,方可成功登录;
(2)认证数据包的到达时间间隔存在差异,即用户按键的时间与暴力破解的非按键时间存在差异,作为检测单个攻击的标准。
3.1 C4.5决策树
决策树[13]通过一系列决策对样本进行分类,而当前决策有助于做出后续决策。这样的决策序列以树结构表示。样本的分类是从根节点开始到符合决策的末端叶节点,其中每个末端叶节点表示分类类别。样本的属性分配给每个节点,每个分支的值对应于属性。决策树又分为分类决策树、回归决策树。具有一系列离散(符号)类标签的决策树称为分类树,而具有一系列连续(数字)值的决策树称为回归树。这里采用的是分类决策树。
C4.5决策树算法如下:
输入:训练数据D,特征集A,阈值ε;
输出:决策树T。
步骤1:若D中所有实例均为同一类别Ck,则T为单节点树,将Ck作为该节点的类标记,返回T;
步骤2:若A=∅,则T为单节点树,将D中类别最大的类Ck作为该节点的类标记,返回T;
步骤3:计算特征集合A中各个特征对D的信息增益比,选择特征集合A中信息增益比最大的特征Ag;
步骤4:如果Ag的信息增益比小于阈值ε,则设置T为单节点树,将D中类别最大的类Ck作为该节点的类标记,返回T;
步骤5:对Ag中的每一个取值ai,依ai将D分割为非空子集Di,以Di中实例最多的类作为类标记,构建子节点,由节点Ag与子节点构成树T,并返回T;
步骤6:对第i个子节点,以Di为训练集,A-Ag为特征集,递归调用步骤1~5,得到子树Ti,返回Ti。
建立了机器学习算法之后,将检测模型分为两部分,第一部分为数据预处理,生成训练数据集和测试数据集;第二部分为决策树训练与预测。基于决策树的检测模型如图1所示。
3.2 流量处理
机器学习模型需要训练数据集和测试数据集,而如何简单高效地从数据流中根据选取的特征获取这些数据是非常关键的一步。为了更好地检测隐蔽性的分布式字典攻击,需要统计每个IP的建立SSH连接的端口号(即应用进程)的流量信息。因此文中提出一种算法,可以在大量待处理的数据流中快速获取决策树算法所需要的数据,算法如下:
步骤1:初始化i为零,并将数据流以IP地址为标志划分成数据流集合F;
步骤2:从数据流集合F中取出下标为i的数据流Fip,并初始化下标j为零,获取Fip第一个数据包的IP地址和端口号p0,初始化每个IP的源端口数据流fport为空;
步骤3:从Fip中获取下标为j的数据包,并获取其端口号pnext;
步骤4:若端口号pnext与p0相等,则fport添加该数据包,Fip移除该数据包;否则下标j自增;
步骤5:Fip数据流长度与下标j相等,则统计该IP源端口号的数据流信息,否则返回步骤3;
步骤6:若Fip为空,下标i自增,并统计该IP数据流信息;
步骤7:若F数据流长度与下标i相等,则流量处理完毕,否则返回步骤2。
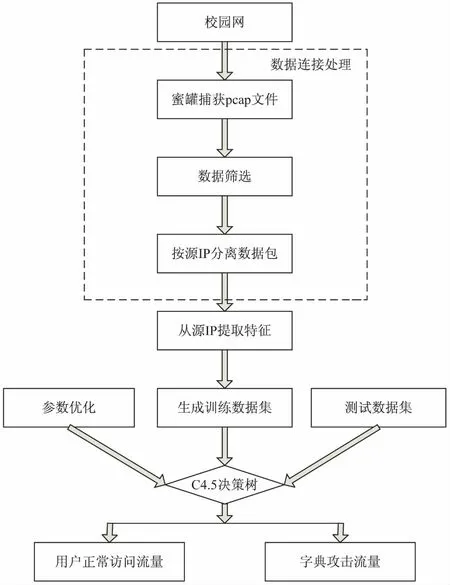
图1 基于决策树的检测模型
3.3 信息增益比
基于网络流量特征的暴力破解检测基本上是分类问题,检测系统必须将给定的一组网络数据包分类为正常访问或字典攻击。网络数据流的各种特征为分类提供数据输入,所以使用的特征数量会影响计算的复杂性和所需的计算机资源。因此,希望获得尽可能少的特征且这些特征必须满足最佳分类效果。
在本节中,提出了使用信息增益比[14]来筛选通过蜜罐系统捕获和预处理的网络数据包的相关特征。信息增益比参数测量每个网络流量特征用于数据分类时的相关性。
首先熵的定义为度量随机变量的不确定性。假定随机变量X的可能取值有x1,x2,…,xn。对于每一个可能的取值xi,其概率P(X=xi)=pi,i=1,2,…,n,所以随机变量X的熵为:
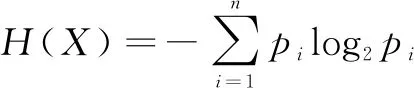
(1)
信息增益的定义:以单一特征划分数据集前后的熵的差值,差值越大该特征对于样本集合D的划分效果越好,否则相反。
信息增益正式的定义如下:设X和Y分别表示样本属性(x1,x2,…,xm)和类属性(y1,y2,…,yn)的离散变量。H(Y)表示Y值的不确定性;当X的值已知,H(Y|X)表示Y值的不确定性。当确定一个特征属性X将有助于减少类属性Y的不确定性。故信息增益的数学表达式为:
G(Y;X)=H(Y)-H(Y|X)
(2)
对于集合样本D来说,随机变量Y的不确定度表示样本集合D的熵,公式如下:
(3)
当确定一个特征属性xi(i=1,2,…,n)时,类属性Y的不确定度为:
(4)
因为在相同条件下,取值较多的特征比取值较少的特征获得的信息增益大,即信息增益容易偏向取值较多的特征,为了克服这个不足,这里采用信息增益比,公式如下:
(5)
文中X定义了分类中输入的个别特征,Y定义了流量所属类别。通过计算每个候选特征的信息增益,选择少数几个基于较高信息增益的特征用于网络流量分类,这样不仅可以保证正确性,还可以减少机器学习耗费的时间。从网络流量中提取的数据特征如表1所示。

表1 网络流量特征
文中使用1~10特征作为计算信息增益比的候选特征,经过信息增益比算法计算获得表2展示的各个候选特征的信息增益比排序。从表2中可以看出每个IP端口号的平均时间、平均字节数、平均包数、端口号数的信息增益比较大,所以选择这4个信息增益比值大的候选特征作为决策树分类特征。
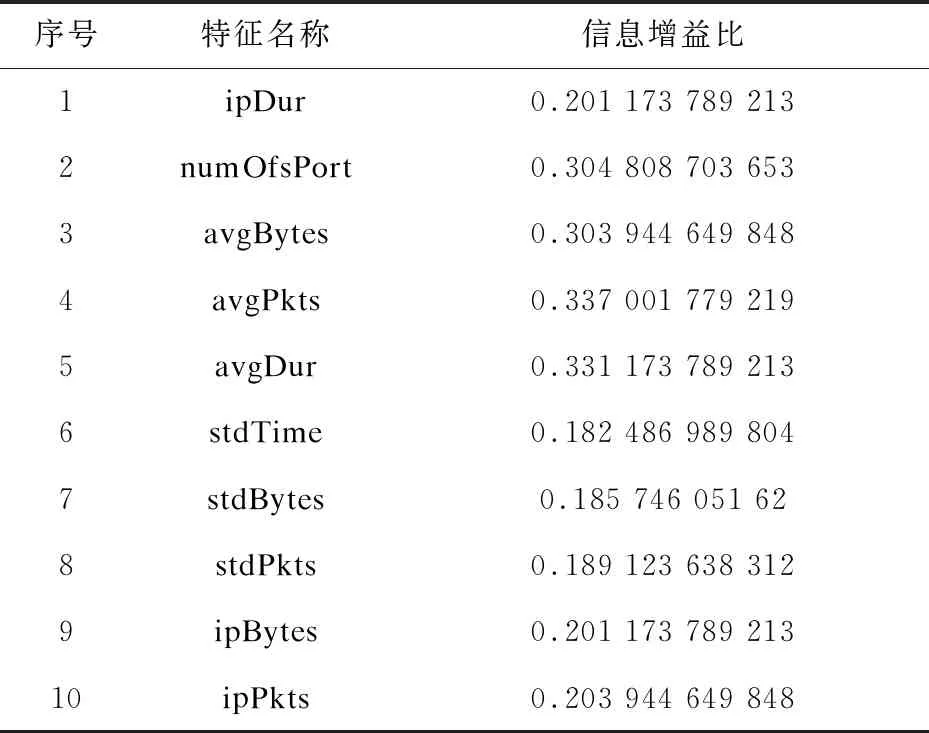
表2 网络流量特征的信息增益比
4 实验过程及结果
4.1 数据集
在校园网中部署了三个蜜罐[15-16],见图2,在每个蜜罐中使用tcpdump工具捕获SSH流量。首先使用命令“tcpdump-i eth0-w flow.pcap”抓取流量数据,获得pcap文件,接着从每个数据集中提取出具有五元组(源IP、目的IP、源端口、目的端口、协议)的网络流量并过滤出源端口或目的端口为22端口的数据包,其次过滤掉没有应用层数据的数据包,即将具有TCP控制信息的SYN、ACK、FIN数据包丢弃,这些数据包与检测SSH流量无关,并可以减少程序处理数据包的个数,最后将pcap文件按源IP特征进行分割,统计出每个IP的信息。
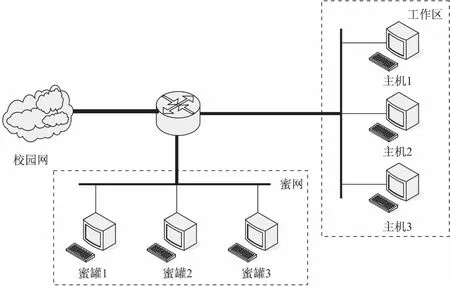
图2 分布式蜜罐架
4.1.1 源端口号特征
在网络通信过程中,主机之间通过IP地址和端口建立连接,每个端口号对应一个应用进程,可以发现无论暴力破解采用单线程方式还是多线程方式,为了保证攻击的效率,在一段时间内,同个主机IP都会占用大量端口,以维持不断地与目标主机的连接,尝试尽可能多的应用进程对目标主机进行暴力破解;而正常用户在一段时间内不会与目标主机建立如此多的连接。从这个角度出发,可以收集一段时间内同一个源IP的端口数量,如果端口数量大于所设定的阈值,可以判定该IP存在字典攻击行为。如图3所示,一段时间内每隔10秒用户正常访问所占用的端口数在1~2个波动,而单线程暴力破解则在4~5个波动,而多线程占用的端口数又是单线程数倍,即多线程的线程池个数。所以只要设定合适的阈值,在正常情况下即可区别流量类别。
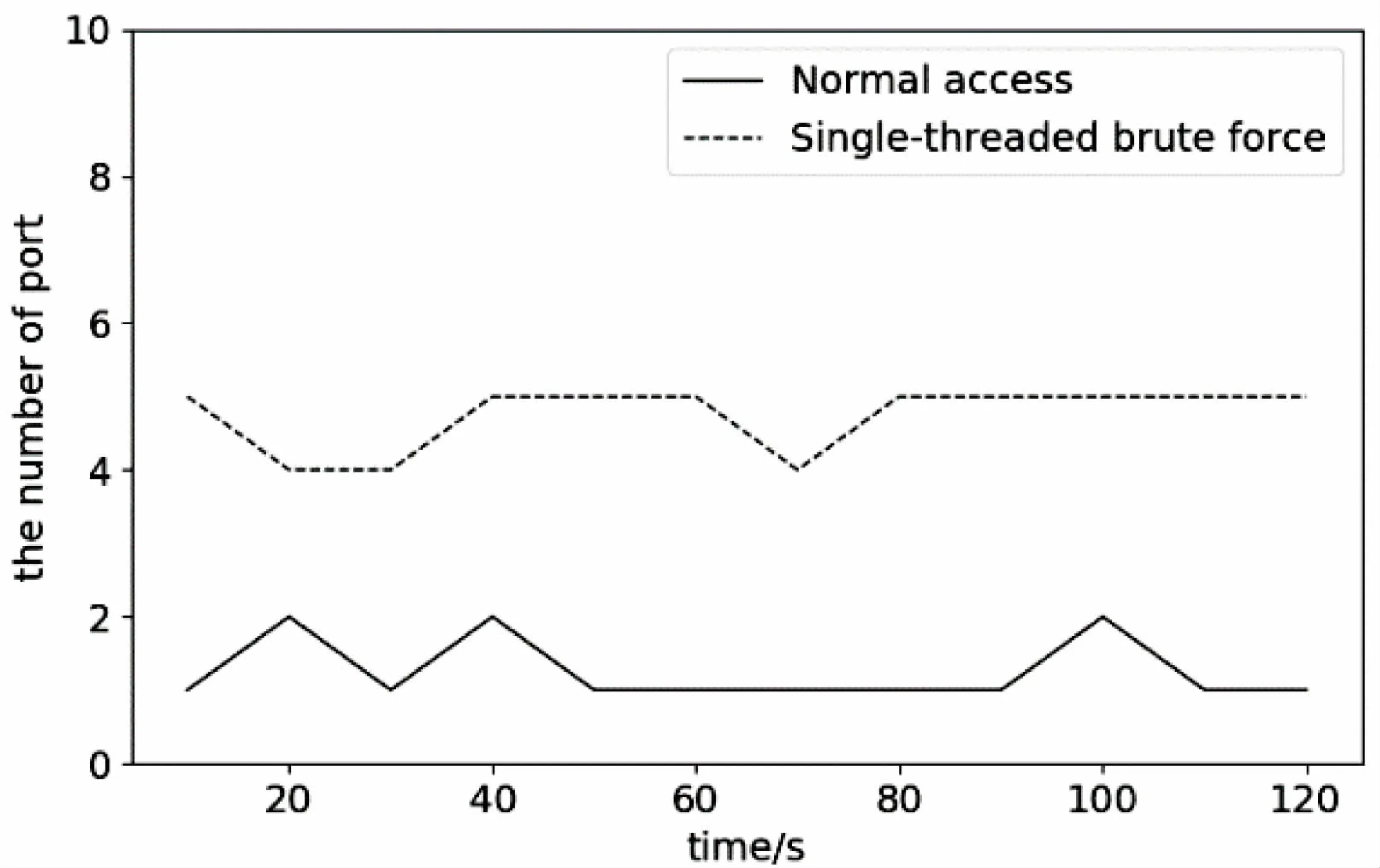
图3 端口占用数量分布
4.1.2 数据包特征
前面提到攻击者为了保证效率一般会采取单线程或者多线程的暴力破解方式,如果攻击者主要针对特定主机IP,会使用较大的字典,而字典数量一变大所耗费的时间将线性增加,所以他们往往会采取多线程的攻击方式。而像僵尸网络,特别是著名的Mirai僵尸网路,则采用单线程的暴力破解方式。但是这两种方式都有共同的特征,即采用自动化暴力破解的方式(非按键形式),这使得它们比用户手动按键进行用户认证时间更快。
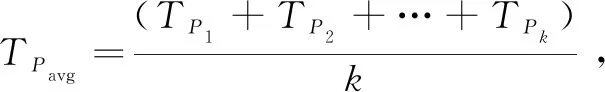
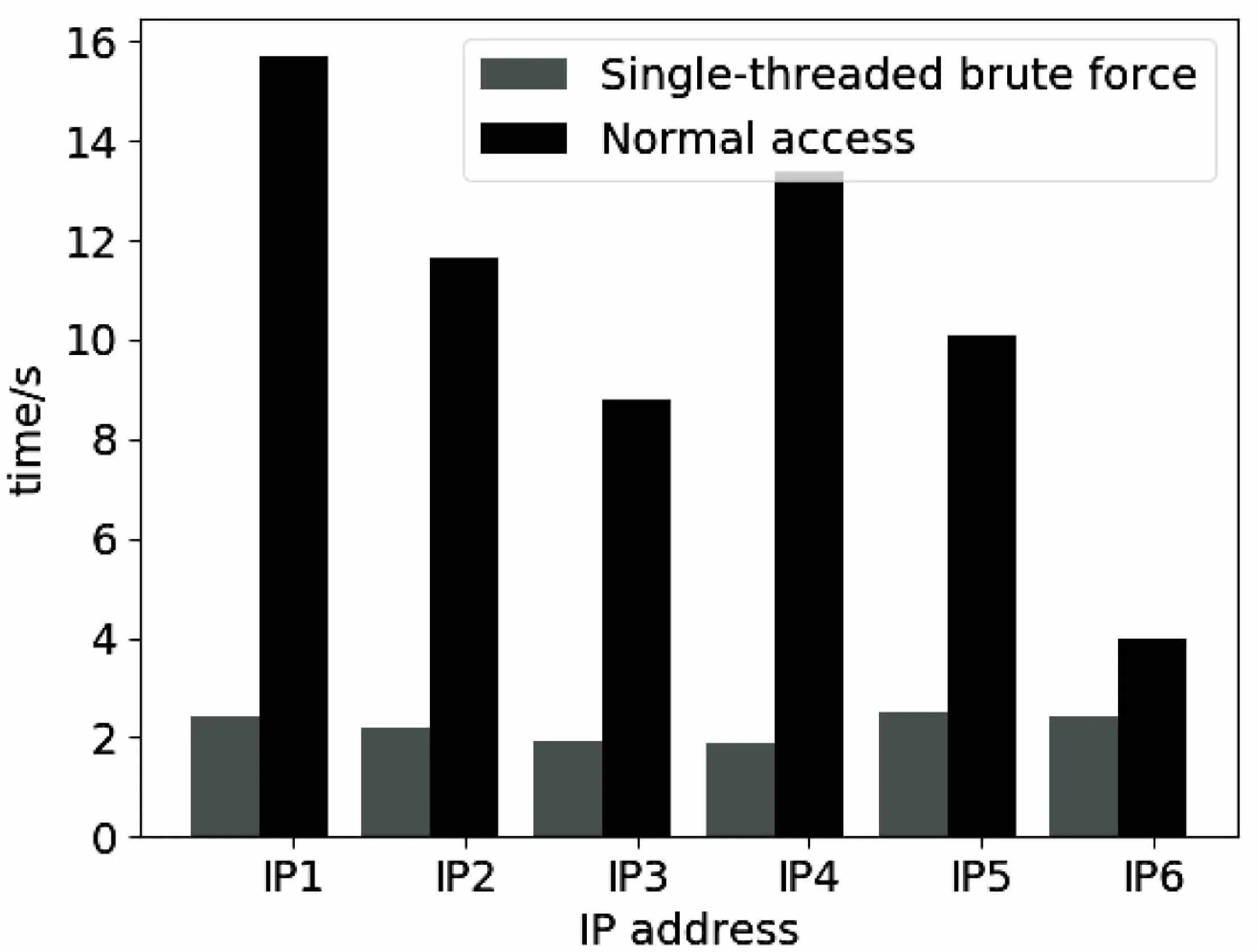
图4 SSH认证失败消耗的时间
4.2 实验结果与评估
部署的三个蜜罐在校园网中运行,在其中收集一个星期的SSH数据,并通过观察蜜罐中的系统日志,标记数据包的类型,接着拿出一部分数据集作为训练数据,另外一部分作为测试数据。训练数据将放入C4.5决策树程序训练,然后将测试数据放入程序中进行检验,最后将测试数据的分类结果与测试数据原本的分类结果作对比,统计测试结果。为了计算测试性能,定义了如下指标:
误报(FP):属于用户正常访问的流量被错误地视为字典攻击流量的数据流个数;
漏报(FN):属于字典攻击流量被错误视为用户正常访问的数据流个数;
真阳性(TP):属于字典攻击流量被正确视为字典攻击流量的数据流个数;
真阴性(TN):属于用户正常访问流量被正确视为用户正常访问流量的数据流个数。
用召回率表示属于用户正常访问流量被视为用户正常访问流量的比例:
(6)
精确率表示属于字典攻击流量被视为字典攻击流量的比例:
(7)
误报率表示属于用户正常访问流量被视为字典攻击流量的比例:
(8)
漏报率表示属于字典攻击流量被错误视为用户正常访问流量的比例:
(9)
总体精确度:正确识别流量的百分比:
(10)
对蜜罐网络收集的SSH数据一共包括577个不同的源IP地址,经过机器学习模型统计测试分类结果和性能评估,决策树分类结果为:真阳性个数497,真阴性个数76,误报个数1,漏报个数3。根据决策树的分类结果对决策树分类性能进行评估,评估结果为召回率0.994,精确率0.997,误报率0.006,漏报率0.013,总体精确度0.993。
从决策树算法的分类结果和性能评估来看,总体分类正确率在99%以上,但存在个别误报、漏报的情况,主要是数据包在传输过程中存在包丢失和包重传的现象,导致数据流特征改变,影响决策树的正确分类,对于隐蔽的字典攻击,只有少量数据包,若其中一些包出错可能会改变分类结果,但对于发起大量数据包的字典攻击来说,该机器学习模型分类效果还是非常有效的。
5 结束语
字典攻击作为传统的攻击手段,近年来开始受到攻击者的关注。字典攻击一旦成功,危害无疑是巨大的,攻击者可以获取设备的控制权限,实施窃密等恶意活动。因此,文中提出一种基于网络流量的字典攻击检测,并以SSH协议为例,分析了SSH协议的原理和结构。但由于SSH流量为加密流量,观察不到流量的攻击载荷信息,文中从另一个角度,通过观察数据包包头的信息,提取相关的攻击特征,并运用机器学习C4.5决策树的方法,提高了分类识别的精确度。在数据处理方面,将无关的TCP协议控制信息过滤,减少待处理的数据包数量,同时设计了一种简单高效的数据处理算法,加快了数据处理的速度,对今后在高速网络中实时在线快速检测打下基础。
传统的字典攻击防御手段是在主机层面,通过管理员观察日志信息统计一段时间内IP出现的频率来判断该IP是否正常访问。对于当前复杂的网络环境,僵尸网络分布式暴力破解骤增和需管理主机设备数量的增长,传统基于主机的防御手段已不能够缓解大量的字典攻击。因此文中采用扩展性更好的基于网络流量的检测,可以在网关层面检测存在的暴力破解,并通过将恶意IP加入防火墙黑名单的方法,保护主机设备不被非法入侵。
在未来的工作中,对于复杂的高速网络中进行在线的实时检测无疑是很好的工作,同时可以在字典攻击的基础上,增加对恶意扫描、分布式拒绝服务攻击的检测,在网络流量上设计入侵检测系统,从而更好地保护主机的安全。
猜你喜欢
航空学报(2022年7期)2022-09-05
舰船科学技术(2022年10期)2022-06-17
计算机应用与软件(2022年2期)2022-02-19
汽车维修与保养(2020年10期)2021-01-22
沈阳工业大学学报(2020年6期)2020-12-29
数码世界(2020年4期)2020-06-18
汽车维修与保养(2020年11期)2020-06-09
计算机技术与发展(2020年5期)2020-05-22
科学与信息化(2019年28期)2019-10-21
科学与财富(2016年32期)2017-03-04
