
基于随机森林算法的恩施市用水量预测
2019-05-27 09:57:58邬述飞
陕西水利 2019年4期
邬述飞,刘 远,金 锴
(湖北省恩施土家族苗族自治州水文水资源勘测局,湖北 恩施 445000)
0 引言
用水量是区域生产生活、生态环境用水的总度量,准确掌握用水情况,对合理调配、科学管理水资源尤为重要[1~2]。恩施位于湖北省经济、人口、水资源密集地带,但近几年来随着工业化发展区域用水需求增加,起用水结构也随着发生改变。鉴于此,本文拟以恩施地区为案例,阐释基于随机森林算法的用水量预测模型构建与方法有效性,并为区域水资源规划与管理提供参考依据。
1 随机森林算法
随机森林(Random Forest,RF)是Breiman等[3]提出的集成多棵决策树(Decision tree)模型{h(X,θk),k=1,2,…,}而形成的融合算法。该算法借助随机子空间和自助聚集理论,运用bootstrap方法从全部特征变量属性中进行随机等概率地放回抽样,对每个bootstrap样本构建决策树,通过打分寻找得分最高结果作为分类或回归的结果[4]。该算法主要流程为:
先利用bootstrap随抽样法从原始训练集T={(x1,y1),(x2,y2),…,(xn,yn)}中抽取n个样本,记作训练集Tt,进行k次抽样,则有k个独立样本形成的训练集。
然后对各bootstrap训练集构建回归决策树组合模型,单树由根节点遍历向下分裂,使其自由生长而不剪枝处理,k棵树集成即为随机森林。对于单棵树,从随机选择的m个属性中选出最优属性进行分裂。
生成的单棵树模型即为独立领域的专家,组合k棵树中得分最高的类别即为预测的结果。RF回归预测结果表示为k棵回归模型的预测结果是k棵决策树{h(X,θi,i=1,2,...,k)}回归的均值:

式中:P(x)为随机森林组合模型结果,pi为单棵树分类模型,I为指示函数,Y为输出变量[5]。
2 应用实例
2.1 恩施用水量预测变量选取
用水量主要受供水量、用水需求的制约,其中供水量的直接影响因素有水资源总量、降水量等,用水需求则体现为水资源供应对人口、经济发展的承载。在借鉴前人研究的基础上[6],综合考虑恩施市人口、经济、水资源环境等三方面因素,确定用水量预测模型的解释因子,依次为:总人口数(万人)、水资源总量(亿 m3)、人均水资源量、d.GDP(亿元)、单位 gDP 耗水量、第一产业占GDP的比重(%)、有效灌溉面积(千hm2)、城市人均日生活用水量(L)、农业人口数(万人)、第一产业用水总量(亿m3)、第二产业用水总量 (亿m3)、第三产业用水总量 (亿m3)、降水量(mm)。指标数据的时间域为2000年~2015年,从《恩施统计年鉴》(2001~2015)、《恩施市水资源公报》(2000~2015) 中提取指标原始数据。
2.2 基于随机森林的用水量预测模型构建
2.2.1 变量设置与参数优选
选取的13个变量分属不同量纲,不具可比性且其绝对数值差异较大,出于预测模型精度的考虑,将其进行归一化处理[7]。将所有样本数据划分为两部分,2000年~2010年的数据为训练样本,2011年~2015年的数据为检测样本,两类样本中解释变量作为输入值,用水量数据作为输出值,在RStudio1.0平台上调用randorForest程序包进行编程实现,样例代码参见[8]。
2.2.2 预测结果与精度比较
图1和表1分别为RF算法计算得到训练样本和测试样本的预测结果。为比较算法优越性,另使用RBF、SVM实施建模预测。依图1可知,3种不同算法均能够较好拟合用水量变化,对训练样本各年份用水量预测的相对误差介于-0.372亿m3~0.464亿m3之间,表明训练模型精度可靠。2000年~2010年恩施市用水量总体呈上升趋势,而于2003年用水量较之于往常年份有所降低,对这种局部异常 (图1-a、1-b),SVM和RBF算法未能准确模拟,RF模型则能够通过各解释变量变化特征捕捉到这一细节变化。训练模型统计显示,RF、SVM、RBF训练模型的平均绝对误差依次为0.78%、0.89%、0.67%。测试结果表明,基于RF的预测结果最优,其平均绝对误差仅为0.94%,而基于SVM和RF的预测结果的平均绝对误差分别为1.15%、1.58%。综合来看,基于RF的用水量预测模型精度高、预测效果良好,能够适用于用水量预测建模。
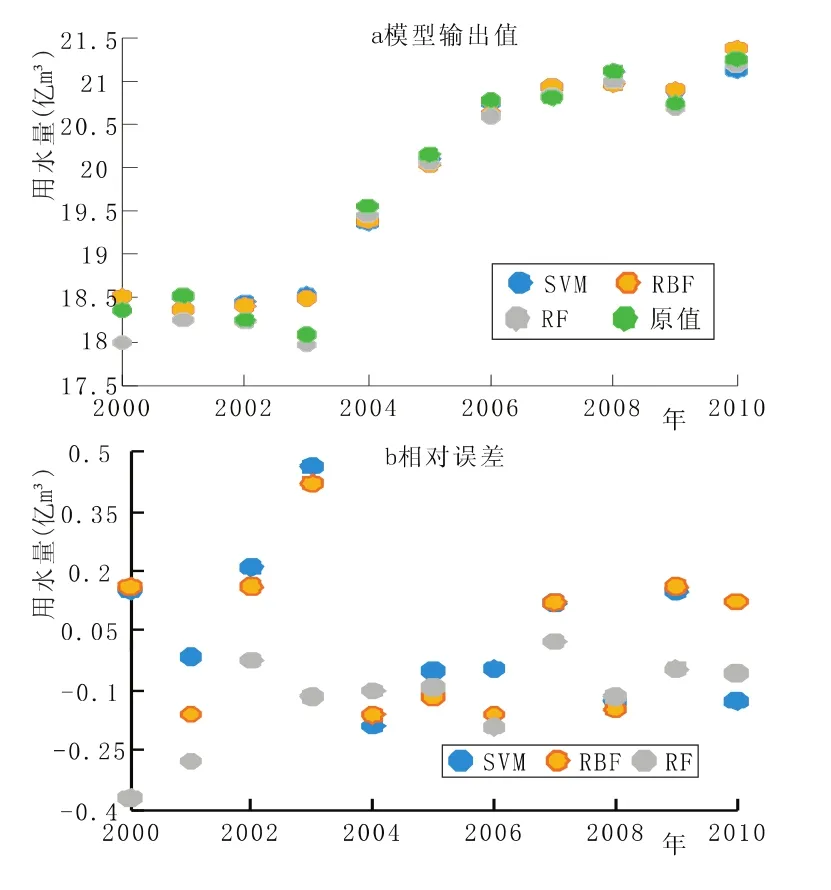
图1 三种预测模型训练精度对比
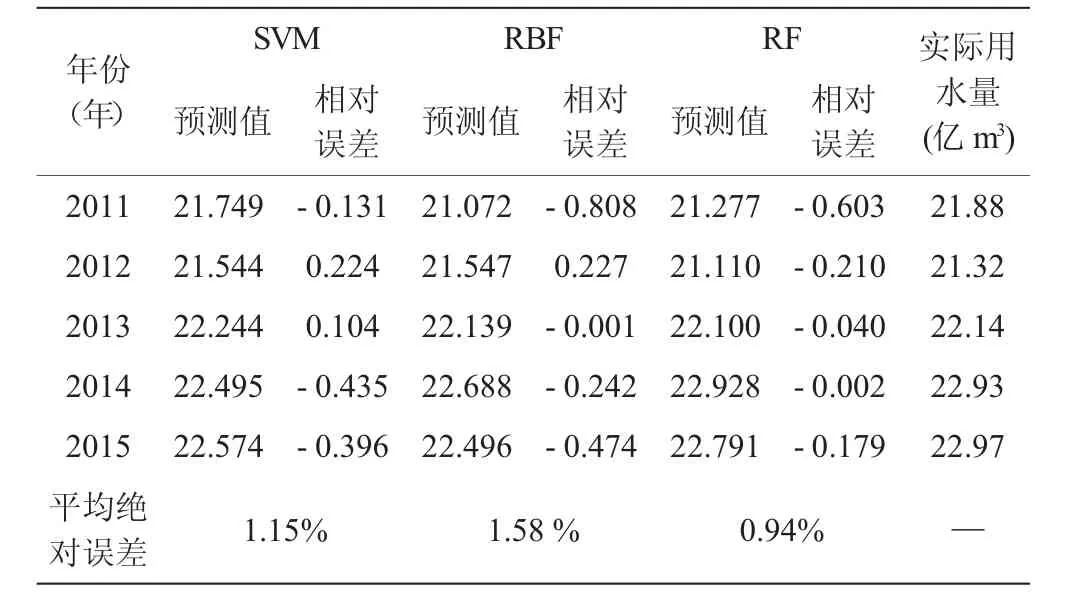
表1 三种模型测试精度与相对误差
2.2.3 解释变量重要性分析
在RF的每棵树中,使用随机抽取的训练自助样本构造决策树,并计算未选择数据即袋外数据(Out of bag,OOB)对模型的性能影响,即袋外误差,然后随机对OOB数据全部特征加入噪声干扰,再次计算袋外误差,变量重要性为两次OOB误差之差经标准化后在所有树中的平均值,其值越大,表明该变量对模型的重要性越大[9]。应用randomForest程序包中的importance函数获取重要性分值(图 2),可知农业人口数(万人)、总人口数(万人)、城市人均日生活用水量(m3)的分值最大,依次为达4.48、4.05、4.04,表明其对模型精度具有重要影响;第三产业用水总量、GDP(亿元)、第一产业占GDP的比重(%)、单位GDP耗水量、第二产业用水总量(亿m3)、第一产业用水总量(亿m3)的重要性分值介于2.93~3.93之间,它们对模型精度的影响次之;其他变量的重要性分值仅为0.083~0.072左右,表明其对模型精度贡献较差,在后续建模中应予以替换。

图2 解释变量的重要性
3 结论
随机森林算法能够较好地拟合2000年~2015年恩施市用水量变化,训练误差与预测误差均较小,表明该模型具有一定应用价值。用水量预测模型受多维因子共同制约,随机森林算法能够排除多维因素非线性的影响,并输出各因子对模型精度的影响荷载,这对于预测因子的筛选和模型精度提高具有重要意义。基于随机森林算法的用水量预测模型较于传统RBF和SVM算法的精度高,泛化能力强,具有一定优越性。
猜你喜欢
机电安全(2022年1期)2022-08-27 02:14:50
水利建设与管理(2021年12期)2022-01-15 08:37:24
中华环境(2021年8期)2021-10-13 07:28:34
小学科学(学生版)(2021年5期)2021-07-22 02:40:02
小学科学(学生版)(2021年6期)2021-07-21 09:18:26
今日农业(2020年14期)2020-12-14 19:47:34
智能城市(2018年7期)2018-07-10 08:30:30
山西省政法管理干部学院学报(2016年1期)2016-07-31 18:09:48
建材与装饰(2015年41期)2015-04-17 00:38:21
河南水利与南水北调(2014年1期)2014-08-15 00:47:53
