
基于多方安全计算的属性泛化mix-zone
2019-05-05 09:44王斌张磊张国印
通信学报 2019年4期
王斌,张磊,张国印
(1. 哈尔滨工程大学计算机科学与技术学院,黑龙江 哈尔滨 150001;2. 佳木斯大学信息电子技术学院,黑龙江 佳木斯 154007)
1 引言
随着定位技术和无线通信技术的不断发展,基于这类技术的位置服务已经广泛地深入人们的日常生活当中,这种以提交用户当前或一段时间真实位置并获得如导航、兴趣点查询、广告推送等相关信息的服务方式为广大用户的日常生活带来了极大的便利。但是,随着越来越多地使用这种服务,人们逐渐发现基于位置的服务存在着获取及威胁用户个人隐私的情况,这使很多人逐渐减少对其的使用,并很大程度上制约了这种服务方式和服务技术的发展。
针对隐私泄露问题,很多研究者都提出了自己的观点。其中,提出最早并影响最深的是 Gruteser等[1]提出的k-匿名观点,该观点认为把用户的真实位置与其他至少k-1个位置共同提交给基于位置服务的服务提供商,利用真实位置与其他用户位置之间的不确定性来降低攻击者准确识别指定用户的概率,以此保护用户的个人隐私。随着该观点的提出,区域泛化[2]、位置多样性[3]、查询多样性[4]等相关观点被分别提出,并逐渐演化为欧氏空间的快照查询隐私保护[5-7]和欧氏空间的连续查询隐私保护[8-9]。但这类方法较难应用到真实环境当中,因为人们真实活动的空间被道路组成的网络结构所覆盖,按照欧氏空间得到的匿名位置可能位于一些不可到达或者易被攻击者识别的区域,进而无法有效地起到泛化用户真实位置的目的。因此,研究者又专门针对路网环境,提出了在该环境下的连续查询隐私保护方法[10-12]。不过,这些方法或者无法有效地应对攻击者使用的追踪攻击,或者在隐私保护过程中过于追求隐私保护的效果而对服务质量影响较大。这种情况导致另外一种被称作mix-zone[13-18]的可抵抗追踪攻击并能有效减少对服务质量影响的方法被广泛研究和应用。通常情况下,mix-zone可看作是一个外部用户无法获知任何消息的黑盒区域,在该区域中,内部用户可以进行信息交互、信息处理等一系列操作,而外部用户无法通过各种方式获取任何信息传递情况。同时,由于 mix-zone采用的是按照关键位置节点部署的方式,使2个连续节点之间的用户未受到各种算法的影响,因此对服务质量的影响相对较弱。综上,mix-zone的这一系列优点使其更适合在路网环境部署应用。
不过,用户在连续移动并查询的过程中并非仅仅去掉假名、查询时间等有限属性便可有效地抵抗攻击者的攻击行为。按照张磊等[19]的观点,攻击者可以根据连续用户所表现出的多种属性进行关联,进而猜测出用户的连续位置,分析获得用户的隐私信息。尽管在文献[20-22]中已经利用属性泛化实现隐私保护,但由于所针对环境的差异,这些方法并不适合直接应用到mix-zone中。针对这个问题,本文以属性泛化为基本出发点,从mix-zone构成的基本特性考虑,基于同态加密的基本思想,设计并提出了一种基于mix-zone半可信的用户代理、且用户属性信息全程不可获知的隐私保护方法,简称 AG mix-zone算法。基于该方法,mix-zone中用户可秘密计算获知泛化后的属性集合信息,利用泛化后的属性集合信息在离开mix-zone后表现为用户属性,以此令攻击者无法在非 mix-zone区域对用户属性加以关联。最后,本文通过安全性分析和实验验证,证明了本文所提算法的隐私保护能力及其在实际部署中的执行效率。
2 预备知识
2.1 系统架构
mix-zone主要设计用来防止攻击者实施追踪攻击,即通过mix-zone切断攻击者对用户的连续暴露位置所表现出的用户信息。但是,由于用户的属性彼此之间存在差异,使假名、查询间隔等有限属性互换很难隐藏可被攻击者利用的全部属性信息,进而表现为如图1所示的可被攻击者利用的属性关联模型。图1中,进出mix-zone的移动用户均表现出自身特定的用户属性,如用户ID、查询频率、查询内容等,并用三角形、五角形、五边形等不同图形来表示。攻击者可利用这些属性的相似性对进出 mix-zone的用户加以关联,使mix-zone的作用失效。

图1 未经属性泛化导致的用户属性表现
基于上述分析及图1的观测比较发现,这种关联的攻击方式可以表示为用户可被观测的全部属性的相似性比较,因此使用来量化这种相似性,其中,sim(⋅)表示相似性。设某一指定被追踪用户的属性为该用户离开 mixzone之后表现出的属性为若存在则可认为这 2种属性为同一用户所表现,即进出mix-zone的用户为同一用户,进而攻击者可对该用户进行持续追踪。其中,m为可被识别的属性数量,λ为攻击者可使用的属性相似最小阈值。
2.2 算法基本思想
针对利用用户表现出的属性相似性进行攻击的方法,最有效的手段就是进行属性泛化。属性泛化的基本思想是令所有离开 mix-zone的用户表现出相似属性,使攻击者无法利用进出mix-zone的用户属性关联来识别出指定的追踪用户。图2给出了这种思想处理后表现出的属性泛化结果。
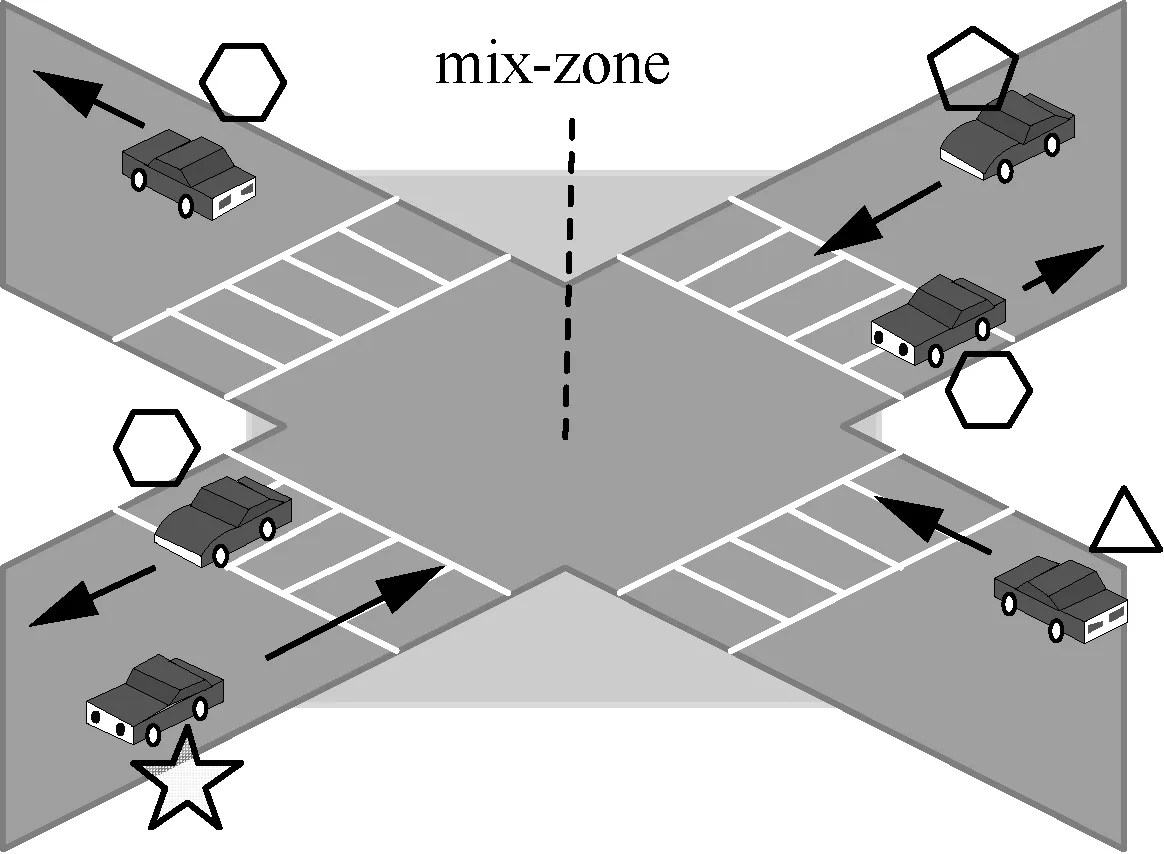
图2 经过属性泛化后的用户属性表现
从图2中可以看出,进入mix-zone时表现出不同属性类型的移动用户,在经过mix-zone的处理之后,均表现出五边形属性,这使攻击者无法利用进出mix-zone的用户之间的属性相似来识别用户。形式化表示为其中,n为当前mix-zone中的用户数量。但是,简单地通过mix-zone中的用户彼此之间交换并建立这种相似属性是不安全的,因为攻击者可以伪装成为参与者并被包含在mix-zone区域内,进而造成交换数据被攻击者获得从而泄露用户隐私,因此,需要一种既能够保障mix-zone中的用户彼此之间不能获得相关信息,同时又能通过选择的半可信代理用户完成相同属性信息处理的隐私保护方法。基于这一思路,本文利用同态加密的基本特性,分别利用秘密数据比较和秘密相似属性值计算对属性泛化的观点进行处理。在整个属性泛化的处理过程中,用户的信息既不会被代理获知,也不会被 mix-zone中参与者所了解,所有用户仅能获得最后泛化的属性均值,并利用该均值实现离开mix-zone后的用户属性泛化。
3 半可信代理的属性相似mix-zone
3.1 基于秘密数据比较的代理选择
完成属性相似计算的首要问题是在当前mix-zone区域内由所有用户共同选择一个半可信代理来完成属性相似计算。在各用户均无法获知真实出价的情况下,由出价最高的用户被选为代理。首先代理应是如图3所示的mix-zone内成员,以便与用户进行信息交互;其次,代理是在连续的竞标过程中胜出的一方,这样能够获得由其他用户反馈给该用户的消耗补偿。竞标过程可表现为如图4所示的分组竞标价格比较过程。

图3 mix-zone中代理与用户关系

图4 mix-zone中分组竞标价格比较过程
因此竞标比较问题可转换为多方的秘密数据比较问题,借鉴文献[23]给出的秘密比较方法,可获得如下所述的秘密比较处理过程。
假设当前mix-zone中存在的参与者人数为n,则参与者Pi( 1 ≤i≤n)每人拥有的长度为l bit的代理参选投标出价为转换为二进制表示为则出价可按照以下步骤进行比较。
步骤 21P利用自己的公钥pk1对自身的二进制出价进行逐比特加密,得到加密后的信息并向其他n-1个用户公开加密后的出价信息E(b1)。
步骤3 当kP收到加密后的出价E(b1)时,首先利用pkk对自身的出价进行加密,获得然后计算
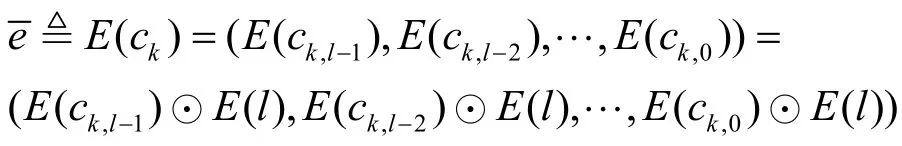
其中,E(l)是l在经过全同态加密后获得的密文,即将加密后的l位与出价E(l)的模之间进行d进位加法,如果其结果超出l位整数的表示范围,则只需去除低于l位的结果。
在完成上述计算之后,kP计算其中,gk表示第k位计算结果,表示对应的 2个λ位整数的进位加法,分别表示第i位的计算结果和第i位向第i+1位的进位;表示的模d进位乘法,模d进位加法和模d进位乘法均按照全同态加密方案中同态运算步骤加以执行,且每次对2个密文完成加法或乘法运算后,执行同态解密操作以降低密文中存在的噪声。在完成以上操作后,得到发送给用户1P。
步骤41P对解密后得到1P将结果发送给kP。
3.2 基于同态加密的属性模糊计算
通常情况下,用户在道路环境下的连续移动过程中可被攻击者获得并被识别的m个用户属性可表示为针对mix-zone中的n个用户,可将这种属性表示为1≤i≤n。属性模糊的目的就是使mix-zone中的多个用户表现出的属性集合之间存在,即针对任意选择的2个用户ui和其表现出的属性之间满足其中,λ为攻击者不可分辨出的最小阈值。为实现这种属性相似计算,且mix-zone中各用户(包括所选择的代理用户)在计算过程中无法获知任何用户属性信息,本文修改文献[24]提供的单轮集合地点计算的方式,对不同用户提供的属性进行相似属性计算。该计算过程可表示如下。
代理用户利用 ElGamal生成公钥pks=私钥为sks=α。其中,p是一个大素数,的发生器,满足
步骤1 对于mix-zone中的任意2个用户ui和用户uj分发和这 4个私密随机数;用户ui分发这4个私密随机数,其中,用户随机选择一个正整数满足并将si保存,其中,||.||表示比特长度。所有mix-zone中的用户共享一个通用的正整数且r满足
步骤2 将属性值平均分成两部分,用户ui的属性为用户uj的属性为首先,用户uj计算密文,具体如下。
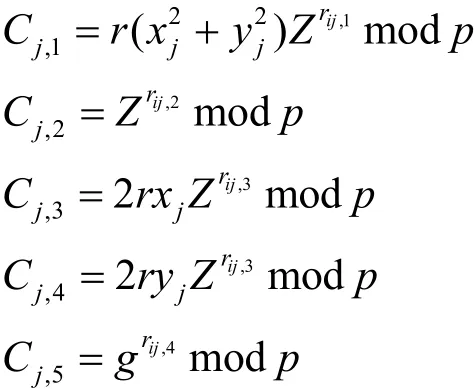
然后,用户uj将密文发送给用户ui。当收到密文后,用户ui计算如下密文。
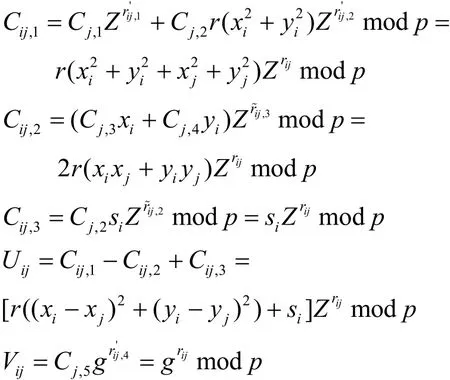
最后,用户ui将密文发送给代理。
步骤 3 代理在从用户ui处获得密文后,使用自身的私钥sks=α对其进行解密,并获得明文表示2个用户之间的属性差异距离。由于有 0≤mij=
步骤4 对于mix-zone中的每一个用户,代理计算mij的平均值然后计算差异对于每个差异代理需要计算r次,获得对每个用户之间的属性差异iσ,即。在获得后,代理在其中选择最小值及其索引k。由于r是正整数,可知kσ是在集合之中的最小值。即计算后获得的Ak的属性值kσ是与mix-zone中所有用户属性值最相近的,可以使用该值作为模糊后所有用户可使用的泛化属性。在整个计算处理过程中,每个用户均不知道其他用户的真实属性,而代理仅知道模糊后所有用户共同使用的泛化属性值,即在整个处理过程中没有用户属性信息被其他实体所获知。
3.3 安全性分析
由于本文所提算法是在属性相似的思想基础上,基于同态加密的处理方法实现的,该方法既可针对全程追踪的攻击者,又可针对参与mix-zone中的伪装攻击者,因此,其安全性需要从2个方面考虑:1) 攻击者对泛化后的属性信息准确猜测的不确定性;2) 算法中所使用的加密算法对参与到mix-zone中的2种用户(代理和一般用户)的信息泄露情况。
攻击者对泛化后属性猜测的不确定性使用信息熵进行度量,即设攻击者在离开mix-zone的众多用户中,根据表现出的属性相似性准确识别出追踪用户的概率为则攻击者在众多离开mix-zone中的用户中,利用相似性猜测的情况可表示为按照Jaynes最大熵定理可知,当Hi最大时,攻击者具有最大不确定性,即无法在离开的n个用户中准确地识别出追踪用户。为证明这一点,假设攻击者掌握的追踪用户属性为在离开mix-zone的n个用户中的任意 2个用户ui和uj的属性为和根据属性相似,攻击者可通过计算来判断这2个用户哪一个是被追踪用户。假设pu,i和pu,j分别是攻击者将这2个用户与追踪用户进行相似属性关联获得的猜测概率,则有而经过属性泛化,使攻击者无法通过相似属性对这2个用户进行区分,进而有此时根据Jaynes最大熵定理可知H取最大值,即攻击者在n个用户中准确地识别出追踪用户的不确定性最大。
加密算法对用户信息的披露可以从代理竞选和属性私密计算两方面加以分析。在代理竞选方面,任意用户之间只存在竞选代理所需要的计算补偿,只有在计算补偿最小的情况下,该用户才能被选为代理。整个竞选过程中,所有出价均在加密状态下完成,任何用户均无法获知其他用户的出价。由于代理竞选是在n个用户中选择,可能会出现参与竞选用户共谋获取其中某一用户出价的情况,但仅在的情况下,可猜测获得出价排位,但并不能获知具体出价。同时,由于mix-zone中的用户是一种随机建立的用户群组,一方面很难出现全部参与用户中仅余一个用户为待攻击对象的情况;另一方面,由于代理在属性泛化的过程中仍不能准确地获得待攻击对象的属性信息,因此其攻击投入与收获不符,即攻击者很难通过这种方式对待攻击对象加以攻击并获得其隐私信息。
在属性私密计算方面,用户信息的披露程度可以从相似属性计算的私密性方面加以分析,即在相似属性的计算过程中没有隐私信息被mix-zone中的其他参与者获知。对于代理用户,由于代理需获得密文并通过自己的私钥sks解密计算泛化后的属性信息,而分别是通过用户ui和用户uj的属性信息经过一系列模操作计算获取的。在模值(即mod计算后所取得的结果)为确定数的情况下,原始值(即加密前的明文信息)是不确定的,因而代理是不能利用获得的密文将用户的属性信息还原的,即使恶意用户与代理共谋攻击也无法还原该信息。
每个考站考核完毕教师分别根据考生表现进行针对性的点评,并适当提问相关问题,考生能现场对每一站的内容查漏补缺,尽量做到评定-治疗-病例分析之间的密切联系。每个考生考完一站后必须马上转移地点进行下一站考核,考完三站的考生最后在教室回避,不能与未完成考核的考生有任何交流。
对于除代理外的参与用户,设ε为隐私参数,A为攻击者,B为待攻击对象,攻击者对属性信息的攻击可转换为A和B之间的博弈在整个属性信息泛化处理过程中,假设A可获得代理用户的私钥sks及B的公开参数。所有mix-zone中的参与者的属性信息可表示为A1,A2,… ,An。B执行秘密属性计算可得到泛化后的属性信息并将密文及对的索引发送给A。B再选择随机属性并随机选择当ε=0时,将发送给A;当ε=1时,则将Ar发送给A。A猜测针对隐私参数ε的猜测值 {0,1}时,A获胜。此时攻击者在此博弈中的优势可表示为ε′∈ ,当且仅当由于在整个过程中,A无法通过有效的手段准确猜测ε′的取值,进而使ε′=ε的概率为随机猜测概率,由此可获得攻击者的博弈优势即攻击者不具备优势。因此,可认为除代理外的参与用户无法获知任意用户的属性信息。
基于上述分析,可认为本文所提的基于多方安全计算的属性泛化的 mix-zone能够有效地提供隐私保护,且针对不同类型的攻击者均具有较好的防护能力。
4 实验验证
4.1 实验设定
为了验证本文所提AG mix-zone算法在隐私保护能力和算法执行效率这2个方面的优势,本文利用BerlinMOD Data Set提供的路网数据,并随机选择位置生成mix-zone进行测试。实验使用笔记本电脑的处理器为Intel core I7,内存为4 GB,操作系统为Windows10,并采用Matlab R2017a作为测试工具进行模拟实验。同时,为进一步验证 AG mix-zone算法的优势,在测试的过程中与当前的一些同类算法进行了比较,参与比较的算法有通过移动耽搁泛化查询间隔时间的等待忍耐 mix-zone(delay-tolerant mix-zone)[25]、利用 mix-zone变形降低关联程度的偏移mix-zone(shifted mix-zone)[26]、多维 mix-zone授权的多维 mix-zone(multiple mix-zone)[17]和基于身份验证加密的加密mix-zone(cryptographic mix-zone)[18]。实验将从隐私保护能力和算法执行效率这2个方面展开,并且同时针对规则mix-zone和不规则mix-zone进行测试比较,以便获得部署mix-zone的最佳形状。其中,隐私保护能力将在属性泛化后的信息熵度量、泛化后的属性差异率、进出mix-zone用户的可关联性这3个方面展开;算法执行效率将在规则mix-zone和不规则mix-zone状态影响下的算法执行时间和隐私保护成功率等这2个方面展开。在验证属性数量对算法的影响时,将用户限定在 10个,而在验证用户数量对算法的影响时则将属性设定为 15个。为简化算法验证过程,整个实验中所使用的用户和属性数量均为 1~30。
4.2 隐私保护能力分析
从图5中可以看出,除本文所提AG mix-zone算法外,在用户数量一定的前提下,其他算法的信息熵均随属性数量的增加而减小。这是由于本文算法主要针对 mix-zone中的用户利用量化的多属性相似计算完成属性泛化,该方法处理的属性数量远超过其他算法。相比之下,加密mix-zone由于同样使用加密手段隐藏属性,表现要好于其他3种算法。而多维mix-zone表现要好于mix-zone和等待忍耐mix-zone算法,这主要是由于该算法使用多重的mix-zone进行重复覆盖,在一定程度上提升了属性隐藏的效率。偏移 mix-zone和等待忍耐 mix-zone由于针对的属性有限,且未能通过多重覆盖的方式降低属性暴露的风险,随属性增加导致的信息熵取值相对较低,但偏移mix-zone表现要好于等待忍耐mix-zone,这是由于偏移后的mix-zone在一定程度上起到了覆盖的作用,虽然低于多维mix-zone但要好于等待忍耐mix-zone。

图5 属性变化导致的泛化后信息熵曲线
从表1可以看出,5种算法在属性数量确定的前提下,信息熵均随着参与用户数量的提升而增长,即攻击者对属性泛化后用户的不确定性在持续增加。这是由于用户数量提升了攻击者的不确定性,令攻击者猜测的基数不断增长。在5种算法中,AG mix-zone算法能够取得信息熵最大值,这是由于该算法将所有显露的用户属性均加以泛化,最大程度地减少了攻击者可利用的属性。而其他算法中,多维mix-zone使用了多重覆盖的原理,在多个不同的 mix-zone中使用大量用户进行多种属性的泛化处理,其信息熵取值比AG mix-zone算法稍低。加密mix-zone虽然采用加密手段进行属性隐藏,但其所针对的属性有限,其信息熵低于多维mix-zone。另2种算法中,偏移mix-zone由于偏移性与覆盖相似,但偏移距离有限,限制了其对属性的泛化效果。最后,等待忍耐mix-zone由于主要应对时间间隔这一属性,其对于其他类型的属性泛化能力有限,导致该算法表现不佳。
从图6中可以看出,随着属性数量的增加,除本AG mix-zone算法外,其他算法在经过处理后用户表现出的属性之间仍存在较大差异,且属性数量越大这种差异越明显。由于AG mix-zone算法是针对所有潜在属性进行整体性泛化,因此泛化后的属性差异并不随着属性数量的增加而产生变化。其他算法则针对有限的属性加以处理,其处理能力有限,无法对所有属性展开泛化处理,属性差异随着属性数量的增加而逐渐变大。

图6 属性泛化后的差异
对于进出mix-zone用户的可关联性,本文采用成对熵加以度量,即成对熵取值越高,可关联性越低。从表2可以看出,AG mix-zone算法可取得最高成对熵取值,因为该算法将用户间的属性加以泛化,使离开mix-zone的用户均表现出相似属性,攻击者无法将这些用户中的任意一个与进入mix-zone之前的用户相关联。而其他4种算法均无法对所有属性加以处理,进而造成攻击者可通过属性加以关联,致使成对熵取值随属性数量的增加而逐渐降低,即攻击者可将进出mix-zone用户加以关联的概率增加,用户存在被攻击者识别的风险。
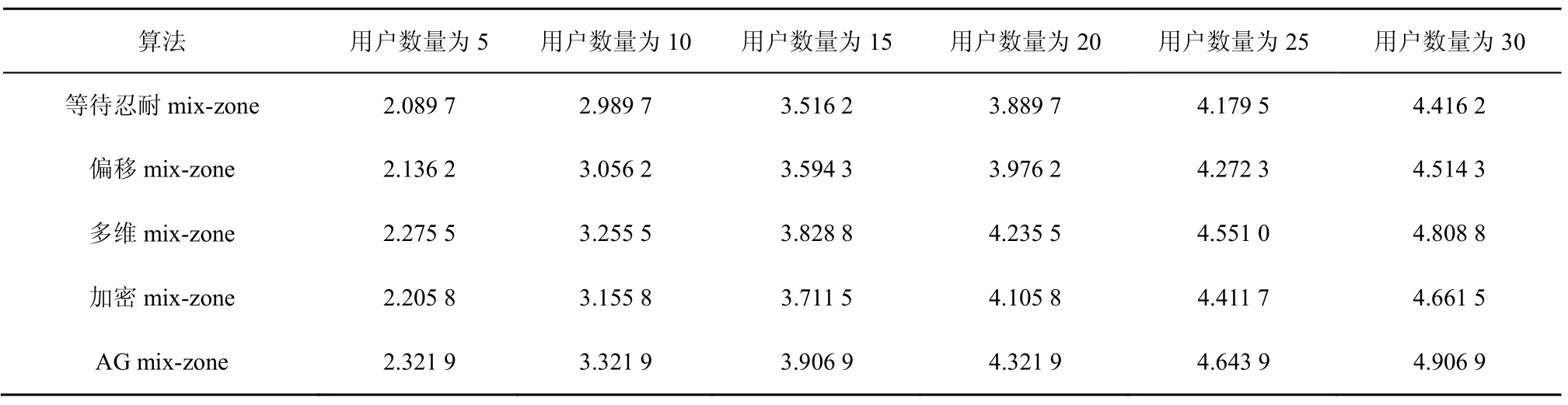
表1 5种算法在不同用户数量下的信息熵
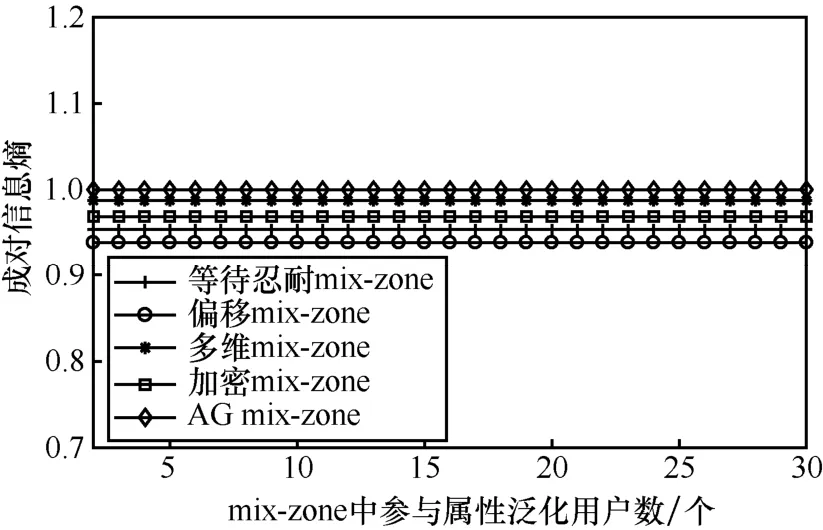
图7 随用户数量变化导致的进出mix-zone用户可关联性差异
4.3 算法执行效率分析
从图8中可以看出,除AG mix-zone算法外,其他算法均随着属性数量的增加,算法执行时间显著增长。这是由于 AG mix-zone算法采用的是mix-zone中的用户共同处理相似属性的方法,这种方法是对所有属性量化后由代理和用户之间共同完成的,整个处理过程不随着属性数量的增加而改变。而其他算法由于针对的属性种类等方面的限制,使在属性增加的情况下,算法不得不重复执行或者多次处理,进而导致随着属性数量的变化,算法的整体执行时间不断增加。其中,加密mix-zone和多维 mix-zone由于需要多次执行算法以处理更多的属性,因此执行时间受属性变化的影响最高,且在超过某一值后,这种变化加剧。而等待忍耐mix-zone和偏移mix-zone算法的执行时间未随属性的增加而加剧并不是因为这2种算法很好地解决了重复执行的问题,而是因为这2种算法针对的属性有限,即使多次重复也无法有效地处理过多的属性,因而其执行时间的变化并未表现出急剧上升的情况。

图8 随属性变化的执行时间(规则的mix-zone)
与规则 mix-zone下算法随属性变化而导致的时间差异不同,从图9中可以看出,AG mix-zone算法在不规则 mix-zone下其执行时间要高于规则mix-zone,这是因为在不规则 mix-zone下,AG mix-zone算法需要更多的时间来选择足够的且通信便利的用户来进行多方安全计算,通信距离的限制在不规则mix-zone中表现得更为明显,因而在一定程度上影响了AG mix-zone算法的表现。其他算法中,偏移mix-zone算法的表现要好于另外3种算法,这是由于该算法主要设计为不规则 mix-zone下的区域偏移扩展,更适于在不规则mix-zone的条件下部署。
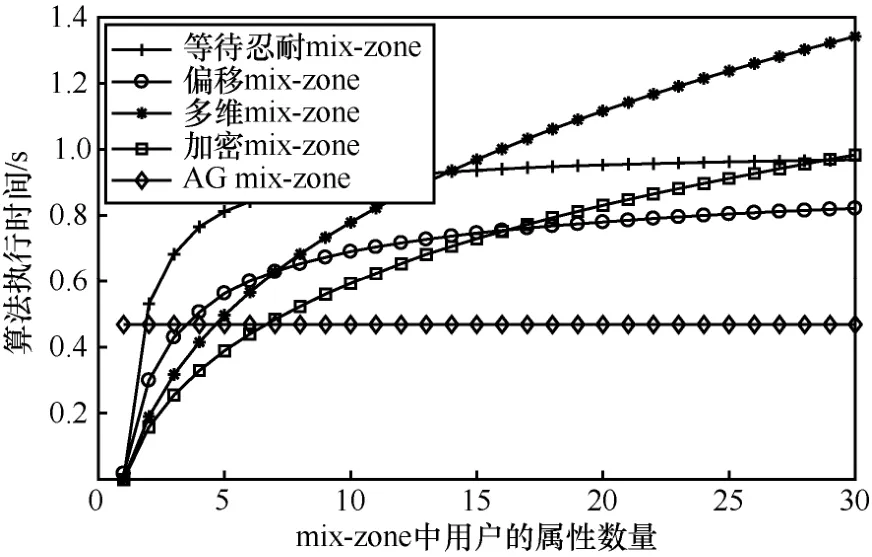
图9 随属性变化的执行时间(不规则mix-zone)
从表3中可以看出,随用户数量的变化导致的算法执行时间与随属性变化导致的执行时间存在较大差异。首先,AG mix-zone算法的执行时间不再保持固定不变,而是随着人数的增加逐渐延长。这是由于该算法需要mix-zone内用户进行多方安全计算,而增加的用户数量势必会导致计算的轮次或计算的基数增大,进而导致算法执行时间的延长。以加密为手段的加密mix-zone同样受到这一影响,其算法执行时间随mix-zone中用户数量的增长而延长。其他4种算法由于仅需建立mix-zone,并在区域中简单地对属性进行隐藏或者泛化,处理过程不随着用户数量的增加而更加复杂,因此在完成基本处理后无论mix-zone中的用户增加多少,处理时间保持稳定。
与规则 mix-zone下的用户数量变化导致的算法执行时间差异相似,从图 10中可以看出,AG mix-zone算法的执行时间依旧受用户数量的影响较大,且同类以加密为手段的加密mix-zone表现依旧相似。所不同的是多维 mix-zone在不规则mix-zone的条件下,受影响的程度有所降低,这是由于该算法在不规则mix-zone的条件下不再需要部署更多重复性的 mix-zone来实现属性隐藏,因此降低了其部署 mix-zone的数量,间接地导致算法执行时间的下降,但是这种降低较为有限。

图10 随用户数量变化的算法执行时间(不规则mix-zone)
从图11中可以看出,在规则的 mix-zone中随着用户数量的增加,各算法的执行成功率逐渐降低,这是由于所有算法均需要在mix-zone中找到足够的用户以满足当前属性泛化所要求的用户数量,当不能找到足够数量的用户情况下,算法执行失败。在这些算法中,AG mix-zone算法的执行成功率受用户数量的影响较小,这是由于该算法通过mix-zone中用户彼此间的多方安全计算来完成属性泛化,算法的执行仅需要找到足够数量的用户即可,并不需要对用户情况加以限制。其他算法中,多维mix-zone算法的执行成功率仅次于AG mix-zone算法,这是由于该算法仅需要在用户数量不足的情况下重复或者延伸部署mix-zone通过多重mix-zone来提升算法的执行成功率。相比之下,同样基于加密算法的加密mix-zone的受用户数量的影响相对较大,这是由于该算法需要通过寻找具有相似属性的用户来完成属性泛化,因此在很大程度上相似属性用户的寻找限制了其执行成功率。偏移mix-zone由于通过移动方式提升了相似属性用户的寻找能力,但是由于对查询时间的属性泛化,使该算法需要设定等待时间,而这种等待时间在很大程度上影响了用户参与的积极性,造成随着用户数量增加而导致的算法执行成功率降低。最后,等待忍耐mix-zone既没有偏移包含更多用户的能力,又受到等待时间的影响,成功率最低。

表3 随用户数量变化的算法执行时间对比(规则mix-zone)
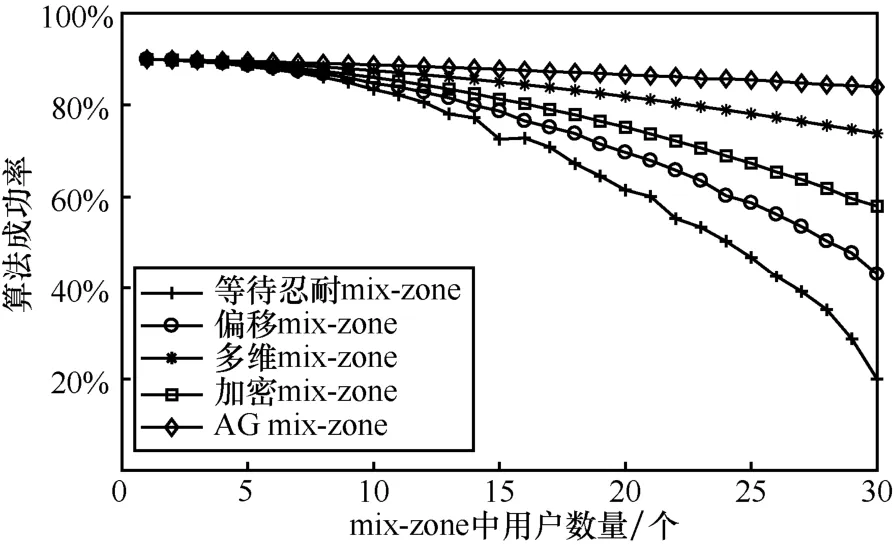
图11 随用户数变化的算法执行成功率(规则mix-zone)
不规则 mix-zone中随用户数量变化导致的算法成功率差异与规则 mix-zone中算法成功率的差异大体相同,所不同的是不规则mix-zone的算法成功率更高,进而表现为如表4所示的算法成功率整体上升的状态。这主要是不规则mix-zone由于设计特性导致其能够包含更多的用户在 mix-zone当中,相比于规则mix-zone更多的用户为属性泛化提供了更多的选择,进而提升了属性泛化的算法执行成功效率。
从图12中可以看出,在规则mix-zone下随属性变化导致的算法执行产生的成功率差异。AG mix-zone算法的执行成功率受属性变化的影响较小,仅当属性数量超过某一阈值时才逐渐表现出成功率的降低,这是由于该算法是通过属性量化后展开的相似属性泛化实现的隐私保护,算法所处理的是属性共有值而不是单独某一个值,而表现为不受属性数量影响的处理过程。而其他算法中,由于是直接对属性展开泛化,因此在属性增加的情况下,需要寻找满足属性相似的大量用户,在一定程度上,因属性数量增加而导致的相似属性用户寻找的困难造成了算法执行成功率的降低。另外,由于多维mix-zone、等待忍耐mix-zone和偏移mix-zone针对的属性数量有限,在成功率下降的同时,这3种算法反而表现出平稳的下降趋势,这是由于这3种算法仅针对某些特定属性,在无法提供所有属性泛化的情况下,这3种算法仅需完成对所针对属性的泛化便可完成算法执行,因而其下降趋势有所缓解。
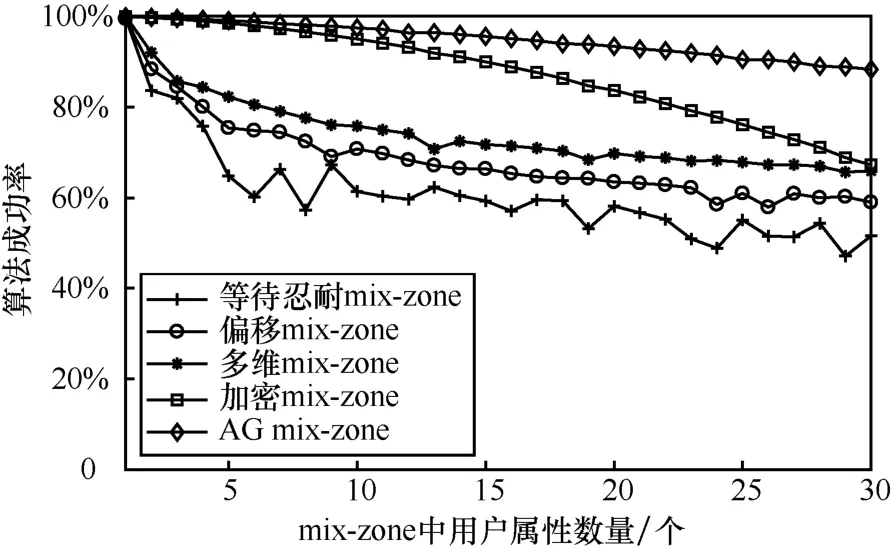
图12 随属性变化的算法执行成功率(规则mix-zone)
与在规则mix-zone下随属性变化的算法执行成功率相似,在不规则mix-zone下,各算法表现出的成功率差异可从如图 13所示的曲线差异中看出。所不同的是在不规则mix-zone下,各算法的成功率要高于规则 mix-zone,这是由于不规则的mix-zone能够包含更多的用户,进而为算法执行提供了便利,充足的用户数量提升了算法的执行成功率。

图13 随属性变化的算法执行成功率(不规则mix-zone)

表4 随用户数变化的算法执行成功率对比(不规则mix-zone)
通过上述实验验证结果可以看出,本文 AG mix-zone算法比其他同类算法具有更好地隐私保护能力和算法执行效率,因而该算法可更好地应用在实际路网环境的部署当中,有效地保护了用户的个人隐私。
5 结束语
在路网环境中,mix-zone作为一种有效地防治攻击者对用户展开追踪攻击的手段被广泛的研究和应用。然而,在现实使用的过程中,一方面用户在离开mix-zone区域后所展现的属性可被关联;另一方面一些潜在的能够伪装并加入mix-zone中的伪装攻击者可获得用户彼此间传递的信息。针对这2种存在的问题,本文基于属性泛化和同态加密,提出了一种能够实现用户属性不可关联且mix-zone中用户无法获知彼此真实信息的隐私保护方法。该方法通过秘密选择代理,并由代理完成私密相似属性计算,最终实现离开mix-zone的用户彼此间的属性不可关联。为证明本文所提AG mix-zone算法的有效性和算法执行效率,在安全性分析中使用了博弈论的观点对加密手段和泛化效果进行了理论证明,同时在实验验证中给出了算法在实际部署中取得的各种效果,并通过与其他 4种算法的比较进一步说明本文所提 AG mix-zone算法的优势。尽管本文所提AG mix-zone算法能够解决mix-zone中存在的固有问题,但是由于所采用的多方安全计算需要较大的计算量和计算处理时间,AG mix-zone算法在执行效率上仍存在较大缺陷,今后的工作将在如何提升执行效率方面展开。
猜你喜欢
摄影之友(2019年8期)2019-03-31
爱你·心灵读本(2018年6期)2018-09-10
爱你(2018年16期)2018-06-21
软科学(2017年3期)2017-03-31
学生天地·小学中高年级(2016年8期)2016-05-14
指挥与控制学报(2015年4期)2015-11-01
中国火炬(2014年8期)2014-07-24
中国火炬(2014年1期)2014-07-24
环球时报(2014-01-18)2014-01-18
中国火炬(2012年2期)2012-07-24
