
基于密度异常因子的武器装备故障检测方法∗
2019-06-06 08:12:02刘冬冬
舰船电子工程 2019年5期
刘冬冬
(中国电子科技集团公司第二十研究所 西安 710000)
1 引言
高新技术在武器装备中的应用越发广泛,因此武器装备的故障检测诊断和维修保障工作也更为重要[1~2]。武器装备的故障具有很强的隐蔽性和随机性,而目前的装备故障检测依赖种类多,通用性差,而且操作复杂的故障检修设备,其自动化程度低,对工作环境要求苛刻,不能实现快速检测[3]。针对装备故障发生后的诊断与分析,国内进行了很多研究,文献[4]采用基于决策树的方法来发现军用装备故障特征与故障点之间的关联,文献[5]提出了一种适合飞机机电系统故障诊断的改进免疫算法,文献[6]设计了一种基于虚拟仪器和BP神经网络技术的液压系统远程故障诊断系统。
武器装备在服役过程中,对其稳定性要求较高,不只是需要在故障发生后能快速诊断与检修,也需要在运行过程中去实时检测异常,防止发生大的故障导致硬件损坏。当装备有发生故障征兆时,其运行状态参数也往往会发生变化,产生一些异常参数信息,因此,本文提出一种基于密度异常因子的异常检测方法,针对采集的武器装备运行数据集,计算数据在其近邻中的密度,并建立起密度相似队列。最终,根据密度相似队列和数据点与其近邻的密度差异,给出每个数据点一个异常因子值,武器装备的检修人员可以根据运行数据集中异常因子值较高的数据点快速定位和分析,确认装备是否存在异常或故障。
2 异常检测简述
异常检测是数据挖掘领域一个重要的研究领域,它是检测其行为很不同于预期对象的过程,这种对象称为异常点或孤立点[7]。而异常检测又常被称为离群点检测,孤立点检测或数据缺陷检测。
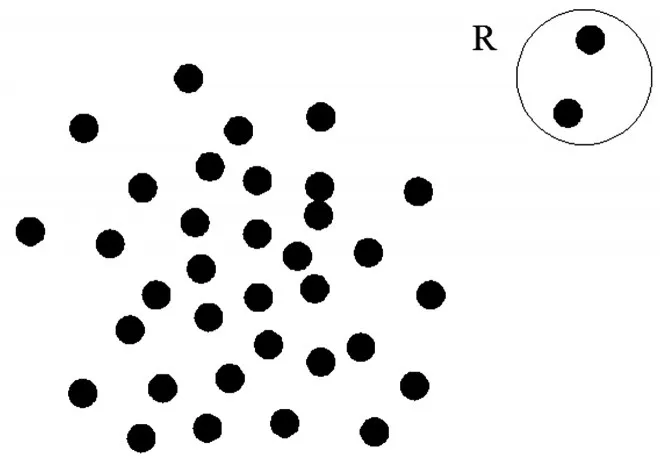
图1 异常点示意
异常点或孤立点是一个较复杂的概念,长期以来并没有一个统一的定义。例如,统计学的观点认为,异常点是关于数据集的概率分布模型中具有低概率的点[8];基于距离的观点认为,异常点是数据集中与大多数点之间的距离大于某个阈值的对象[9];聚类学派的观点则认为,异常点是不严格属于任何簇的对象[10];而基于密度的观点认为,异常点是具有最大局部孤立因子的对象[11]。这些对异常点概念的阐述都是从不同的侧重点出发,适用于某个具体的应用情境。Hawkins提出了异常点最权威的定义:异常点是明显偏离数据集中其他对象的数据,使人猜测这些数据并非随机偏差,而是产生于完全不同的机制[12]。
武器装备的运行状态数据中存在异常点,可能有两方面的原因。第一,装备存在某种故障,导致采集的数据中某些变量存在异常,该类异常需要被及时的检测和分析,以便进行相应的维修。第二,由于测量仪器的问题或者人为操作错误,所记录下来的测量值会出现不正确的情况。该类情况虽不及第一种严重,但在目前的军用研究领域,常常需要采集并存储装备的运行状态数据进行分析建模,如进行武器装备的效能评估[13],若数据集中存在异常点,则会影响后续的分析挖掘进程。
因此,无论异常点是由故障征兆产生还是测量失误,都有及时检测的价值和意义。然而,很多装备的运行数据采集周期短,数量大,靠人工很难进行有效的分析与检测,因此,构建一种可以进行实时异常检测和分析的算法是十分重要的。
3 算法
针对武器装备的运行状态数据集进行异常检测的需求,本文提出一种基于密度异常因子的异常检测算法,大多数武器装备的运行状态数据或检修数据都是具有多种属性的数据集,其本质都是在多维数据空间中的点。首先,针对多维数据集中的点,给出点的k-近邻密度的定义如下:
定义1:对任意正整数k,一个点 p周围的密度等于它到k个最近邻点的平均距离的倒数。

式中:Nk(p)表示 p的k近邻邻域,dist是求两点之间距离的运算符,median为取中值运算符。该定义可以较好地反应出数据集中点的密集分布程度。
在点的k-近邻密度的基础上,给出算法的详细步骤流程。
输入:数据集D;任意正整数k;
输出:数据集D中点的异常因子值。
算法描述:
步骤1:计算数据集D中点两两之间的距离并且确定出每个点的k-近邻邻域;然后根据式(1)计算出所有数据点的k-近邻密度。对象间距离的量度有很多种,本文采用常用的欧几里得距离。
步骤2:根据D中所有数据点的密度值构建密度相似队列(DSQ,Density-Similarity-Queue)。

式中:oi∈Nk(p),i=1,2,…,r,并且 r是 Nk(p)中点的个数。
假设X和Y是两个非空数据集,且X∩Y=φ,则它们之间的k-密度差值可定义为

对于任意给定的x,x∈X,如果Y中存在点y使得Δkden(x,y)=Δkden(X,Y),则 x被称为对于Y的密度相似近邻。
因此,步骤2是一个反复计算的过程,DSQ(p)的初始值是{}p。在每次计算时,算法不断从Nk(p)剩下的点中找到对于DSQ(p)的密度相似近邻,并把找出的对象加到DSQ(p)中去。如果找到的对象不只一个,则根据事先排好的对象顺序将前者加到DSQ(p)中去。在每次计算完毕后,更新DSQ(p)信息后再进行下一次计算。当Nk(p)中所有对象都被陆续加入到DSQ(p)后,该步骤结束。此时,对象p的密度相似队列构建完毕。采用同样的方法,算法可以完成对D中所有对象的密度相似队列的构建。
步骤3:基于步骤2中的密度相似队列,计算平均连接波动(ALF,Average-Link-Fluctuation)。
ALF是用于描述密度相似队列的波动的,它可以反应数据点与其近邻之间的密度波动,且密度相似队列中越靠前的对象对ALF的贡献越大,具体计算如下:
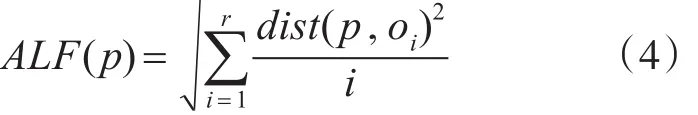
式中:r是Nk(p)中点的个数,dist(p,oi)是计算两点之间的距离。
步骤4:计算D中所有对象的密度异常因子(Density-Anomaly-Factor)。
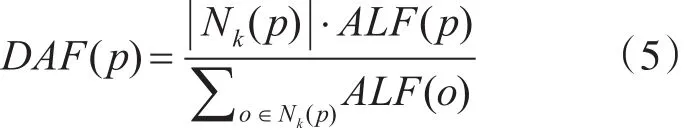
密度异常因子是基于数据点与其k-近邻邻域中点的密度差异,它给出数据集中每个点一个异常得分,故障诊断人员可以根据高得分的异常点进行针对性的分析。
4 仿真结果及分析
为了验证本文所提算法的有效性,本节将在实际数据集上对所提算法进行仿真实验,并与经典的LOF算法[14]进行比较,本文仿真所用数据集来自著名的UCI机器学习开源数据库。
4.1 评价标准
对于异常检测算法,学术界一般使用精度(Precision)、召回率(Recall)作为评价算法的标准[15],异常检测算法一般都是给出目标数据集中每个对象是孤立点的程度或得分,根据该程度从大到小将数据集中的对象重新排序。用Om表示这个新序列的最前面m个对象中所有孤立点的集合,其中m是大于等于1的正整数。
精度等于由算法返回的新序列的最前面m个对象中孤立点的个数占这m个对象的百分比:

式中: ||Om表示Om中对象的个数。
召回率等于由算法返回的新序列最前面m个对象中孤立点的个数占数据集中孤立点个数的百分比:

式中: ||Do表示Do中对象的个数。
根据以上两个评价标准的定义,算法的精度和召回率越高对于异常点的发现效果越好。
4.2 仿真实验1
实验1采用Johns Hopkins university ionosphere数据集,该数据集由good类的所有225个对象和bad类的10个对象组成,类的具体分布如表1所示。

表1 Johns Hopkins university ionosphere数据集类的分布
在该数据集中,bad类的对象相对整个数据集而言就是异常点,本文使用所提算法和LOF算法在该数据集上来检测异常点,仿真结果如表2所示,当m等于5和10时,本文所提算法和LOF算法的精度和召回率保持一致,然后随着m的增大,本文所提算法检测出的异常点个数要大于LOF算法,且精度更高。
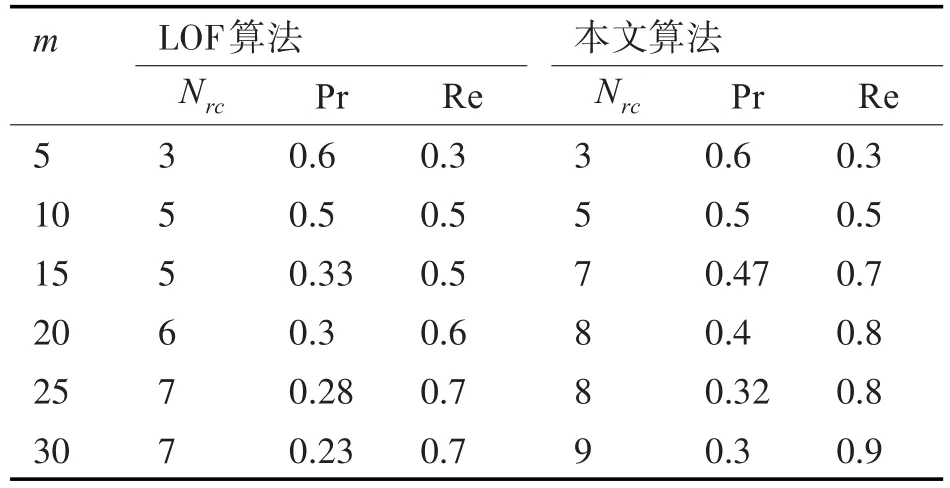
表2 实验1仿真结果
4.3 仿真实验2
实验2采用Pima Indians diabetes数据集,该数据集有8个属性且包括280个点,所有对象分别属于“0”和“1”两个类,类的具体分布如表3所示。

表3 Pima Indians diabetes数据集类的分布
同理,在该数据集中,“0”类中的12个点相对整个数据集为异常点,本文使用所提算法和LOF算法在该数据集上来检测异常点,仿真结果如表4所示,当m等于5时,LOF算法无法发现任何异常点,随着m的增大,本文所提算法的性能始终优于LOF算法,当m=60时,本文算法可以检测到所有的异常点,而LOF算法有3个异常点未能成功检测。

表4 实验2仿真结果
通过两组实际数据集的仿真可以看出,本文所提算法在检测异常点上具有较好的性能。
5 结语
本文在分析了武器装备故障检测现状与问题的基础上,基于数据挖掘的理念,提出基于密度异常因子的异常检测算法,能根据武器装备的运行状态数据与检修数据,发现数据集中隐藏的异常点,并使用算法在开源数据集上进行了仿真实验,与经典算法的对比证明的所提算法的有效性。因军用装备数据的保密问题,所提算法还未在多种实战装备的数据集上进行测试验证,未来仍需进行更多的测试验证。
猜你喜欢
睿士(2023年2期)2023-03-02 02:01:09
小学生学习指导(低年级)(2021年9期)2021-10-14 07:57:00
小学生学习指导(低年级)(2020年4期)2020-06-02 09:09:26
软件(2020年3期)2020-04-20 00:58:44
中学生数理化·七年级数学人教版(2019年10期)2019-11-25 07:34:00
小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:28
军营文化天地(2018年2期)2018-12-15 17:39:08
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:46
意林(2018年3期)2018-03-02 15:17:24
产品可靠性报告(2017年7期)2017-09-05 09:49:12
