
采用BI-LSTM-CRF模型的数值信息抽取
2019-05-16 08:32:36王竣平蔡东风
计算机应用与软件 2019年5期
王竣平 白 宇 蔡东风
(沈阳航空航天大学人机智能研究中心 辽宁 沈阳 110136)(辽宁省知识工程与人机交互工程技术研究中心 辽宁 沈阳 110136)
0 引 言
数值信息是文本中的一种重要信息,也是数据中直观的表达方式之一。而且数值信息的抽取对信息检索、数值类问答,知识库或事实库构建、文本可视化分析等应用具有重要的现实意义。
数值在非结构化文本中非常普遍,常见的数值包括时间、货币、数量词、电话号码等,但仅仅单纯对数值的抽取意义不大,因为数值只有存在于相应的语言环境中,和相关的主体,单位等元素一起存在,才能更全面地表达出其本身所携带的信息。一个数值信息应该包括主体、属性、属性值等基本元素,考虑到数值信息表述中的相对性特征,数值信息还应该包括比较词、趋势词、比较对象、时间、地点等元素。
当前的数值信息的抽取以模板的方式为主,且抽取的格式无法完全表达数值信息的含义。为了更加全面地描述数值信息且克服模板抽取的局限性,本文提出了一种数值信息的存储格式和抽取方法。输入例子和输出结果分别如表1和表2所示,数值信息的抽取流程图如图1所示。

表1 输入句子
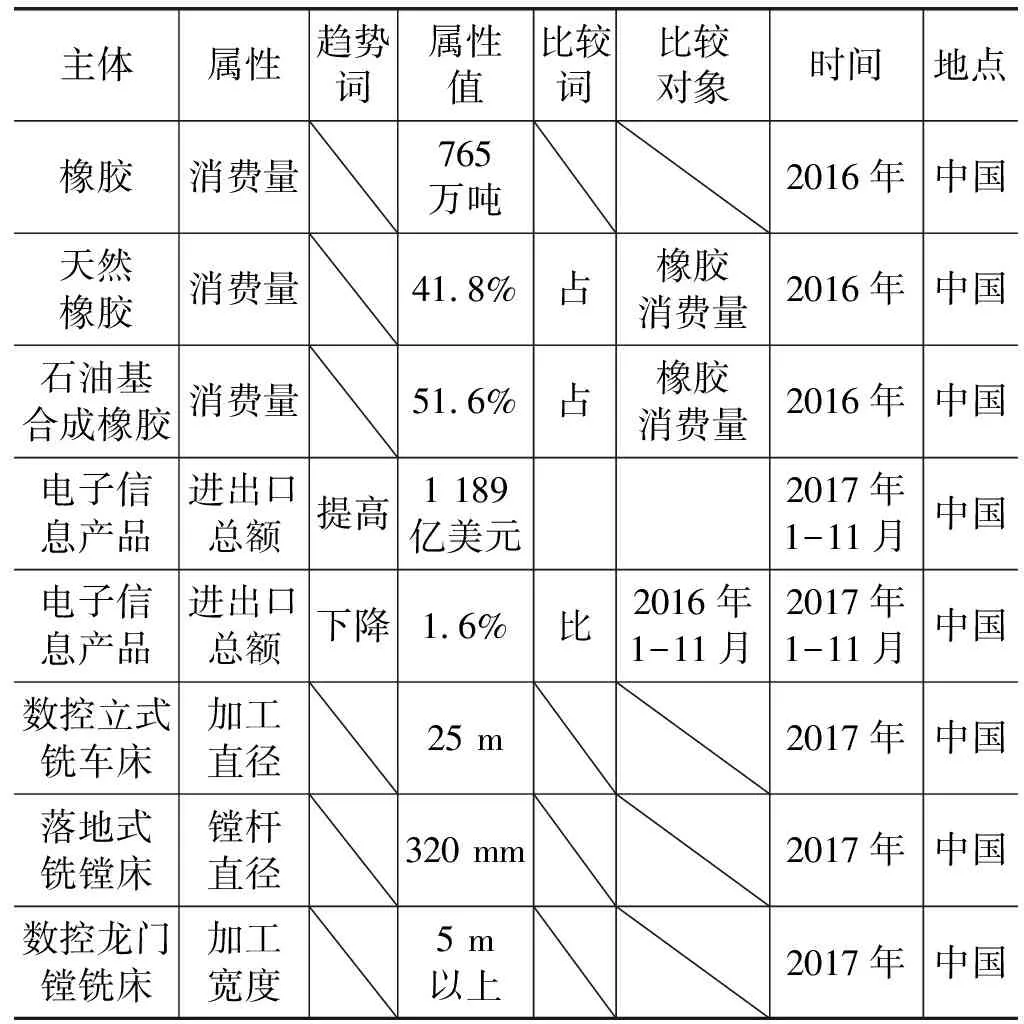
表2 部分输出结果

图1 数值信息抽取流程图
1 相关研究
关于信息抽取方面目前主要有4种方法:基于规则、基于统计机器学习、基于规则统计相结合以及基于深度学习的方法。基于规则的方法有:封春生等[3]人利用关键字来定义模式匹配原则;朱文琰等[4]提出一种基于正则表达式状态转换的算法,来学习复杂正则表达式来抽取网页中的信息;仇培元等[5]提出使用词性序列来制定抽取模式。这些方法的移植性较差。基于统计机器学习方法有:使用条件随机场[6-8],利用序列标注的思想对命名实体来进行抽取。文献[9-10]采用了基于规则和统计相结合的方法进行属性的抽取。通常来说结合的方式有两种,先使用规则后使用统计和先使用统计后使用规则两种方法,具体选择哪种方法,需要根据具体的问题来选择方法。基于深度学习的方法:这类方法通常不再依赖于人工特征或领域知识,实现了端到端的抽取模式,减少了人工特征提取所需的代价。文献[11]提出了BI-LSTM-CRF模型,通过序列标注进行命名实体识别均达到了最好的效果。
在数值信息抽取方面,大部分相关工作都是采用基于模式匹配的方式。对数值信息进行抽取,首先要对数值进行识别。石海峰等[12]利用数字+单位的方法来对数值信息进行识别;文献[13]对数词和量词进行分类,分析数词和量词的组合方式并对组合方式进行分类,形成知识库。利用知识库对数量名短语进行识别(包括数值)。肖洪等[14]采用了基于规则的方法,从海量年鉴文本中抽取宏观数值信息,为了使数值信息含义更加明确,使用了由六元组结构表示数值信息的方法,但没有对数值信息的表达模式做具体的分析,只定义了3种抽取模式。温有奎等[15]利用人工抽取数值的经验,开发了数值型知识元抽取软件,用于抽取《年鉴》中的数值信息。文献[16]开发了一个可以从大量的日文文档中半自动抽取数值信息的一个系统,并能够根据抽取到的数值信息自绘制多种图形。文献[17]将数值信息根据时间将数值信息分为了绝对数值信息和相对数值信息,采用了一种数值信息抽取模板辅以条件随机场的方法。但文献[17]的相对数值信息只做到了在时间上的比对,并且对含有多数值的句子的抽取效果不佳。
本文针对数值信息抽取过程中比较信息处理比较单一和多数值抽取效果不佳的问题,并结合数值信息的特点,提出了一种抽取框架和抽取方法。比较关系的处理上,不仅仅局限于时间上的比较,而且对于含有多数值、多同种类型元素的句子,数值信息抽取效果也得到了改善。相比于单纯用模式匹配来对整个数值信息抽取的方法,本文方法有效改善了大量人工干预来制定抽取模式和模式冲突的问题。
2 数值信息元素识别
2.1 属性值识别
属性值是判断数值信息是否被抽取的关键所在,也是判断一个数值信息是否存在的关键。所以本文先对属性值进行抽取,并将属性值作为抽取的触发词。但在非结构化的文本中,属性值存在大量省略表达的情况。而且无论是省略还是非省略的情况,属性值规律性比较强,而模板相比于其他方法,更适合抽取这种表达规律性较强的属性值。故本文采用模板的方式对属性值进行识别。
2.1.1属性值抽取模板
通过观察文本,趋势词和单位会因并列表达而存在省略的情况,故本文在定义属性值抽取模板时,同时将趋势词、单位和量词进行抽取。抽取数字的趋势词和量词,不仅对数字的意义表示的更为全面,同时也能表示出数字之间的逻辑关系。
本文定义的属性值抽取模板如表3所示。其中:“Qu”代表趋势词;“Num”代表数字;“Dan”用来代表单位;“Li”代表量词。并按表格的顺序由上至下进行匹配。
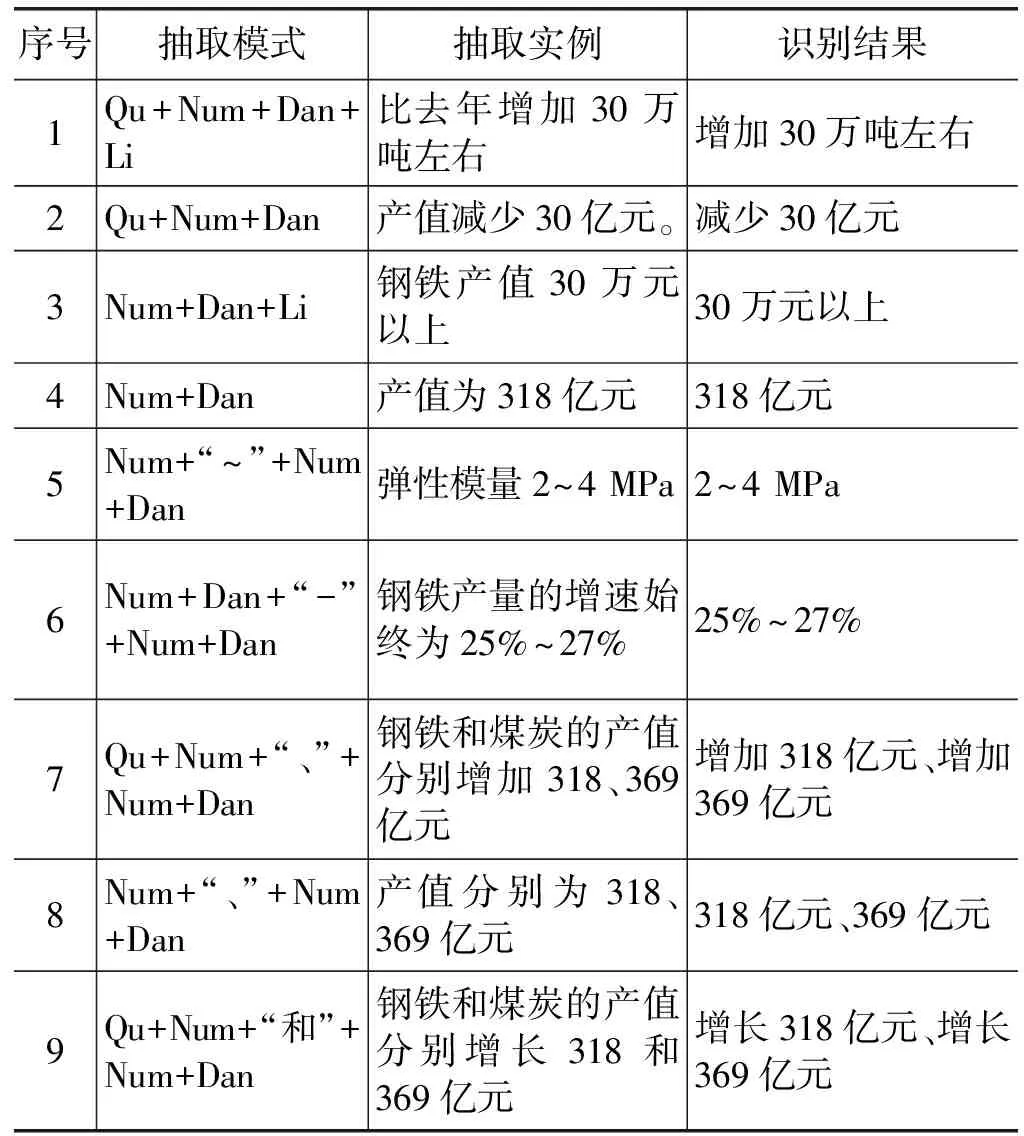
表3 属性值的抽取模式
2.1.2单位、量词和趋势词知识库的建立
本文通过建立知识词库结合模板来对属性值进行抽取。单位、量词、趋势词相对有限,所以通过建立知识库来进行抽取属性值进行抽取。
1) 单位。从知网和外部知识中获取单位的个数为673个。将数值单位的类型分成14大类分别为:长度、质量、体积、面积、温度、密度、压强、功率、力、速度、电、光照度、组合单位、其他。单位词表如表4所示。
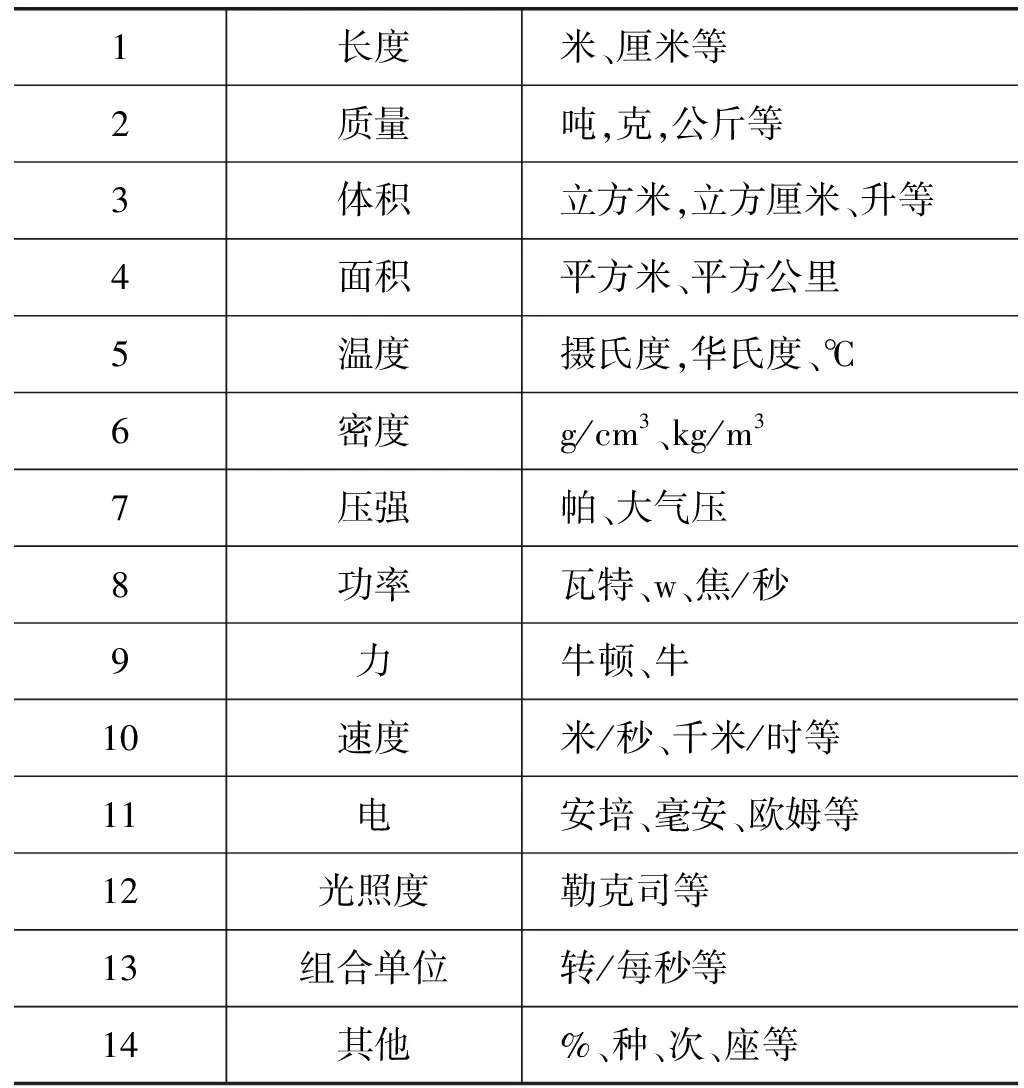
表4 单位表
2) 趋势词和量词。趋势词表达了属性值所在数值信息之间的逻辑关系,是进行推理的重要标志。本文在文献[17]收集的趋势词的基础上进行补充,趋势词表如表5所示。
收集到的方向量词为:及以上、以上、左右。
2.2 主体、属性、比较词识别
数值信息元素识别的目的是为了标注出句子中各词汇是否在数值信息中,可以看作序列标注问题,目前常见的用于序列标注的模型有CRF模型、BI-LSTM-CRF模型。BI-LSTM-CRF模型具有对句子整体信息的长距离依赖、自动抽象特征等以及利用CEF假设标签之间存在关系而非独立性的特点[11,20],而且不需要人工精心构建特征,编写特征模板等优势,因此被越来越多研究者使用。本研究选择BI-LSTM-CRF模型来完成数值信息的主体、属性、比较词关键元素进行识别。
2.2.1模型建立
BI-LSTM-CRF模型是将BI-LSTM网络和 CRF模型结合起来,即在BI-LSTM网络的隐藏层后加一层CRF线性层,BI-LSTM层可以有效地使用之前或者之后的输入特征[11]。通过CRF层可以使用句子级别的之前或之后的标签信息。BI-LSTM-CRF模型结构如图2所示。
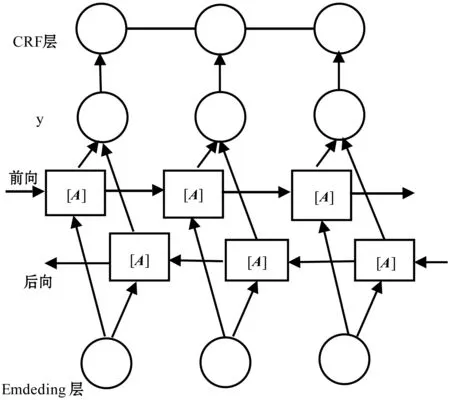
图2 BI-LSTM-CRF模型结构
对于句子序列X=(x1,x2,…,xn),分别进入两个LSTM,将LSTM正序输出和反序输出的进行拼接,通过引入状态转移矩阵[A],然后设定矩阵P为双层LSTM网络的输出。[A]i,j表示时序上从第i个状态转移到第j个状态的概率;[P]i,j表示输入观察序列中第i个词为第j个标注的概率。则观察序列[X]对应的标注序列y=(y1,y2,…,yn)的预测输出为:
动态规划算法可以有效地计算状态转移矩阵和优化标签序列,具体算法请参考文献[18]。
2.2.2训练方法
本文将主体、属性、比较词标注体系如表6所示。图3为数值信息元素标注示意图,其中,文字部分为文本经中文分词后的词序列,各词上方代码为输入的数值信息元素类型标记代码。
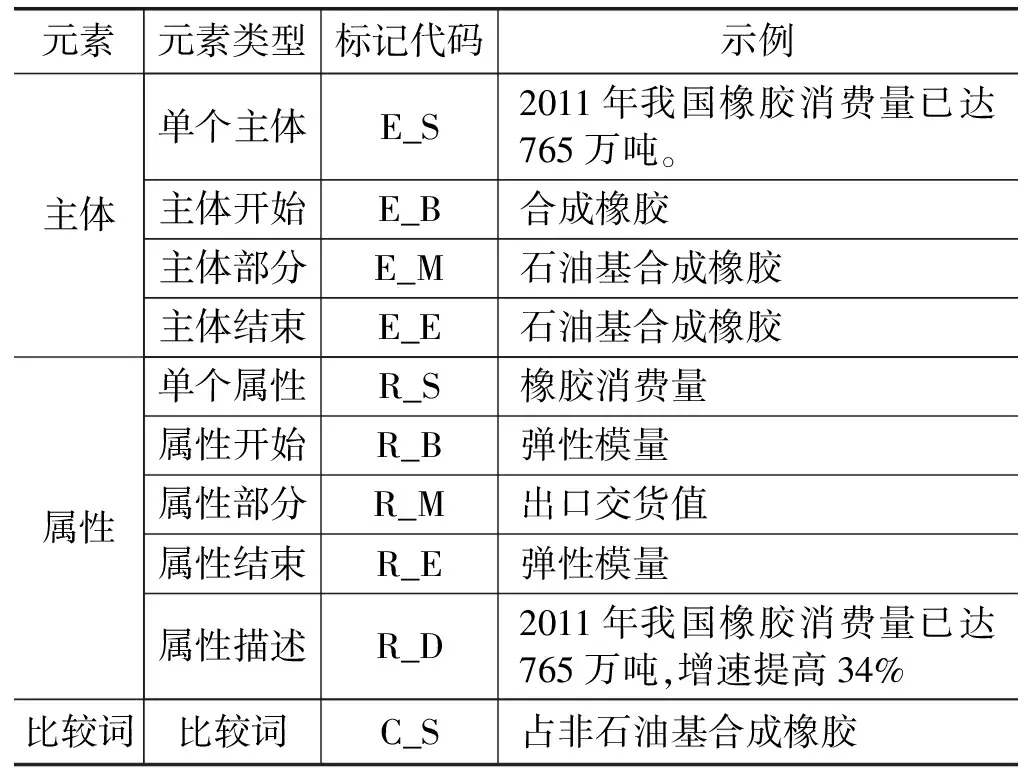
表6 主体、属性、比较词标注体系
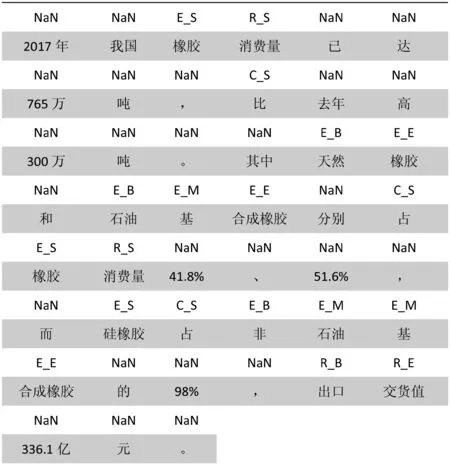
图3 标注示意图(非数值信息元素标记代码为“NaN”)
分词后的词序列首先需要分布式向量化,这里采用的是文献[19]提出的word2vec方法。基于本文构建的标注流程图如图4所示。
我们将整个训练数据分批次,并每次处理一批包含一个由批量大小参数确定的句子数量的句子列表,本文选择的批大小为50。对于每一批次,我们分别运行BI-LSTM-CRF模型。首先运行双向LSTM-CRF模型正向传播,通过正向传播BI-LSTM网络的前向状态和后向状态,得到所有词对应所有标签的概率。然后,运行CRF层来计算网络输出和状态转移矩阵边缘概率的梯度。之后,将错误从输出反向传播到输入,其中包括向前和向后状态的反向传播。进而可以更新相应的状态转移矩阵[A],标签标注概率矩阵[P][11],并使用了dropout方法来减少过拟合。
将标注出来的语料进行整理,通过如下标签来对句子中的数值信息所属元素进行标记:主体:、属性:、比较词:、比较对象:、时间:、地点:、属性值:
2.3 时间、地点元素识别
数值信息地点元素的识别则使用了公开的工具,地名和机构名的识别采用了哈工大的LTP工具,时间元素的识别则采用了正则表达式匹配的方法。并根据实际情况,利用正则表达式和知识库对地点和时间元素进行补充。比如地点中表达:中、西部地区,需要抽取出中部地区和西部地区。再比如时间上的省略表达:2016年3月、4月,需要抽取出2016年3月、2016年4月。
2.4 比较对象识别
通过含有数值的文本进行分析,比较对象均来自于除比较词外的其他元素,为了不增加标注的标签量,识别出比较词之后,采用如下规则从已识别的数值信息元素中将比较对象识别出来。
(1) 将比较词和数值之间的数值信息元素标记为比较对象。
(2) 将介词后面到分句结束之间的数值信息元素标记为比较对象。
(3) 若上面两种情况都不满足且还存在比较词,上一个分句的主体和属性值补充到该分句作为比较对象。
(4) 对于不同的元素则组合为一个比较对象,相同则认为多个比较对象。
例如:经过标注后处理成、。橡胶和消费量在比较词和数字之间且一个是主体一个是属性,元素类型不同,经过规则(1)和规则(4)后,我们将比较对象识别出并标记为:、。
3 数值信息元素关系识别
非结构化文本含有多个属性值时,频繁出现的省略描述方式造成不同数值信息混杂,不利于计算机自动区分。在训练数据集有限,特征明显且确定的情况下,本文采用基于特征的方式进行识别,去判断属性值和识别出的其他元素之间是否有语义关系。本文所选择的特征如表7所示。

表7 特征列表
在进行识别之前,先将识别好的句子按逗号进行分割,以含有属性值的分句为单位,对分句中的元素进行识别。如果分句中缺少元组中需要的数值信息元素,即有省略的情况,则将前面分句中最近出现的相同数值信息元素按表7中的特征进行判别。若整个句子所有分句无相应元素,则认为数值信息不含有该元素。
从表7中,由上到下对特征进行匹配只要有一条符合的结果为是,则我们就认为该成份和该属性值有关系。例如经过识别后得到这样的一个标注的句子:
已达,
比如要寻找属性值41.8%的其他数值信息元素,在该分句中含有两个主体,其中天然橡胶出现次序和41.8%在该分句中同类型属性值均为第一次出现。根据特征4,认为41.8%的主体为天然橡胶。而上一个分句中有属性且只有一个,即消费量,所以我们认为消费量是41.8%的属性。对于比较对象、比较词、时间、地点全部都唯一,根据特征3,判断属性值41.8%和三者有关系。
4 实 验
4.1 实验环境
本文从工信部的网站上爬取了工信数据,经过筛选出含有属性值的句子共4 725句。经人工标注后为实验语料,并按4∶1的比例随机划分出训练集和测试集,语料样例如表1所示。
为对比本文方法与模式比配方法的效果,本文参照文献[19]已有成果构建了基于模式匹配的数值数值信息抽取方法。每一个模式对应一个数值信息数值信息。并将本文标注出来的主体,比较词作为知识对该方法进行补充。
本文采用正确率(P),召回率(R),和F-值(F)来对方法的性能进行评价。三个指标的计算公式如下:
(1)
(2)
(3)
4.2 参数设定
本文选用了712 M搜狗全网新闻语料训练词向量,采用的分词工具为清华大学的THULAC。采用了tensorflow深度学习框架。将分好词的语料以词向量作为神经网络的输入。参考文献[21-22]的经验值,设置的参数为:词向量200维、学习率0.01、迭代次数300、批大小50、Dropout取0.5。
4.3 结果与分析
为判定每一步的结果,将属性值识别结果,以及主体、属性、比较词的识别的抽取结果,分别如表8、表9所示。

表8 属性值识别结果
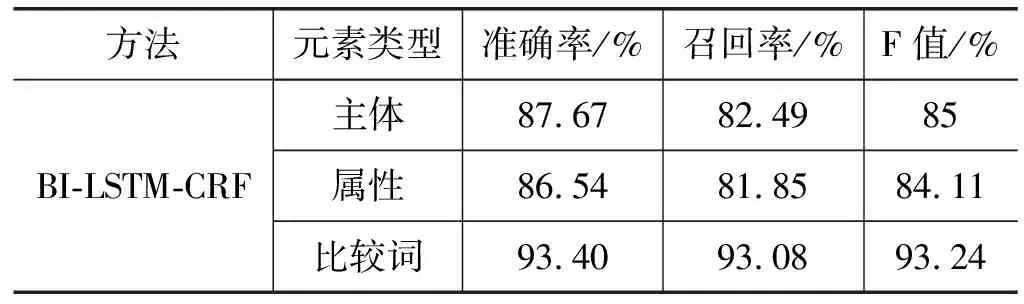
表9 数值信息元素的识别结果
为评价对数值信息抽取的效果,在对属性值标注和BI-LSTM-CRF模型的识别的主体、属性、比较词基础上,分别进行数值信息抽取实验,抽取得到的数值信息中的成员全部正确则认为数值信息抽取正确。与模式匹配法比较的实验结果如表10所示。
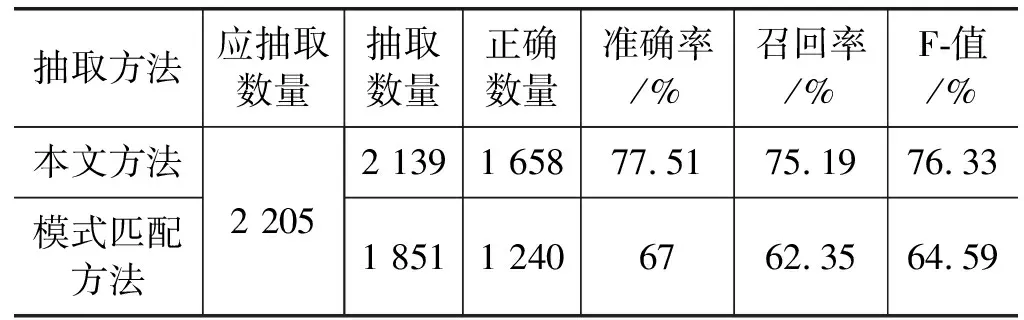
表10 数值信息抽取结果
对于属性值识别部分,准确率、召回率和F-值均到达95%以上,这是因为属性值在非结构化文本中的表达比较固定且规律明显,而模板的方法的优势在于对固定规律的表示,因而可以用较少的代价实现很好的效果。然而一些不常见的组合单位和包含数字的主体则对属性值的识别造成了干扰,比如:分钟、月户等。
从数值信息中的主体、属性、比较词的元素识别结果可以看出,BI-LSTM-CRF模型在不使用人工设计特征和编写特征模板的前提下,对三种元素的识别的F-均达到了84%以上。对于主体和属性来说,文本中有很多较长的表达。BI-LSTM-CRF模型能够自动从文本序列中抽象出文本特征进而给CRF层进行训练,因而抽象过程中使用的词向量能够抽象出很多人工无法表达的特征,所以对文本的观察更为全面。比如“石油基合成橡胶”在训练语料中并没有完全出现,只出现了“合成橡胶”,BI-LSTM-CRF模型就能识别出此主体。原因在于输入的词表示向量带入了一定的语义信息,虽然训练语料中未出现,但经过BI-LSTM-CRF模型的抽象可以较好地学习出一些特征。
对于比较词识别的F-值达到了90%以上,但在识别时会将不含属性值的分句中的比较词识别出来。像“比较明显”、“占主导地位”中的,“比”、“占”也有些会被识别成比较词,但因为本文方法是以属性值作为数值信息抽取的触发词,故这种比较的错误词对最后的数值信息抽取结果并不会产生影响。
从表10的数值信息抽取结果可以看出,本文提出的方法要好于模式匹配的方法。原因在于,对于只含有一个属性值的句子来说,这种句子表达具有一定的规律性,有利于模式匹配。但对于含有多个属性值的句子来说,属性值和主体的元素都存在省略表达情况,而且对于含有多个属性值、多个主体、属性等元素时,这种之间的关系抽取利用模板很难表达出来,而非结构化文本中随意表达的无关词较多。并且有时候一个句子会被多个模式匹配或者不被匹配,从而抽取出错误信息或者抽取不出来。本文方法以属性值为触发词,通过特征识别各个元素和属性值的关系,对句子含有多数值和多主体等元素情况具有较好的抽取结果,方法具有灵活性和可移植性。本文方法的数值信息最终抽取结果是建立在其元素识别的基础之上,因此各个识别过程产生的误差会传递积累,有时一个主体等相关元素识别错误,会导致多个数值信息的抽取产生错误。因此,提高识别阶段的识别质量是提高本文方法抽取精度的关键,也是后续研究的主要内容之一。
在非结构化文本中,对于定中关系的属性值和主体会省略一些属性的表达。比如“180台平板电脑”,由于表达习惯将“数量”这个属性省略,省略的属性往往是这个单位所属的类别。所以今后要对收集到的单位进行更加详细的分类,加入句法分析等特征,进而对属性进行推理补充,以减少这种因为省略而造成的数值信息的抽取错误。
对于抽取出来的数值信息中比较类型的数值信息,可根据需要做相应的逻辑处理,推理出句子中隐含有的数值信息,表示成不含有比较元素的数值信息。
5 结 语
本文提出一种数值信息表示方法和数值信息抽取框架。该表示方法可以全面地表示出数值信息。抽取过程主要分为两步:数值信息元素和关系识别。其中针对属性值表达比较固定的特点,利用模板的方法对句子中的属性值在进行识别。采用了BI-LSTM-CRF模型对数值信息主体、属性和比较词进行识别。通过选取特征,判断属性值和其他元素之间的关系。实验结果表明,采用BI-LSTM-CRF识别的抽取方法正确率和召回率都达到75%以上,优于现有的模式匹配方法。
在未来的工作中,我们将尝试对深度学习模型参数进行改进,分别对主体、属性、比较词的识别进行优化。同时增加句法和句子角色等特征,尝试采用机器学习相关模型来进行元素之间的关系识别,进一步提高数值信息抽取的准确率。
猜你喜欢
小学生学习指导(低年级)(2023年4期)2023-05-09 11:52:52
建材发展导向(2022年23期)2022-12-22 07:30:02
建材发展导向(2022年12期)2022-08-19 02:33:10
中学生数理化·高一版(2021年11期)2021-09-05 14:27:13
南大法学(2021年3期)2021-08-13 09:22:32
自然与文化遗产研究(2016年2期)2016-05-17 05:53:59
焊接(2016年2期)2016-02-27 13:01:02
中国房地产业(2016年24期)2016-02-16 06:10:20
中国卫生(2015年9期)2015-11-10 03:11:10
山西大同大学学报(社会科学版)(2015年6期)2015-01-22 07:22:22
