
基于用户负荷的用电模式分析方法∗
2019-06-01 08:08:46邓明斌谭致远陈广开徐志淼
计算机与数字工程 2019年5期
邓明斌 谭致远 陈广开 韩 玮 徐志淼
(广州供电局有限公司 广州 510620)
1 引言
随着电力系统信息化程度的不断提高和配用电数据量的迅速增长,研究适用于配用电数据挖掘的算法并建立有效的知识发现模型,对配用电业务模式创新和智能电网的发展具有重要意义。然而到目前为止,“数据海量,信息匮乏”仍是电力企业面临的重要问题[1]。
电力大数据的内涵是重塑电力核心价值和转变电力发展方式。通过对市场个性化需求和企业自身良性发展的挖掘,实现由以电力生产为中心向以客户为中心转变,推动电力工业向低耗能、低排放、高效率的绿色发展方式转变。通过对配用电大数据的有效挖掘,推动以电网物理模型为核心的传统业务模式向以数据信息相关性为基础的大数据业务模式转变[2]。
本文研究的目的在于训练出用户历史用电的用电模式,判别当前用电行为是否存在异常,其作用体现在三个方面,首先,帮助营销稽查人员辅助判断用电异常嫌疑户;其次,是提高营销业务人员分析异常用户的工作效率,最后,是查获异常用户挽回供电企业损失,提高供电企业效益[3]。
建立用户用电模式采用了数据挖掘流程包括数据提取、数据处理、数据训练、异常判别、结果验证等,用电模式训练引进了数据挖掘中的K-means聚类算法,并结合当前业务对聚类算法进行了改进。
2 建立专变用户用电模式模型
建立用电模式模型主要分为两个阶段:训练阶段和异常识别阶段。选取正常天的分时电量进行训练,训练出用户正常的用电模式,再对待测数据进行检测。
专业术语说明:
梯度阈值:表示分时电量发生变化的最小幅度,超过该幅度则表示电量发生了变化。用gradient表示,由统计得出。
梯度归一化:由梯度阈值,根据分时电量是否增加,不变,减少归一化成1,0,-1。
2.1 用电模式训练阶段
2.1.1 用电模式训练流程
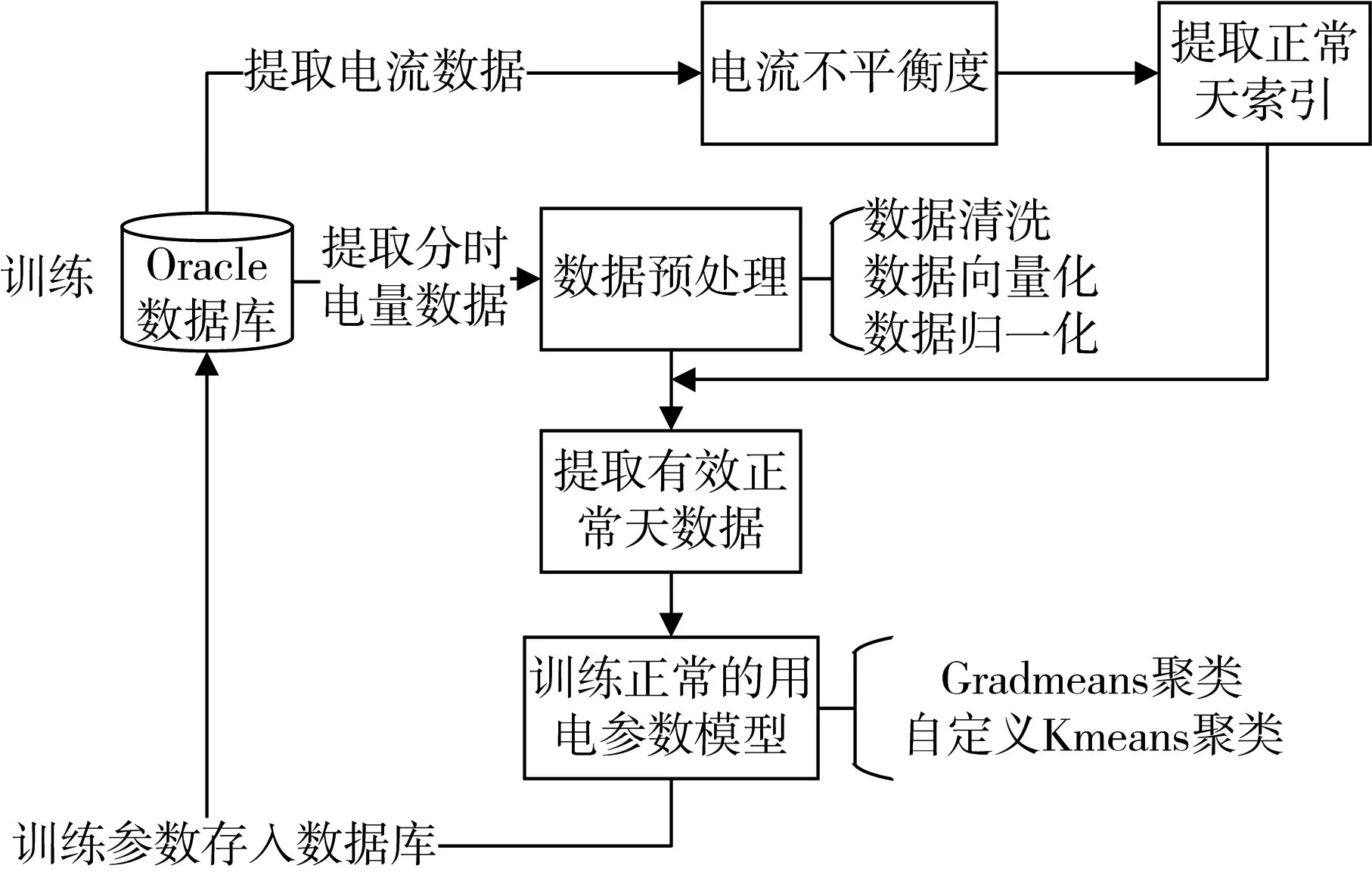
图1 用电模式训练流程图
1)提取用户电流数据,以用户电流平衡度来判断用户正常用电数据;
2)提取用户24h整点分时电量数据;
3)对数据进行预处理,包括数据清洗、数据向量化、数据归一化处理;
4)提取有效的正常天数据;
5)训练正常的用电参数模型,引进了改进型K-means聚类算法。
2.1.2 数据预处理
标记好正常日期后,接下来就是对数据进行预处理。具体包括:
1)首先进行数据清洗。有两类异常值会影响计算,第一类为数据空缺,第二类为计量故障得到的特别大的值,在这里直接滤掉。对于第二类异常值主要是由于计量故障引起的,得到的电量值可能是很多天的累计或者小数点移位等,导致计量的电量值可能是实际值的几十倍,甚至上百倍。对于这类异常值在数据计算前必须进行清洗,否则得到的特征值会很大,会增加异常的概率。根据数据的分布情况,这里设定临界值为99.9分位点,可以比较准确地清洗掉异常值,保留有用数据。
将数据按天提取成24维向量,方便计算。为保证训练数据的准确性,将不足24个点的,有空缺的天滤掉。
2)将数据进行归一化,这里采用:value=(value-min)/(max-min)*10,其中min为用户分时电量的最小值,max为用户分时电量的最大值。放大10倍便于计算,则归一化后的数据范围为[0~10]。
2.1.3 梯度聚类
聚类分析是数据挖掘技术中最重要的算法之一。常用的聚类方法可以划分为如下几种:1)划分聚类方法,包括K-means和K-medoids等算法;2)层次聚类方法,可分为凝聚算法和分裂算法;3)密度聚类算法,主要包括DBSCAN、OPTICS和DENCLUE算法;4)基于网格的方法,如STING 法;5)基于模型的SOM、COBWEB算法等。其中,K-means聚类分析法是目前应用最为广泛的一种算法,该算法由MacQueen于1967年提出,具有原理简单、计算快速的优点,尤其对于数值属性的数据,它能较好地体现聚类在几何和统计学上的意义[4]。
在进行kmeans聚类之前,先进行梯度聚类,然后将梯度聚类的结果作为kmeans聚类的初值。这样不仅使kmeans聚类有了一个比较好的初值,而且还指定了用电模式的个数。梯度聚类分为两步,第一步先进行常规的kmeans聚类聚成6类,第二步再把相似的用电模式按取均值的方式合并出最后结果。具体步骤为
1)将预处理后的数据进行kmeans聚类成6类,因为单个用户的用电模式一般为2~3个,这里先聚成6类,再根据曼哈顿距离把模式相近的进行合并。在这里求曼哈顿距离的时候先进行了梯度归一化处理。具体步骤:先将每天的24维分时数据向量[d0,d1,d2…d23]向前作差转化成23维的向量[d1-d0,d2-d1…d23-d22],然后对所有得到的数据取80分位点作为梯度阈值gradient,事实上梯度阈值会在一个合理的范围,所以有如下判断:
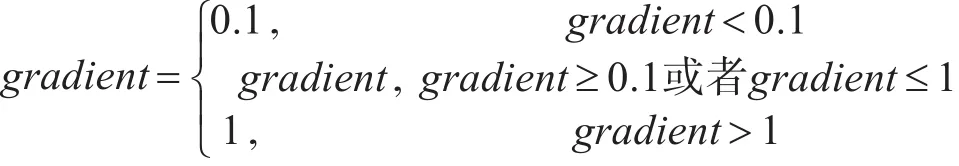
将所得的23维向量value_(0-22)进行如下转化:

这样就把原数据转化成了只包含0,1,-1的23维向量,再计算曼哈顿距离,这样可以使得越平行向量之间曼哈顿距离越小。
2)计算每个簇中的点到中心点的归一化的曼哈顿距离,取75分位点作为这个簇的势力范围,如果两个簇的中心点之间的归一化曼哈顿距离分别在这两个簇的势力范围之内,则说明这两个模式可以合并。若多个簇之前可以相互合并则一起合并。合并后的簇中心点为各个簇中心点的均值。重复步骤2),直到不能被合并为止,得到最后的用电模式。
2.2 用电模式异常识别
2.2.1 识别流程
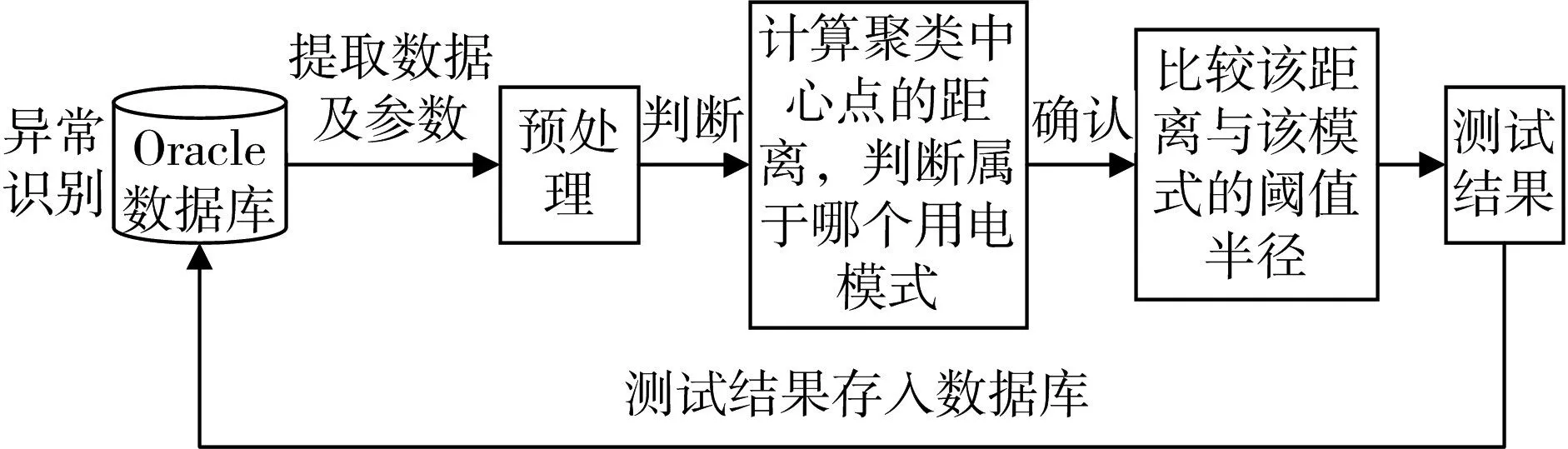
图2 用电模式识别流程图
1)提取待测数据及相关参数,待测数据为每天24h整点功率数据,在测试过程中,对于数据缺失不太多且没有连续缺失的天采用线性插值的方法进行填充;
2)数据预处理后,计算每天的数据向量到每个簇中心点的距离,离哪个中心点近,就判定它属于哪个簇。
3)当判定测试数据属于哪个簇后,还要进行确认它是否真的属于这个簇。这里采用测试数据到簇中心点的距离与该簇的阈值半径进行比较,若大于该阈值,则认为该用电数据不属于该模式,即可判定为异常,若小于该阈值,则可判定该天正常。
4)异常结果输出。
2.2.2 异常识别结果分析
用户A为大工业用户,存在一种用电模式,用电模式为双峰型,表示该用户过去长期都是这种双峰型用电模式,当前负荷轨迹与用户历史用电模型进行判别,两条曲线趋势和吻合度都很相似,判别结果为正常。
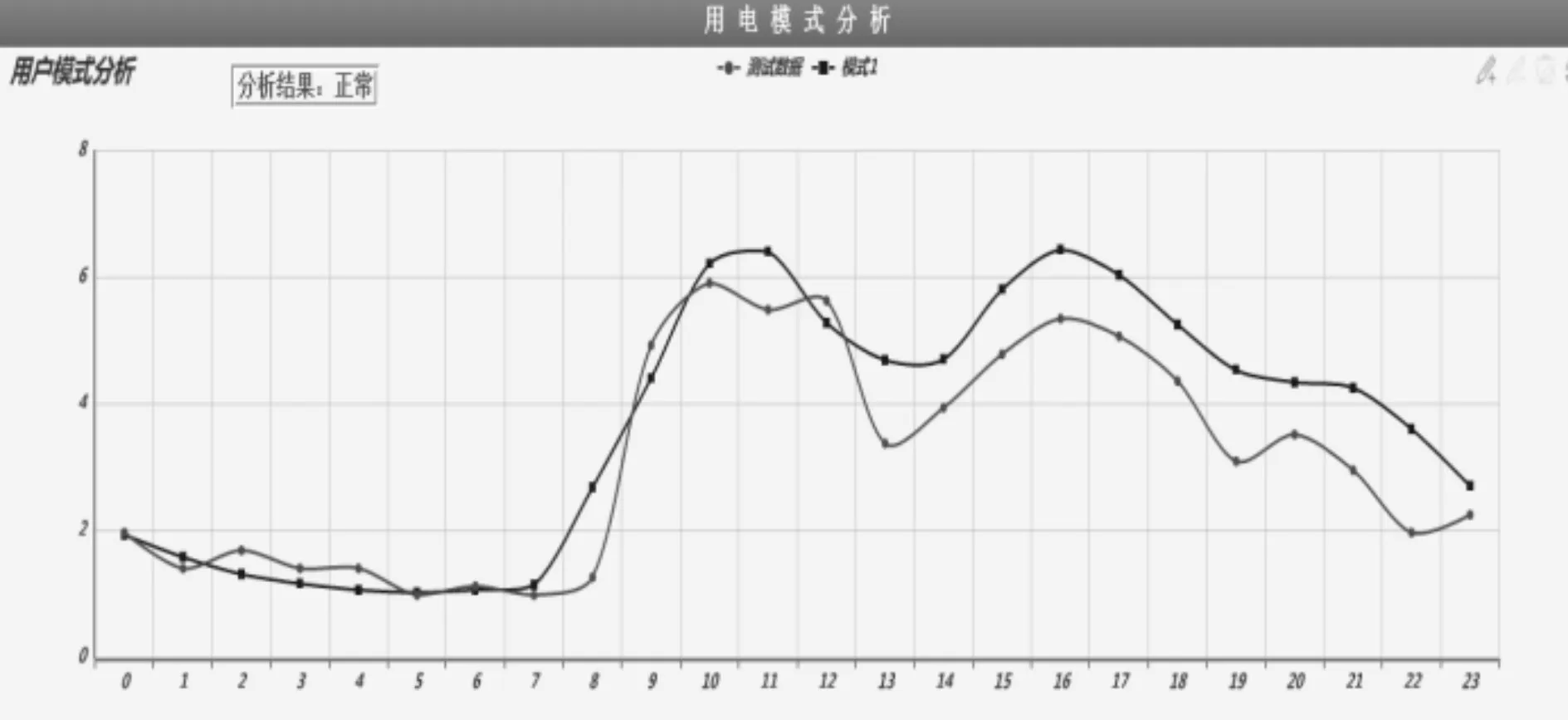
图3 正确用电模式
用户用电模式聚类结果有四类,当前测试数据与历史用电模式进行识别,最终判定出结果为异常。
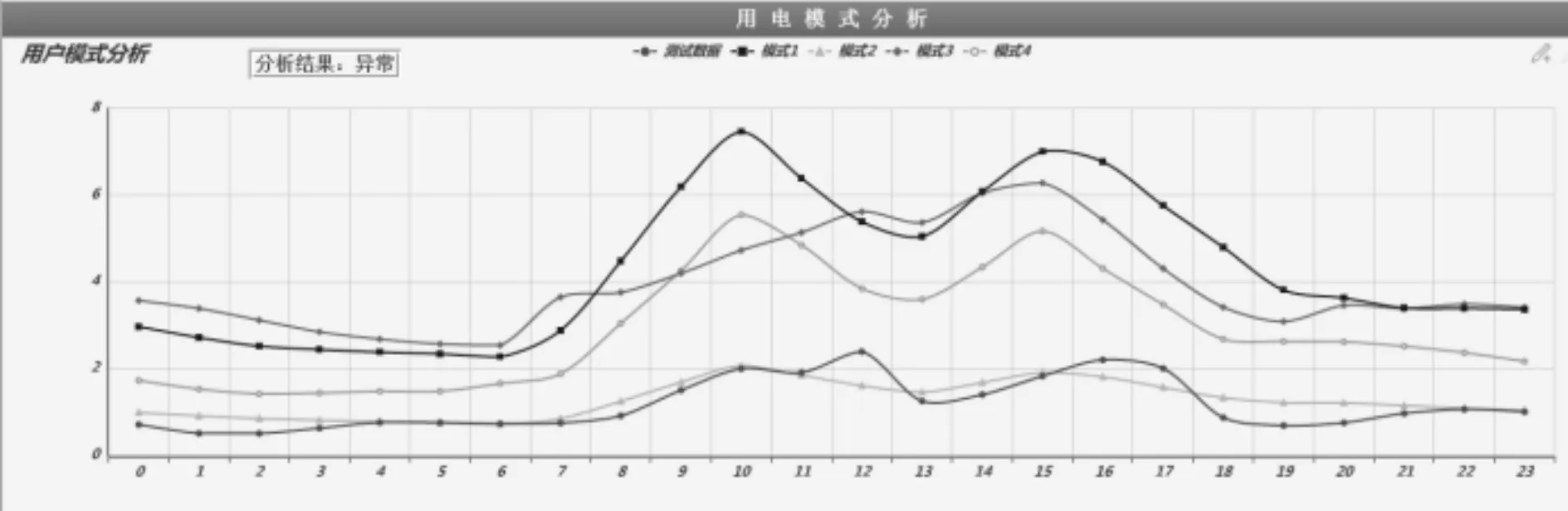
图4 异常用电模式
用户B,用电模式聚类结果有四类,当前测试数据与历史用电模式进行识别,再结合用户电量数据、用户日瞬时量数据进行判断,用户从2017年4月开始功率因数总开始无序波动且功率因数一天中超过多次低于0.5,再结合用户日电量、月电量数据分析,用户电量从4月开始下降,因此最终判定出结果为异常。
3 结语
实践表明,综合运用以上建立的模型分析法,基本能够做到及时、准确地将符合数据特征的窃电行为消灭在萌芽状态,无需另外投入,即可大大减少因窃电减少的经济损失。
猜你喜欢
学苑创造·B版(2022年9期)2022-05-30 18:16:10
数学物理学报(2021年6期)2021-12-21 06:24:38
电脑报(2020年12期)2020-06-30 19:56:42
应用数学(2020年2期)2020-06-24 06:02:50
电脑报(2019年4期)2019-09-10 07:22:44
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52
四川水力发电(2018年4期)2018-03-25 14:04:35
铁道通信信号(2016年8期)2016-06-01 12:10:21
少儿美术·书法版(2016年1期)2016-02-06 00:59:39
大众摄影(2015年9期)2015-09-06 17:05:41
