
医药大数据技术在药物价值评估中的应用
2019-06-06 01:00韩屹
中国药物经济学 2019年5期
韩 屹
近年来大数据和人工智能(AI)的结合在世界范围内产生了深远的影响。大数据的概念最早是MichaelCox 和David Ellswort 于1997年IEEE 会议上首先提出[1]。2009年以来,大数据技术取得了重大突破,云计算不仅大幅度提高了数据存储和提取能力,数据分析方法也由以前的集中结构化数据处理逐步推进至对非结构化信息的分析和建模[2]。目前,主流搜索引擎可根据用户搜索历史调整搜索结果的前后排序,网络电商根据用户的购买和浏览历史了解不同客户的购物倾向。世界范围内,包括以谷歌(Google)和亚马逊(Amazon)为代表的众多直接服务于消费者的行业均开始借助大数据和AI 技术提高服务效率并获取新的增长动力。
然而大数据和AI 在医疗健康领域,是在医药产 品上市后的应用,却远滞后于其他行业。以发表论文数目为例,图1展示的趋势也证明了医药领域的滞后:PubMed 文献库的大数据和药物评估文章从2013年才起步。值得注意的是虽然中文核心期刊在这个领域的论文数目一直超过全球英文文献总和,但在2018年这个代表高质量中文论文的总数出现拐点,反而低于2017年。同期国际英文研究论文数目仍在稳定增加。
1 大数据特性和应用框架
目前大数据在各行各业取得了广泛应用。而所谓大数据针对于不同行业有不同的定义。概括来说,它主要是指规模及数据量巨大的数据。针对于医疗卫生来说,大数据主要是指由医学诊断、患者行为及管理、医保、研发等形成的海量的、高增长率、多样化的信息资产。这些信息隐含着巨大的信息量及潜在价值,若得到有效开发,必能使每个医疗卫生行业的参与方受益无穷。在熟练掌握大数据分析的基础上,通过深层次挖掘关联性及价值性的信息,必能在信息化的基础上实现医疗行业的一体化及智能化的发展。
Doug Laney 在2001年提出的大数据3V 概念(Volume,Velocity 和Variety)已被广范接受[3]。即使仅从一所医院内部数据出发,患者接受医疗服务中产生的大量问诊记录、处方数据、医保付费数据、住院病历和医嘱、化验结果及医学影像图片均格外突出了大数据的3V 特征。目前医院信息系统(HIS)尚未提出全国统一的电子健康档案(HER)行业标 准。不同HIS 之间的数据标识和管理差异巨大。汇总并联合来自于不同医院和不同HIS 供应商的数据库是一项高投入的艰巨任务。
支持循证医学是医疗大数据应用的重要方向之一。值得注意的是Kruse 等[4]提出了3V 之外非常重要的一个V:准确性(Veracity)。医疗大数据中的错误信息可能来自于数据缺失、记录错误、有意造假,或不规范用语等多个方面。虽然大数据在其他领域的应用也需要解决数据准确性问题,在卫生健康领域数据准确性更是至关重要。医疗大数据的研究结果经常会作为临床决策和医疗政策的证据。对医疗大数据的分析有可能通过报销制度和临床路径等多种方式直接影响大量患者的治疗方案。虽然分析方法的改进可以在一定程度上对数据样本的偏差进行矫正,但分析方法本身并不能完全抵消数据中的错误和偏差对研究结果的影响。因此无论从伦理角度还是科研角度,准确性在医疗大数据中的重要性远超过其他属性。
医疗大数据的来源有多种,按照健康市场的参与方总结大致可以分为4 类:1)医院和药房的数据:这些数据直接记录了患者的就医经历,包括治疗方法和检测指标等,是医疗大数据的核心部分;2)国家全民医保和商业医保报销数据:包括重要的经济信息和使用记录,对于评估经济效果和研究医保政策具有重要意义;3)医疗器材和制药企业研发和营销数据:其是开发新型医疗技术及评估产品商业价值等商业行为的基础;4)患者数据:这些数据涵盖患者本身 的基础社会经济信息、社交网络记录以及各种可穿戴产品的数据记录,可用以研究患者的健康行为和习惯,对加强疾病管理和预防具有重要意义。
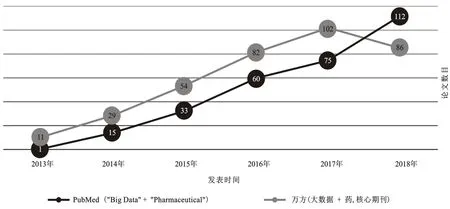
图1 期刊论文发表趋势(数字显示的是2019年3月15日搜索结果)
由于数据源和数据结构较复杂,在使用医疗大数据前必须进行有效整合,以保证数据信息准确和结构完整。Wang 等[5]在2018年的研究中提出了切实可行的架构。在这一框架下(图2),医疗大数据的收集、转换和使用分别在相对独立的层面完成,多样化的数据源可以直接联入大数据体系,数据源的增加或减少可在接入层面通过插件形式完成,整合层对数据规范化后实现质量控制和标准化,不同数据的连接也是在整合层完成,分析和使用则是建立在完整可靠的数据基础上完成。数据管理部门用来全面负责大数据管理工作(包括安全和更新等)。
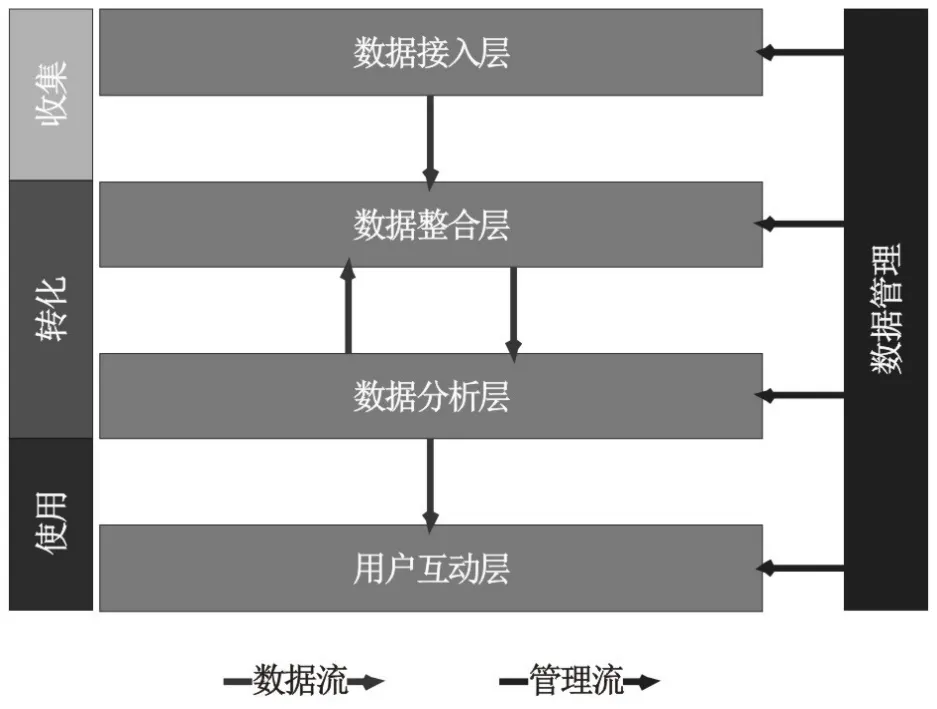
图2 大数据系统构架
2 医疗大数据在药物价值评估领域的应用
在发达国家医药市场,产品上市后继续使用各种非临床试验数据对药物进行评估和检测已是常态化操作。这些数据有别于随机临床试验(RCT),长期以来被统称为真实世界数据(RWD)。国际药物经济学与结果研究协会(ISPOR)将真实世界数据定义为初期RCT 外在临床实践中产生的一切数据[6]。根据ISPOR 对RWD 的定义,RWD 只是医疗大数据组成部分,医疗大数据的范畴则超过RWD。因为除了临床数据外,医疗大数据还包括研发数据、社交媒体和行为数据等不包括在RWD 之内的非临床信息。RCT 目前仍然是各国药物监管部门对药品上市审批和医保价值评估的黄金标准。医疗大数据与RCT 相比,具有以下4 方面优势:1)医疗大数据可以提供比RCT 更长的观察时间。大部分药物的价值优势需要长期观测,难以在临床试验中完全实现(例如患者依从性、疫苗的有效保护期等)。高质量的医疗大数据可以用非常低的成本通过回顾性研究评估产品的长期价值。2)医疗大数据的患者样本明显大于临床试验中的患者人群数。与RCT 相比,对于医药产品的小概率事件(例如严重毒副作用),使用大数据评估可以显著降低Ⅱ型误差。3)医疗大数据的采集来自于医疗机构的日常诊疗工作。对于就诊患者不设纳排标准,药物使用剂量、频率以及提供的相关辅助医疗服务与RCT 相比较更真实,产品疗效和安全性与RCT 相比较结论更具实际价值。4)大数据可以支持相同适应证下不同药物的疗效和安全性比较,但可以提供竞争产品间头对头安全性和疗效比较的RCT 数量有限,RCT 所需要的大量资源也使得这样的对比性试验难以全部实现。医疗大数据在这一领域则可通过筛选合适患者比较两种或多种治疗药物的疗效和安全性。
Nishita 和Pandit[7]在2018年对医疗大数据的分析方法进行了系统性文献回顾,从这篇文献中可以看到很多具有典型大数据特色的方法已经开始应用于药物评估。例如MapReduce 方法在药物警戒方面的应用展示了对非结构化数据的分析能力[8]:Wang等[8]通过对PubMed 文献中的毒副作用报道分析建立模型并用以评估药物与毒副作用的相关性。虽然非结构化数据是大数据的重要部分,针对非结构化数据的分析方法在药物价值评估中并不多见。
对已经上市的医药产品进行评估经常侧重于衡量产品的真实世界价值从而支持医保报销决策,评估结论对于医保体系、临床应用和厂家业绩均具有及其重要的影响。这类研究多采用相对比较成熟的分析建模方法基于大数据中结构化数据部分开展。无论是从药厂角度还是医保体系角度,分析的重点集中于验证产品在RCT 中无法全面证实的价值陈述。表1列举了一些比较典型的研究方向。
文献中结构化大数据的应用实例比较丰富。很多这类大数据研究的设计就是为了补充临床研究数据的欠缺,进而为衡量药物价值提供重要信息。例如提高用药的依从性是确保治疗效果的前提。然而临床研究中的给药方和观察时间长度经常无法提供对依从性计算的数据。医疗大数据可以填补这方面的信息欠缺。
作为依从性研究的实例,Gurel 等[9]使用2007—2012年美国肢端肥大症患者长期用药记录对其依从性进行分析,分析终点为患者首次发生用药中断事件所需时间。通过使用Cox 生存模型获得不同药物之间出现首次停药的风险。研究结果显示使用长效奥曲肽治疗患者与使用兰瑞肽比较可增加38.5%的停用药风险。真实世界使用中必然会产生的药品浪费也是临床试验数据罕有记录的一个方面,使用过程中无法避免的药物浪费会成为医疗费用中计算不可忽视的一个因素。Li 等[10]对真实世界中新型抗癌药物使用时由于剂量改变而导致的浪费进行了精细评估。在这项研究中,作者对2015年2月至2016年2月1242 例使用新型恶性乳腺癌靶向药palbociclib患者的用药情况进行了详细跟踪分析。结果显示其中128 例存在处方重叠期,平均重叠时间长度为11 d,大部分处方重叠是因患者调整使用剂量所致。由于抗癌药物的特殊性,可以合理假设患者采用新滴定的剂量后不会使继续使用剩余的旧剂量药物。基于这个假设,作者计算剂量调整导致的药物浪费每位患者平均可达5471 美元。

表1 典型医药产品的价值验证研究方向
3 医疗大数据发展面临的挑战
虽然全球医疗大数据的发展潜力巨大,但无论是在数据来源,数据结构还是IT 技术方面医疗大数据均面临着巨大挑战。我国的医疗大数据发展也不例外。总体来说,这些挑战可以分为以下4 个方面。
3.1 数据可及性
政策和资源是形成数据可及性障碍的主要原因。由于数据所有权和数据分享政策不明朗,医保部门、医药器材企业、各级医院等数据拥有者对于医疗大数据的分享多采取相对比较保守的态度,数据源分享程度低,局限性强。数据源的不统一和分享范围狭小造成了目前中国市场缺乏具有代表性的全国医疗大数据。科研机构、企业和政府部门的研究除了依靠自己内部一些数据资源,几乎没有可以直接购买使用的EMR 或医保报销数据库。KMPG 公司2017年4月发表的全球医疗卫生透明度报告中从6 个维度对32 个国家评估。在评比的6 个维度中,两个维度是与数据直接相关。中国在这个评比榜上以总分32 居末位。从资源层面看,大规模的数据整合需要非常显著的投资才能实现。例如各级医院采用不同的HIS 体系,实现不同医院之间的数据对接和信息共享存需要不小的前期投入。这些对资本的要求,形成了使用大数据的壁垒。
3.2 数据可靠性
医疗大数据的可靠性不仅与数据收集的来源有关,也受数据的采集方法和初始目标影响。目前国内医院的HIS 没有形成统一标准。在诸如药品名称和医疗检测结果等方面的记录中没有规范可循。甚至HIS记录中ICD-10 编码,也存在大量的不精确记录。由于部分数据的输入不是实时完成,而是事后由数据录入人员填写完成,HIS 中也回出现转录错误。电子病历中非必填项目的内容大幅度缺失也常见。在网络问诊的数据记录中,很多患者自填信息没有通过认证。如果直接使用会导致分析结果的偏差。另外由于不同数据库之间没有对接,很多患者的诊疗记录无法形成完整闭环,不能真实记录患者历程。
3.3 患者隐私保护
随着国家数据管理政策法规的加强,大多数医疗数据源都有隐私保护意识。但是关联整合多方数据库之后,隐私保护就不再是简单的问题。进一步加入患者在互联网行为数据之后,通过对大量脱敏数据的分析后倒推患者身份信息的风险也在提高。在开展罕见病的RWD 研究时,由于罕见病本身的患者稀少,如果没有充分的设计,很可能导致患者信息的泄露。如何在支持医疗大数据使用的同时保护患者隐私是医疗大数据发展必须面对的问题。
3.4 大数据技术困难
医疗大数据本身必然会充分体现4 个V 的特点。这是医疗服务的复杂多样性加上每天大量的就诊患者流决定的。巨大的绝对数据量和每天快速的增长量为数据标准化、整理、存储、数据质量检查和提取等IT 技术提出很高的要求。更严峻的挑战在于如何快速利用这些数据,即时建模,即时更新,并使用到医疗工作当中。类似语意识别分析技术这样对非结构化数据分析利用的方法在医药评估上还有很大的进步空间。
大数据在医疗卫生领域的应用广泛,然而,在实际的数据应用中,同样存在一定的挑战。这些挑战诸如医疗卫生数据的过于分散性以及各大机构对于医疗大数据的利用率较低的问题等,使得数据分析存在一定的艰难性。此外,针对于医疗卫生行业,其大数据中包含了大量的非结构化数据,在关于合理整 合及存储、合理利用这些非结构性数据上,同样存在一定的困难。最后,在关于医疗大数据的应用上,相关法律环节的缺失、医疗数据分散在不同平台中所形成的信息孤立、标准化的缺失 导致的信息共享困难等,使得大数据在医疗卫生的发展面临更多的挑战[11-13]。
4 展望和建议
中国的医药市场正在逐步建立一个以价值为主导的运行体系,无论是国家医保报销药物目录的动态更新还是临床指南的改进均需要对已经上市的药品进行系统价值评估。国家卫计委卫生发展研究中心牵头正式启动的中国卫生技术评估机制建设项目更是强调了医药使用中的循证研究。医疗大数据可为验证新药上市后在真实世界中的效果研究提供强大的信息源。可以预见,医疗大数据在中国的应用会越来越深入。在建设医疗大数据的过程中,建立数据管理和共享的法规制度,明确医疗大数据中隐私保护的范围和标准,制定国家医院HIS 的国家标准和联网技术规范将为医疗大数据打好基础。用开放的态度允许有偿共享不含敏感患者信息的医疗数据库,可以增加建设大数据的资源。吸引包括学界和企业界的研究机构多方参与医疗大数据分析和应用会加速总体数据技术的创新。
猜你喜欢
现代仪器与医疗(2022年4期)2022-10-08
中老年保健(2022年1期)2022-08-17
中老年保健(2021年9期)2021-08-24
中老年保健(2021年12期)2021-08-24
大学(2021年2期)2021-06-11
中国卫生(2016年1期)2016-11-12
中国卫生(2016年1期)2016-11-12
中国卫生(2016年1期)2016-01-24
中国卫生(2014年3期)2014-11-12
浙江人大(2014年5期)2014-03-20
