
LDA特征扩展的多类SVM短文本分类方法研究
2019-04-25 01:59:16吴雨川
武汉纺织大学学报 2019年2期
郑 腾,吴雨川
LDA特征扩展的多类SVM短文本分类方法研究
郑 腾,吴雨川*
(武汉纺织大学 机械工程与自动化学院,湖北 武汉 430200)
针对短文本信息量少、特征稀疏的特点,提出一种基于LDA主题扩展的多类SVM短文本分类方法。在短文本基础上,利用LDA主题模得到文档的主题分布,将主题中的词扩充到原短文本的特征中,在特征空间上使用基于经典权重计算方法的多类SVM分类器进行分类。实验结果表明,在各个类别上的查准率、查全率和F1值都有所提高,验证了该方法的可行性。
短文本分类;特征扩展;SVM;LDA
随着网络技术的快速发展,手机短信、微博、广告文本等以文本表示的信息内容以极快的内容增长,而这其中又有很大一部分是短文本内容,如何从短文本内容中发现有价值的信息成为信息处理急需解决的问题。
由于短文本具有信息量少、特征稀疏、依赖上下文等特点,传统的空间向量模型以及KNN、贝叶斯等经典算法不能很好应用在短文本分类上。短文本的分类主要的难点在于特征非常稀疏[1]和上下文依赖性强。一些学者通过引入外部知识库来扩展文本的语义特征,丰富了词语间语义关系[2-3],但是它的计算量大,耗时大。因此,本文采用LDA主题扩展可以将对应主题下的词扩充到原来短文本的特征中,作为新的部分特征词,在新的特征空间上使用基于经典权重计算方法的多类SVM分类器进行分类。
1 LDA主题扩展的短文本分类
1.1 LDA主题模型
LDA[4]是一种三层贝叶斯概率模型,由词项、主题、文档组成,LDA三层模型如图1所示,若干个隐含主题随机组成一个文档,而每个主题又由文档中的若干个词语表示。因此,可将每篇文档代表为主题概率分布,而每个主题又代表词项概率分布。
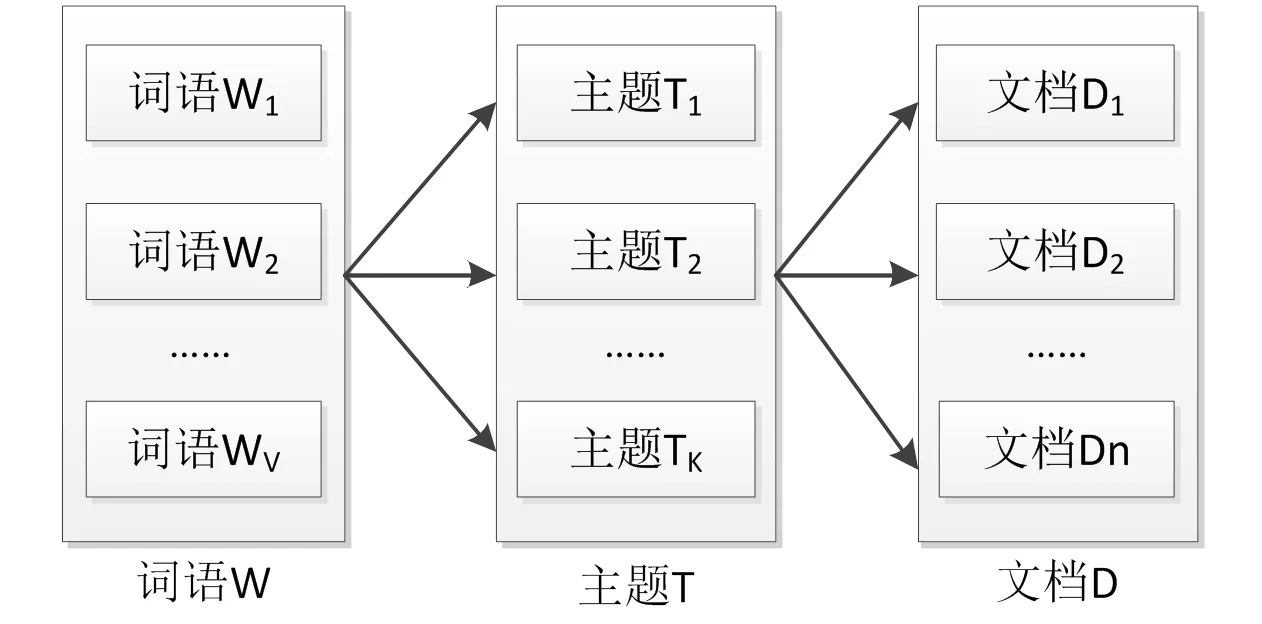
图1 文档-主题-词语关系
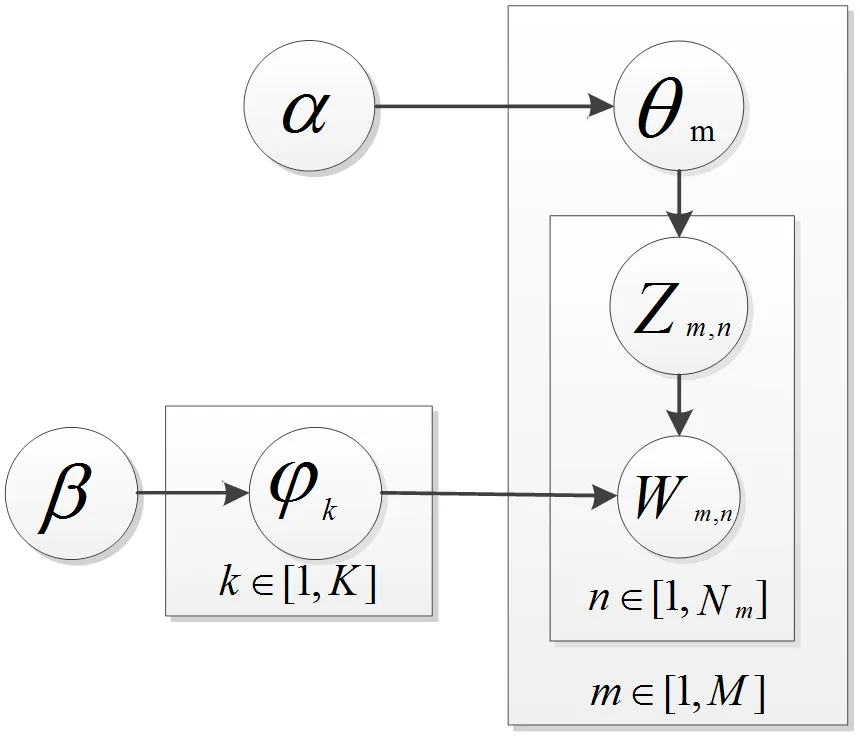
图2 LDA主题模型
LDA模型如图2所示,该模型引入两个超参数α,β,表示多维变量相互之间的权重关系。“文档—主题”的概率分布符合多项分布,“主题—词语”的概率分布也同样符合多项分布。
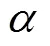
利用LDA主题模型对文档集主题模型的生成过程可以看作模型一种概率取样的过程,具体步骤如下:
不断重复上述过程,完成M篇文档的生成。依据LDA主题模型,可以写出所有变量的联合分布:
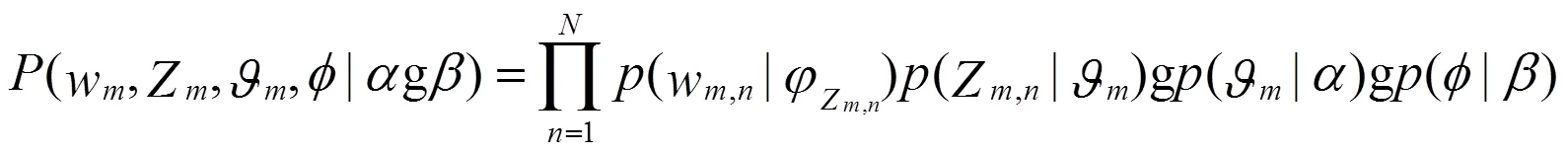
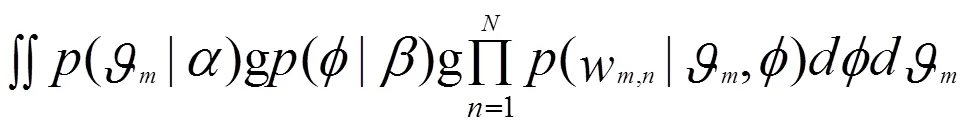
整个文档集W的分布为:
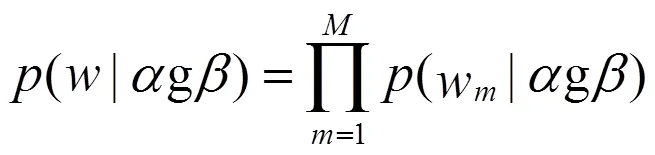
1.2 SVM简介
SVM是在高维特征空间使用线性函数假设空间的学习系统,它集成了最大间隔超平面、Mercer核、凸二次规划、稀疏矩阵核松弛变量等多项技术[5]。SVM在解决小样本、非线性以及高维模式识别中所具有的优势,取得丰硕成果。但是,传统的SVM是针对二分类问题提出的,现实中遇到的大多数问题是属于多分类问题。所以,在保证精度的前提下提出合理的多分类策略就成为当前的一个研究热点。按照采取策略不同,将多类SVM分类器的构建方法分为“一对一”[6]、“一对多”、二叉树算法、直接非循环图SVM等。其中,“一对一”方法是对多类中的任意两类都构建一个二类分类器,理论最严密,也是实际中使用最多的方式。具体做法是:选取2个不同类别构成一个SVM子分类器,共有k(k-1)/2个SVM子分类器,通过组合这些子分类器,利用特征权重进行分类投票,票数最多的一类即为该样本所属的类别。文献[7]比较了常见的几种多类分类支持向量机。
1.3 参数估计方法
LDA主题模型有两种主要的参数估计方法:变分推算方法和吉布斯抽样方法(Gibbs抽样方法)。由于Gibbs 采样的直接、易于理解和运行速度快的特性,成为最常用的估计参数的方法。本文中采用它对LDA模型进行估计,其采样公式如下:

Gibbs 抽样方法的步骤如下:
(1)随机初始化:训练语料库中任一篇文档中的每个单词w被随机分配一个主题号z;
(2)重新扫描语料库,根据每个单词w的采样公式(4)重新对其主题进行采样,并在语料库中对其进行更新;
(3)重复(1)到(2)步骤,直到Gibbs采样收敛;
(4)统计语料库的“主题-词”共出现的频率矩阵,该矩阵就是LDA模型。
1.4 卡方检验
卡方检验是一种假设检验方法,它是比较两个分类变量的关联性分析。词项t与类别c之间的卡方统计模型为[8]:
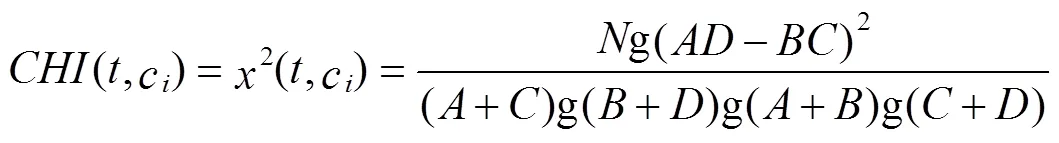
2 实验分类步骤
2.1 分类框架
具体分类框架如图3所示。
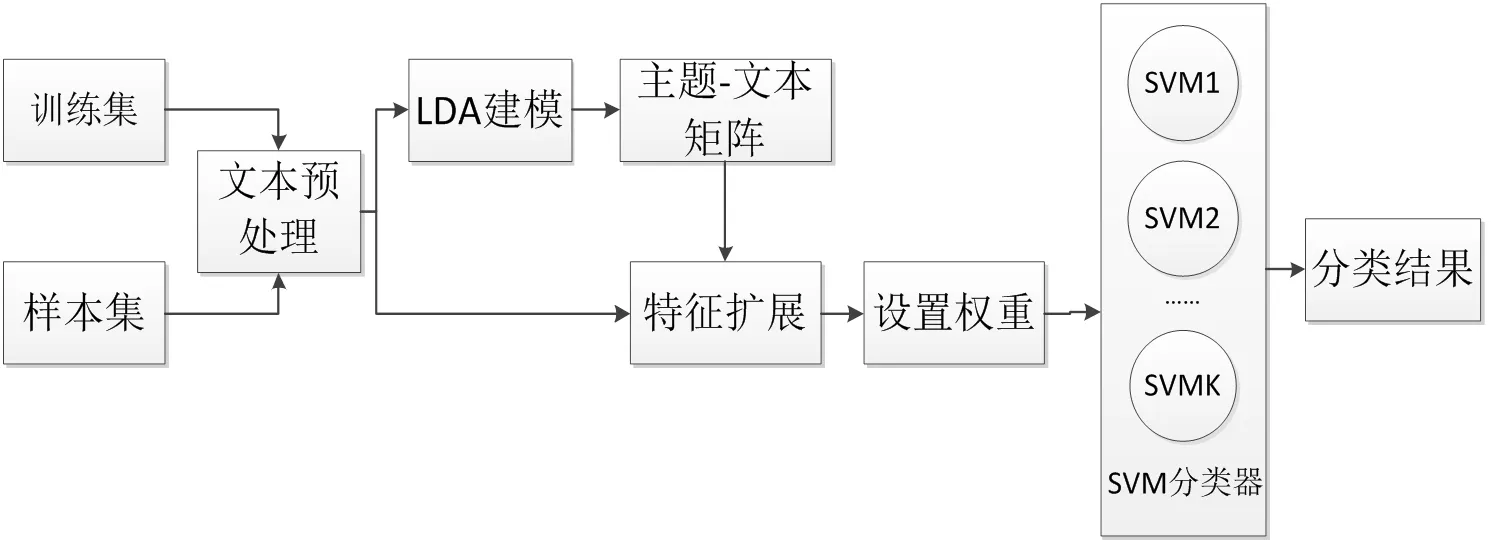
图3 基于LDA特征扩展的短文本分类框架
2.2 文本预处理
文本预处理是文本分类的第一步。首先,去除指定无用的符号,比如:数字、空格、标点等,可以通过Python的正则表达式(re)删除,让文本只保留汉字。然后,用jieba分词(结巴分词)工具进行短文本分词。最后,通过停用词表去除停用词,过滤文本中很多无效的词。
2.3 特征选择与向量表示
目前大多数中文分类系统都采用词作为特征项,如果把所有的词项都作为特征项,将会导致特征向量的维数非常高,快速完成文本分类将非常困难。特征选择是在表达文本关键信息的时候,能够使特征向量维度处于在一个合适的范围,使得在处理文本分类时候效率得到提高。文本特征选择的方法主要有:互信息[9]、信息增益[10]、文本证据权、卡方检验[11]等。本文选择卡方检验作为文本特征选择。对训练集中的每一篇文档经过文本预处理后,进行向量化,得到特征词典。
2.4 特征扩展
首先使用一个数量比较大的文档集训练LDA模型,得到“主题-词”分布矩阵。将训练好的LDA模型应用于语料集中的某一篇文档进行预测,得到“文档-主题”概率分布,将概率最大主题下的词语扩展到短文本初始特征中,形成新的特征向量。
2.5 多类SVM分类
在进行多类SVM[12]训练前,需要组合这些子分类器,利用特征权重进行分类投票,也即需要对LDA 特征扩展的空间向量模型中特征矩阵设置权重。一般最经典的常用方法是TF-IDF,具体计算公式如下:
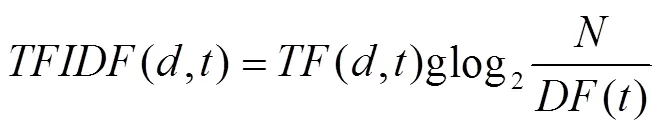
根据LDA特征扩展的空间向量模型,首先依据权重计算公式(6)计算主题特征词的权重,通过SVM分类器(LIBSVM)进行分类。
2.6 LDA模型主题数确定
将复旦大学提供的文本数据作为LDA模型的语料库。测试语料集与训练语料集的比例为1:2。先在训练语料集上训练出不同主题下的LDA模型,通过训练生成的LDA模型推断出测试语料集的“主题-词”矩阵分布。并在测试语料集上计算其困惑度。困惑度计算公式如下:

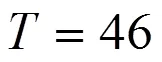

图4 三种方法的值对比
3 实验结果与分析
3.1 实验数据
本文数据来源于复旦大学提供的中文分类数据集,将其分为8类:教育、体育、科技、财经、艺术、旅游、历史、政治。训练语料集与测试语料集的比例为2:1。每一类随机抽取1200个文本,共9600个文本组成训练语料集。每一类筛选600个短文本,共4800个短文本组成测试语料集。
3.2 性能评估



3.3 实验结果
特征选择中,利用卡方检验公式(5)计算出每类词项的卡方值,将每一类前600个词项作为该类的特征,并合并为特征词典中。实验结果如表1所示:
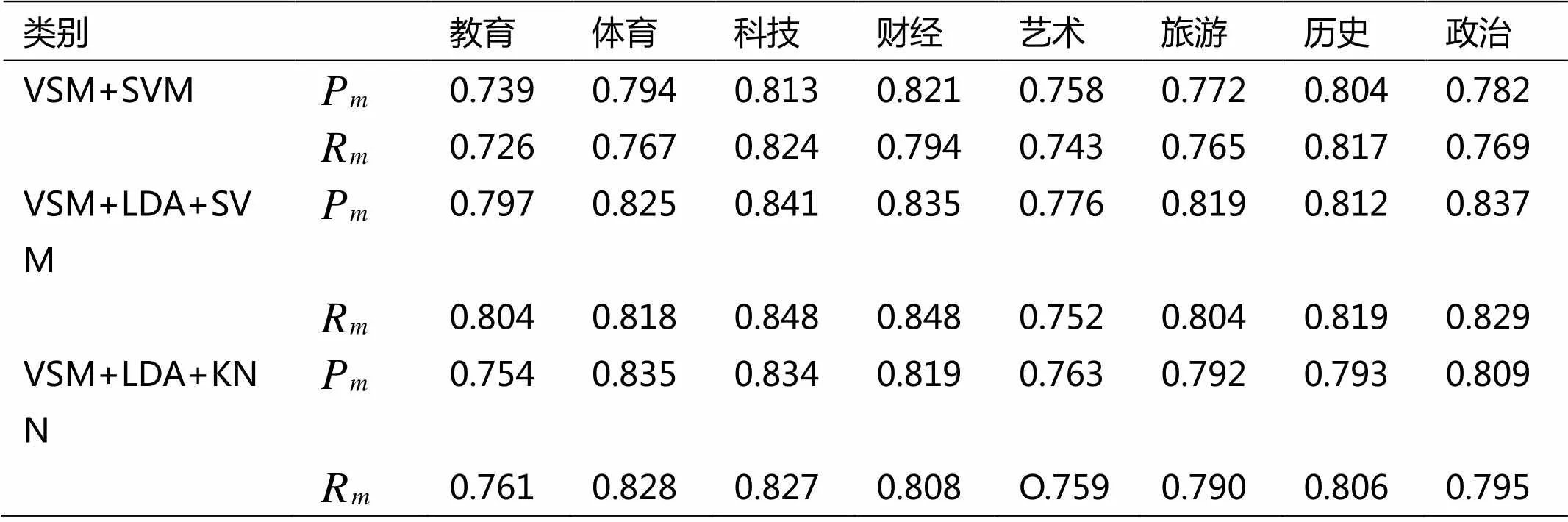
表1 实验结果对比
从表1中可以看出,本文所采用的VSM+LDA+SVM分类方法优于VSM+SVM和VSM+LDA+KNN方法。说明本文的方法是切实可行的。
4 结论
文本分类涉及许多复杂的技术,如文本表示,特征稀疏处理和算法决策。本文研究并改进了传统的特征选择方法,利用LDA模型进行特征扩展,丰富了短文本的语义信息,解决了短文本数据长度短、信息弱的问题。在多类SVM特征权重设置是基于TF-ID,在分类实现上还有很多不足地方,在后续的工作中,可以改进特征提取方法,设置新的特征权重,以期得到更好的分类效果。
[1] 张虹.短文本分类技术研究[D].大连:辽宁师范大学,2015.2-3.
[2] 朱征宇,孙俊华.改进的基于知网的词汇语义相似度计算[J].计算机应用,2013,33(8):2276-2279+2288.
[3] 王荣波,谌志群,周建政,等.基于Wikipedia的短文本语义相关度计算方法[J].计算机应用与软件,2015,32(1):82-85+92.
[4] Blei D M,Ng A Y,Jordan M I. Latent dirichlet allocation[J].Journal of Machine Learning Research,2003,(3):993-1022.
[5] 刘秀松.带有云化核函数的SVM文本分类方法[J].科技情报开发与经济,2007,17(30):13-15.
[6] Ulrich Krebel.Pairwise classification and support vector machines[M].In B.Schuolkopf,Burges C J C,Smola A J,editors,Advances in Kernal Methods:Support Vector Learning,Pages,MITPress,Cambrige,MA,1999.255-268.
[7] HSU C W,LIN C J.A comparison of methods for multiclass support vector machines[J].IEEE Trans on Neural Networks,2002,13(2):415-425.
[8] 闫健卓.基于X2统计的改进文本特征选择方法[J].计算机应用研究,2012,29(7):2454-2456.
[9] 刘海峰,姚泽清,苏展.基于词频的优化互信息文本特征选择方法[j].计算机工程,2014,40(7):179-182.
[10]刘庆河,梁正友.一种基于信息增益的特征优化选择方法[J].计算机工程与应用,2011,47(12):130-134.
[11]裴英博,刘晓霞.文本分类中改进CHI特征选择方法的研究[J].计算机工程与应用,2011,47(4):128-130.
[12]霍颖瑜,王晓峰.一种新的SVM多类分类算法[J].佳木斯大学学报(自然科学版),2006,24(4):476-478.
Research on the Classification Methods of Multiple SVM Short Texts based on LDA Feature Extension
ZHENG Teng, WU Yu-chuan
(School of Mechanical Engineering and Automation, Wuhan Textile University, Wuhan Hubei 430200, China)
Based on the short text and characteristics of sparse, this paper puts forward a short text classify method based on characteristics extend of LDA. This method used the LDA model to obtain the subject distribution of document, extended the word under the corresponding topic into the characteristics of the original short text as a new part of the feature word. A multi-class SVM classifier based on classical weight calculation was used. Experimental results show that the precision, recall and F1 values are improved in all categories. It verifies this model has some superiority in text categorization.
short text classification; feature expansion; Laten Dirichlet Allocation(LDA); SVM
吴雨川(1960-),男,教授,研究方向:模式识别、智能检测与控制.
国家自然科学基金面上项目(61271008).
TP391.1
A
2095-414X(2019)02-0072-05
猜你喜欢
时代英语·高二(2018年7期)2018-12-03 09:23:06
时代英语·高二(2018年3期)2018-06-06 05:24:36
电子测试(2018年1期)2018-04-18 11:52:35
海外华文教育(2016年1期)2017-01-20 08:21:58
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
电测与仪表(2014年15期)2014-04-04 12:05:20
