
基于数据挖掘的计算机管理系统设计与实现
2019-06-10 08:32王兴宏
安阳师范学院学报 2019年2期
王兴宏
(阜阳幼儿师范高等专科学校,安徽 阜阳 236015)
0 引言
随着互联网技术和计算机技术的快速发展,现代图书馆成为一个复合型图书馆,既有传统的纸质图书,也有电子图书,读者既可以在线访问数字图书馆,也可以到图书馆借阅图书。传统图书馆计算机服务系统只能为读者提供较为简单的查询功能,所能提供的信息较为有限,无法满足读者的日益多样化需求[1-2]。同时,图书馆系统所存储的大量借阅信息,无法得到最大限度利用,造成数据信息资源的浪费,因此如何准确高效地利用读者的习惯、偏好、使用行为和读者特定需求[3],为读者提供个性化服务,开发一款具有数据挖掘功能的图书信息管理系统具有重要的理论价值和实际意义。
1 数据挖掘
所谓数据挖掘[4](Data Ming,DM)一般是指从大量的、有噪声的、不完全的、随机的、模糊的海量数据集中发掘潜在有用的、有效的、新颖的信息过程。通过数据挖掘可以发现有价值的信息或规律,为用户提供新的知识和有价值的信息和规律。
2 系统需求分析
选择某高等学校图书管理系统为研究对象,将数据挖掘技术应用于原有的图书管理系统,通过数据挖掘技术,可以分析读者或用户的各种需求,主动为读者或者用户提供个性化推荐服务。通过研究和分析,基于数据挖掘的图书信息管理系统的主要需求如下:
2.1 关联性分析
由于图书借阅过程中存在许多关联性,因此对借阅过程进行关联性分析,可以有效掌握读者或者用户的借阅规律,图书馆可以改变自己的服务方式,由原来的被动服务变为主动服务,主动为读者或者用户推荐相关联的图书,为读者或用户提供更好的服务。
2.2 聚类分析
通过对图书历史借阅数据进行聚类分析,可以了解不同图书的受欢迎程度和图书的借阅使用情况,在此基础上,对馆藏图书进行合理优化配置,为图书的订阅和采购提供决策依据。
2.3 个性化推荐服务
根据图书的关联性分析[5]和聚类分析[6]结果,根据读者的个人偏好、习惯等主动为读者或用户提供图书推荐等个性化服务。
3 系统功能模块设计
在系统需求分析的基础上,基于数据挖掘的图书信息管理系统需要实现如下功能:1)数据挖掘功能:根据历史借阅数据,进行关联分析和聚类分析,发掘图书借阅的潜在规律;2)提供服务:根据数据挖掘结果,根据读者的偏好、个人习惯等,提供个性化推荐服务。系统模块图如图1所示。
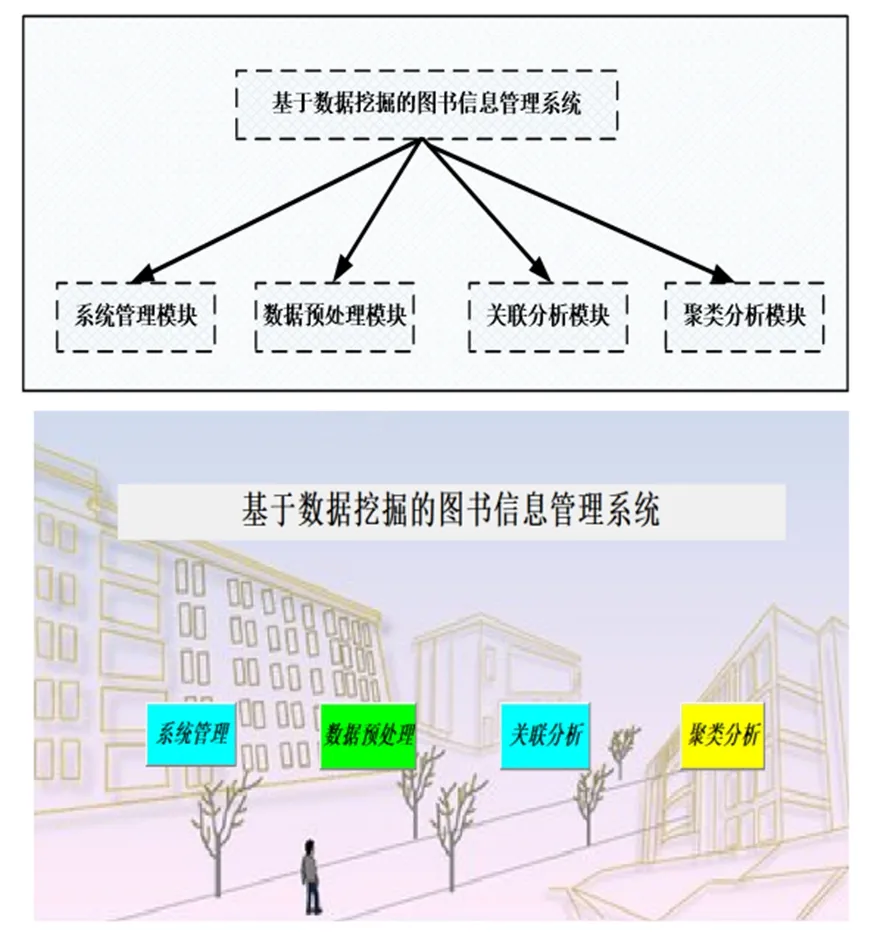
图1 系统模块图
3.1 数据预处理
由于原始的历史图书借阅数据中存在大量噪声、不完整信息,因此数据挖掘处理之前需对原始数据进行预处理,剔除无用信息,提高数据的质量,为后续数据挖掘奠定良好的基础[7]。首先从数据库中读取需要预处理的历史借阅数据;之后,根据借阅信息(包括借书日期、还书日期、续借次数、借阅规则和书籍分类)进行预处理,涉及删除无用属性、填充空值、规范字段等。
图2 数据预处理模块
3.2 数据挖掘模块
数据挖掘模块主要包括关联规则分析和聚类分析,关联分析主要目的是掌握读者或者用户的借阅规律。图书馆可以改变自己的服务方式,由原来的被动服务变成主动服务,主动为读者或者用户推荐相关联的图书,为读者或用户提供更好的服务,关联规则模块如图3所示。
图3 关联规则挖掘模块
聚类分析的目的是了解不同图书的受欢迎程度和图书的借阅使用情况,在此基础上,对馆藏图书进行合理优化配置,为图书的订阅和采购提供决策依据,聚类分析模块如图4所示。

图4 聚类分析模块
3.3 服务推荐模块

图5 图书推荐模块
根据图书的关联性分析和聚类分析结果,根据读者的个人偏好、习惯等主动为读者或用户提供图书推荐等个性化服务。推荐信息包括图书的条码、题名、作者、出版社、出版日期、ISBN和索引号等信息,同时包括相关图书推荐,服务推荐模块如图5所示。
4 实证分析
4.1 数据来源
选择某高等学校2008年图书馆借阅历史数据为研究对象[8-9],图书馆图书分类统计结果如图6所示。全年共412715条记录,其中借阅信息包括借书日期、还书日期、续借次数、借阅规则和书籍分类等。
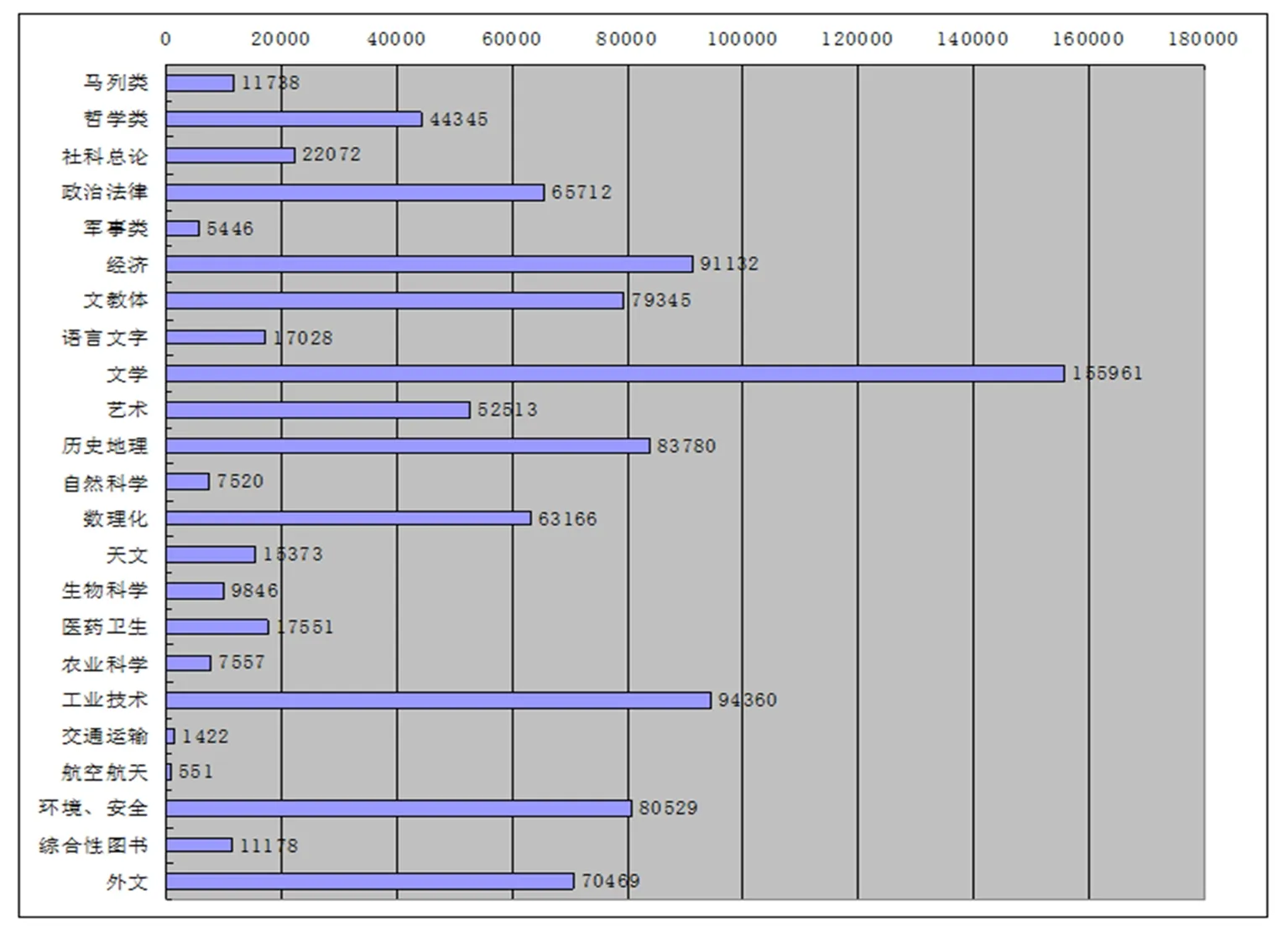
图6 图书分类统计图
4.2结果分析
为了便于数据分析,用实际分类名称代替中图分类号,为了获取更多有用的信息,将藏书量信息也作为数据挖掘因素[10-12]。考虑该校师生比约为1:10,为了得到学生和老师之间的不同借阅规律,将学生和老师的借阅情况进行分类显示,分别如图7和图8所示。
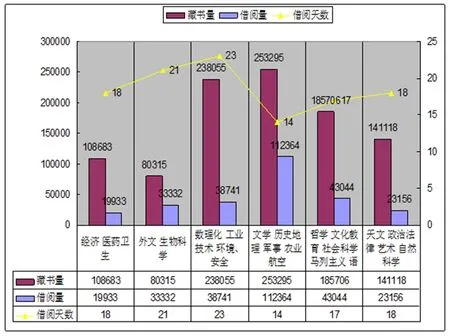
图7 学生借阅信息挖掘结果图
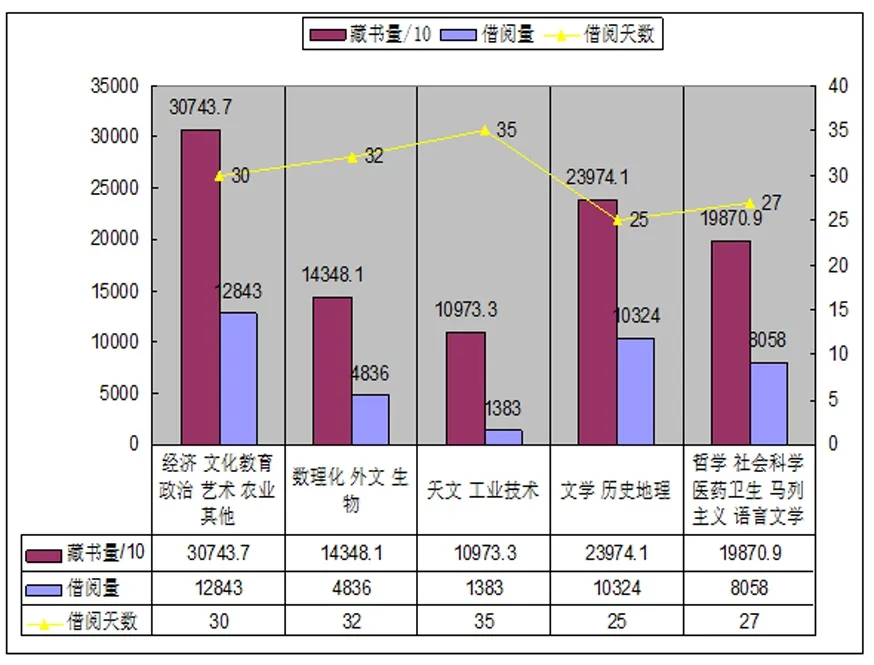
图8 教师借阅信息挖掘结果图
通过图书借阅信息可以发掘如下规律:1)教师借阅量与藏书量基本平衡,而学生借阅量较为不均衡,主要集中于文学、史地、哲学、教育、外文等文科类书籍。2)文学、历史地理、军事等书籍借阅量大,流通的速度快,借期时间最短,说明这类书籍对读者的吸引力大,阅读时间快,读完之后还有继续阅读该类书籍的兴趣,该类书籍是图书借阅的主要对象。3)理工科类书籍的借阅量普遍不高,借阅时间很长,可能是该类书籍的专业性太强,需耗费较多时间研读。
5 结论
针对传统图书馆计算机服务系统只能为读者提供较为简单的查询功能,所能提供的信息较为有限,无法满足读者的日益多样化需求。根据历史借阅数据、读者的习惯、偏好、使用行为和读者特定需求,将数据挖掘技术应用于传统图书管理系统,提出一种基于数据挖掘的图书信息管理系统,通过关联和聚类分析,实现图书的合理化馆藏和个性化推荐以及图书资源的合理化配置。
猜你喜欢
大众投资指南(2021年35期)2021-02-16
南风(2020年22期)2020-09-15
文苑(2020年4期)2020-05-30
小学生优秀作文(低年级)(2019年5期)2019-04-25
新闻传播(2018年12期)2018-09-19
小学阅读指南·低年级版(2017年12期)2017-12-26
电力与能源(2017年6期)2017-05-14
汽车与新动力(2016年6期)2017-01-04
信息通信技术(2015年6期)2015-12-26
中国卫生(2015年1期)2015-01-22
