
西装识别的深度学习方法
2019-04-25 06:40:18刘正东刘以涵王首人
纺织学报 2019年4期
刘正东, 刘以涵, 王首人
(1. 北京服装学院 服装艺术与工程学院, 北京 100029; 2. 北京工业大学 信息学部, 北京 100124;3. 湖南大学 信息科学与工程学院, 湖南 长沙 410082)
服装电子商务的发展为消费者带来很大的方便,同时积累了大量的服装款式图片,可作为服装图像识别算法的样本,进一步成为以图搜图系统的基础。另外,人工智能中的人脸识别、步态识别、指纹识别已趋于成熟,进一步需要对视觉内容进行深层次的感知,比如对图像中人物着装进行识别和评判、服装搭配智能推荐服务等。
由于服装形态和特征的复杂性,传统识别与分类算法的精度和场景适应性仍有待提高,图像分割和特征提取等工作需要人为的规定和大量的实验才能确定[1]。大部分算法研究主要通过使用图像轮廓提取、边缘检测或者多尺度角点检测来提取图像特征[2],再利用各种分类器(贝叶斯、支持向量机、人工神经网络等)进行模式识别[3-4]。由于服装的柔性,其显现出的多种形态给特征提取带来了很大困难,传统的特征抽取方法和分类识别模型面临着巨大的挑战。
深度卷积神经网络的兴起为复杂目标的识别提供了新思路。自AlexNet[5-6]在ImageNet大规模视觉识别挑战2012(ILSVRC)上取得成功以来,后续研究人员已经提出了更深的网络[7-8],并在ImageNet及其他基准数据集上实现高性能的实验结果[9-10],但这类实验一般是根据已有的经过标准化的图像样本集合(基准数据集),而非真实场景图像。
为此,本文提出一种基于电商平台实际图片样本库,利用深度卷积神经网络,快速检测图像中西装的目标,并能确定1个或者多个目标的位置,有效处理不同照明条件、目标大小、背景变化等因素的影响,为服装领域的机器视觉提供算法基础。
1 基于深度学习的目标检测
深度学习方法允许研究人员设计从原始输入到分类输出这样端到端的训练与测试系统,而不像传统的模式识别方法中特征抽取与分类识别阶段分开处理的手工方法。卷积神经网络(CNNs)作为图像识别任务中的特征提取器具有突出的特点,目前该思想已经广泛扩展到了机器人视觉、语音识别等多个人工智能领域[9-10]。
1.1 深度学习
深度学习与传统模式识别方法相比具有自动特征学习和深层架构的优势。
自动特征学习是深度学习的主要特征,算法从大数据样本中自动学习得到合适的图像特征,而不像传统方法一样使用手工提取。手工提取主要依靠算法研究人员的先验知识,提取到的特征集合维度和深度具有很大的限制。深度学习基于大量的样本数据利用机器学习的方法自动学习特征表示,可以包含成千上万的参数,而且在神经网络的框架下,特征表示和分类器是联合优化的,可最大程度地发挥二者联合协作的性能。
深度学习另外一个特征是深层的结构,意味着作为基本构成的神经网络具有很多层,多则可达到上百层。而传统的分类方法,比如支持向量机、Boosting等机器学习模型都是浅层结构,一般为几层。浅层模型提供的是局部表达,随着分类问题复杂度的增加,需要将分类空间划分成越来越多的局部区域,因而需要越来越多的参数和训练样本,以至于很难达到较高的识别效率。而深度模型能够从像素级原始数据到抽象的语义概念逐层提取信息,具有强大的学习能力和高效的特征表达能力,这使得它在提取图像的全局特征和上下文信息方面具有突出的优势,为解决服装识别等计算机视觉问题提供了思路。
1.2 目标检测的深度学习
目前,卷积神经网络是深度学习中目标检测的主要方法。随着硬件技术的不断提高,更高性能的深度网络也被提出,其中,一些先进的目标识别和分类算法得到了很好的实验效果。根据以往文献及应用分析,实验主要集中在3个学习框架:快速区域卷积神经网络(faster R-CNN)[11],基于区域的全连接卷积网络(R-FCN)[12]和单次多盒检测(SSD)[13],其他的框架通常与这三者类似。谷歌发布的Tensorflow目标检测API中,针对特定模型也提供了以上几种开发模型。
1)快速区域卷积神经网络。faster R-CNN的核心设计与原始的R-CNN一致:先假设对象区域,然后对其进行分类。不同点是用一个快速的区域建议网络(RPN)代替了之前慢速的选择搜索算法(selective search algorithm)。检测过程分2个阶段进行:在第1阶段,区域建议网络将图像作为输入,并通过特征提取器进行处理。中间层用于目标预测,每个候选目标区都有一个分数。为训练RPN,系统根据候选区域与标签区域的相交程度考虑候选区域是否包含对象;在第2阶段中,通过池化层、全连接层以及最后的softmax分类层和目标边框回归器(bounding box regressor)识别目标区域。
2)基于区域的全连接卷积网络。R-FCN框架提出使用位置敏感映射来解决平移不变性问题。这种方法类似于Faster R-CNN,但不是从区域建议的同一层抽取特征,而是从预测之前的最后一个特征层抽取特征(包含对象或成为其一部分的可能性较高的区域)。通过该技术的应用,减少了区域计算中使用的存储器的数量。文献[12]中表明使用ResNet-101作为特征提取器可产生比R-CNN更快的竞争性能。
3)单次多盒检测。以上2个模型均是分 2个步骤执行,首先使用一个区域建议网络来生成感兴趣区域(region of interest),然后再利用卷积网络对这些区域进行分类。SSD可在单个步骤中完成上述2个步骤,并且在处理图像的同时预测目标包围盒和目标分类。SSD模型通过前馈卷积网络来处理目标识别问题,前馈卷积网络产生固定大小的包围盒集合并且在每个盒子中存在对象类别的评分。
虽然每个网络模式都具有自己的特色,但他们都有相同的目标,即提高准确性,同时降低计算复杂度。3个框架在公开的图像样本库PASCAL VOC、MS COCO和ILSVRC数据集上都有测评[7,9],并且与其他方法进行了对比,但这些样本集是经过规格化处理的,是否能在实际图片中得到很好的应用需要进一步验证。真实场景包括拍摄的照片或者网络下载的图片,其特点是场景复杂,而且大小不同。这些与标准化的样本图片是不同的。由于目前并没有统一的服装图像样本库,需要创建一个新的样本库。据此收集了来自天猫网(www.tmall.com)的包含西装目标的500个样本图像。
表1示出利用3种算法对采集的真实样本集的训练结果,其中训练时间是采用20万步的迭代所花费的时间。可以看出,SSD方法在速度上是3种算法中最快的,在检测精度上可以和faster R-CNN相媲美,并有很高的召回率。
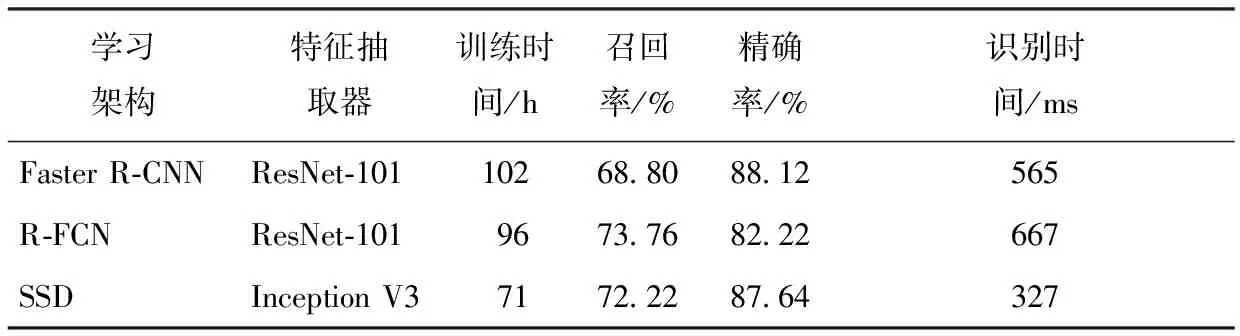
表1 3种方法的西装识别对比Tab.1 Comparison of suit recognition by three methods
SSD架构是如图1所示的一个开放系统,将规格化的300像素×300像素分辨率的输入图像利用多层卷积进行特征提取,经多层网络(特征提取和分类器)处理后,识别图像中目标类别并定位。其核心是在特征图上采用卷积核来预测一系列候选区域框的类别分数和位置。
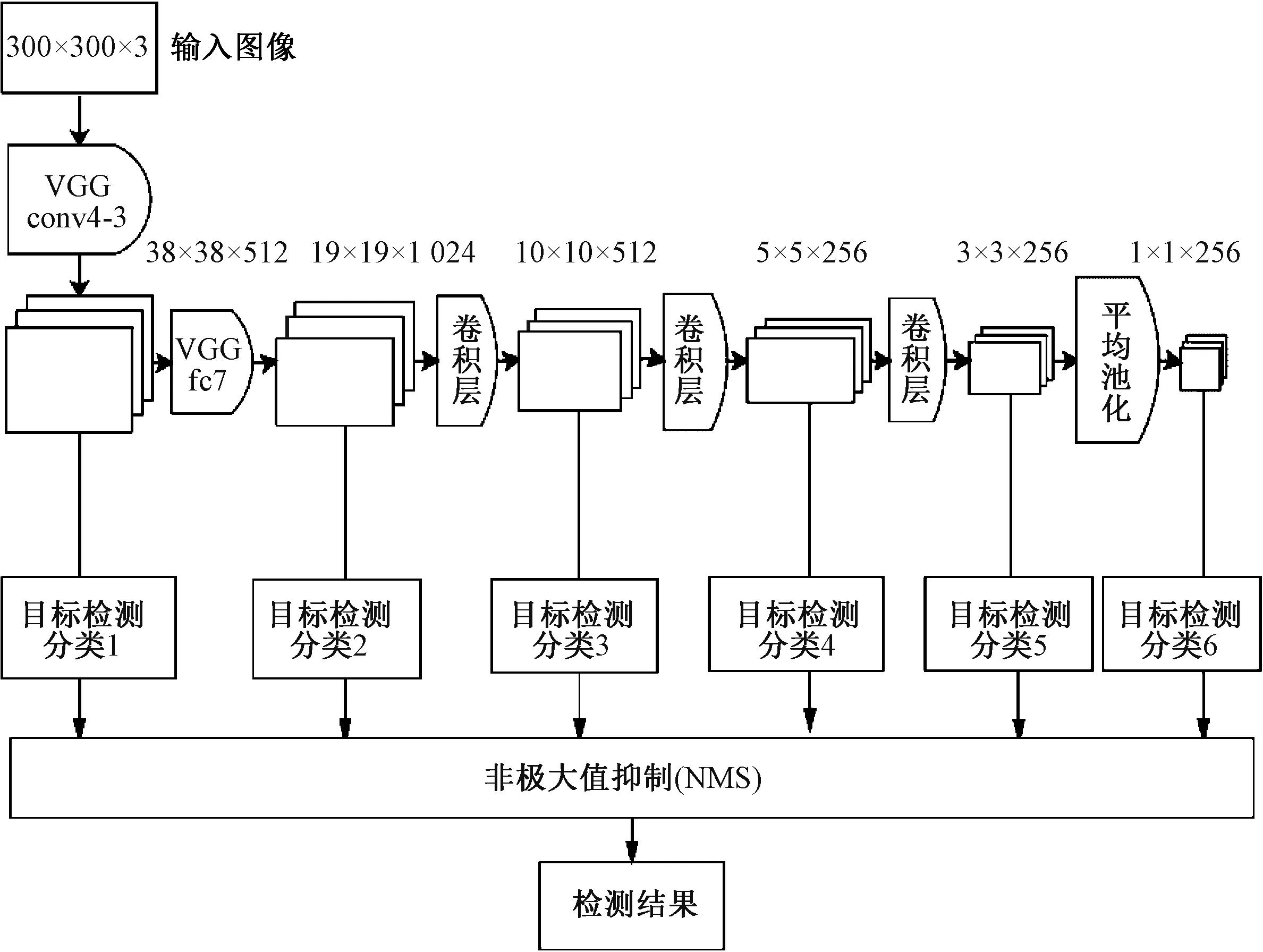
图1 SSD架构Fig.1 SSD framework
SSD使用了经典的VGG(visual geometry group)深度卷积网络。每组卷积都使用4×3的卷积核(以conv4-3表示)和fc7的全连接层。在训练高级别的网络时,可以先训练低级别的网络,用前者获得的权重初始化高级别的网络,可加速网络的收敛。
由图1可知,SSD各层中大量使用卷积获得的目标特征。图中标识出每个阶段生成的特征图结果,如38×38×512表示38像素×38像素的特征图,层数为512个。
对于上层的输入fi-1(x),利用卷积核gi(x)获得该层的特征图hi(x)。
式中:fi-1(x)为前一层的图像;gi(x)为卷积函数;hi(x)为卷积处理之后的特征图像。
为进一步降低特征的维度,深度学习采用池化层。SDD采用2×2的平均池化处理,相当于又一次的特征提取,数据量进一步减小,而且能够对输入的微小变化产生更大的容忍性,包括图像成像的平移、旋转和缩放等。
在卷积层和池化层获得特征图之后,进行目标的分类检测。为提高检测准确率,采用特征金字塔结构进行检测,在不同尺度的特征图上进行预测。这种架构设计,实现了端到端的训练,即使图像的分辨率比较低,也能保证检测的精度。检测时利用了4×3、6×2、7×2、8×2、9×2这些大小不同的卷积核,是为了能够检测到不同尺度的物体、达到多尺度的目的,如图2所示。
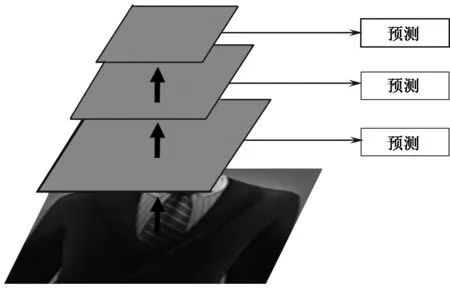
图2 金字塔型特征抽取Fig.2 Pyramid feature extraction
在训练之前,需要用包围盒和类标签手动标注每个图像中包含西装的区域。卷积网络目标识别输出是不同大小的包围盒边界框,与其相应的预测结果区域通过交并比进行评估。
交并比(IoU)定义为目标识别产生的候选包围盒C与真实目标包围盒G的交叠率,即它们的交集与并集的比值,如图3所示。最理想情况是完全重叠,即比值为1。loU的值定义为
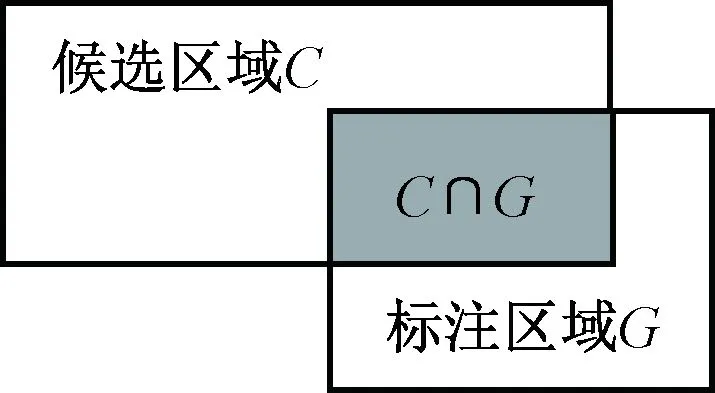
图3 交并比Fig.3 Inter section over union

图4 失败例子Fig.4 Failure cases. (a)Target failure; (b)Target loss; (c)Target overlap
在训练时,真实标注与预测包围盒按照如下方式进行配对:首先,寻找与每个真实标注框有最大的x的预测包围盒,这样就能保证每个真实标注包围盒与唯一的一个预测包围盒对应起来。之后将剩余还没有配对的预测包围盒与任意一个真实标注包围盒尝试配对,只要二者之间的x大于阈值0.5,就认为匹配。匹配成功的预测包围盒就是正样本(Pos),如果匹配不成功,就是负样本(Neg)。
SSD的损失函数为
L(x,c,l,g)=(Lconf(x,c)+aLloc(x,l,g))/N
式中:x为IoU值;l为候选包围盒的位置信息;g为真实目标包围盒的位置信息;c为候选包围盒的置信度,是一个权重参数,默认为1;a为用于调整预测误差和位置误差之间的比例,默认为1;N为与真实目标包围盒相匹配的候选包围盒数量,若N为0,则总体损失等于0;Lloc(x,l,g)为候选包围盒与真实目标包围盒的Smooth L1损失函数;Lconf(x,c)为置信损失函数,这里采用交叉熵损失函数。
Smooth L1损失函数定义为
在训练过程中,通过随机梯度下降以及反向传播机制不断减小损失函数值,从而使候选包围盒的位置逼近真实目标包围盒位置,同时提高类别置信度,通过多次优化,不断增强网络模型检测目标的效果,最终得到一个最优的目标检测模型。
1.3 失败分析
尽管SSD深度学习算法在原始样本的评估上表现出色,达到了87.64%的精确度,但在某些情况下也会出现评估困难,这是需要进一步研究的方向。需要说明的是,由于样本数量只有500个,对于充分训练是不足的,易引起过拟合。然而不同类别的服装形态具有明显的差异,弥补了样本数量不足的弊病。但在一些形变差异较大的情况下往往识别错误,导致误报或精度降低。
图4示出分析和整理后出现最多的3种识别失败的案例。图4(a)是将一些特殊区域误判为目标区域,这一般是因为样本数量太少,训练不够充分造成的;图4(b)是没有识别出来西装目标,因为大图像在标准化过程中被缩小,相应地,西装领部分变成了小目标,在卷积过程中小尺度的卷积未能很好地抽取其特征,SSD对小目标的识别率一直较低;图4(c)是识别区域的包含错误,在SSD算法中,全包含的区域以最外层的包围盒作为结果输出,但对于交叉区域的识别具有很大的重复识别问题。
2 西装图像的目标识别
2.1 样本的标注
图5示出西装常用的几种穿着形式。

图5 西装常用穿着形式Fig.5 Usual dress forms to suit. (a)With a tie;(b)With a bow tie; (c)No tie; (d)Not fasten
西服的领型一般分为平驳头、戗驳头或者青果领,一般是套在浅色的衬衫外面,有的配有领带,有的没有,还有的配有领结。从图像视觉效果来看,作为整体,西服的特征具有一定的明显性,无论什么领型都是具有大致统一的结构形式,而且与衬衫的色彩反差比较大,但是相比而言,无论是平驳头、戗驳头或者青果领,在图片上的细分特征并不显眼。
样本数据集主要包含2个方面:一是电子商务平台上大量的服装产品图;二是利用手机和摄像头拍摄的生活中的图片。因为产品效果图是摆拍,使用了专业的影棚和专业设备,特征是很明显的,而且更能体现现实生活的场景,所以样本包括了这2种不同类型的数据,这些样本的采集有助于将训练模型用于现实场景的目标识别工作。
西装目标的标注采用人工标注,鉴于特征的明显部分在于领子的外形和衬衫的搭配,所以标注的范围为如图6所示的白色包围框进行标签处理。V型的西装领所覆盖的区域是让机器进行学习的标注区。

图6 目标标注Fig.6 Labeling target box. (a)Box of tie; (b)Box of bow tie
2.2 SSD的改进
在失败案例中,图4(a)代表的类型可通过增加样本数量逐步解决,图4(b)、(c)代表的失败类型可设定被包含区域与外层区域的占比来决定是否舍弃被包含区域,而选择外层区域。因为在实际场景中,一个人的空间是较为独立的,多个服装彼此交叉的情况较少,即使在多人合影的图片中,人与人之间的距离较近,服装目标也会彼此交叉,但识别前面最大的目标的结果也是合理的。
SSD虽然采用了金字塔特征层次的思路,但对小目标的识别召回效果依然一般,如图4(b)所示。一般认为,小目标识别率较低是由于SSD使用类似conv4-3小卷积核的低级特征检测小目标,而低级特征卷积层数少,存在特征提取不充分的问题。这样带来一个问题,因为采集或者下载的图片一般都是大尺寸图片,训练过程开始前会标准化为300像素×300 像素尺寸,相应的特征区域就变得很小,即被识别目标变成了小目标,这样,对训练结果会有很大影响。
另外,SSD会将一些场景中的非目标区域误识别为目标。经过分析预判的原因可能是因为训练的样本缺乏这些场景的定义。尤其是当把模型应用于摄像头等实时采集的应用环境时,新的背景成了模型未训练的目标,会造成误判。针对该问题,处理的方式是:当将模型应用于一个具有新背景的应用场景时,首先预采集使用环境下的多角度图片,对模型进行增强训练,让模型熟悉新的环境。把这些需要让模型排除的背景样本称之为负样本。
针对以上2个问题,提出基于尺寸分割和负样本的SSD增强方法(DN-SSD)。主要目的是能够将SSD算法应用于任何实际场景,并能提高小目标的分辨能力。
基于尺寸分割的目的是防止小目标的消失,不是简单地将输入图片规格化为固定大小(如300像素×300像素)的尺寸,而是将大于300像素的图像按照300像素为单位进行分割,算法借鉴多视窗分割方法[14],但不是以图像的4个角为单位,而是分割的区域含有交叉,通过实验确定交叉的比例为图像的10%,分割数量s按照下式进行计算。
s=sc×sr
式中:c为图像的列数;r为图像的行数;sc为横向分割的个数;sr为纵向分割的个数;s为分割后的小图像个数。
基于此,一幅大于300像素的图像会被分割为具有交叉区域的多个图像,每个图像分别地独立进行SSD检测,避免了图像缩小过程中目标区域的消失。基于尺寸分割和负样本的SSD增强方法识别过程如图7所示。
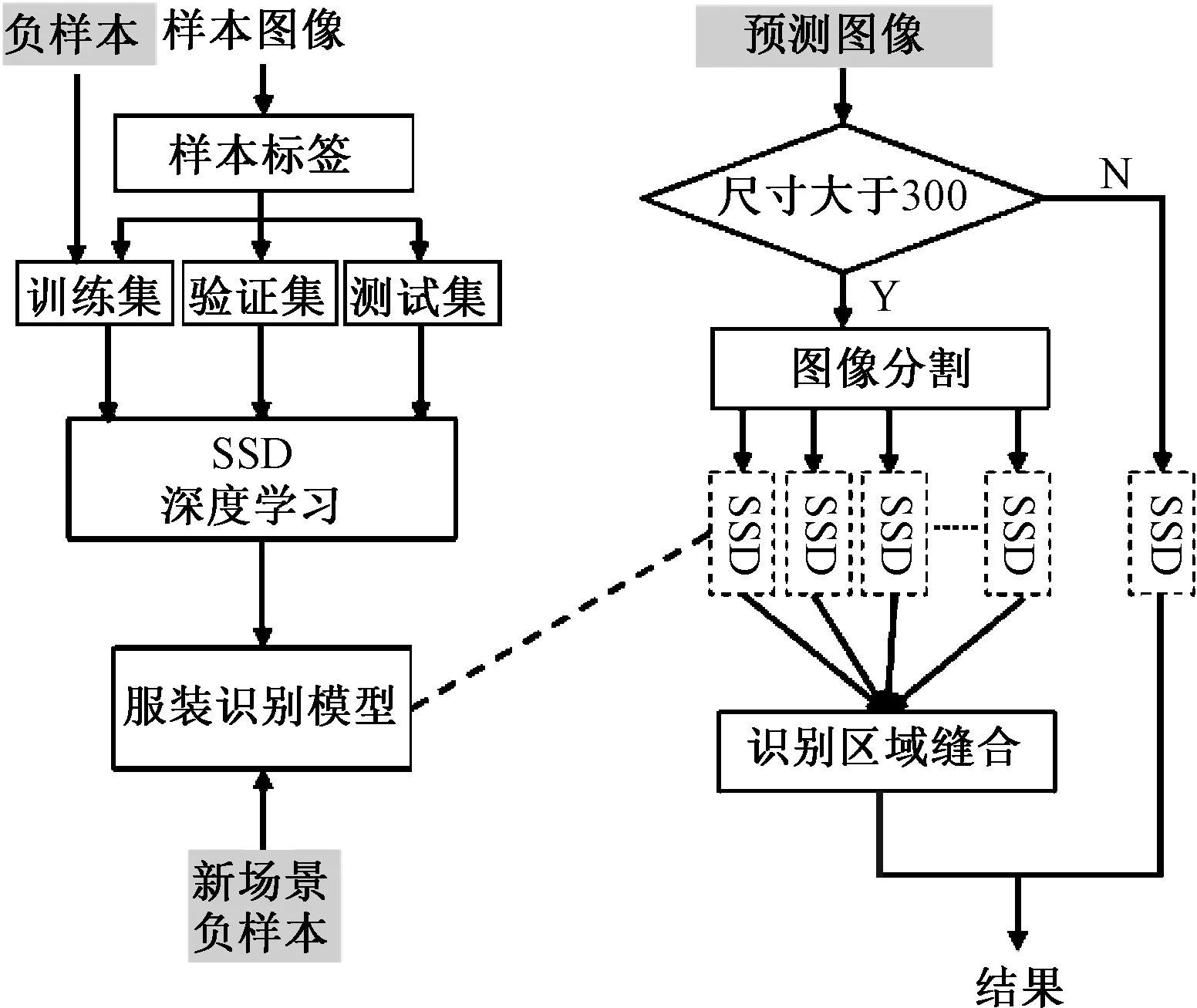
图7 SSD增强方法识别过程Fig.7 Recognition process of DN-SSD
其中,负样本的引入是为了排除实际应用中环境图像的影响,告诉系统什么样的内容不应该误识别为目标。负样本图像不包含任何实际目标,只是作为训练,以防过样本过少产生过拟合失败。

图9 识别的结果Fig.9 Detection results. (a)Single target detection 1; (b)Single target detection 2; (c)Multi target detection; (d)Small target detection
3 实验结果与分析
在500张样本集的基础上,采用编程语言Python 3.6,在谷歌深度学习框架Tensorflow 1.5中,基于HP ZBook笔记本电脑的Win10系统(Intel i7-4810 CPU,2.8 GHz,16 GB RAM)完成实验。在已收集的西装图像数据集上进行实验,所有图像均被标注西装所在的区域位置和大小。
DN-SSD模型是在SSD框架的基础上增加了尺寸分割,以保证西装目标不至于过小,并利用负样本来处理真实图像中西装的检测和识别。实验时数据集被分成80%的训练集,10%的验证集和10%的测试集。实验在训练集上进行训练,在验证集上进行评估,对测试集进行最终评估。由于数据集中的图像数量较少,为避免过拟合,针对应用场景又增加了50张负样本。
图8示出训练过程迭代到20万步时的损失函数值变化曲线。这证明了卷积网络有效地学习了数据,同时在大约10万次迭代中实现了较低的错误率。
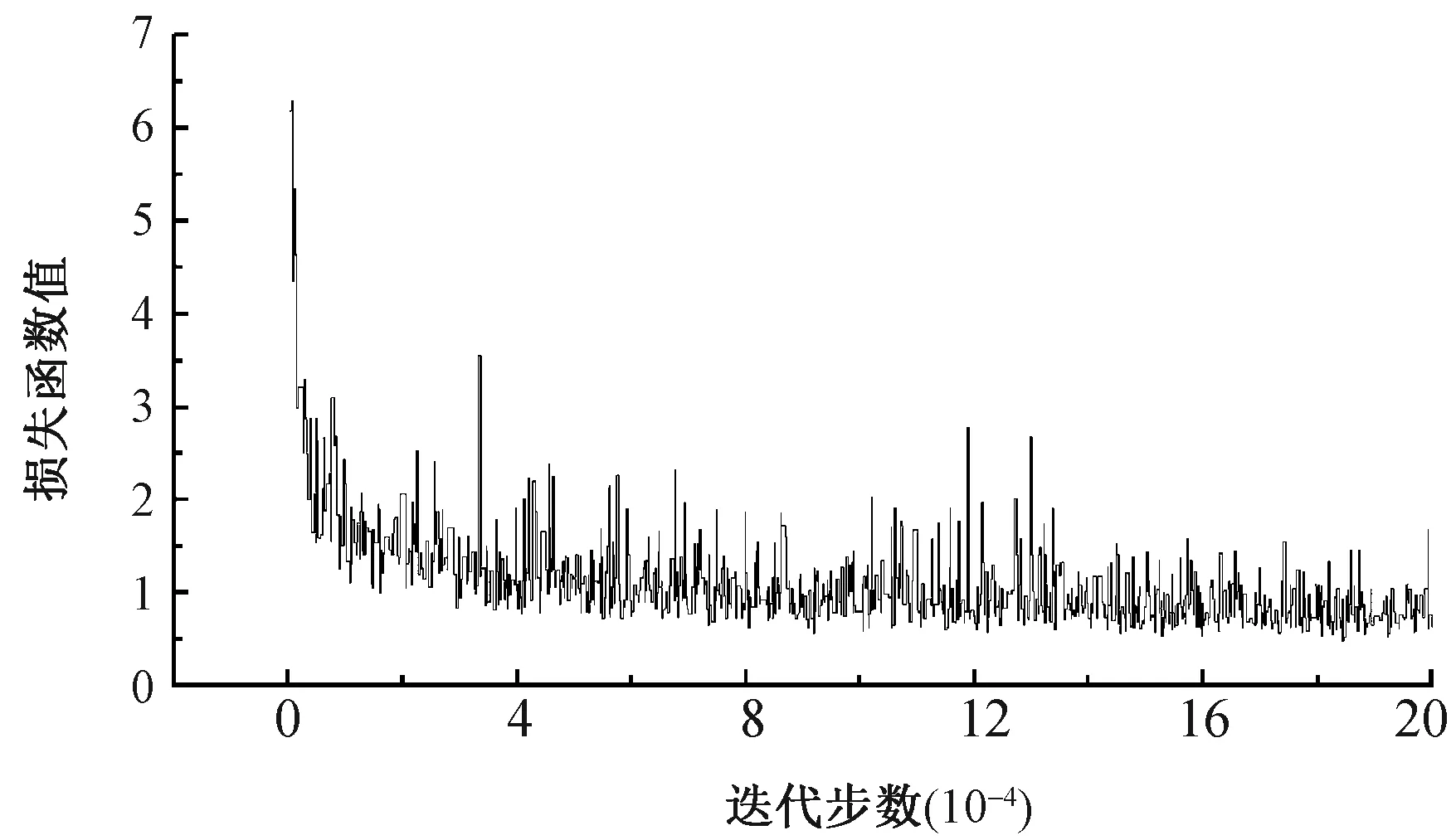
图8 训练过程中损失函数值曲线Fig.8 Curve of loss function value in training process
因为实验是识别西装这一种类别,使用召回率和精确率来评估是合理的,在提出的新的DN-SSD算法中,其识别召回率为77.54%,精确率为92.76%,识别时间为388 ms,总体性能要要优于经典SSD算法。召回率提高了7.36%,精确率提高了 5.84%,总体的识别时间变化不是很大,提高了61 ms,对于实时的运算可以忽略不计。究其原因是在小目标检测上提高了识别能力。实例识别结果如图9 所示,最后一张图是经典SSD无法识别的小目标。
相比于经典的SSD算法,本文采用的DN-SSD算法呈现出2点特点:一是可以检测出更多的物体,如图9(c);二是对于同样识别出的物体,其置信度更高,大部分的识别置信度都在90%以上。此外,深度学习系统的实施需要大量数据,并会影响最终的性能。为避免过拟合,本文输入负样本也提高了算法的召回率。
4 结 论
为解决机器智能对人类着装的视觉判断,本文提出一种基于深度学习的西装识别检测算法DN-SSD。基于经典的SSD算法,使用基于尺寸分割和负样本增强技术可获得更好的性能和效率,为电商平台或者实时监控系统对机器自动的着装分类识别提供一个实用而快速的解决方案。该方法与其他分类方法的主要区别在于,其应用场景并非是针对已有的、规格化的样本库,而是针对真实的网络图片或者各种摄像设备捕获的图像,通过使用GPU的实时硬件和软件系统进行处理。实验结果和比较也证明了基于深度学习的检测器能够以92%以上的成功率识别图像中的西装。未来进一步研究将集中在改善当前的结果上,并将算法扩展到其他服装款式的识别工作中。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
智族GQ(2020年9期)2020-10-26 06:57:16
电子制作(2019年11期)2019-07-04 00:34:38
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
智族GQ(2018年3期)2018-05-14 12:33:23
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
数学学习与研究(2017年3期)2017-03-09 18:12:42
Coco薇(2016年10期)2016-11-29 02:53:53
中国老区建设(2016年1期)2016-02-28 09:32:00
