
基于门控循环单元神经网络的PM2.5浓度预测
2019-05-22 09:27王玮王文发张哲
无线互联科技 2019年4期
王玮 王文发 张哲

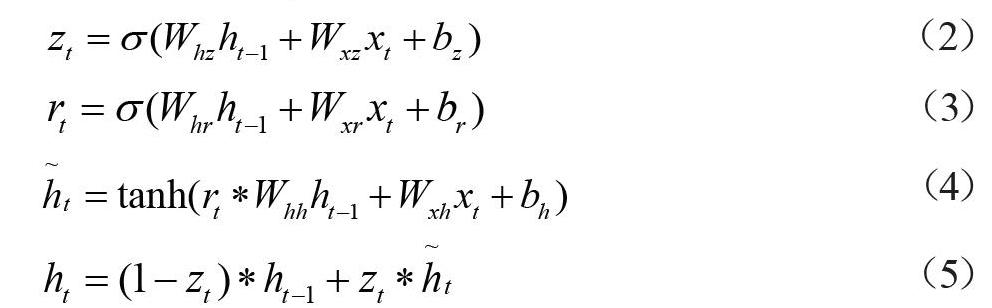
摘 要:文章首先针对延安市市监测站单站点观测数据与PM2.5的关系,从中抽取了影响PM2.5较为明显的14组特征数据。依据所抽取的数据,利用LSTM深度神经网络的一种变体GRU建立了未来数小时的PM2.5浓度预测模型,通过仿真实验,该模型对PM2.5预测有较高的一致性,可以较好地满足日常预测业务需求。
关键词:PM2.5浓度预测;LSTM;GRU;机器学习;循环神经网络
近年来,我国很多地方出现了严重雾霾天气,影响着人们生活的各个方面,最严重的危害还是对人体健康的危害。PM2.5作为城市环境质量恶化的主要污染物之一,越来越受到民众的关注,因此,及时准确地预测PM2.5浓度,是当前环境质量研究领域的热点问题之一。本文以长短期记忆网络(Long Short-Term Memory,LSTM)的一种变体,门控循环单元(Gated Recurrent Unit,GRU),作为循环层来建立模型,预测PM2.5浓度。
1 数据分析
1.1 准备数据
在本文中,将使用一个PM2.5浓度时间序列数据集,它是由陕西省延安市市监测站(1928A,(109.4824,36.5767))记录的2016年9月到2018年9月的空气质量监测逐时数据。数据内容包括PM2.5,SO2,NO2,CO,O3和PM10 6种污染物的当前数值以及这些污染物在不同时间长度的滑动平均值,共16 965条数据。
1.2 特征分析
图1是PM2.5与其他5种空气污染物(SO2、NO2、CO、O3和PM10)之间的相关关系散点图,使用最小二乘法对数据进行直线拟合。由图可以看出PM2.5浓度与O3呈负相关,与其他4种污染物均呈正相关。
为了考量各特征之间的相关程度,我们计算皮尔森相关系数,相关系数越接近1或﹣1,相关度越强,相关系数越接近0,相关度越弱,计算公式如下:
其中:Var(X)是X的方差,Var(Y)是Y的方差,Cov(X,Y)是X和Y的协方差。PM2.5浓度与其他所有特征之间的皮尔森相关系数如表1所示,可以看出,PM2.5浓度与其他特征之间都有一定的相关性,其中PM2.5与CO相关性最强,与O3_8_24相关性最弱。
经过上述分析,可以得到PM2.5浓度变化是在多种因素综合影响下的结果,因此,我们使用上述14种特征数据建立未来数小时PM2.5浓度预测模型。
2 基于GRU的PM2.5浓度预测模型
循环神经网络(Recurrent Neural Network,RNN)是一类目前常用来处理序列数据的神经网络,它将过去的数据与未来的数据联系起来,更适用于时间序列分析[1]。但是RNN会遇到一个很大的问题,叫做梯度消失问题(Vanishing Gradient Problem),从理论上来说,RNN在某一时间应该能记住许多时间步之前的信息,但实际上它是不能形成这种长期依赖的[2]。
由Hochreiter和Schmidhuber[3]在1997年设计的LSTM算法就是为解决这个问题而开发的。LSTM在時间序列上有着强大的预测能力,如语音识别[4-5]、自动乐曲谱写[6]和自然语言学习[7]等,且在空气质量研究领域,也有基于LSTM的空气污染物预测的先例[8-9]。它通过增加一个用来保存过去信息的Cell以便后面使用,从而防止较早的信号在处理过程中逐渐消失,并通过精心设计的一种“门”(gate)结构来实现遗忘或记忆功能,一个LSTM单元有这样的3个门,分别是遗忘门(forget gate)、输入门(input gate)和输出门(output gate)[10]。
2.1 门控循环单元
LSTM相比RNN具备了长期记忆功能,可控记忆能力,但是网络结构复杂,拥有多个门,对效率有所影响,为此,Chung等[11]在2014年开发了GRU。GRU是LSTM的一种变体,与LSTM相比,GRU只有两个门且没有细胞状态,简化了LSTM的结构,图2是本文使用的GRU网络模型,它将遗忘门和输入门合成一个单一的更新门(update gate),作用是决定上一时间步隐藏状态中有多少信息传递到当前隐藏状态中。GRU中还有一个重置门(reset gate),计算操作与更新门类似,只是权重矩阵不同,作用是决定上一时间步隐藏状态的多少信息是需要遗忘的。同时GRU还混合了细胞状态和隐藏状态,以及其他一些改动,使得GRU拥有更少的参数,因此,运行的计算代价更低。
在GRU网络模型中,xt,ht分别表示t时刻的GRU网络的输入和输出,其中ht由下列公式迭代计算:
式中,zt,rt分别为更新门和重置门的输出,Whz,Wxz分别为t-1时刻输出和t时刻输入到更新门的权重矩阵,Whr、Wxz分别为t-1时刻输出和t时刻输入到重置门的权重矩阵,这两个门的结果都经过一个sigmoid函数,值域为[0,1];,ht分别为候选隐藏状态和隐藏状态,它们分别控制上一时刻隐藏状态ht-1有多少信息被遗忘和有多少信息被保存,Whh,Wxh分别为t-1时刻输出和t时刻输入到候选隐藏状态的权重矩阵,候选隐藏状态的结果经过一个tanh函数;bz,br和bh表示更新门、重置门和候选隐藏状态的偏置量。
2.2 PM2.5浓度预测模型
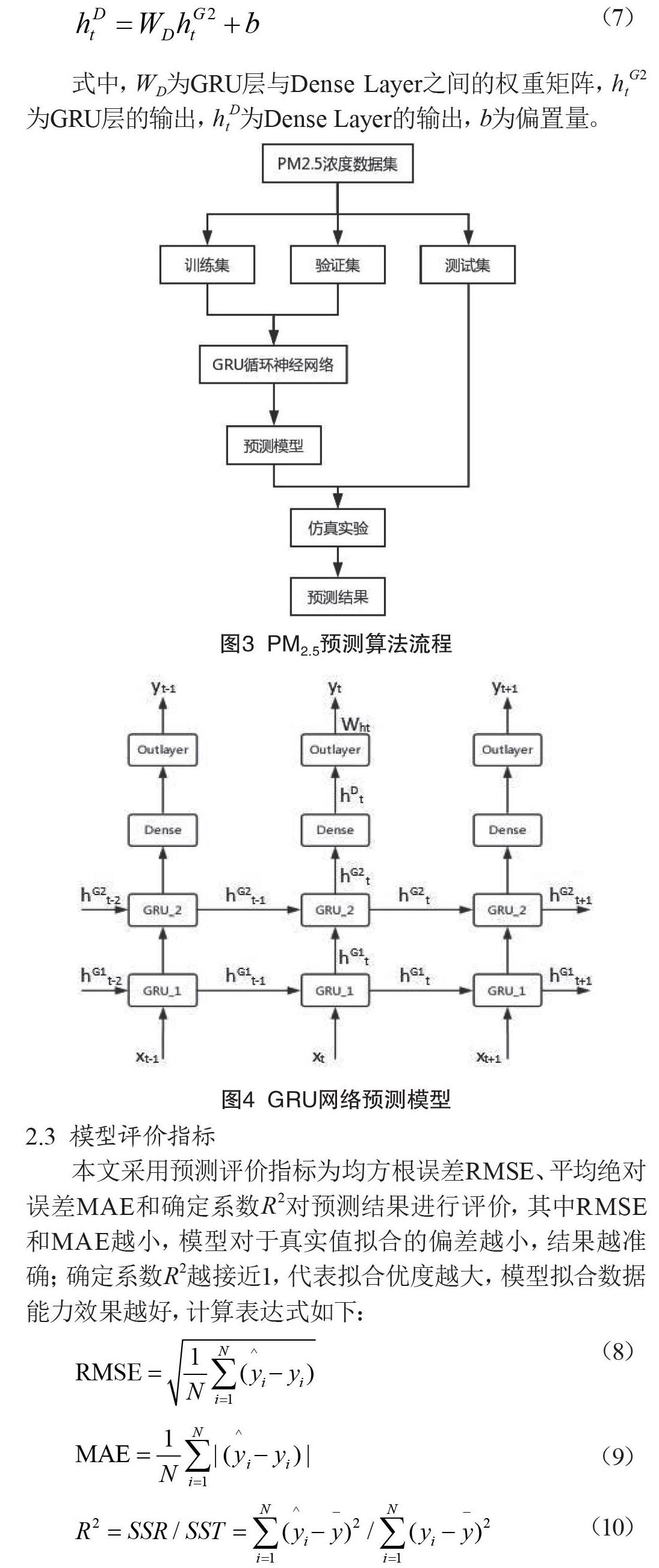
为了实现PM2.5浓度的预测,本文设计了如图3所示的算法流程,首先将PM2.5浓度数据集以7∶2∶1的比例按照时间顺序划分为训练集、验证集和测试集,然后使用训练集和验证集来训练GRU网络预测模型,最后使用测试集对训练得到的模型进行测试。图4展示了本文所建立的GRU网络预测模型,该网络隐藏层包含了两个GRU层和一个Dense Layer层。在t时刻,网络的输入为采集的历史数据xt,输出为未来数小时的PM2.5浓度预测值yt。经过网络隐藏层后可以计算出该时刻隐藏层输出htD。网络的输出为:
式中,activation()为激活函数,通常使用双曲正切函数tanh,Wyh为隐藏层与输出层之间的权重矩阵,b为偏置量。在本文中,采用当前时刻之前的24小时的历史数据作为GRU网络的输入进行模型训练和PM2.5浓度预测,历史数据经过GRU网络循环迭代计算后更新隐藏状态,进而根据历史数据对未来数小时的PM2.5浓度实现预测。
上述GRU网络有两个GRU层,第一个GRU层以历史数据xt为输入,输出隐藏状态htG1,第二个GRU层以上一个GRU层的输出htG1作为输入,输出为htG2。GRU层输出与一个全链接的稠密层(Dense Layer)相连接,Dense Layer的每一个神经元连接到上一层的所有神经元输出,通过Dense Layer,GRU的输出信息与一个矩阵相乘并增加偏置量后实现预测数据的输出,计算过程如下:
式中,WD为GRU层与Dense Layer之间的权重矩阵,htG2为GRU层的输出,htD为Dense Layer的输出,b为偏置量。
2.3 模型评价指标
本文采用预测评价指标为均方根误差RMSE、平均绝对误差MAE和确定系数R2对预测结果进行评价,其中RMSE和MAE越小,模型对于真实值拟合的偏差越小,结果越准确;确定系数R2越接近1,代表拟合优度越大,模型拟合数据能力效果越好,计算表达式如下:
其中,N为观测值和预测值的对比次数,为模型预测值,yi为观测值,为观测值的平均值。
3 仿真实验
3.1 模型训练
根据时间顺序,选择数据集前11 876条数据作为训练集,随后的3 392条数据作为验证集,剩下的1 696条数据作为测试集。由于数据中的每个时间序列位于不同范围,故对每个时间序列分别做标准化,让它们在相似的范围内都取较小的值,具体方法是,将每个时间序列减去其平均值,然后除以其标准差。在模型训练过程中,损失函数使用平均绝对误差(MAE),模型训练过程中采用RMSprop算法进行优化,模型参数选择上包括训练次数(epoch)、学习率(Learning rate)、隐藏层节点数(hidden size)和正则化参数(dropout),本实验是在Python编程环境下实现。
首先固定训练次数epoch=100,进行学习率和隐藏层节点数调整,将两层GRU层中的节点数以2为间隔从14开始逐步增加到40,学习率以0.000 1为间隔从0.000 1开始逐步增加到0.01,通过训练得到最佳隐藏层节点数与学习率组合为(16,32,0.001)。epoch的大小会对模型的预测精度和运行效率造成较大影响,较大的epoch导致运行效率低并可能伴随过拟合现象,较小的epoch会使模型训练不充分出现欠拟合现象。图5为GRU模型训练过程中loss关于epoch的变化散点图,根据loss变化曲线,选择epoch=40。为了增加模型的泛化能力消除过拟合,本文使用循環dropout技术来降低过拟合,该技术将dropout应用于循环层内部而不是外部,系数为dropout=0.1。
3.2 仿真实验与结果分析
为了检验模型的预测能力,将测试集输入模型,图6为模型根据过去24小时历史数据预测未来1小时后PM2.5浓度,图6(a)是测试集上的预测值和观测值比较,图6(b)为预测值与观测值的线性拟合结果,两者相关系数高达0.98,决定系数R2为0.96。从图中可以看出预测值能较好地拟合观测值,但存在实际值低的点位,预测值比较高。
继续使用模型分别对未来1 h、2 h、3 h、4 h、5 h和10 h后PM2.5浓度进行预测,结果如表2所示,可以看到模型的预测能力在短期预测有着较高的准确率,但是随着预测时间长度的增加预测能力持续降低,特别是当预测时长为10 h时,预测的准确率明显下降,说明模型的长期预测能力不足。
4 结语
本文提出的基于GRU深度学习神经网络模型的PM2.5浓度预测模型,通过仿真实验,该模型能够较好地拟合实际PM2.5浓度,可以满足日常预测业务需求,验证了所提方法的有效性,但是随着预测时间的增长,模型的预测能力变差。因此,该模型更适合于短期PM2.5浓度的预测,对于PM2.5浓度的长期预测有待进一步研究。此外,该模型在训练时只采用了延安市市监测站单站点数据,对于模型在其他环境下的泛用性有待讨论。
[参考文献]
[1]TSENG V S,WU C W,FOURNIER-VIGER P,et al.Efficient algorithms for mining top-k high utility itemsets[J].IEEE Transactions on Knowledge and Data Engineering,2016(1):54-67.
[2]BENGIO Y,SIMARD P,FRASCONI P.Learning long term dependencies with gradient descent is difficult[J].IEEE Transactions on Neural Networks,1994(2):157-166.
[3]HOCHEREITER S,SCHMIDHUBER J.Long short-term memory [J].Neural Computation,1997(8):1735-1780.
[4]DAHL G E,ACERO A.Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition[J].IEEE Transactions on Audio Speech & Language Processing,2011(1):30-42.
[5]HINTON G,DENG L,YU D,et al.Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups[J].IEEE Signal Processing Magazine,2012(6):82-97.
[6]ECK D,SCHMIDHUBER J.Learning the long-term structure of the blues[J].Lecture Notes in Computer Science,2002(2415):284-289.
[7]SUTSKEVER I,VINYALS O,LE Q V.Sequence to sequence learning with neural networks[J].Computer Science,2014(4):3104-3112.
[8]范竣翔,李琦,朱亚杰,等.基于RNN的空气污染时空预报模型研究[J].测绘科学,2017(7):76-83,120.
[9]韩伟,吴艳兰,任福.基于全连接和LSTM神经网络的空气污染物预测[J].地理信息世界,2018(3):34-40.
[10]GRAVES A.Long short-term memory[M].Heidelberg:Supervised Sequence Labelling with Recurrent Neural Networks,2012.
[11]CHUNG J,GULCEHRE C,CHO K,et al.Empirical evaluation of gated recurrent neural networks on sequence modeling[C].Kuching:Conference on Neural Information Processing Systems,2014.
猜你喜欢
环球人物(2022年4期)2022-02-22
今日农业(2021年19期)2022-01-12
环境保护与循环经济(2021年7期)2021-11-02
国外核新闻(2020年8期)2020-03-14
电子制作(2019年19期)2019-11-23
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
小学阅读指南·高年级版(2014年2期)2014-05-27
