
基于LSTM神经网络的燃煤锅炉热效率预测方法
2019-06-05 09:26:42李佳鹤周献军
智能物联技术 2019年3期
李佳鹤 ,徐 慧 ,张 静 ,周献军
(1.杭州深蓝数智科技有限公司,浙江 杭州 310053;2.浙江大华技术股份有限公司,浙江 杭州310053)
0 引言
工业锅炉作为一种高耗能特种设备,主要为工业生产提供工艺蒸汽,是工业和社会必需的动力机械,使用面广、需求量大,每年能耗约合4~5亿吨标准煤,每年消耗的能源约占我国能源消耗总量的1/4。2010年国家质量监督检验检疫总局颁布了《工业锅炉能效测试与评价规则》《锅炉节能技术监督管理规程》,明确规定对锅炉等高耗能特种设备进行节能监管,其中,对锅炉热效率的监管尤为重要。
目前锅炉热效率测试方法主要依据《GB/T 10180-2003》[1],该标准规定的锅炉能效测试方法所需仪器设备较多、测试时间长,加上燃料化验时间,得到测试结果一般需要15个工作日。一方面,该方法的测试结果具有一定的滞后性,不利于企业实时调整燃烧状况;另一方面,该方法测试成本高,不便于企业监测锅炉使用状况[2]。通过采集海量的锅炉运行历史数据,分析各参数之间的相关性程度,从而寻找一种快速有效的锅炉热效率预测方法,对锅炉使用单位实时掌握并调整燃烧参数,提高锅炉燃烧热效率有着重要的意义[3]。目前热效率预测建立模型的主要方法有神经网络和支持向量机等[4-8],李越胜、江政纬[9]提出了基于PSO-LSSVM算法的燃油工业锅炉效率软测量,预测结果表明基于粒子群优化的最小二乘支持向量机模型能较为准确地预测锅炉效率。徐齐胜、罗胜琪[10]提出基于BP神经网络建立锅炉燃烧预测模型,以排烟温度和飞灰含碳量作为神经网络的目标值,构建了锅炉燃烧过程仿真预测模型,具有一定的泛化能力。
锅炉燃烧过程属于持续性工艺流程,当前运行工况会受到前N个周期的工况时间序列叠加影响,现有技术方案从原理上都属于浅层学习方法,无法深入挖掘锅炉热负荷数据的随机性、滞后性和时间序列特征。LSTM(Long Short-Term Memory,长短期记忆网络),是一种时间循环神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件和规律特性。LSTM通过引入记忆神经元,能够对长周期的持续性时间序列数据进行深入挖掘,可以克服锅炉持续性燃烧调整的工况叠加带来的预测误差。本文在研究锅炉热效率和主要影响参数相关性的基础上,提出基于LSTM神经网络模型的燃煤锅炉热效率快速预测方法。
1 锅炉热效率的影响因素
燃煤锅炉的热效率受到多种热损失的影响,以机械不完全燃烧损失q4受锅炉燃烧状况的影响最为复杂。因此,可通过收集锅炉运行中排出的煤灰和煤渣,检测其中的含碳量,对比原料煤中含碳量的检测数据,计算锅炉热效率,作为样本的输出数据。根据《GB/T10180-2003锅炉反平衡分析法》,影响锅炉热效率的主要参数有:锅炉负荷、省煤器出口氧量、各二次风挡板开度、燃尽风挡板开度、各磨煤机给煤量、炉膛与风箱差压、一次风总风压等。
2 基于LSTM神经网络的锅炉热效率模型
构建基于LSTM神经网络的锅炉热效率预测模型主要包括以下几个步骤:
步骤一,选用现场DCS系统采集锅炉负荷、省煤器出口氧量等参数,检测煤灰和煤渣中的含碳量,按时间维度收集相关历史数据,形成燃煤锅炉热效率训练的样本集时间序列数据;
步骤二,对训练样本中的影响因子数据和输出数据进行标准化处理;
步骤三,将标准化后的样本数据序列输入LSTM神经网络进行训练,获得长短期记忆神经网络预测模型;
步骤四,将锅炉实时运行数据输入LSTM神经网络预测模型,计算得出锅炉热效率预测结果。
2.1 数据标准化
建立预测模型之前,需要对训练数据集中的影响因子数据和输出数据进行标准化处理。由于锅炉负荷、省煤器出口氧量等参数的值域范围无法限定,不能预设最小值和最大值,因此采用Z-Score标准化方法对训练样本进行标准化,根据每一个特征的值落在均值上下的标准差来重新调整每一个特征值。标准化处理可以消除影响因子数据量纲差异对预测结果产生的影响。
Z-Score标准化处理计算公式为:

其中μ为X因子的平均值,σ为X因子的标准差,计算公式为:
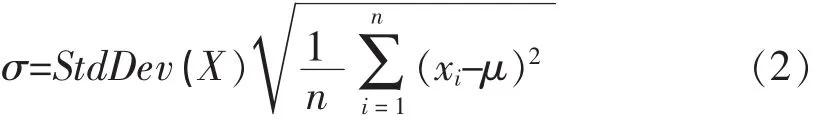
其中:μ为X因子的平均值,n为X因子的样本数量。
2.2 建立LSTM神经网络预测模型
将标准化后的样本数据序列输入LSTM神经网络进行处理,获得LSTM神经网络预测模型。
其中,LSTM神经网络由N个相互联系的递归子网络,也就是记忆模块组成。每个记忆模块包含了三个门(forget gate、input gate、output gate)与一个记忆单元(cell),它们分别对应着锅炉主成分特征样本数据序列的写入、读取和先前状态的重置(reset)操作。
包含记忆单元的LSTM神经网络的记忆模块如图1所示。
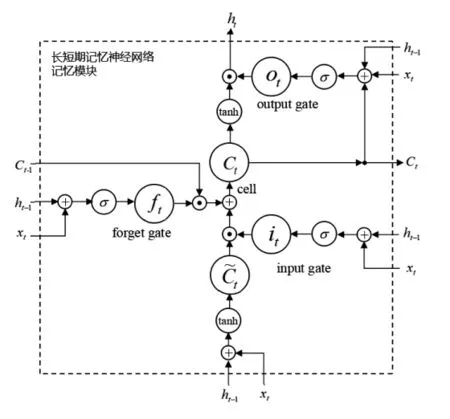
图1 LSTM记忆模块
LSTM神经网络的记忆模块执行步骤具体如下:
样本数据序列输入“forget gate”层,根据上一时刻的输出ht-1和当前输入xt,通过sigmoid激活函数,计算出一个0~1之间的ft值,计算结果决定了是否让上一时刻学到的信息Ct-1完全通过或部分通过。ft的计算公式为:

其中:σ表示 sigmod激活函数,Wf为“forget gate”层的权值向量,bf为“forget gate”层的偏置参数。
“input gate”层采用与“forget gate”层耦合的方式对向记忆单元(cell)注入的信息进行控制,共同决定哪些值用来更新。“input gate”层通过sigmoid激活函数计算更新值it;利用tanh激活函数计算更
tanh激活函数为:

it的计算公式为:
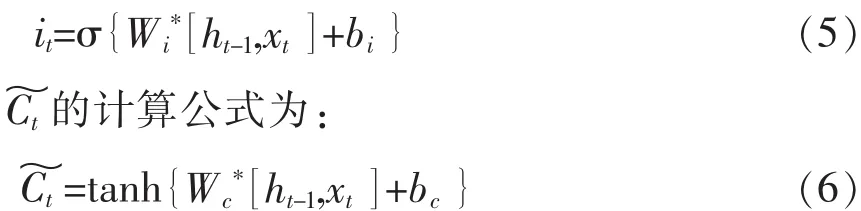
其中:Wi、Wc分别为“input gate”层和记忆单元(cell)的权值向量;bi、bc分别为“input gate”层和记忆单元(cell)的偏置参数。

最后计算该记忆模块的输出层 “output gate”,通过sigmoid激活函数来得到一个初始输出Ot,然后使用tanh将Ct值归一化到-1~1之间,再与sigmoid得到的初始输出相乘,得到记忆模块的输出ht。相关计算公式为:
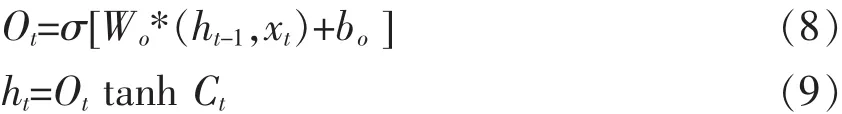
其中Wo为 “output gate”层的权值向量,bo为“output gate”层的偏置参数。
将锅炉实时运行数据进行Z-Score标准化后,输入训练完成的LSTM神经网络预测模型,将输出结果进行逆向标准化,即为锅炉热效率预测结果。
3 实验结果与分析
本文实验选取某热电企业燃煤锅炉历史运行数据作为实验样本,收集DCS系统中的锅炉负荷、省煤器出口氧量、各二次风挡板开度、燃尽风挡板开度、各磨煤机给煤量、炉膛与风箱差压、一次风总风压等参数,按时间维度收集相关历史数据,形成影响因子数据序列,收集锅炉运行中排出的煤灰和煤渣的含碳量化验数据作为样本的输出数据。
在训练LSTM模型时,利用 Xavier方法对权重初始化,采用Adam优化算法对LSTM神经网络进行训练,可动态调整针对每个锅炉样本输入参数的学习速率,适用于解决锅炉训练样本中包含高斯噪声的问题。训练过程设定损失函数最小为优化目标,给定网络初始化的随机种子数seed、初始学习率以及最大迭代次数Maxit=100。
本文用BP神经网络算法作为对比实验,BP神经网络采用3层网络结构,8个隐藏节点。实验对2个模型进行100次迭代训练,在每轮迭代完成后计算2个模型的loss值,迭代完成后统计模型的预测准确度。图2反映了2种模型的loss值随迭代次数的变化,图3反映了BP模型预测结果与真实值的对比情况,图4反映了LSTM模型预测结果与真实值的对比情况,表1反映了2个模型的预测误差统计分析结果对比。
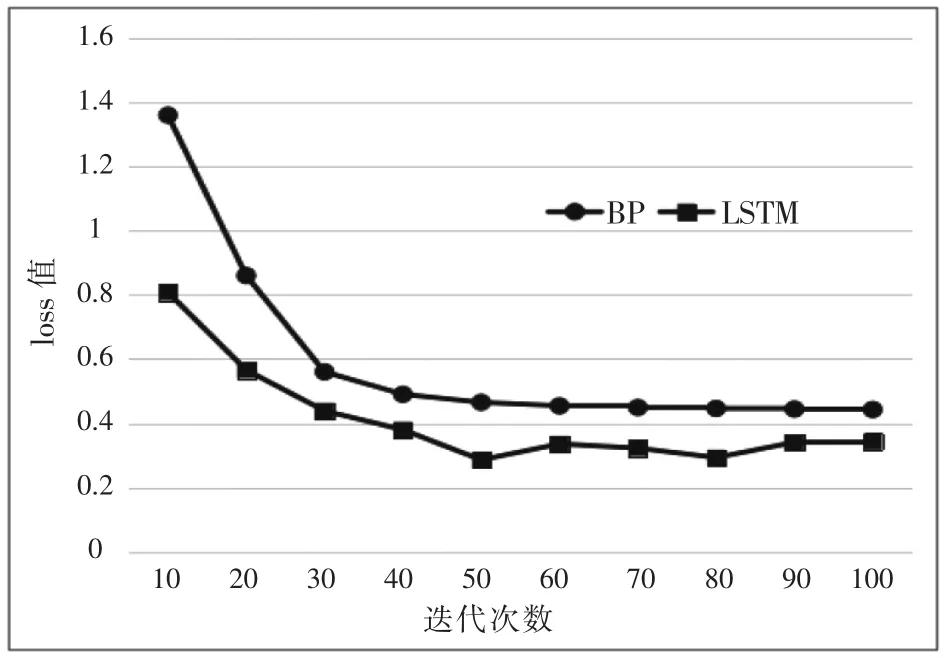
图2 算法训练loss值趋势对比
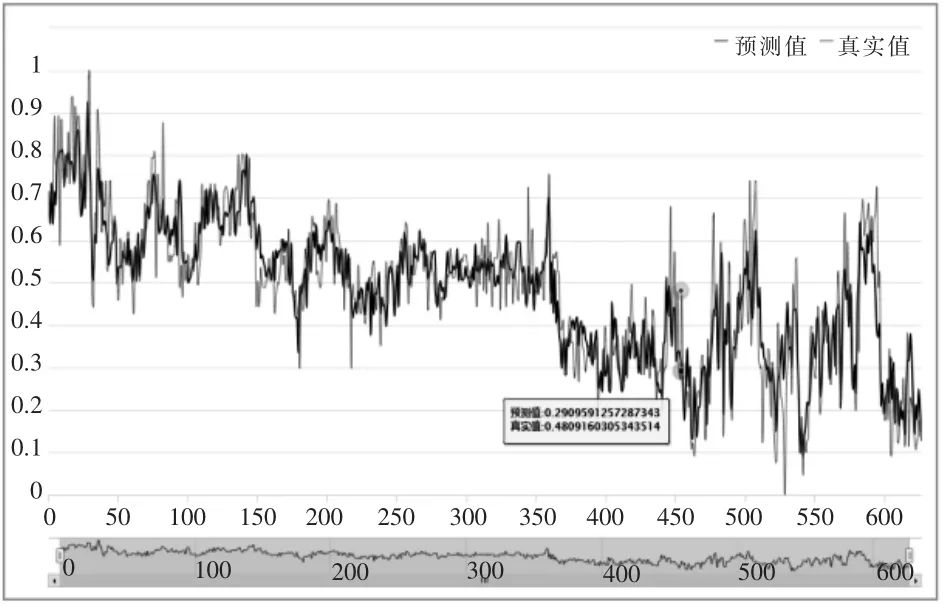
图3 BP模型预测结果
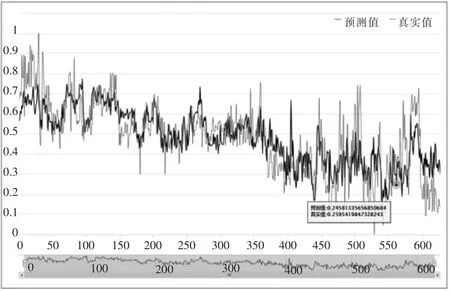
图4 LSTM模型预测结果
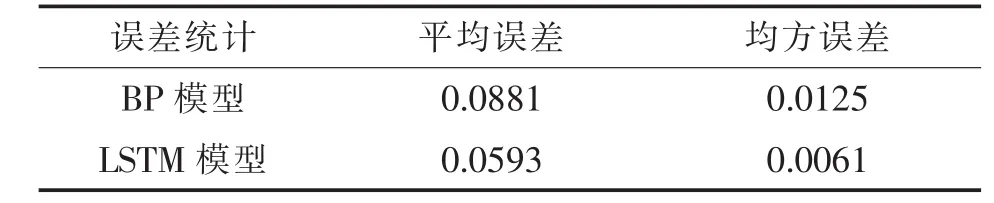
表1 模型预测误差统计分析结果
从实验结果可知,BP模型训练结果均方根误差为0.0125,LSTM模型训练结果均方根误差仅为0.0061。相对于LSTM神经网络模型来说,BP神经网络模型本身就存在对时间序列数据的规律特征学习不充分的先天性不足,这一缺陷导致它无法学得时间维度特征之间的关系,并且随着迭代次数的增加,容易出现过拟合或学习能力下降的情况,导致学习不充分。
本文采用的LSTM神经网络模型是由上一时刻神经网络模块的输出单元和记忆单元的状态信息以及当前时刻的输入单元,共同决定当前时刻记忆单元状态信息的更新,使得学习更加充分,并且有效避免了在学习过程中出现的梯度消失问题。实验结果表明,利用锅炉运行参数时间序列数据预测锅炉热效率指标方面,本文的LSTM神经网络预测模型要优于BP神经网络模型。
4 结语
本文采用LSTM神经网络对燃煤锅炉热效率进行建模预测。通过收集有关参数,形成时间序列样本集,构建LSTM神经网络模型,用于预测燃煤锅炉热效率。和传统BP神经网络预测模型相比,LSTM神经网络模型能够挖掘并记忆锅炉连续运行过程中参数自身变化与热效率影响的客观规律,使得学习更加充分,在工程中具有较高的使用价值。
猜你喜欢
昆钢科技(2020年6期)2020-03-29 06:39:50
电子制作(2019年19期)2019-11-23 08:42:00
山东冶金(2018年5期)2018-11-22 05:12:06
山东工业技术(2016年15期)2016-12-01 05:30:56
当代化工研究(2016年2期)2016-03-20 16:21:16
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
汽车与新动力(2015年1期)2015-02-27 12:11:00
中国设备工程(2014年1期)2014-02-28 13:43:26
