
路由器之VRRP排障篇
2019-06-04 06:01:14河南李虎夏晓斌
网络安全和信息化 2019年5期
■ 河南 李虎 夏晓斌
编者按: 笔者单位在经过网络升级后,出现业务系统登录不畅的问题,笔者经过一系列排查发现,是因为ACL访问列表的加入导致VRRP协议工作出现异常。
S集团下属某分公司使用两台H3C6604路由器部署在内网边界,直连内网核心交换机,同时通过两条运营商专线(800M移动和50M电信),上联集团总部。
两台路由器使用VRRP协议做双机热备部署,电信专线路由器内网互联IP为10.*.*.222(以下简称“222”),移动专线路由器内网互联IP为10.*.*.223(以下简称“223”),建立了VRID分别是100和200的两个VRRP热备组,热备组100的master是移动专线路由器,虚拟IP是10.*.*.210,内网核心上把去往集团的大部分流量指向了该IP;热备组200的master是电信专线路由器,虚拟IP是10.*.*.211,内网核心上把去往集团总部的少量重要业务指向该IP。
因为两条专线存在较大差异,通过上述部署,可以实现电信专线故障后,该链路上的所有流量可以由移动专线承载,而移动专线故障后,仅有少量业务流量转移至电信专线传输。VRRP热备组拓扑结构如图1所示。
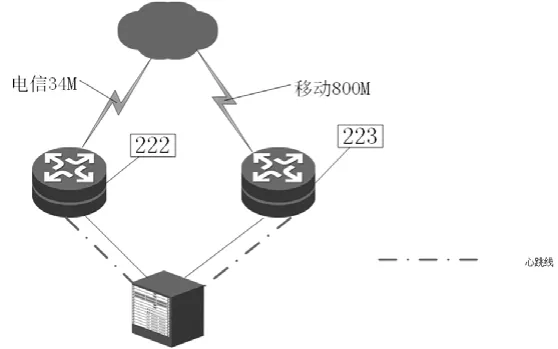
图1 VRRP热备组拓扑图
故障现象
近日,集团公司要求加强网络安全管控,该分公司网管在核心交换机上设置了ACL访问列表,把去往集团总部的流量实行白名单准入策略。
随后两天陆续有很多用户反映访问集团总部应用系统时快时慢,无法进行耗时较长的在线业务,分给两条专线的业务都存在这样的问题。
网管人员通过ping总部服务器发现有时很流畅不丢包,响应时间很短;有时丢包严重,响应时间也较长。
故障分析
针对这一现象,网管员首先逐一检查了核心交换机上的ACL策略条目,白名单策略都是严格按照分公司到集团的业务访问需求做的,该通的都放通,且ACL不结合QoS策略,不会对流量快慢造成影响。接着联系移动和电信检查了专线链路,也排除了链路质量问题。难道是网络攻击造成的?网管员检查了在内网核心和路由器之间做透明部署的防火墙,检查了各类日志,也未发现异常。
在排除了ACL策略、链路质量和网络攻击等故障原因之后,网管员把思路重新调整到路由方面,这一调整确实有重大发现。之前,网管员登录网管平台曾发现50M电信专线流量明显有异于平常,这几天里有大量的突发流量超出了专线带宽。另外,使用tracert追踪路由,发现本该走移动专线路由器223的流量走的却是电信专线222(如图2),过一会儿再tracert,发现又正常了,如此频繁反复,造成了50M电信专线上时常承载了超出自身带宽能力的流量,最终导致用户访问集团业务出现问题也不奇怪了,如图3。

图2 使用tracert追踪路由结果

图3 频繁反复走tracert致流量过载
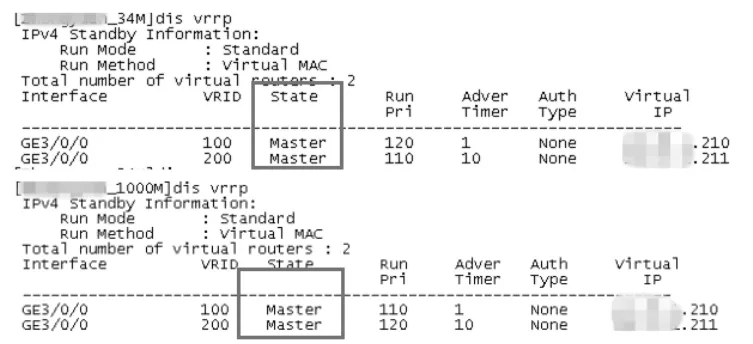
图4 两台路由器都宣告自己是master
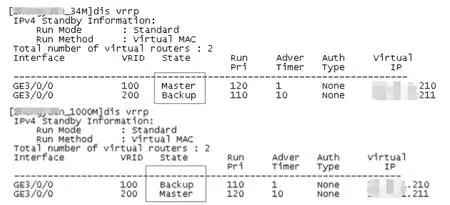
图5 增加一条策略后再次登录路由器观察
总结上述发现,即内网核心上去往总部的下一跳地址在两个专线路由器之间来回变化,最终导致访问总部业务的异常。接下来就是寻找下一跳地址来回变化的原因了。内网核心交换机把去往总部的路由分别指向了两个专线路由器VRRP热备组的虚拟IP,这一点不会变化,而虚拟IP代表的路由器是可能发生变化的,一般情况下,热备组中的优先级高的那台路由器会被选为master,这时,master才是虚拟IP的真身。网管员分别登录两台路由器,发现两台路由器都宣告自己是master,如图 4。
两台路由器都认为自己是master,都会给内网核心交换机广播IP(热备组虚拟IP)相同但MAC不同的ARP信息,导致核心交换机上去往总部的路由下一跳不断地变化,由此引发故障。
双Master的出现一定是两个路由器通信出现了问题,要么是互相不通,要么是VRRP工作异常。在两台路由器上互ping对方内网接口地址(222和223),并没有问题。那么剩下的就只有VRRP机制工作异常这一个可能了。
故障解决
仔细回顾了一下VRRP工作原理,结合此故障现象发生的开始时间与开启白名单准入进行访问控制的时间相同,所以故障原因应为做白名单准入的ACL阻断了两个路由器之间的VRRP协商,而VRRP主备协商要用到的组播地址224.0.0.18并没有在这个ACL的放行策略里。
此时,故障的前因后果完全清晰起来,最后一击就变得很简单了,在核心交换机的ACL访问控制列表中增加一条访问策略,如下:
rule 99 permit ip source any destination 224.0.0.18 0
增加这条策略之后,再次登录路由器进行观察,持续双master的问题得到解决,业务恢复正常,如图5。
猜你喜欢
现代装饰(2022年4期)2022-08-31 01:39:24
科教新报(2022年24期)2022-07-08 02:54:21
铁道科学与工程学报(2020年7期)2020-08-07 05:01:54
海洋信息技术与应用(2020年2期)2020-07-27 01:42:08
现代装饰(2020年7期)2020-07-27 01:28:32
现代装饰(2018年5期)2018-05-26 09:09:15
现代装饰(2018年5期)2018-05-26 09:09:05
中国防伪报道(2015年4期)2015-12-27 00:52:35
中小企业管理与科技·下旬刊(2015年11期)2015-06-11 06:36:43
河南科技(2014年22期)2014-02-27 14:18:13
