
基于震例类比的震后趋势早期判定技术系统建设
2019-05-04 11:24刘珠妹蒋海昆李盛乐黎明晓汪园园刘坚
中国地震 2019年4期
刘珠妹 蒋海昆 李盛乐 黎明晓 汪园园 刘坚
1)湖北省地震局,地震预警湖北省重点实验室,武汉 430071 2)中国地震台网中心,北京 100045
0 引言
震后趋势早期判定对震后应急部署决策有重要的参考意义。震后趋势判定的时效性和科学性是其关键。根据中国地震局监测预报司震后紧急会商工作流程(1)中国地震局办公室,2019,《震后趋势会商业务规定(试行)》(中震办函[2019]23号).规定,显著地震发生后半小时内需上报震后趋势快速研判意见。在极短时间内,大量历史地震、构造背景等资料的清理、计算、分析以至于产出产品,离不开技术系统的支持。
美国国家现代地震监测系统(ANSS)自2000年创立以来,依赖地震与大地测量数据的汇集和分析,向政府应急管理人员、社会公众以及地震研究人员发布地震发生及其影响的多类信息,包括地震速报、ShakeMap相关产品、测震波形资料、震源机制解等。值得注意的是,自2018年8月开始,ANSS开始采用Page等(2016)改进的Reasenberg-Jones模型(Reasenberg et al,1994、1989),对美国境内显著地震进行余震概率预测,并计划于2019年实现自动化产出。目前,人工参与的余震概率预测第一次产出在震后30min后,之后将随着序列的不断发育更新预测结果(Barall et al,2019)。
我国应用震后趋势判定技术始于1990年,北京亚运会期间发生昌平4.0级地震,原国家地震局迅速应对,判断后续不会发生影响性地震,保障了亚运会的顺利举办。武安绪等(1999)在国家地震局预测预防司支持下,于1998年推出了SSRA地震现场震情分析软件,在地震现场和日常预报工作中取得了一定效益。蒋海昆等于2007年组织研制了基于GIS的华东南地区震后趋势判定软件(董曼,2008),在地震类型分区的基础上,一键产出震中所在区域的构造背景、历史地震活动空间分布和区域特征,为分析预报人员提供会商基础材料。2014年,张永仙等参与组织了华北地区强化跟踪项目,将华北地区进一步细化为14个首都圈分区与50个外围分区,并建立了华北震后快速响应及计算机查询系统,在多次地震应急响应工作中发挥了效用。随后该系统被统一集成到MapSIS地震分析预报软件中,在全国的震情分析会商工作中得到应用(刘坚等,2018)。
除此之外,还有应用于局部区域震后趋势判定的软件,如广西震后趋势快速研判系统(张华等,2014)、基于地震序列研究的震后快速判定系统(许昭平,2012)、震后趋势决策支持系统PTDSS(庄昆元等,2001)、基于震例的测震学异常辅助判定系统(黄金刚等,2017)等。上述系统在序列统计分析、震后地震活动趋势判定工作中发挥了作用,但也存在许多不足,影响着序列早期趋势判断的时效性和规范性。随着我国地震应急管理体制的逐步建立,针对新的需求,各类问题日益凸显:
(1)服务于震后趋势判定的基础知识库不够完备。例如在地震序列类型判定中最重要的地震序列目录,目前均由各省级地震局自行收集或以一定算法提取,缺乏完整、权威的全国范围内的地震序列知识库。此外,以往使用的全国行政区划数据、全国断层构造数据大部分为2000年左右版本,需要及时更新以提高产品准确性以及满足规范化地图生产的要求。目前由于各类基础数据的差异,国家层面与区域层面产出结果之间不一致的现象时有发生,这在当前政府部门上下联动紧密、资讯快速传递的应急管理体制下,不能满足地震工作服务政府部门的相关要求。
(2)现有震后趋势判定系统流程规范性不足。现有的大部分趋势判定系统均为按需定制的工具型软件,需要人机交互操作完成资料下载、序列时空分析、趋势会商意见产出等工作,尚未完成流程化作业。部分软件(如MapSIS)在趋势判定自动产出方面开展了初步的尝试,但由于触发机制不够完善,趋势判定规则及流程尚未统一规范,也未实现权限控制下的资料多平台推送,尚不能满足新时代地震工作服务社会的需要。
(3)判定规则简单,未充分体现目前对震后趋势判定的科学认知。此外,目前的震后趋势快速判定大多根据特定区域内不同震级档的先验模板产出,不能在震情发展过程中及时更新资料,也未能结合专家知识和其它辅助条件灵活调整判定规则、动态参与到震后趋势判定中来。
针对上述问题和新形势下地震应急工作的需求,震后趋势判定技术系统(CENC Automatic Aftershock Forecasting, 简称CAAF)于2018年投入研发。其中震后趋势早期判定技术系统作为CAAF中最重要的子系统,将最新的区域地质背景、行政地理和人口经济要素、历史及现代地震活动、震源机制解、水库或人类工业活动等多源异构数据结合起来,根据中国地震局地震应急处置和工作流程要求,以历史地震活动类比为基础,基于专家规则和动态震情数据,初步实现自动触发的震后早期趋势研判及相关报告的流程化产出,并在权限规定内通过多平台快速推送给用户。
1 震后趋势判定相关知识库建立
1.1 知识库组成
服务于本系统的知识库包括多方面的数据集,可大致分为地理地质、测震两大类。这些数据集部分来源于已有研究成果或最新行业共享资料,部分由本文重新整理所得。各数据集来源、更新版本和更新频率见表1。

表1 震后趋势背景知识库数据集
地理地质类数据集包括全国行政区划边界(分为省、市、县、乡镇四级)、县级人口统计数据、中国及邻区构造断层矢量数据(徐锡伟等,2016)、全国30s分辨率地形数据、全国大型水库数据(1亿m3库容以上)、工业活动区范围等。
测震类数据集包括中国及邻区1970年以来现代小震目录、1900年以来历史强震目录(5级以上)、地震序列目录、1900年以来“西6东5”(2)“西6东5”指以107°E为界,我国西部M≥6、东部M≥5地震事件。后文“西5东4”同理。强震破裂区、1900年以来震源机制解(4级以上)以及区域地震活动资料。其中,历史地震序列目录采用了《中国大陆地震序列目录整理》项目的“西5东4”序列目录成果(3)中国地震台网中心等,2018,《中国大陆地震序列目录整理》。,此外还补充本系统计算的其它小震地震序列类型。区域地震活动资料采用了《中小地震(序列)类型及区域特征》项目成果(4)中国地震台网中心等,2007、2008,《中小地震(序列)类型及区域特征》。,包括全国176个地震分区的地震构造概况、历史与现代地震活动特征等大量的基础数据和图文资料。
1.2 历史地震序列数据集创建
1.2.1 序列分类规则
根据震后趋势判定工作需要,我国一般将序列类型分为主-余型(包含前-主-余型)、孤立型和多震型3种类型(Utsu,2002;吴开统,1990)。依据《震后趋势判定参考指南》(蒋海昆等,2015),本系统采用ΔT时间内序列主震与最大余震震级差ΔM划分序列类型
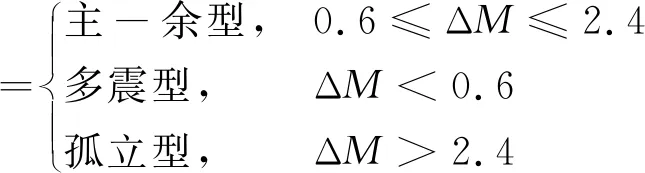
(1)
参考蒋海昆等(2006)对中国大陆中强地震序列的统计结果,93%的序列1年内的最大余震发生在90天内,因此ΔT取3个月。
1.2.2 序列目录及类型确定
1970年以来“西5东4”以上的序列目录及相关资料由《中国大陆地震序列目录整理》课题组整理得到。该数据集依据最大曲率方法(Wiemer et al,2000),选择使G-R关系偏离线性时的震级作为最小完备震级。序列持续时间根据震源区当前地震活动率与背景地震发生率相比较的方法确定(盛菊琴等,2007)。余震区范围则是考虑主震发生区域地震监测能力,以主震后48h或72h(余震较少时适当延长)内余震分布外包络并外扩一定范围得到的。余震后期扩展较为丰富的序列则依靠人工判断勾画合适的区域边界。
为弥补人工整理的地震序列不足,排除已整理的“西5东4”序列后,系统对剩余目录中所有M≥3地震,利用上述规则自动检测小震序列。
2 系统设计及实现
2.1 系统框架设计
为实现震后快速资料准备、参数计算、趋势判定以及多平台发布要求,系统采用稳定性强的C/S架构(图1),部署在中国地震台网中心云服务平台,分为数据资源、核心计算、业务模型、接口服务以及表现层5部分。
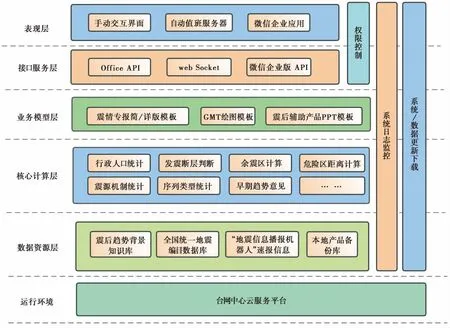
图 1 系统框架设计
数据资源层包括震后趋势判定相关背景知识库、全国统一地震编目数据库、地震速报信息以及系统产品的本地备份。其中震后趋势判定背景知识库以文件数据集的形式列装于服务器;全国统一地震编目数据通过Oracle数据库接口调用;地震速报信息包括发震时间、震中经纬度、震级、深度、发震地名,通过web接口向“地震信息播报机器人”高速拉取。
核心计算层包括震情基础资料、会商辅助信息以及震后趋势快速研判过程中涉及到的数据清洗、资料时空统计以及模型运算,如行政人口统计、发震断层判断、强震余震区计算等。业务模型层中预先设置了绘图模板和Word、PPT产品模板,核心计算的结果将在该层生成对应的图件,并通过Office API接口生成《震情专报》简报或详报以及会商辅助信息PPT产品。
最后,产品分别推送到台网中心值班服务器以及“地震信息播报机器人”企业公众号。前者采用web Socket实现局域网点对点的文件传输,相较于FTP文件传输方式更为简易方便;后者在“地震信息播报机器人”主体上建立“震后趋势”应用程序,设定用户审核通过机制,通过企业微信API发送http消息请求,将产出的震后趋势判定相关信息发送至“震后趋势”应用,再推送至特定权限的行业用户。
以上流程除自动触发启动以外,系统还支持断网、断库情况下的手动操作模式。值班员可通过客户端界面输入地震参数,调用本地存储资料进行手工流程触发,以避免应急时网络堵塞等状况,但手工操作的数据无法实时自动更新。
2.2 系统产品设计
系统产出的最终产品为《震情专报(详版)》、《震情专报(简版)》、会商辅助信息PPT以及相关图件和原始数据资料。
《震情专报(详版)》是协助预报人员在会商后撰写趋势研判报告提供的草拟稿,共包含12类震情相关信息,分别为:①地震三要素,②与历史强震的时空关系,③震中附近历史及现代地震活动概况,④历史地震序列类型统计特征,⑤震情早期趋势判定意见,⑥Ⅲ度以上烈度影响范围及人口数量,⑦震中附近主要断层及断层性质,⑧与年度地震危险区的空间位置关系,⑨震前15天内“前震”活动概况,⑩震中附近水库、工业活动等人类活动区域分布,震中附近历史震源机制及优势空间分布,震中所在地震分区的构造背景和地震活动特征等。《震情专报(简版)》是预报人员震后半小时内上报研判意见的基础,是《震情专报(详版)》的凝缩,包括上述前5类震情信息。以上基本信息根据不同场景要求、实际的数据完备程度,灵活组装为通顺连贯的报告。
会商辅助信息PPT则将上述信息以文字、表格、构造和震中分布图、不同时间尺度M-T图、震源机制沙滩球及玫瑰花图等可视化的形式进行展示,作为预报人员会商汇报的基础素材。
2.3 系统技术实现
2.3.1 系统启动阈值
在服务器运行期间,系统高频拉取“地震信息播报机器人”提供的地震速报参数。一旦检测到新发生的地震且符合启动阈值时,将自动触发震后趋势判定工作流程。
结合中国地震局震后趋势会商工作流程①要求,目前系统启动阈值为:
(1)大陆西部(107°E以西,含)M≥3.8地震;
(2)大陆东部(107°E以东,不含)M≥2.8地震;
(3)北京、天津、上海、唐山、保定、张家口、承德、廊坊行政区域M≥2.0地震;
(4)中国台湾地区M≥4.5地震;
(5)其他省会城市与计划单列市M≥3.0地震。
本系统原则上只针对“主震”开展早期趋势判定工作。为避免大震后强余震频发触发系统,降低对用户的“打扰”,系统根据动态震情数据,采用预定义规则对启动阈值进行动态调整。通过该机制,目前对强震发生后24h内的4级以下余震做“静默”处理,预判并提醒用户当前地震是否与近期已发生强震构成“多震型”序列或属于其“余震”。
2.3.2 震后趋势早期判定技术
由于时间紧迫,震后第一时间内序列尚未充分发育,无法满足序列参数计算的样本要求。但由于中强地震破裂特征主要受制于区域应力场与局部构造的相互作用,中国大陆中强地震破裂特征具有一定的区域差异性(张晓东,2004),相应的序列类型也有一定的区域特征(蒋海昆等,2006),因此实际工作中常常根据区域历史地震活动特征和历史地震序列特点,通过相似性类比方法(中国地震局,1998),初步判定震后早期趋势意见。本系统充分利用专家规则,建立的震后趋势早期判定模型,如图2 所示。
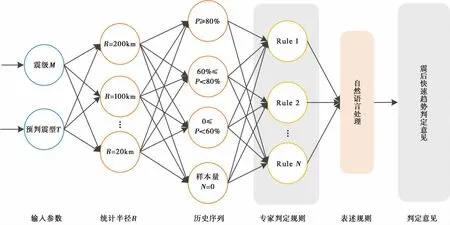
图 2 震后趋势早期判定模型
其中,震后趋势判定意见的专家规则Rule,可表示为如下形式:

在该规则中,只要输入参数满足一定的预置条件,即将得出唯一对应的结论。
〈条件变量〉包括5种,分别为当前震级M,区域统计半径R,历史地震序列比例P,历史序列样本量N以及预判震型T。根据《震后趋势会商业务规定》(中国地震局办公室,2019),R(单位:km)与M的关系为
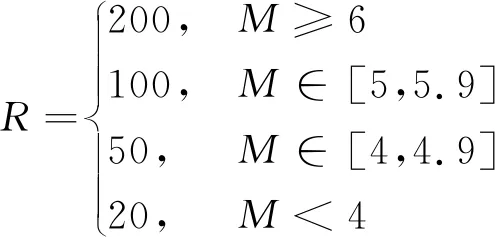
(2)
预判震型T={主震,余震,多震},表示当前地震是否为独立主震事件,或者与前次地震构成余震或多震型序列。
〈运算符〉表示条件变量间的关系,通常为“且(and)”、“或(or)”和“非(not)”。〈条件值〉表示条件变量的取值,如R=200,P=65%,N>10。〈权重〉表示各变量在规则判定中的重要程度。在本模型中,当T取值为“余震”或“多震”时,各变量权值将自动调整,以输入震级M和预判类型T为主进行早期趋势判定。
〈结论变量〉包括2种,分别为“后续是否有强震”、“强震震级”。〈结论值〉经自然语言处理为{“有可能发生”、“发生的可能性不大”}、{“有感地震”、“类似大小地震”、“m(m|4,4.5,5,5.5,6)级地震”、“更大地震”}等多种表述方式。
通过以上设定,当输入地震事件的震级、预判类型时,该模型将自动统计规定范围内的历史序列类型,并经过专家判定规则与自然语言表述规则,最终输出该地震的震后早期趋势判定意见。
2.3.3 不同场景下信息模板筛选技术
根据资料的完整度以及震级下限设定,系统可采用不同的优化算法,选取不同信息模板统计不同范围的资料,从而产出不同详细程度、不同信息组合的产品。具体的实现过程为:根据输入的地震速报基本参数和预置的模板选用规则,在模板库中检索和筛选候选模板;利用预置的各模板组合顺序,最终确定完整的产品模板;最后过滤不同模板中“冗余”信息,使报告简洁、精炼,更贴近于自然语言输出。部分候选模板及筛选条件见表2。
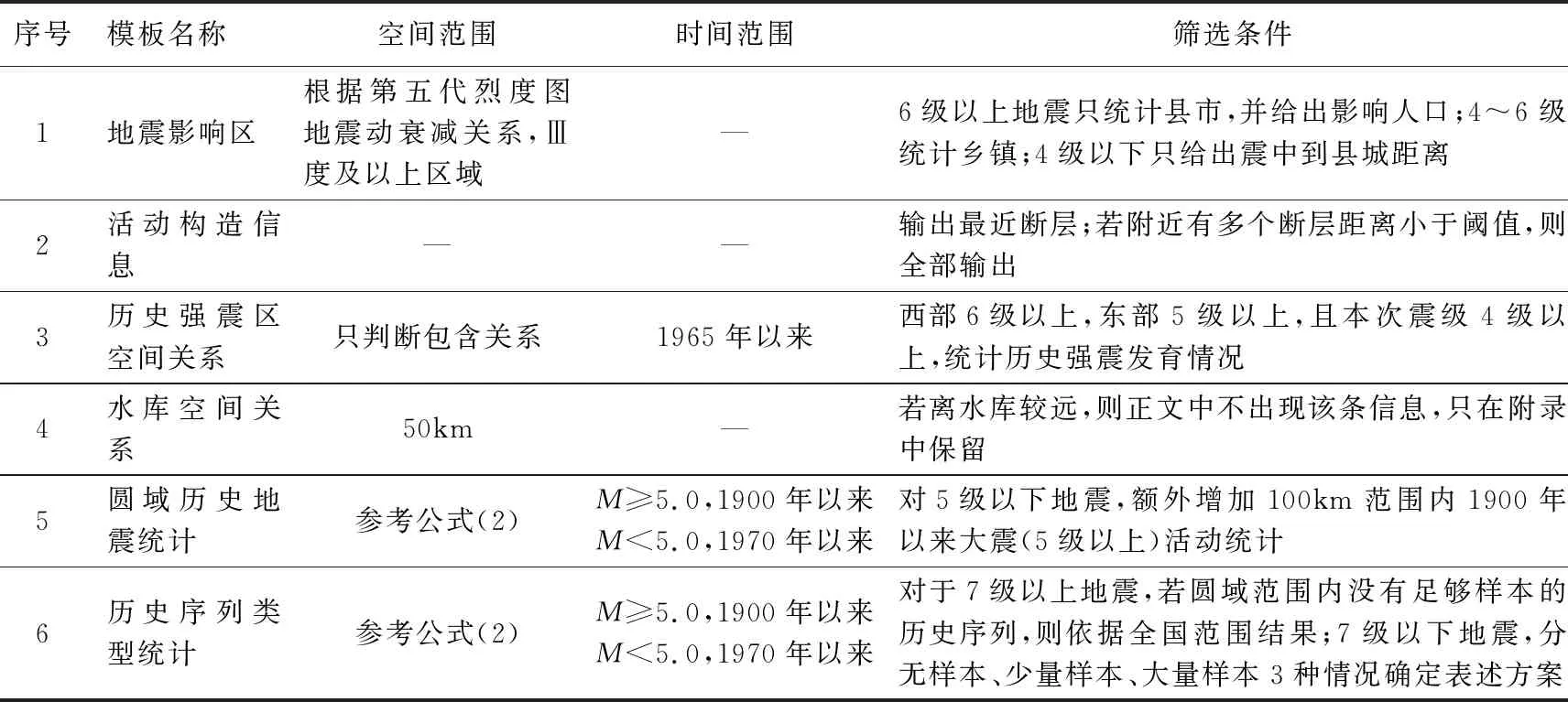
表2 部分候选模板及筛选条件
注:“—”表示没有该约束条件。
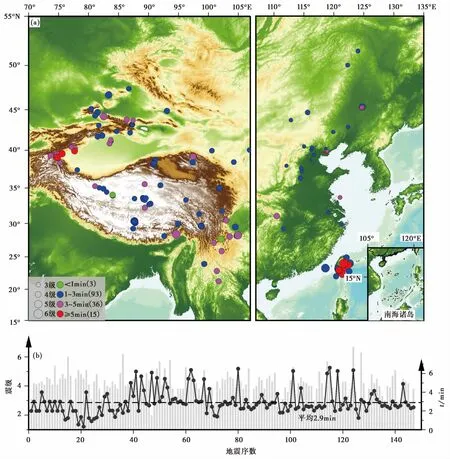
图 3 系统试运行期间响应震例的空间分布(a),震级(灰色柱图)及产出时间(黑色点线)(b)
3 系统应用
震后趋势早期判定技术系统于2018年10月开始试运行,直接与中国地震台网中心预报部业务挂钩,同时向中国地震局监测预报管理部门、全国各省地震局分析预报部门提供服务,初步实现震情会商分析资料、社会地理资料、地质构造资料、历史地震活动资料以及震后趋势快速研判意见等产品的快速产出。截至2019年5月31日,正式产出147个地震事件的震后早期研判震情专报及会商PPT等产品,地震事件分布见图3。
3.1 产品产出时间
系统部署在Windows server 2008虚拟主机上,配置Intel E5双核CPU及32G服务器处理内存、2TB硬盘,安装Office2013及GMT6.0制图软件。
自系统检测到符合触发条件的震例开始,至产品推送到指定用户,计算产品产出时间。该时间与产品的丰富程度、类型格式以及具体的可视化呈现形式有关,不同的产出条件消耗时间不同。如MapSIS软件一键产出会商PPT报告约耗时3~5min;广西震后趋势快速研判系统基于ArcGIS平台,可在5min内产出Word或PPT形式的震后研判结果;美国ANSS系统的余震预测意见在震后30min内产出至地震专题网页。虽然不同系统具体产出内容不同,无法做绝对时间消耗的对比,但在本系统试运行阶段,约90%的震例(132个)产品产出在5min以内,说明系统运行效率较高,能高效完成资料准备、计算、绘图、分析、产品推送整个流程。所有147个震例的产品产出平均消耗2.9min(图3(b)),时间效率优于同类系统或与同类系统持平(3~30min不等)。
另外,约10%震例(15个)的产品产出时间在5min以上,主要分布在唐山老震区、中国台湾东部、新疆塔什库尔干至乌什等区域(图3(a))。这些区域地震活跃、历史地震资料多,因此需要绘制的图片较多,耗时较长。其中耗时最长的为2019年4月4日中国台湾台东县5.1级地震,约6分37秒,但仍满足早期震后趋势快速判定的要求。同时,由图3(b)可知,产品产出时间与地震震级大小关系不明显。虽然主震震级越大、统计区域半径越大,但参与统计的历史地震震级下限也随之提高,加之不同区域的地震活动有差异,实际检索到的历史震例丰富程度并不随之增大。
3.2 震例自动产出与人工研判结果的对比
系统研发目的是为预报人员在震后快速产出、意见快速上报阶段提供辅助支持。除基础信息的提供、参数的计算、基本图件的制作外,其核心是快速产出震后趋势研判意见。该意见与人工参与研判结果的一致性程度,是衡量系统能否在一定程度上“替代”人工的关键。
系统被震情触发后,自动产出的震后趋势研判意见(以下简称为“自动产出”),经中国地震台网中心预报人员快速研判修订为“《震情专报》快速研判意见”(以下简称“人工修订”),并在半小时内上报。若震级达到规定的应急响应级别,各学科专家、片区相关分析预报人员将召开震情紧急会商,在3h内产出并上报“《震情专报》会商研判意见”(以下简称“会商意见”)。“人工修订”和“会商意见”统称为“专家研判”。在上述的趋势研判意见中,核心内容是原震区近几日后续地震活动水平上限估计,针对部分地震还包括可能的余震震级预测。
从“自动产出”与“人工修订”、“会商意见”结果的定性对比来看(图4),主震震级在5级以下时,“人工修订”和“会商意见”震级略高于“自动产出”。例如2018年11月6日广东雷州3.1级地震,系统判定后续不会发生更大地震,而专家研判认为后续地震上限应为5.0级(实际上,震后数月雷州地区未发生3.1级以上地震)。主震震级在5级以上时,“人工修订”和“会商意见”震级略低于“自动产出”。如2019年4月4日中国台湾海峡5.1级地震,系统判定后续地震不会超过6.0级,而专家研判认为后续震级应在5.0级以内(实际震后数月原震区确实未发生5.0级以上地震)。
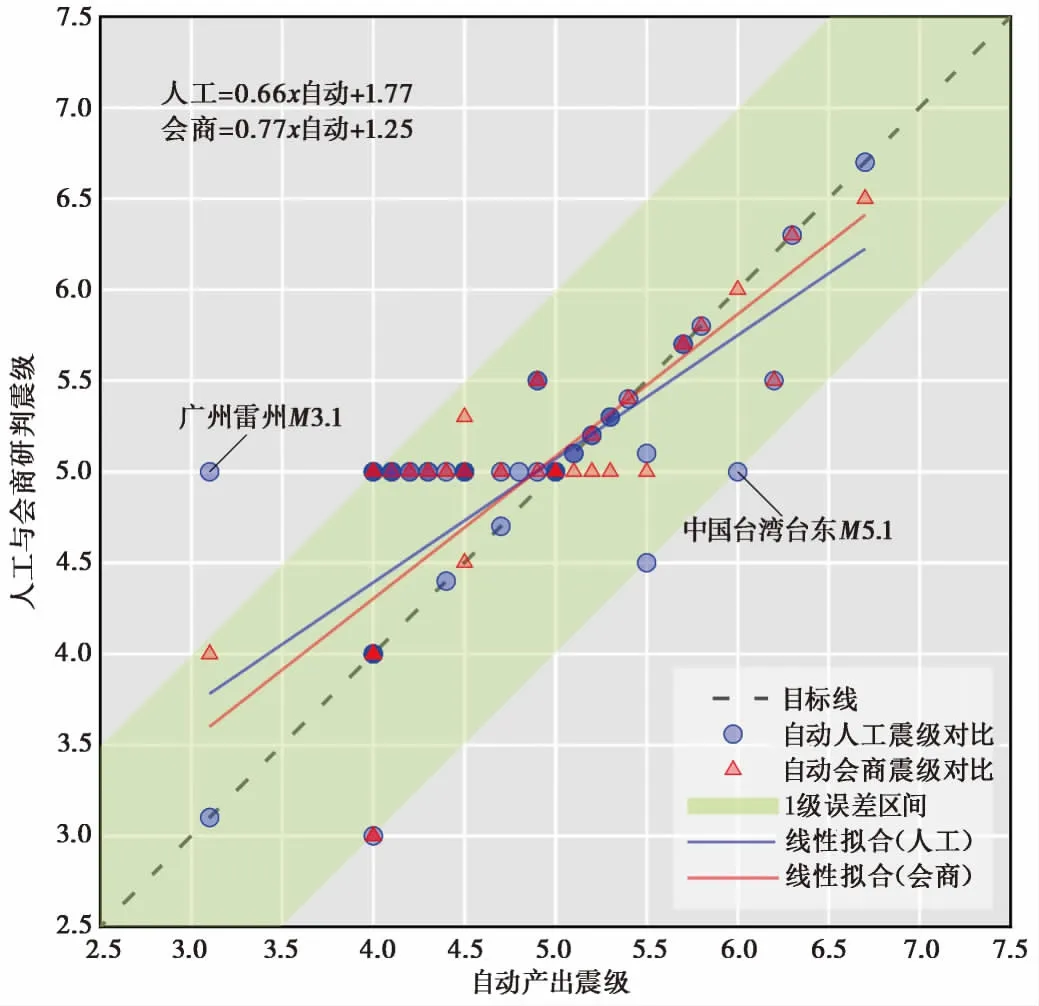
图 4 “自动产出”与“人工修订”、“会商意见”结果对比当自动产出震级与人工及会商意见一致时,标记点将落在斜率为1的目标线上
此外,主震震级在4.0~5.5之间时,“人工修订”和“会商意见”以5级居多。这实际上是人工更多地考虑到地震的影响程度(5级以下一般不会造成明显破坏或人员伤亡),从而给出了1个“比较安全”的震级上限估计,并不是严格按照序列判定规则给出的结果。
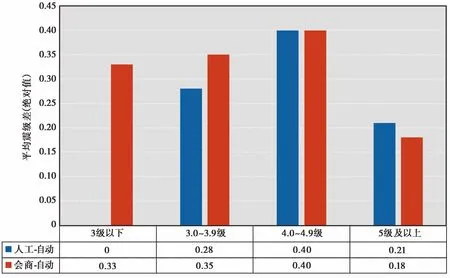
图 5 震级偏差与主震震级分段的关系
此外,分析震级偏差与主震震级分档的关系(图5)可知,就震后0.5h内必须上报的“人工修订”意见而言(图5 蓝色柱),3.0级以下震级段的“人工修订”直接采用了“自动产出”结果,因此图5 中该档震级“人工-自动”平均震级差为0;而3.0级以上震级段的“人工修订”结果一般与“自动产出”相差0.2~0.4个震级单位。就震后3h内要求上报的会商意见而言(图5 橙色柱),5级以下震级段的“会商意见”与“自动产出”相差0.3~0.4个震级单位,5级以上震级段的“会商意见”与“自动产出”相差0.1~0.2个震级单位。
综上,大多数情况下“自动产出”与“人工修订”以及“会商意见”其结果差别不大(许多情况下“人工修订”直接采用了“自动产出”结果),但经过人工参与的专家研判震级上限一般会高于自动产出结果,平均提高0~0.4个震级单位。
3.3 自动产出及专家研判结果与地震实况的对比
系统试运行期间响应的147次震例中,有39次在震后7天内发生了后续余震。对比“自动产出”以及“专家研判”结果与实际地震情况的吻合程度,“专家研判”结果以“会商意见”为主,若未会商则采用半小时之内上报的“人工修订”结果。
从39次震例的预测情况来看(图6),“自动产出”震级上限(橙色曲线)随不同震级有较明显的起伏波动,与主震震级(灰色柱)有一定的正相关关系;“专家研判”震级上限(蓝色曲线)起伏趋势与“自动产出”基本一致,但有明显的“趋稳”特点,许多震例震级上限估计趋于5.0级,即一般表述为“发生5级以上地震的可能性不大”或“不会发生5级以上地震”,这与前述考虑破坏影响的预测思路有关,并不是严格基于序列数据得到的结果。具体来看,4次震例(约10%,表3)震后7日内原震区地震震级突破了“自动产出”的震级上限,但仅有1次(2019年5月11日吉林松原5.1级地震)突破了“专家研判”的震级上限。说明仅就预期震级上限估计而言,“专家研判”结果相对更为保险。除震级上限估计外,“自动产出”还对其中21个震例给出具体的预测震级范围(图6 中紫色圆点及±0.5级误差棒)。21次震例的预测震级与地震实况平均相差0.8级,其中约43%(9次)震例震级偏差在0.5以内。
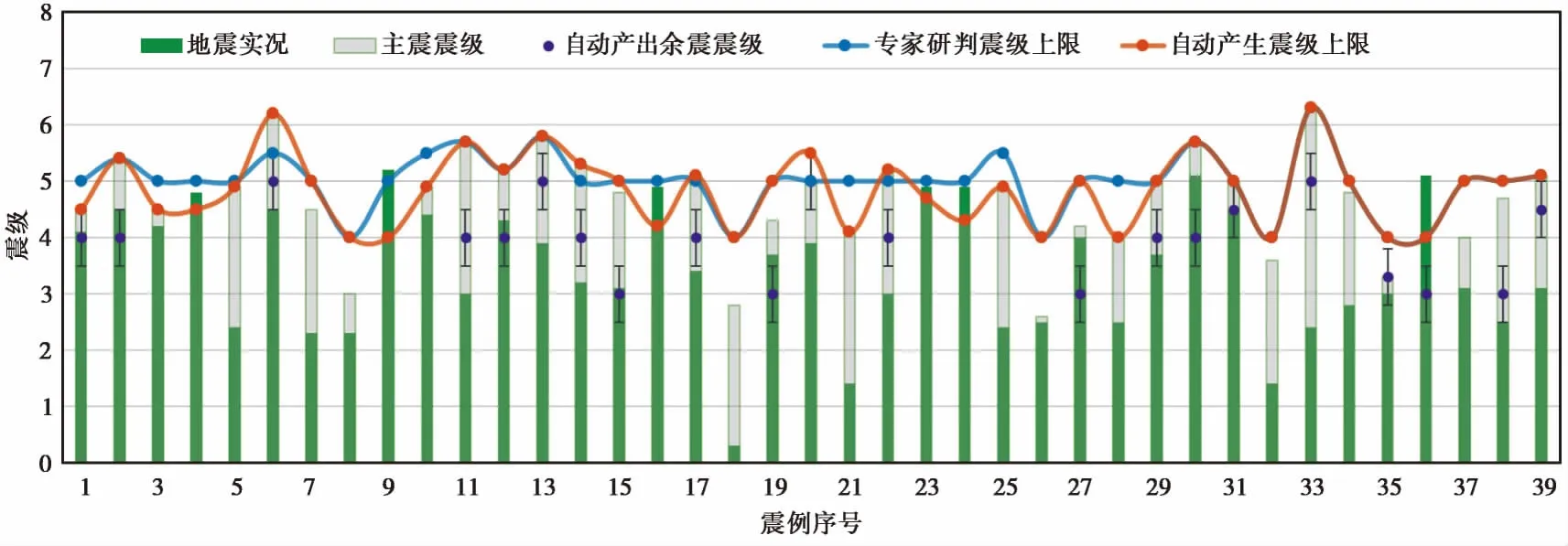
图 6 自动产出以及专家研判与地震实况的关系
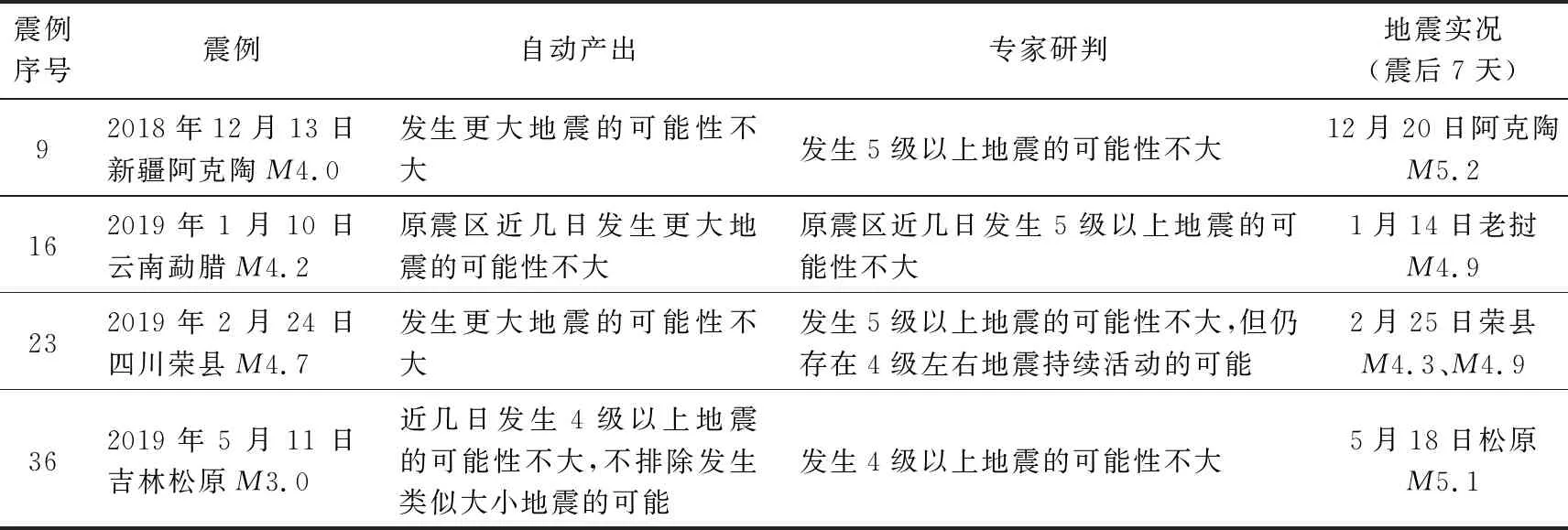
表3 突破自动产出震级上限的震例
以0.5个震级单位为间隔统计与“地震实况”的震级偏差(图7),可见“自动产出”震级偏差在±0.5较小范围内的震例数多于“人工研判”结果(图7 蓝框范围及蓝色箭头所指);对于大于1.0的较大震级偏差范围,“专家研判”结果的震例数多于“自动产出”(图7 红框范围及红色箭头所指)。这意味着,若仅就与地震实况的吻合程度对比来看,“自动产出”结果略好于“人工研判”结果。由全部39次震例预测的后续地震震级与7日内实际最大余震震级的对比来看,“自动产出”和“专家研判”结果的平均偏差分别为1.04和1.19,尽管总体差异不大,但“自动产出”仍略好于“专家研判”结果。
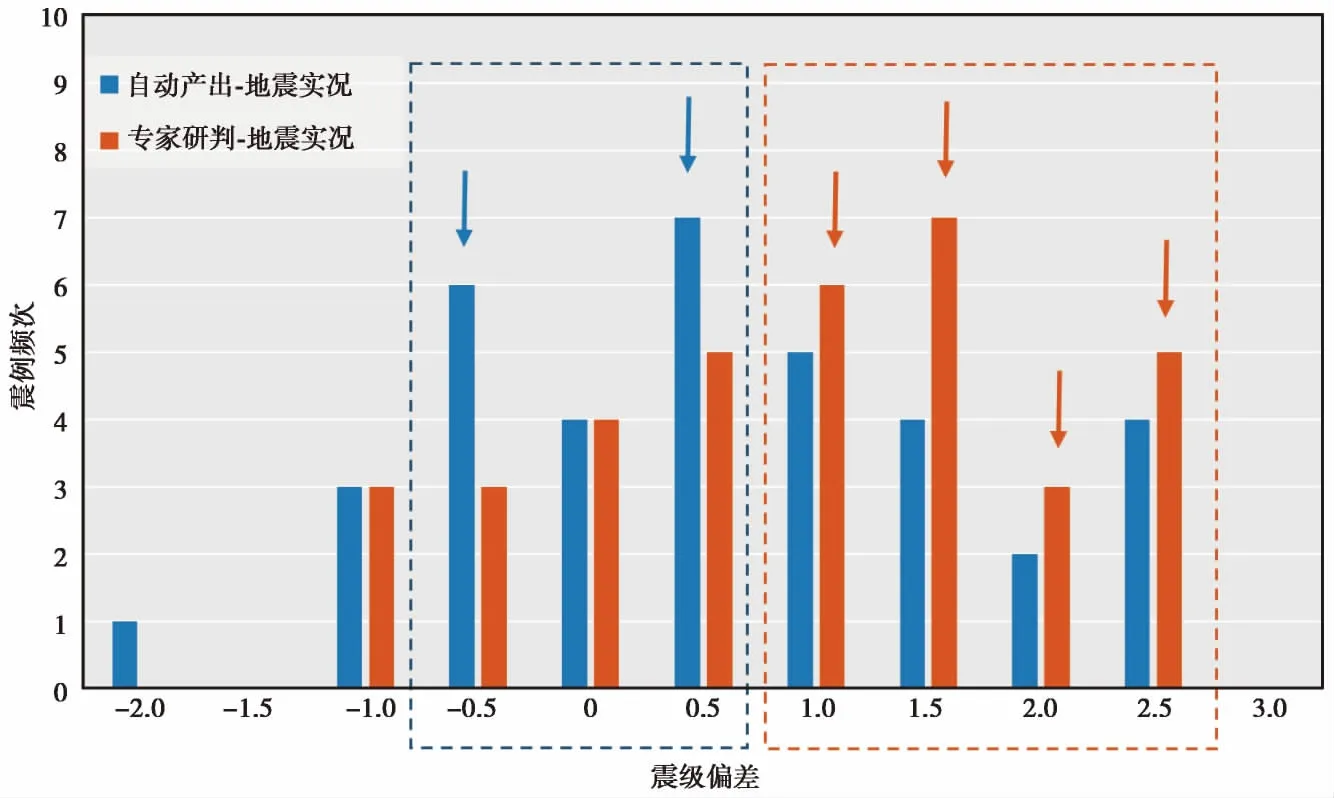
图 7 “自动产出”、“专家研判”与“地震实况”之间震级偏差统计
4 讨论与结论
(1)基于震例类比原则,开发了震后早期趋势判定技术系统。该系统为预报人员起草会商意见及《震情专报》初稿以及震后首次会商提供基础素材(各类检索统计结果、基础图件制作、PPT)。经过8个月的试运行,系统显著提升了中国地震台网中心对震后趋势快速研判的时效性,成为不可或缺的技术系统。在科学性方面,多数情况下自动产出与人工结果差异不大,自动产出与地震实况吻合程度略好于人工结果。
(2)针对震群型地震序列中的后续主震、中强地震序列中的较强余震,系统在自动产出意见以及文字表述上,仍存在较多问题。针对这些问题,一是必须收集更新资料,根据我国大陆地震序列特点,尤其是后续最大余震震级的认识,修正、完善震后早期趋势判定模型;二是继续充实、完善自然语言表述规则,尤其是针对震群型序列后续地震以及中强地震强余震的自动产出专报编写规则。
(3)由于目前地震序列类型自动检测算法尚在不断改进,序列资料的实时更新机制尚未建立。后续将继续深入研究地震序列特征,改进完善地震序列自动检测算法,实现地震序列基础数据库的自动更新。
(4)由于样本的限制,本系统无法穷尽所有的应用场景,目前基于专家经验的研判规则尚未完善,加之科技和技术的进步,实践要求也随之变化,因而本系统需要持续地修改和完善。更重要的是,能否引入机器学习等新技术,用于系统知识的自学习及判定规则的自我优化,是在现有理论认识基础上并基于现有数据信息条件下,系统能够发挥更大作用的关键一步。
致谢:《中国大陆地震序列目录整理》课题组为本文提供1970年以来“西5东4”序列数据集,主要完成人及所承担的区域数据的整理分别为:蒋海昆(负责人),赵小艳(云南),祁玉萍、龙峰(四川),聂晓红(新疆),王培玲(青海),冯建刚(甘肃),贾若(吉林),张帆(内蒙),孙业君(江苏),袁丽文(福建及中国台湾),黎明晓、薛艳、张小涛(大陆东部),徐长朋(山东),李玉铰(山西),鲍子文、倪玉红(安徽),郭蕾(河北),董非非(江西),王亮(辽宁),周晨(黑龙江);李盛乐、汪园园对全部序列数据进行了错误检测及格式校验;杜方、苏有锦以及以上大部分专家参与了判定规则的讨论;中国地震局地质研究所“活动断层探测数据汇交与共享管理中心”为本研究提供数据支持,在此一并感谢。
猜你喜欢
地震科学进展(2022年10期)2022-10-14
哈哈画报(2022年5期)2022-07-11
自然灾害学报(2022年2期)2022-05-10
成都信息工程大学学报(2021年4期)2021-11-22
气象科技(2021年5期)2021-11-02
奥秘(创新大赛)(2021年3期)2021-05-15
青海农技推广(2021年1期)2021-04-15
科技视界(2018年30期)2018-01-31
地震研究(2015年4期)2015-12-25
计算技术与自动化(2014年1期)2014-12-12
