
引入兴趣点的地理加权人口空间分布模型研究
——以天津市为例
2019-05-17 08:18李泽宇董春
遥感信息 2019年2期
李泽宇,董春
(1.辽宁工程技术大学,辽宁 阜新 123000;2.中国测绘科学研究院,北京 100036)
0 引言
探究城市内部人口空间差异是当前人口空间化研究的重要方向。现代社会,迅猛发展的测绘技术为空间化研究提供丰富的数据源。目前空间化模型众多,常用的空间化模型包括空间插值估计、多元回归[1]、核密度估计、多因素融合[2]、机器学习[3]等。建模要素从土地利用[4]、地形地貌[5]、河流水系、交通路网[6]、夜间灯光遥感[7]等传统数据,到LIDAR点云[8]、OSM[9]、手机信号[10]等数据。
社会经济和自然地理是影响人口空间分布的两大因素。兴趣点(point of interest,POI)是社会经济数据的一种,具有人口指示作用。目前,城市开展空间化研究多采用多因素融合方法,该方法能综合多方面要素,但以往研究缺少对城市内人口分布的区分。是否可以利用兴趣点结合城镇建设用地、农村居民点,对城市内部人口细化做出新的探索,值得研究。本文以天津市15区作为研究区(不包括滨海新区),引入电子地图兴趣点位数据,结合土地利用数据,对研究区采用分区建模。以电子地图兴趣点、城市基础设施作为分区标准,构建街道级别人口空间回归模型,生成人口1 km数据集,实现城市内部精细人口空间分布。
1 研究区概况与数据处理
1.1 研究区概况
天津市由中心城区、环城四区和远郊区县和滨海新区组成。中心城区包括和平区、河西区、河东区、南开区、红桥区、河北区,统称为市内六区。环城四区包括东丽区、西青区、津南区、北辰区。远郊区县包括宝坻区、武清区、蓟县、宁河区、静海区。全市人口分布不均匀,中心城区人口密集,经济发展迅速,地铁、公路等交通设施,超市、学校、医疗等服务机构完善,远郊区县人口稀少,基础设施薄弱。
1.2 数据来源与预处理
1)数据来源。
(1)电子地图兴趣点、城市公共基础线状设施。兴趣点包括学校、超市、地铁站、医院点位数据等,公共基础线状设施包括城市快速路、地铁线、水系、省道、乡镇街道等,空间分布如图1所示。
(2)土地利用数据,本文采用城镇建设用地和农村居民点作为人口影响因素。
(3)ASTER-GDEM,来源于地理空间数据云,分辨率为30 m,经过拼接后裁剪出研究范围内的栅格数据。
(4)乡镇街道行政边界,来自中国科学院资源环境科学数据中心,字段属性包含行政区划代码、行政区划名称等。
(5)人口统计数据,2010年第六次人口普查数据。
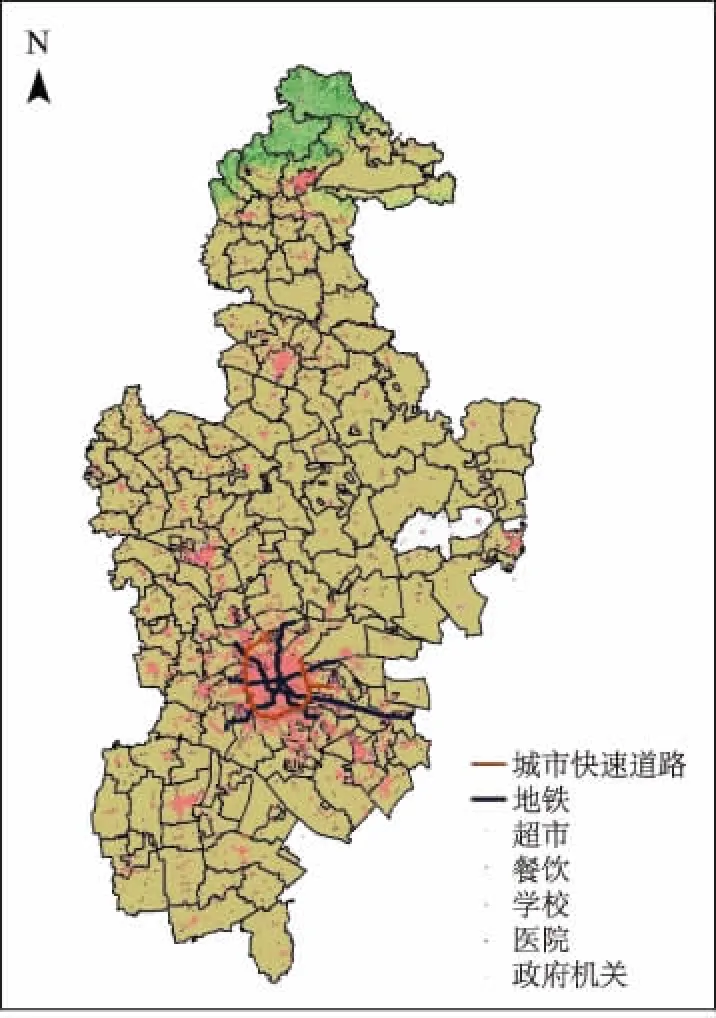
图1 天津市兴趣点空间分布
2)预处理。
(1)数据类型有人口统计数据、栅格数据和矢量数据。矢量数据和栅格数据统一转换投影为CGCS2000_Albers,人口统计数据与乡镇街道区划名称进行关联,录入人口数量,并擦除水系面状要素。
(2)计算街道几何中心与距离最近的地铁出入口的欧式距离作为地铁的要素属性。
(3)提取与人日常生活息息相关的兴趣点,例如超市、医院、学校等。
1.3 技术路线
在对城市内部划分分区后,引入土地利用数据(城市建设用地、农村居民点)、省道、乡镇街道、兴趣点,进行多元逐步回归,对存在空间异质性的分区采用地理加权回归(geographically weighted regression,GWR)、混合地理加权回归(mixed geographically weighted regression,MGWR)方法,建立各分区的人口空间数据集。技术路线如图2所示。

图2 技术路线
2 研究方法
2.1 逐步回归
多元逐步回归的思想是将自变量逐个引入模型,每引入一个自变量后都要进行F检验,并对已经选入的自变量逐个进行t检验,当原来引入的自变量由于后面自变量的引入变得不再显著时,则将其删除。确保每次引入新变量之前回归方程中只包含显著性变量。
2.2 地理加权回归
地理加权回归模型是在普通线性回归模型的基础上,在回归参数中加入因变量的空间位置。地理加权自变量的回归参数是随着地理位置而变化,建立的是局部回归。在全局模型中加入地理位置的权重函数,使得模型参数在回归过程中不断变化。形式如式(1)所示:
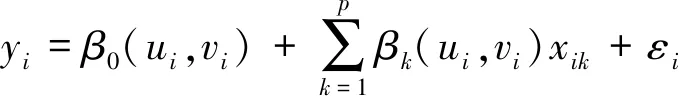
(1)
式中:(ui,vi)是第i个采样点的坐标;β0(ui,vi)是第i个采样点统计回归的常数项;βk(ui,vi)是第i个采样点上的第k个回归系数;xik为第i个采样点上第k个变量;p为某一采样点上参与回归的变量个数;
εi~N(0,σ2),Cov(εi,εj)=0(i≠j)。
2.3 混合地理加权回归
OLS(ordinary least square,OLS)模型假设回归参数不随地理空间位置变化,而GWR模型假定所有回归参数都随地理空间变化。但在实际应用中,并不是所有参数都是随着地理位置发生变化,有些参数在空间上变化,有些参数在空间上是不变的,或者变化非常小,可以忽略不计。进一步改进模型为混合地理加权,混合地理加权中部分参数随着地理位置发生变化,成为变参数,其他不随空间位置发生变化的参数称为常参数。
(i=1,2,……,n)
(2)
3 实例验证
3.1 建模区划分及相关性分析
分区建模是提高人口空间模拟精度有效方法之一,其目的是将建模因素具有相似特征区域归并为同一分区,以便于统一建模,建模因素差异大的区域划分为不同分区,以凸显差异性。本文以街道为最小研究单元,依据土地利用空间分布、兴趣点密度疏密、地铁线、城市快速路进行分区,将天津15区划分为3个分区。第一类分区为中心城市区和环城四区中靠近中心城区的街道。该类分区土地利用类型无农村居民点,全部是城镇建设用地,兴趣点密集,商业发达,有地铁和快速道路。第二类分区为环城四区和远郊区县的中心城区的街道。该类分区有少量的农村居民点,以城镇建设用地为主,兴趣点比较密集,高于周边街道的集聚程度。第三类分区为其余街道。以农村居民点为主,农村居民点、兴趣点分散在各个街道,部分街道有少量城镇建设用地。
本文选取与人口密切相关的兴趣点要素:医院、学校、超市、地铁站;线状交通设施:省道、乡镇街道;承载人口的土地类型:城镇建设用地、农村居民点;地理要素:高程、坡度。利用SPSS计算各分区相关系数如表1所示。

表1 相关系数
兴趣点是城市重要的人口指示因子,尤其是当今社会经济迅猛发展,交通路网不断完善,兴趣点点位、类型的时空分布的数量和密集程度分布极不均衡。以超市为例,超市的功能是满足百姓日常生活需求,具有随人口分布的性质。超市通常环居住小区开设,其规模一定程度能够反映人口的聚居程度和数量。人口与超市分布形成彼此吸引的关系。
3.2 基于城市公共基础设施的多元逐步回归分析
基于上述对各个分区进行相关分析后,避免建模要素彼此冗余,假设同一分区内人口成均匀分布,以高程平均值、坡度平均值、城镇建设用地面积、农村居民点面积、各类兴趣点个数为自变量,街道人口常住数值为因变量,建立多元逐步回归模型,各类建模因素结果及分析如表2所示。
对多元逐步回归结果进行统计检验,结果如表3所示。调整R2代表模型的拟合程度,第一分区拟合度为0.68,第二分区、第三分区拟合程度较高,均为0.83。联合F统计量和Wald统计量要结合Koenker(BP)来检验模型的显著性。当Koenker(BP)不具显著性时,联合F统计量才可信。当Koenker(BP)统计量具有显著性时,应参考Wald统计量确定模型显著性。第一分区和第二分区在95%置信度下,联合F统计量p值(概率)小于0.05,模型具有统计显著性。第三分区Koenker(BP)统计量具有显著性,对于95%置信度下,Wald统计量p值(概率)小于0.05,模型具有统计显著性。此外,第三分区模型残差空间分布不呈现正态分布,存在空间非平稳态。
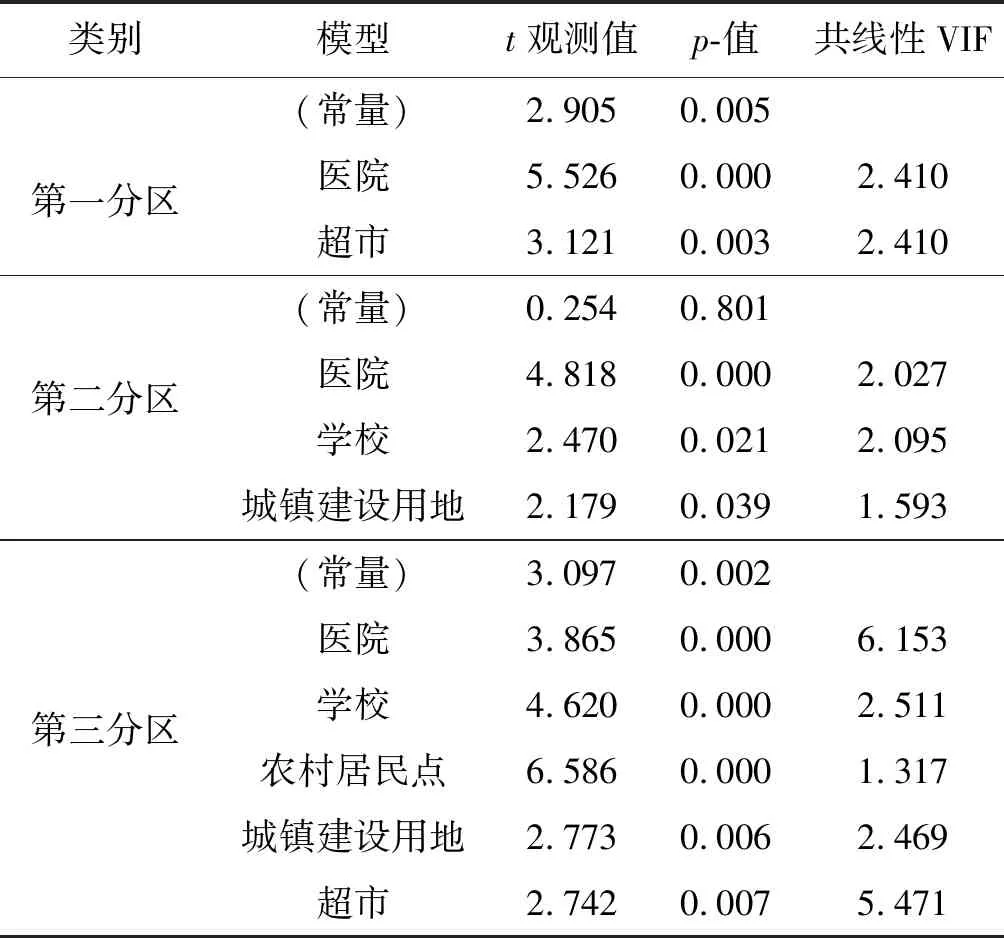
表2 多元逐步回归
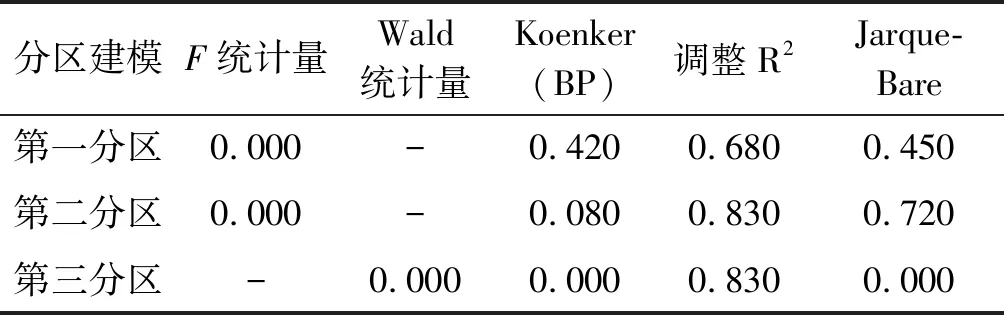
表3 多元逐步回归统计检验
3.3 地理加权回归
由于第三分区存在空间异质性,对第三分区进行地理加权建模,以医院、学校、超市个数,城镇建设用地、农村居民点面积为自变量,以街道人口数量为因变量构建回归模型。利用GWR4软件,模型参数选用自适应的二次平方自适应空间核函数(bi-square)进行建模,选择黄金分割搜索程序进行带宽选取,以赤池信息量准则AIC(akaike information criterion)作为信息评价准则,模型参数估计及参数检验如表4所示。
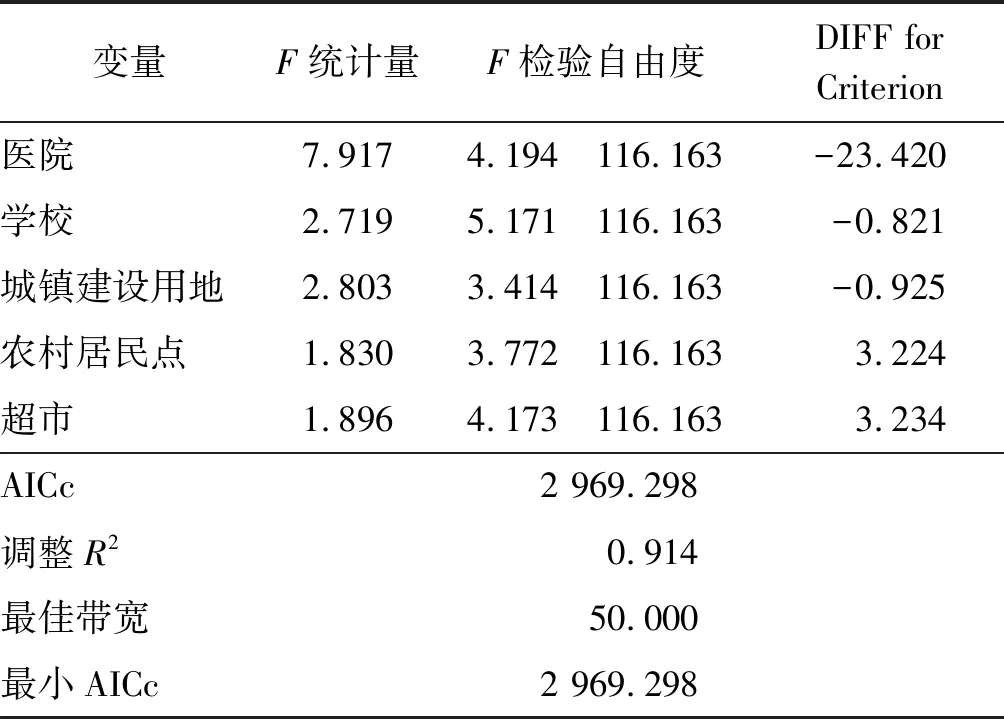
表4 地理加权模型参数估计及参数检验
3.4 混合地理加权回归
在对第三分区进行地理加权回归时,根据DIFF for Criterion大于零,说明农村居民点和超市不具备空间非平稳性,因此对该2个因素固定地理空间位置,采用混合地理加权建模,模型参数估计及参数检验如表5所示。对第一分区、第二分区的多元逐步回归结果和第三分区混合地理加权结果与1 km格网套合,生成天津市15区1 km人口格网数据集,如图3所示。
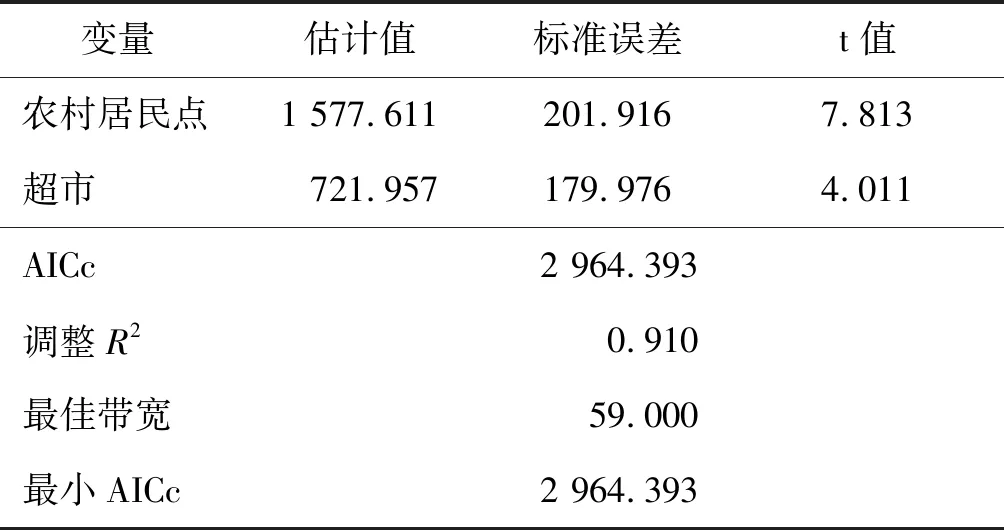
表5 混合地理加权模型参数估计及参数检验
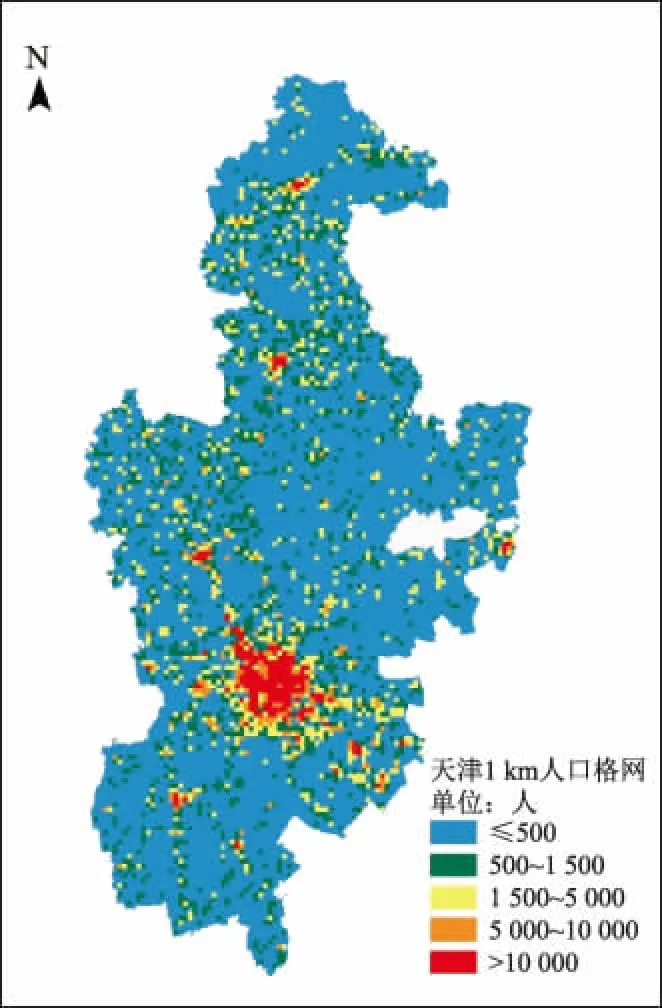
图3 天津市1 km人口格网
4 精度评价及精度影响因素
4.1 精度评价
从表6误差分段统计表来看,整体上误差分布较为合理,能够比较确切地反映实际情况。不可避免,由多元逐步回归结合混合地理加权回归方法模拟的人口空间分布数据与实有数据仍然存在误差,其中街道低估数量从整体上多于高估街道数量。低估区主要分布于郊区,例如武清农场、黄庄农场、红旗农场等,兴趣点数量较少或没有,土地利用种类单一,从客观上增加了模型低估的可能性。高估街道主要位于环城四区和远郊区县中的经济开发区、农业园区等,例如津南国家农业园区、东丽开发区、静海经济开发区等。该地区有一定数量的兴趣点和用于厂房建筑的城镇建设用地,但常住人较少,从客观上增加了模型高估的可能性。
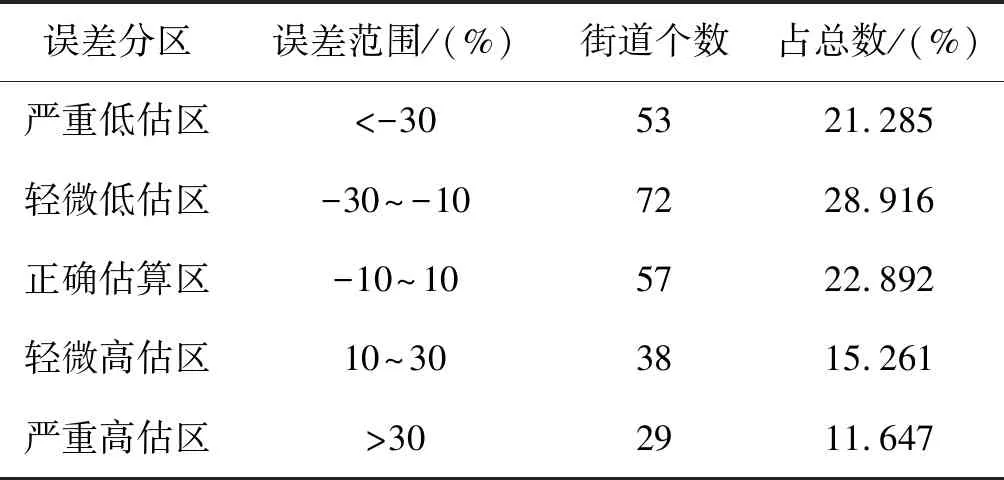
表6 误差范围分段统计表
4.2 模型精度影响因素
为分析模拟人口与实际人口差异的原因,进一步观察发现,引起模型估算有误的原因大致有以下3个方面:①中心城区土地利用类型单一。天津市内六区范围内土地利用类型全部为城镇建设用地,难以区分住宅用地类型和商厦等商业用地类型。这使得将一部分人口分配到商业用地上,这也是造成第一分区模型误差的原因。②兴趣点采集范围不全面。兴趣点是电子地图兴起的衍生产品,为探究人口时空特征提供全新视角。目前,各个地图公司兴趣点采集的详细程度不同,且普遍存在中心城区覆盖度高、郊区覆盖度低的现象。郊区采集的兴趣点偏少,导致郊区存在大范围人口低估区域。③人口街道数据与其他数据时相不匹配。本实验除了统计人口为2010年数据,其余数据时相均是2015年。2种时相的数据存在时间不一致的情况,5年之间人口会出现较大变化,从而造成了模型的估算误差。
5 结束语
本文在人口特征分区的基础上,以兴趣点、城市基础设施作为分区标准对天津市15区进行分区建模,对3个分区进行多元逐步回归,并对存在空间异质性的分区采用地理加权回归和混合地理加权回归方式进行人口空间化建模,生成1 km人口格网数据集。对结果进行模型精度比较和误差分析,研究表明:
①兴趣点能较为有效地展现人口空间分布现状。兴趣点与城市活动具有极强相关性,中心城区是兴趣点聚集程度最密集的区域,郊区兴趣点较为稀疏。实验表明,中心城区呈现高估人口趋势,郊区呈现人口低估趋势,说明中心城区范围内的兴趣点类型丰富,使得住宅区和商业区难以通过兴趣点疏密来区分,这是造成人口高估误差的原因。对于郊区而言,兴趣点采集覆盖程度不够,有些地区兴趣点采集不全面,与实际不符,这是造成郊区人口低估的原因。
②对城市内部进行特征分区建模能够提高模型精度,使人口更加符合现实。加入地理位置的地理加权方法能够充分解释地理空间位置变化对人口的影响。混合地理加权回归模型能够进一步探测出具有空间平稳性和空间非平稳性影响因素,相对于多元逐步回归模型方法精度有进一步的提升。
在后续的研究中,还可以在以下几个方面探索:利用公安机关登记的实有人口代替普查人口,更具准确性;尝试对比多个平台的兴趣点对人口模拟的精度影响;城市中心城区内用住宅小区替代城镇建设用地作相关研究。
猜你喜欢
大众科学(2022年5期)2022-05-18
环球时报(2022-03-29)2022-03-29
智慧少年·故事叮当(2021年1期)2021-01-16
自然资源情报(2018年4期)2018-12-28
知识经济·中国直销(2018年7期)2018-07-27
小学生必读(低年级版)(2017年4期)2017-09-04
中国工程咨询(2017年8期)2017-01-31
琴童(2016年7期)2016-05-14
中国工程咨询(2016年2期)2016-02-14
中国工程咨询(2016年3期)2016-02-13
