
基于领域知识的增强约束词向量
2019-05-24 06:41王恒升
中文信息学报 2019年4期
王恒升,刘 通,任 晋
(1. 中南大学 机电工程学院,湖南 长沙 410083;2. 中南大学 高性能复杂制造国家重点实验室,湖南 长沙 410083)
0 引言
自然语言是人类生产生活中长期积累形成的,用于表达情感、意图的工具以及记录、传播知识的载体。文字是语言的基本构成,是记录语言的符号体系[1]。用信息技术的术语来讲,自然语言是一种典型的信息系统。
计算机及信息技术的发展,为自然语言的计算机处理奠定了基础。按照认识论的分类,计算机自然语言处理可分为基于理性主义的方法和基于经验主义的方法。研究工作的早期阶段以依靠人类知识构建各种语言及语法规则的理性主义研究为主,形成基于规则的句法分析和语义分析技术[2]。随着处理自然语言的规模不断扩大,自然语言作为伴随人类进化过程而不断进化的一种信息系统,其复杂性特征和各种语言现象层出不穷,基于理性主义的方法很快遇到了瓶颈,导致无法处理大规模的真实文本[3]。基于统计学理论的经验主义方法,利用大规模语料库,使用概率统计的方法建立语言模型[4],取得了意想不到的成功。由于基于经验主义的方法在理论的完备性上存在不足,从长远来讲,要解决这个问题,必须将两种方法结合起来,彼此取长补短,才能相得益彰[5]。本文基于这一思想,针对自然语言处理的一个特殊应用场合(限定场合的对话系统),将理性知识融入词向量(一种统计语言模型)中,对词向量建模过程进行干预,得到本文称为“增强约束词向量”的文本模型。经实验测定,增强约束词向量具有更强的词语表达能力,针对本文的应用,能更准确地得到自然语言的语义信息。
本文后续安排如下: 第1节介绍应用背景,第2节阐述增强约束词向量;第3节介绍基于本体知识的增强约束词向量;第4节实验验证并分析实验结果;第5节总结全文,得出结论。
1 应用背景
计算机的应用进军到自然语言领域可以说是科学家雄心勃勃努力的结果,这一工作与人工智能有密切的联系,以至于图灵测试把人机自然语言对话作为通过人工智能检验的一个标准。基于自然语言的人机对话系统按照用途可分为开放型和领域任务型两种。开放型人机对话系统不针对具体问题,是一种开放式的对话,常用作聊天机器人;领域任务型人机对话系统往往针对某一场景,旨在帮助人类解决某一方面的实际应用问题。
本文将自然语言处理任务应用于大学校园的信息查询,针对某大学的一个集教学、科研和实验于一体的综合大楼,提供信息查询、路径导航等功能,是一种领域任务型人机对话系统的应用。(其中的信息查询系统本身不是本文的主要内容,不做详细介绍)
语义理解是人机对话系统的关键部分,其任务是对人的自然语言输入指令进行意图识别及要素提取。大多数学者采用改进语义理解模型的方法提高语义理解的准确性,如Xu[6]等将TriCRF模型与卷积神经网络结合,用于航班预定对话的语义理解,相比标准TriCRF模型在所用数据集上取得了更好的效果。Zhang[7]等基于循环神经网络提出一种联合模型,同时进行对话的意图识别与要素抽取,在所用对话数据集中,两个任务均取得了最佳的效果。尽管利用改进的模型取得了不错的效果,然而大多数模型的特征输入来源于传统方法: 手工标注、one-hot或基于词频的表示(如TF-IDF等)。手工标注费时费力,one-hot与基于词频的表示虽能自动构建,但无法考虑特征间的语义相关性,这个缺点成了进一步提高模型性能的瓶颈。
基于Harris假设[8]“具有相似上下文的词语,其语义是相似的”,Bengio[9]等于2003年提出经典的词向量训练模型——神经网络语言模型,将词的表示向量化,同时保证了语义接近的词语其词向量也是接近的。自此,众多研究学者开始利用带有语义信息的词向量作为文本的特征表达,以克服传统特征表示方法的缺点,提高任务效果。冯艳红[10]等基于词向量技术得到文本特征向量,采用CRF方法实现了领域术语识别,相比于传统的TF-IDF特征,提高了领域术语识别的精度;Liao[11]等利用含有文本主题信息的词向量作为输入特征,在中文情感分析任务中取得了良好的效果。
词的向量表达为自然语言处理打开了一个通道,吸引了大批的研究者。但由于自然语言本身的复杂性,已有的词向量训练模型得到的词向量往往表达力有限,词向量的实际应用效果还有待提高,寻找更好的词向量表达成为一个关键问题,将人类关于自然语言方面的知识显式地融入词向量中成为许多学者努力的方向。一类方式是融入通用语言学方面的知识,如字词的形态学特性(如汉语中的偏旁部首、英语中的词根、前后缀等)、句子的语法规则(如词性、英语中的比较级、单复数、时态等)、词语的语义特性(如文本数据库WordNet, Freebase, Probase等提供的词的关联关系)[12],或者词的情感特性[13];文献[14]利用句法知识,将动词、名词信息加入词向量的学习过程中,得到更准确的表达。另一类方式是将领域知识显式地融入词向量表达中,如Liu[15]等利用本体构建学术论文的领域知识,在训练过程中融入学术论文的语义关系,最大化上下文约束与领域知识约束。Chen[16]等利用UMLS(统一医学语言系统)作为额外的知识库,结合大量与医疗相关的未标注文章,生成医学领域词向量。Taghipour[17]等提出一种改进的词向量模型(adapted word embeddings),在词向量学习过程中增加更具有区别性的领域信息,得到针对于特定领域(金融、体育)的词向量,提高了词语消歧系统的准确性。
本文的研究属于上述第二类,针对校园信息查询对话系统的特殊应用,建立该系统基于本体的知识库,改进skip-gram的训练模型,将该应用的本体知识融入词向量的训练过程中,改造词向量的基分布,在词向量的表达中体现该应用的知识,提高该对话系统对用户提问的理解的准确性,实现更为自然流畅的对话过程。
2 增强约束词向量
训练词向量的基本思想可以理解为以语料库中词语之间的上下文关系为约束条件,对神经网络模型中的参数进行优化,其中的一部分模型参数就构成了词语的数字化表达,将其表示成向量形式,就是词语的向量表达。这种模型看似简单,但经过海量的模型训练,得到惊人的表达效果: 相近含义的词语会在向量空间中相对集中,具有相似关系的词语之间的向量差也会得到相近的向量。下面先简单介绍一下词向量的训练方法,然后介绍本文提出的基于领域本体知识的增强约束的词向量训练方法。
2.1 skip-gram方法
Word2Vec是Google公司2013年开放的、目前应用广泛的训练词向量的软件工具,是基于Mikolv等[18]所提出神经网络训练模型的实现,包括CBOW和skip-gram两种模型。本文采用skip-gram模型。
Skip-gram模型由输入层、投影层和输出层组成,如图1所示。skip-gram模型由前馈神经网络语言模型(feedforward neural net language model,NNLM)改进而来。与NNLM不同的是,skip-gram去掉了非线性隐藏层,投影层由全部词语共享。
整个模型是一种全连接神经网络,这里将输入层与投影层之间的权值矩阵W称为词向量矩阵,W∈k×V;投影层与输出层之间的权值矩阵称为辅助矩阵W′,W′∈V×k,k表示词向量维数,V表示词典大小。
模型输入是中心词wt的one-hot表示wt(wt∈V×1),它的第t个元素为1,其余为0。
投影层对输入进行式(1)所示的操作,取出词向量矩阵W中对应中心词wt的第t列的列向量vt(vt∈k×1)。
模型输出层是softmax函数归一化的条件概率p(wt+j|wt), 如式(2)所示。
其中,b∈V×1,表示偏置向量;w′t+j表示列向量w′∈V×1中第m个元素,m与词典顺序有关。
Skip-gram模型的中心思想是使用中心词wt预测上下文wt+j,其训练目标是使得目标函数取最大值,如式(3)所示。
其中,T表示语料库大小,c表示上下文窗口长度。

图1 skip-gram词向量训练模型
通过图1可以看出,skip-gram模型仅通过词语之间位置关系捕捉语义关系。在很多情况下由于语料不是规范的,例如,口语语料、微博语料等,词语之间的相对位置变动较大,出现较大的训练噪声,难以训练出所需的高精度词向量。为此,我们在skip-gram方法的基础上,针对特定应用,融入词库中词语的类别信息,提出增强约束词向量并给出了训练方法。
2.2 增强约束词向量训练方法
一般词向量在训练中(如skip-gram,CBOW等)仅使用词语之间上下文关系这一种约束条件,词语的其他信息(例如词性)并没有参与到词向量的训练过程中。本文期望通过在词向量的训练过程中,增加约束条件,改变词在向量空间的分布,使其分布更加合理。
本文的目标是限定领域的词向量应用,通过将特定领域的词进行分类,建立一个分类本体(ontology)。将这一分类本体看作是该领域的知识,作为约束条件,引入到词向量的训练过程中,期望得到的词向量能够反映这一知识,形成词向量在空间上更好的分布,更好地反映该领域的词的语义信息。
在词向量训练过程中,增加约束的有效方法是对其目标函数进行修正,或者是在训练过程中增加训练目标的多任务训练。图2为这种方法的一种实现—constraint-enhanced skip-gram(CE-skip-gram),在图1的skip-gram的基础上,增加了第二任务,形成了式(4)所示的目标函数。

图2 constraint enhanced skip-gram模型示意图
CE-skip-gram模型需要对语料{w1,w2,...,wt,...,wT}根据知识信息进行标注,具体标注方法见3.2节,得到每个词的标签{l1,l2,…,lt,…lT},l表示标签。
模型训练目标为最大化Q′,如式(4)所示。
其中,β表示控制约束力度的系数,β越大表示词的分类知识起的作用越大。
CE-skip-gram模型的输入层和隐藏层与skip-gram模型一致,投影层共享词向量矩阵W;不同之处在于,通过联合模型的形式,进行多任务学习,输出层在预测上下文的同时,也预测中心词的类别,通过附加任务,影响词向量矩阵W的参数。
模型的训练目标是最大化式(4)。采用梯度下降(gradient descent, GD)算法对目标函数Q′进行训练,如式(5)所示。
其中,α表示学习率,控制神经网络参数更新的速度。
这样,通过新的目标函数,在词向量训练过程中,将知识标签作为一种约束,干预词向量的生成。
3 基于本体知识的增强约束词向量
3.1 领域知识表达
本文涉及的信息查询系统针对于某大学科教大楼,通过自然语言人机对话,获得该大楼内的路线导航信息、教师信息、研究生信息、教学实验及科研学术活动等信息。该科教大楼是一个集办公、教学和实验于一体的综合建筑,以下简称CMEE。CMEE包含四栋建筑,其中A栋为办公区域,共6层,BCD栋为实验区域与教学区域,共5层。CMEE包含有实验室、办公室、会议室等功能区域,各层之间通过楼梯、电梯连通,各栋之间通过走廊连通,具有一定的综合性。下文对该大楼的本体知识表达方法,对大型商场、医院、综合办公楼等具有一定的参考意义。
知识表达的方法主要有: 产生式表示法、框架式表示法、面向对象表示法、基于本体(ontology)的表示法等。由于本体论提出了规范化描述领域知识的方法,解决了知识交互与共享问题,具有明显优势[19]。本文采用基于本体的方式,构建关于CMEE的领域知识。
本体是对共享的概念进行形式的规范说明,由概念、关系、公理和实例等要素构成[20],它在知识工程中表现为某一领域的概念定义集。首先根据事实,提取CMEE相关的重要概念,如人、活动、楼层等;其次对概念进行分组,建立本体框架,并定义类、关系及实例。图3为CMEE本体知识框架。该本体分为人物、建筑、活动三大类。人物类主要是对该大楼内活动主体进行描述,由老师、学生构成;建筑类主要是对该大楼本身的描述,由栋、层、房间、区域连接组成;活动类是对在该大楼内从事的相关活动进行描述,分既定活动和临时活动类。每种类下又分为若干子类,最后的实例就是具体的描述对象。
使用Protege软件,通过可视化的方式编辑本体,可以以本体语言(web ontology language,OWL)的文本文件形式输出。例如,对于本体间关系“教授是老师的子类”“王恒升是教授的实例”,使用OWL表示为:
之后,利用本体类作为增强约束项,调整词向量的语义表达。

图3 校园信息查询系统本体知识框架
3.2 CE-skip-gram的构建
CE-skip-gram方法的关键是利用词语的分类知识约束词向量,本文采用上述基于本体的方式构建关于CMEE的领域知识,利用领域知识构造词语的分类标签。由于本应用的特殊性,所有本体词语均是名词,故假设每个词语仅有一个标签。
构造词语分类标签的方法如下:
(1) 构建如图3所示的本体知识框架,对本体上下位关系进行分级,没有父类的本体称为零级本体,有一个父类的本体称为一级本体,其余依此类推。
(2) 利用本体知识框架对词语进行标注,标注粒度根据具体任务而定,从而实现不同粒度的知识表达。本文采用较粗的粒度标注,如果词语出现在本体框架中,且是一级本体,则采用本身的标签;如果是二级及二级以下的本体,采用二级本体作为标签,例如,“讲师”“副教授”“导师”“王xx”等词的标签都是二级本体“老师”的标签: “teacher”。
(3) 没有出现在本体中的词语统一给定标签“common”。
例如,对于语料“王|教授|的|办公室|在|哪里”,根据上述方法进行知识标注,得到序列“王|nh|教授|teacher|的|common|办公室|room|在|common|哪里|common”。
CE-skip-gram中的分类器可选常用的softmax回归、支持向量机等,本文选用BP(back propagation)神经网络,输入层是中心词的词向量,输出层选用softmax函数进行概率归一化。
由于本文所涉及任务的特殊性(针对CMEE),无法利用互联网开放的大规模语料,训练词向量数据集全部由实验室众师生与口语对话系统交互所得,共733条(表1)。

表1 语料示例
词向量模型训练需要先对训练语料进行分词,我们使用LTP平台进行分词,然后根据本体知识框架进行标注。本文增强约束词向量模型训练的基本数据如下: 本体知识标签数量为12;训练数据集共有733条语料,词的总数为599个;词向量维数k设置为30,约束系数β为0.7,学习率α为0.1,窗口大小c为2,训练100 000步。编程语言采用Python,词向量模型使用tensorflow框架进行编写。
3.3 关于词的岐义性的说明
自然语言处理的难题之一是词语语义岐义性(word sense disambiguation, WSD),因此消歧就成为该领域中的一个重要研究内容。杨陟卓[21]等采用语言模型优化传统的有监督消歧模型,利用这两种模型的优势,共同推导歧义词的语义;Agirre[22]等提出了基于词汇知识库的WSD算法,实验表明该算法能够更有效地使用WordNet图,性能优势明显。
本文中心词的语义类别获取采用的是利用3.2节中提到的构造词语分类标签的方法,这里的中心词语义标签实际上是本体标签(根据本体知识库构建标签),例如“teacher”“student”“area”“room”等。在本特定应用中,所有的本体词语均是名词,中心词出现歧义性的情况很少,消歧问题不突出。但随着应用范围的扩大,语义消歧会成为一个问题,需要关注。
4 实验及结果分析
评估词向量有两种方法: ①内部任务评价(intrinsic evaluation),②外部任务评价(extrinsic evaluation)。内部任务评价遵循“语义接近的词其词向量也是接近的”原则,通常评价词向量的语义相关性,这种方法需要人工收集近义词表。外部任务评价是在实际任务中对词向量进行评价,例如文本分类任务,通过任务结果来评估词向量,这种与具体任务相结合的评价方法是很有效的[23]。为验证本文所述CE-skip-gram模型的有效性,采用上述两种评价方法。内部任务评价见4.1节实验1,外部任务评价见4.2节实验2、实验3。
4.1 实验1: 内部任务评价
本文采用词向量语义相关性实验作为内部任务评价,使用Word2Vec研究中惯用的做法: 人工标注近义词组,处于同一个近义词组内的词,互为近义关系。测试数据共9组,36个词,如表2所示。

表2 近义词示例

续表
根据训练好的词向量,利用式(4)计算词与词之间的相似度sim。每个近义词组可以认为是同一类词,如果与某个词相似性最高的前三个词,与该词所在近义词组存在交集,且相似度sim>0.65,就认为该词向量是较为准确的(属于这类);否则,认为是不准确的(属于其他类)。这样评价词向量语义相关性就可以看作是多分类任务,评估指标选用精确率(P)、召回率(R)、综合二者的F1值以及准确率(ACC),计算方法如式(7)~式(10)所示。实验结果如表3、表4所示。
其中TP表示将正类预测为正类数;FN表示将正类预测为负类数;FP表示将负类预测为正类数;TN表示将负类预测为负类数。对于多分类任务,把每个类别单独视为“正”,所有其他类别视为“负”。
根据表3~4的实验结果可知,相较于skip-gram模型,CE-skip-gram模型所得到的词向量准确率更高,近义词词向量聚集更紧密。这个结果符合我们的预期。口语语料大多不规整,词语之间相对位置多变,skip-gram模型仅靠词语之间上下文关系约束词向量矩阵,出现较大训练噪声,所得词向量表达能力有限,而CE-skip-gram模型,在利用上下文关系作为约束条件的基础上,增加新的约束条件,利用词语分类信息约束词向量矩阵,减小了噪声的影响,缩小同类词之间的“距离”,使同类词语的词向量分布更加紧密,所得词向量更加准确。

表3 skip-gram模型与CE-skip-gram模型对比

表4 测试结果的部分细节
4.2 外部任务评价
本文所设计的信息查询系统中,语义理解模块是其关键组成部分(其中的信息查询系统未在本文中详细介绍)。该模块需要对语句进行解析,包括两个子任务: 意图理解(intent understanding)与槽填充(slot filling)。“意图理解”是对语句的整体按意图进行分类,“槽”指的是每一种意图的语句经过结构化处理的每一个要素的位置。
根据本文的应用场景,将用户对话意图分为以下7种: Query_student,Query_location,Query_activity,Introduce,Query_teacher,Query_org,Confirm,见表5;槽分为以下20种: teacher, where, name, who, nh, area, activity, p-prop, room, a-prop, org, list, person, location, research, att,

表5 语句意图示例
o, student, department, thing,语句结构化示例见表6。例如,语句“王××|的|研究生|有|哪些|人”,经过语义理解模块,输出意图为“Query_teacher”类,语句的相应要素为“name|o|student|o|which|o”。下一步需要根据所得意图与要素,生成知识库查询语句。

表6 语句结构化信息示例
该系统的知识库通过本体建立起来,是基于谓词逻辑的RDF描述文档。知识库的查询也是使用基于谓词逻辑的查询语句。本系统使用SWI-PROLOG语言,但知识库及Prolog的处理过程不在本文的介绍范围之内。
上述例句生成的查询语句可以表示为(A,is_a_student_of,王××)和(A,is_a,研究生)。其中两个 谓词分别为is_a_student_of和is_a,未知变量为A。通过查询知识库,可以得到结果A。文本处理流程如图4所示。

图4 文本处理流程图
本文所采用的外部任务评价就是利用词向量实现上述语义理解任务,通过评价任务来评价词向量。外部任务评价包括两部分,其一是意图识别实验(实验2),其二是槽填充实验(实验3)。将数据集按照2∶8比例分成测试集(147条)和训练集(586条),模型评估指标选用精确率(P)与召回率(R)以及综合二者的F1值。
4.2.1 实验2: 意图识别实验
对话意图识别是判别用户的意图(目的),是一种分类问题。我们分别将随机数词向量、skip-gram词向量与CE-skip-gram词向量作为分类器的输入,评价分类器的效果。使用的分类器分别为K近邻(KNN)、支持向量机(SVM)、卷积神经网络(CNN)和循环神经网络(RNN)。
KNN、SVM模型的输入是词向量的连接winput=[wt-i⊕...⊕wt⊕...⊕wt+j],构成的一个长向量winput∈m×1,m=l×k,其中l表示语句的长度,k表示词向量的维度,⊕表示连接操作。KNN、SVM模型使用sklearn机器学习工具包实现,模型参数设置见表7。

表7 分类器模型参数设置(1)
CNN模型[24]如图5所示,是一个5层的神经网络。CNN模型的输入是词向量的堆叠winput=[wt-i;...;wt;...;wt+j],构成一个矩阵winput∈k×l;第一层为卷积层,采用宽度为3、4、5的三种卷积窗口,每种窗口有8个卷积核用于特征提取;池化层采用最大池化操作;在拼接层将所得特征全部拼接;经过全连接层后进行softmax操作,得到分类结果。模型参数设置见表8。

图5 CNN模型示意图
RNN模型[25]是按照时间顺序输入语句中每个词的词向量wt,如图6所示。RNN神经网络单元采用双向长短期记忆神经网络(Bi-LSTM),前向LSTM读取序列的正向信息,得到前向状态fhi,反向LSTM读取序列的反向信息,得到反向状态bhi,状态hi=[fhi⊕bhi]。 最终状态hlast接全连接层,进行softmax操作,得到分类结果。模型参数设置见表8。

图6 RNN模型示意图

CNNRNN参数值参数值fliter_size3,4,5input_steps30num_filter8hidden_size100dropout_keep_prob0.7layer_num2batch_size8batch_size8num_epoch200num_epoch50
实验结果分析总结为以下两点:
(1) 从整体上看,四种机器学习模型均在使用CE-skip-gram词向量作为特征向量时,效果最优。原因在于随机数中未包含任何语义信息,skip-gram虽然可以提取到语义信息,但所提取到的语义信息不够准确,而CE-skip-gram可以提取到准确的语义信息,在skip-gram的基础上使机器学习模型学习效果进一步提升。
(2) 观察表9~12的实验结果,使用skip-gram词向量相比于使用随机数词向量,会给模型带来较大的提升,尤其是CNN模型,F1值提升了25.8%。但是这种提升效果在实验4中表现并不明显,原因在于RNN模型本身是序列模型,文本信息隐藏在序列中,模型不完全依赖词向量提供的语义信息,而KNN、SVM、CNN模型几乎不考虑文本的顺序,丢失了文本的序列信息,只能通过词向量获取语义信息,所以词向量构造的好坏直接影响模型的结果。

表9 实验结果1: KNN模型实验结果

表10 实验结果2: SVM模型实验结果

表11 实验结果3: CNN模型实验结果

表12 实验结果4: RNN模型实验结果
4.2.2 实验3: 槽填充实验
槽填充是指从用户对话中提取到与任务相关的关键信息。例如,在本文所涉及的对话任务中,老师、学生、活动地点等词就是关键的槽位信息。通过提取到的槽位信息,生成查询知识库的语句,得到所需的答案。槽填充任务实质是序列标注问题,本文采用的是基于注意力机制的编码-解码(encoder-decoder)模型[23]。
encoder-decoder模型是一种Seq2Seq(sequence to sequence)模型,如图7所示。在编码端,使用Bi-LSTM神经网络,前向LSTM读取序列的正向信息,得到前向状态fhi,反向LSTM读取序列的反向信息,得到反向状态bhi,在第i步的状态hi=[fhi⊕bhi]。 在解码端,使用单向LSTM神经网络,采用注意力机制[26],对每个状态hi进行解码,得到序列标注。模型参数设置见表13。

图7 encoder-decoder模型示意图

参数值input_steps30hidden_size100layer_num2batch_size8num_epoch50
观察表14的实验结果可以发现,①使用CE-skip-gram词向量的实验结果最优,使用skip-gram词向量与随机数词向量的结果大体一致。原因在于序列模型(Seq2Seq模型)主要利用文本的序列信息,而不是语义信息,所以即使是不包含任何语义信息的随机数词向量作为输入特征,模型也能达到可观的效果;②在同样的序列信息基础上,使用语义精度较高的CE-skip-gram词向量,可以进一步提升模型的效果。
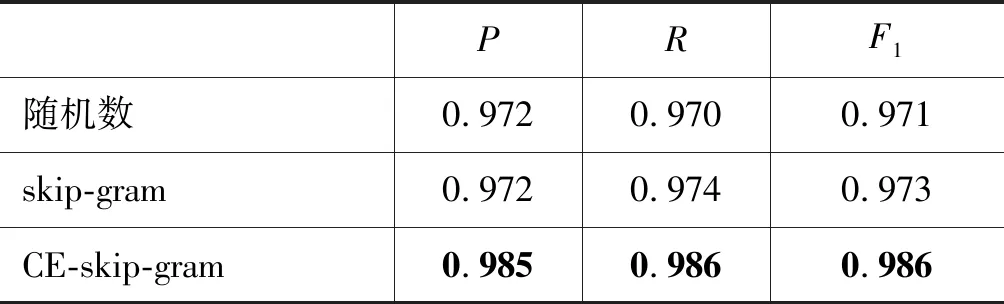
表14 实验结果5: 槽填充实验结果
5 结论
纵观自然语言处理研究的历史,理性主义方法与经验主义方法此消彼长。尽管近年来经验主义方法利用大规模语料,取得了一定的成功,但是它在理论的完备性上存在不足。要想彻底解决自然语言处理问题,必须将这两种研究方法结合起来。基于这种思想,本文提出了一种词向量训练方法——增强约束词向量模型。在利用词语上下文关系作为约束的基础上,将任务相关的知识作为增强约束项,干预词向量的生成。针对具体任务(限定场合的对话系统),我们首先利用本体表达领域知识,之后根据领域知识对词语进行标注,通过多任务学习的机制,将预测中心词的知识标签作为附加任务,对词向量矩阵加以约束,从而将知识信息引入词向量中。这样,词向量中蕴含的语义信息在人工知识的帮助下得以修正,使表达更加精确。采用内部任务和外部任务两种方法对词向量进行评估与对比,结果表明本文提出的增强约束词向量在表达词的语义信息方面更加准确,将其应用于特定场合的对话系统也得到了更好的意图理解效果,对提高自然语言对话的自然流畅性有较大的帮助。
本文的解决思路,用于提升领域任务型对话系统的语义理解与对话的自然流畅性具有一定的普适意义,对大型的商场、医院、地下车场、旅游景点等场合的口语导引系统等具有一定的借鉴意义。本文对于中心词的类别处理是根据知识库人工给出的,没有实现自动类别处理。为提高效率可进一步研究自动化获取领域知识的方法,增加本方法的适用性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
哈哈画报(2021年10期)2021-02-28
开放教育研究(2020年2期)2020-03-31
制造业自动化(2017年2期)2017-03-20
中国修辞(2017年0期)2017-01-31
高中生学习·高三版(2016年9期)2016-05-14
长江学术(2016年4期)2016-03-11
新高考·高二数学(2015年11期)2015-12-23
