
基于区块链和人脸识别的双因子身份认证模型
2019-04-12 06:09吕婧淑操晓春
应用科学学报 2019年2期
吕婧淑,操晓春,杨 培
1.中国科学院信息工程研究所信息安全国家重点实验室,北京100093
2.32081部队,北京100093
身份认证[1]是指在计算机及计算机网络系统中确认访问者身份的过程,进而确定该用户是否具有对某种资源的访问和使用权限,保证系统和数据的安全.它是保障信息安全的重要手段.
目前,主流的身份认证方式分为以下3种:1)以静态口令为代表的根据用户所知道的信息来证明身份;2)以动态口令为代表的根据用户所拥有的东西来证明身份;3)以人脸识别、虹膜识别等为代表的根据独一无二的生物特征来证明用户身份.
第1种方式将静态口令中心化存储和管理,一旦泄库将导致用户的隐私信息被大规模暴露.例如,2014年约200张好莱坞女艺人照片(包括裸照等不雅隐私内容)被盗取并上传至各大社交媒体的网站[2].经调查发现,盗取者破解了中心化存储在服务器的用户名及口令,并利用破解后的用户名和口令冒充合法用户登录应用,获取隐私性极强的用户信息并以此牟利;第2种方式利用动态口令对移动终端设备有较强的依赖,一旦恶意用户得到合法用户的移动设备,便可通过手机号和动态短信口令冒充合法用户登录并窃取信息.第3种身份认证方式是以虹膜识别、指纹识别、声纹识别等为代表的高级生物识别技术.它基于用户个人独一无二的生理特征进行身份认证.因为生物特征具有唯一性、不可复制性,它比静态口令被忘记或破解的难度更大,比持有物被窃取或转移的可能性更低.因此,生物特征识别技术[3]目前被认为是以上3种身份认证方式中最可靠最方便、最快捷的.
区块链技术具有去中心化、时序数据、集体维护和安全可信等特点[4],具体如下:1)去中心化:区块链数据的验证、记账、维护和广播等过程都是基于P2P(peer-to-peer)分布式网络结构[5],采用纯数学方法而不是中心化机构来建立节点间的信任关系,从而形成去中心化的可信任的P2P分布式系统;2)时序数据:区块链采用带有时间戳的链式区块结构存储数据[6],为数据增加了时间维度,具有极强的可验证性和可追溯性;3)集体维护:区块链系统采用特定的共识机制保证所有节点均可参与新区块、新交易的验证过程;4)安全可信:采用哈希、数字签名等非对称加密方法对数据进行加密、签名,同时借助分布式系统各节点的PBFT或工作量证明或权益证明等共识算法形成强大算力来抵御外部攻击,从而保证区块链数据不可篡改和不可伪造.
以上这些特点使区块链非常适合存储和保护隐私数据,以避免因中心化机构遭受攻击或权限管理不当而造成的大规模数据丢失或泄露.任意用户数据均可通过哈希运算打包写入区块链,通过区块链P2P网络系统内节点的共识算法和非对称加密技术来保证安全性.
区块链技术和生物识别技术对身份认证有突出的优势,因此本文提出的模型利用了区块链与人脸识别两种技术,并在下节解释两种技术的原因.
1 相关工作
1.1 区块链与身份认证
区块链的种类包括公有链、联盟链、私有链[7].公有链是指任何节点均可参与的区块链,所有节点可以随时进入系统读取数据、下载完整的区块链数据(全部账本)、竞争记账、发送可获得有效确认的交易;联盟链是指某个机构或组织内部使用的区块链,各个节点通常有对应的实体组织,通过授权后才能加入或退出,每个机构或组织可运行一个或多个节点,数据只允许系统内的不同机构进行读写和发送交易,共同记录交易数据;私有链是指写入权限由某个组织和机构控制的区块链,私有链是完全封闭的,参与节点的权限会受到不同程度的限制,区块链的公开程度由组织根据自身需求决定.
从技术架构的角度可以将区块链这一技术的构成划分为数据层、网络层、共识层、应用层4层,如图1所示.
数据层包括区块、链式结构、非对称加密、哈希算法.链式结构是区块与区块之间的连接方式,即当前区块的区块头部存储前一区块的哈希值;非对称加密[7]通常在加密和解密过程中使用两个非对称的密码,分别称为公钥和私钥.一般通过调用操作系统底层的随机数生成器来生成256位随机数作为私钥,公钥是由私钥通过Secp256k1椭圆曲线加密算法 生成65字节长度的随机数.使用该公钥加密区块体中的交易数据并在验证时用私钥解密;通过SHA256[9]和RIPEMD-160[10]对公钥进行双哈希运算生成20字节的摘要,再通过SHA256和Base58转换形成33字符长度的交易地址.
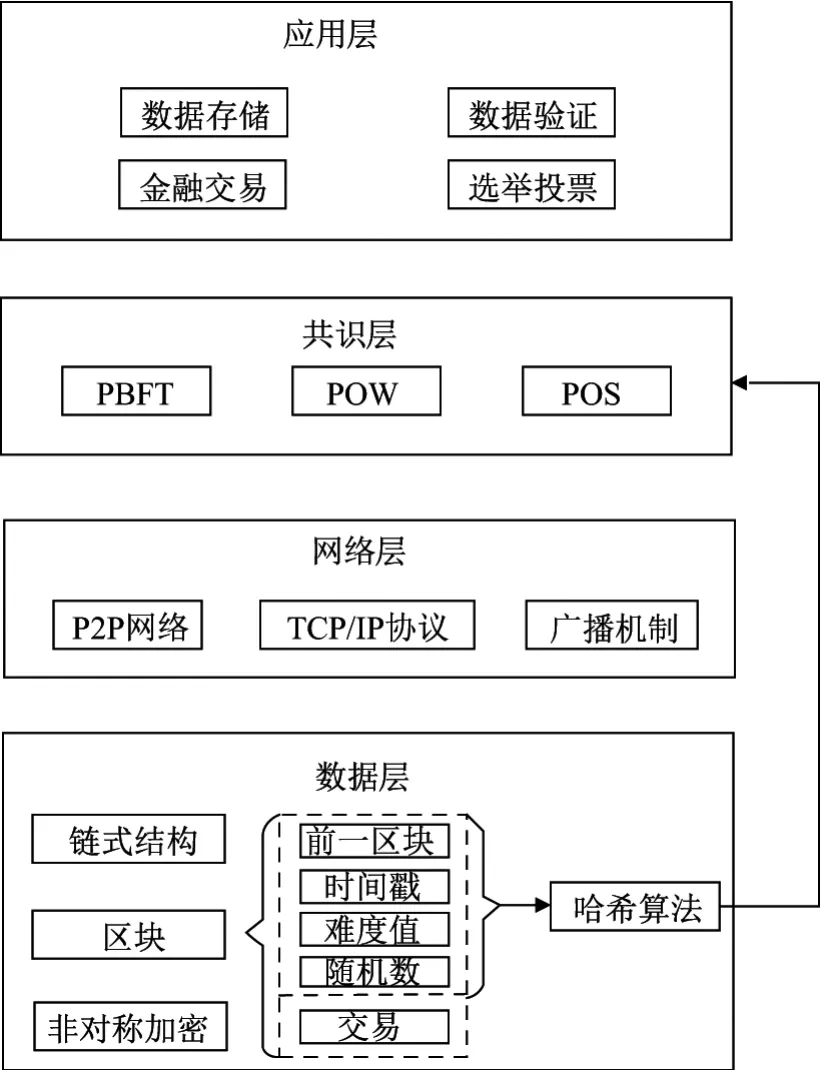
图1 区块链技术框架图Figure 1 Technical framework of blockchain
网络层封装了区块链系统的组网方式、节点连接的协议及消息的传播机制.基于P2P网络结构节点之间通过TCP 3次握手协议建立连接,每个节点最多可建立8个传出连接和117个传入连接;当新区块、新交易产生时,节点向与其建立传出连接的节点发送封装区块或交易数据的消息请求,以达到全网节点共同验证、记录新数据的目的.
共识层包括常见的共识协议,如实用拜占庭容错算法[11](practical Byzantine fault tolerance,PBFT)、工作量证明(proof of work,POW)和股权证明(proof of stake,POS).其中,公有链一般使用POW或POS作为共识机制,而联盟链和私有链一般用PBFT等共识算法,在超级账本Fabric0.6中主要使用该算法.假设区块链系统包含f+1个正常节点、f个故障节点和f个问题节点.PBFT算法的流程如下:
步骤1 选举主节点.全网选举出一个主节点主要负责新区块或新交易的生成;
步骤2 Pre-Prepare阶段.主节点将需要放到新区块的交易排序后存入列表并向其他节点广播该消息;
步骤3 Prepare阶段.每个验证节点按顺序模拟执行交易,签名并广播新区块的哈希值;
步骤4 Commit.一个节点收到其他节点发来的2f个哈希值都与其计算哈希值相同,则向全网广播一条commit消息;
步骤5 Reply.一个节点收到2f+1条commit消息即可提交新区块及交易到本地的区块链和状态数据库.
因此,PBFT共识算法相对于其他共识算法的效率和容错率更高.POW和POS共识算法分别以当前节点的工作量、拥有的货币量作为依据确定新区块的拥有者.
应用层包括数据存储、数据验证、金融交易和选举投票等应用.本文提出的模型就属于数据验证的范畴,这类应用已有一定的研究基础,如ShoCard[12]是一个将实体身份证件数据加密并签名保存在区块链上的服务.用户用手机扫描并上传身份证件,ShoCard应用将证件信息加密后保存在用户本地,将数据指纹保存到区块链.区块链上的数据签名受私钥控制,只有持有私钥的用户才有权修改,即便ShoCard亦无权修改.
区块链的节点若仅拥有匿名地址而无法证明自己的身份,那么其应用场景相对狭窄.因此,将区块链技术应用于身份认证场景不仅能解决传统身份认证方式存在的问题,还能拓展更多的应用范围.
1.2 人脸识别与身份认证
计算机人脸识别技术是一种用计算机分析人脸图像,进而提取出有效的识别信息,可用来“辨认”身份的技术[13].该技术输入一张或一系列含有未确定身份的人脸图像及人脸数据中若干已知身份的人脸图像或相应的编码;输出是待识别人脸与人脸数据库中一系列已知身份人脸的相似度得分.可根据该得分设置阈值以判断待识别人脸的身份.
人脸识别算法的发展历史可以分为3个阶段.第1阶段为1964–1990年,这一阶段人脸识别通常仅作为一般性模式识别问题来研究,所采用的主要技术方案是基于人脸几何结构特征(geometric feature based,GFB)的方法[14].第2阶段为1991–2013年,这一阶段诞生了若干经典的传统人脸识别算法,如eigenface[15],同时以SVM[16]为代表的统计学习理论也在这一时期内被应用于人脸识别与确认中.第3阶段为2013年至今,这一阶段的代表是各类基于深度学习的人脸识别算法,如基于深度CNN的DeepFace算法[17]、DeepID算法[18]、FaceNet算法[19],SphereFace算法[20]提出的角度损失函数,为了进行深度人脸识别提供了一个新的切入点.
人脸识别的流程如图2所示.其中,人脸A为待确定身份人脸、人脸B为已确定身份人脸、classi fier为人脸识别的某种算法.首先通过人脸识别算法分别将人脸A和B向量化为向量A和B;然后将两者连接为向量AB;最后通过classi fier计算向量AB的相似度,以判别人脸A与B的相似性,若相似,则输出1,反之输出0.
综上所述,本文将区块链和人脸识别两种技术结合为双因子身份认证的认证方式,即结合了根据用户所拥有的信息和用户生物特征两种身份认证方式.这样的双因子认证方式优势如下:一是利用了区块链技术去中心化、不可篡改、非实名化的特点,极大地降低了由于中心化存储发生泄库事件而造成用户信息的泄露;借助分布式节点的共识机制抵御恶意节点,确保用户信息一旦被写入区块链则无法更改或注销.除此之外,各节点在区块链上交易或通信用的都是各自公钥生成的地址,因此节点的虚拟身份无法与现实中的真实身份对应起来,保证数据公开情况下的隐私性.二是人脸识别的不可复制性、安全可信.在身份认证的3种方式中,人脸相对于静态或动态口令是独一无二的输入,显然仿制和造假的难度极高.人脸输入经过人脸识别模型的输出是二进制特征值,从输出到输入是不可逆的,保证了用户生物特征的安全性.三是双因子身份认证结合了以上两点优势,安全地存储了用户的基本信息和人脸特征,保证在验证时两者缺一不可,从而提高了身份认证的安全性.
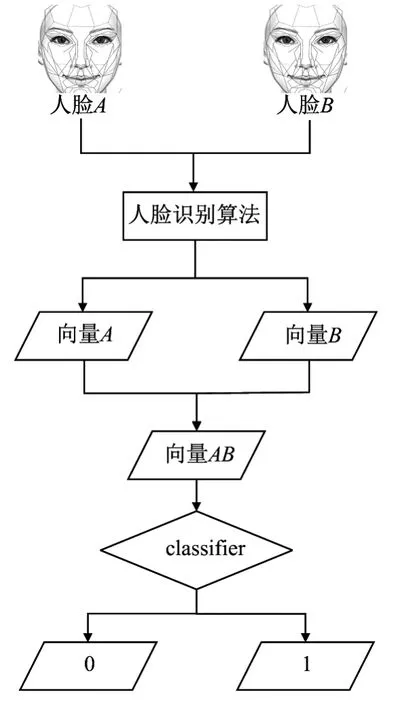
图2 人脸识别流程Figure 2 Face recognition process
2 基于IdentiChain和人脸识别的双因子身份认证模型
2.1 问题建模
传统身份认证技术存在问题的模型如图3所示.问题模型的参与方为用户U、服务供应商S、攻击者A.三者的关系在于U向S请求服务,S需要验证该U的身份,因此U向S输入用户名和口令;S向服务器发起身份注册或身份认证的请求,服务器向数据库发起读写请求,对输入信息进行注册写入或验证计算,并返回是否注册成功或验证成功的结果;A利用漏洞攻击、SQL注入[21]等手段攻击服务器的数据库以获取存储隐私数据的文件,使用暴力破解等手段破解该文件以获得用户名及口令明文.
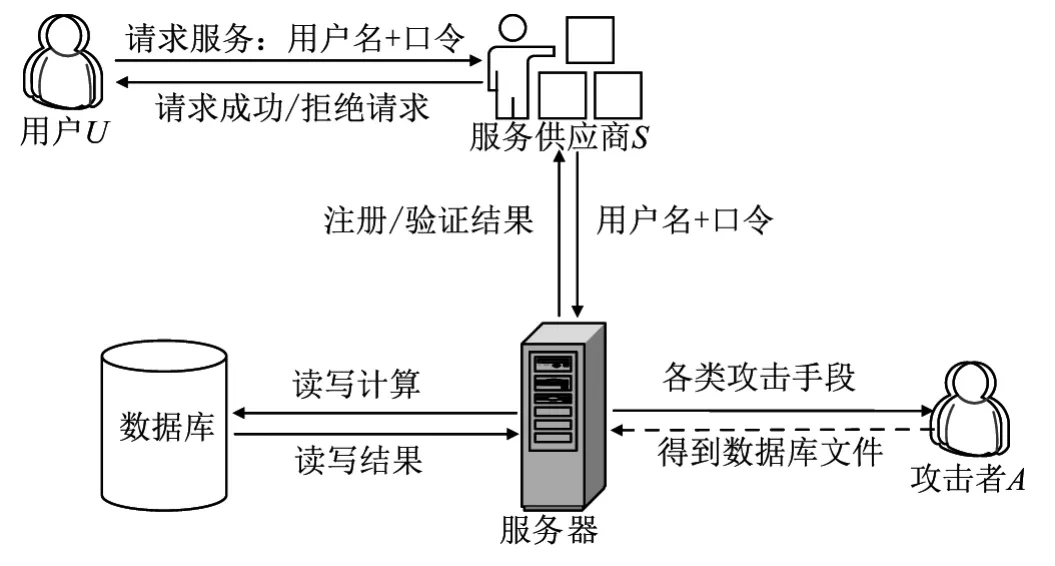
图3 问题模型Figure 3 Question model
2.2 模型框架
针对2.1节的问题模型,本文提出了基于区块链和人脸识别的双因子身份认证模型.该模型由3个参与方和两个技术组件构成.3个参与方分别是用户、移动端APP和服务供应商,两个技术组件分别是人脸识别神经网络模型和基于区块链的身份链IdentiChain.
3个参与方之间的关系如图4所示,用户通过移动端APP访问服务供应商的服务,因此用户需要成为服务供应商的合法认证用户.用户初次发起服务请求时需要完成注册操作,注册成功后服务供应商返回服务和公钥;用户再次请求服务时需要完成验证操作,验证成功后服务供应商返回服务和新公钥.
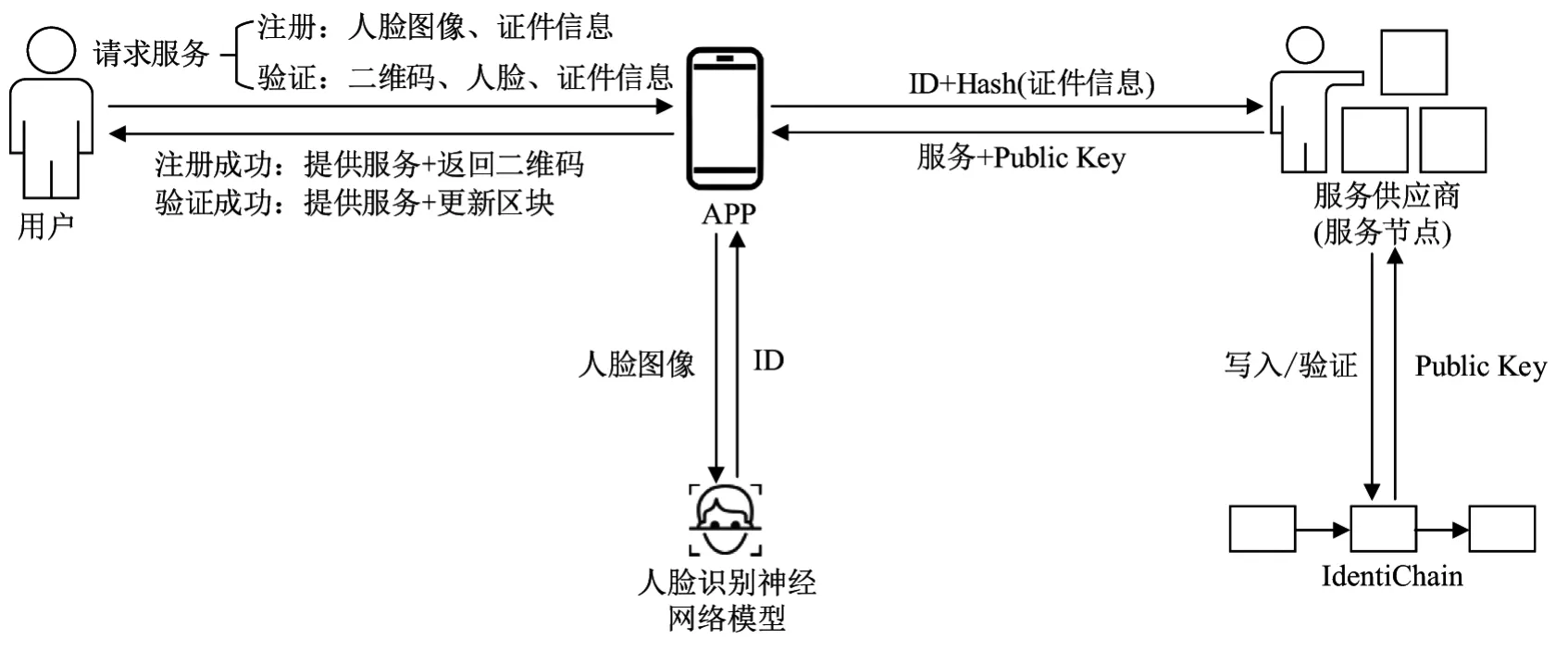
图4 基于IdentiChain和人脸识别的双因子身份认证模型框架Figure 4 Two factor authentication model framework based on IdentiChain and face authentication
两个技术组件分别与移动端APP、服务供应商有读写操作.其中,人脸识别神经网络模型接收APP输入的人脸图像,进行训练后输出该用户的人脸特征值ID并返回给APP.每个服务供应商都是IdentiChain的节点之一.APP向拥有注册权的服务节点输入ID和Hash(证件信息),服务节点在注册、验证等操作中进行不同的计算,如写入和验证.
2.2.1 人脸识别神经网络模型
本文模型是基于深度学习技术的SphereFace人脸识别模型[20].SphereFace模型是对open-set的人脸识别,即测试集中的数据没有出现在训练集中.测试集用输入的某query(待检测的人脸)来计算与数据库中的数据相似度,找出与query最为相似的人脸.这也符合本模型的场景,即用户每次请求服务时输入的人脸图像都不相同,那么验证时输入的query不存在于数据库已存的人脸数据集中.
不同于其他基于深度学习的人脸识别算法,SphereFace算法在对深度网络进行训练的过程中采用了一种改进的基于角度距离的损失函数,因此学习出的深度特征具有角度可分的特性,其性能优于采用欧氏距离度量损失函数(euclidean loss)或三元组损失函数(triplet loss)的传统度量学习网络.在训练过程中,假设训练数据集中第i张人脸图像对应的身份标签为yi,算法首先利用深度卷积神经网络(convolutional neural network,CNN)提取该图像的深度特征xi,然后用如下基于角度距离的损失函数进行网络的训练.
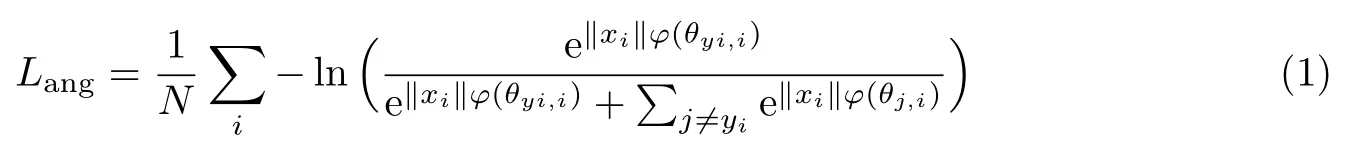
在网络的目标损失函数设计完毕后,SphereFace算法采用基于残差网络[22]的网络结构对网络结构进行精细设计,使网络在保持一定深度的同时不会产生梯度消失或梯度爆炸等问题而影响识别性能.该算法采用一种20层的卷积神经网络,具体结构如图5所示.图5上半部分是网络整体结构图,训练数据中的人脸图像首先经过4个由卷积层、PReLU激活函数层构成的残差网络单元,然后通过一层512维的全连接层,该层的输出即为人脸图像的特征,最后该特征和人脸图像的身份标签一起进入损失函数层,计算损失函数并进行网络参数的训练.图5的下半部分给出了4个残差网络单元的具体结构,其中每个方块代表1个卷积层––PReLU激活层的组合.以3×3,64,S2为例,3×3指的是卷积层的卷积核大小,64是该卷积层输出的特征图的数量,S2是指该卷积层的卷积核移动步长为2.在残差网络单元2、3、4中,同样的网络结构被重复串联多次,在图中用大括号和×2字样表示.
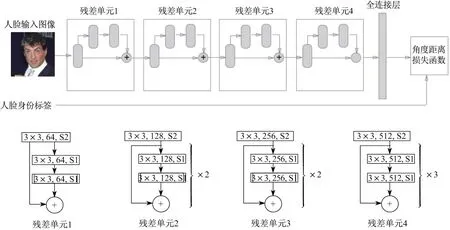
图5 SphereFace算法网络结构示意图Figure 5 Diagram for SphereFace algorithm network structure
给定上文描述的网络结构和损失函数后,SphereCafe算法用公开数据集CASIAWebFace[23]来训练网络.CASIA-WebFace数据集共有494 414张人脸图像,来自10 575个不同的人.在训练前,这些图像首先被水平镜像翻转,增加了训练数据的规模.在具体实现过程中,算法采用深度学习框架Caffe[24]实现网络结构和损失函数,训练过程采用4个GPU,每次迭代有128张训练图像被送进网络,网络的初始学习率为0.1,随后在第16 000和24 000次迭代时,学习率变为原来的1/10,整个训练共迭代28 000次.文献[19]给出了算法的更多实现细节及源代码实现.在训练完毕后,对给定的人脸图像即可利用深度网络提出具有良好区分度的深度特征.
在得到人脸深度模型后,人脸身份认证的流程如图6所示.在认证过程中,对给定的输入图像,首先利用MTCNN人脸检测算法[25]检测人脸及其特征点,然后对检测出的人脸,取双眼、嘴角和鼻尖共5个特征点位置,并利用这些位置信息求解变换矩阵,对人脸进行对齐操作.在获得对齐后的人脸图像后,将图像输入SphereFace模型进行特征提取,并利用特征间的余弦距离(cosine similarity)将提取的特征与已在身份库中的人脸特征进行相似度比较,假设相似度得分大于一定阈值,则认为匹配成功,否则匹配失败.
图6 人脸识别模型流程Figure 6 Face recognition model process
2.2.2 身份链IdentiChain
1.1节描述了区块链的3种类型,提出的身份链IdentiChain是基于联盟链的应用.文中开头指出传统身份认证方式存在的问题特点如下:1)用户身份信息的隐私性极高,去中心化地存储也要保证身份信息的安全性和隐私性,因此用户仅向少数信任的机构提供身份信息;2)注册请求具有高并发性;3)一次注册后用户再访问其他服务无需重复注册.
联盟链的特点如下:1)因为仅向其联盟成员开放全部或部分功能,所以联盟链上的读写权限、记账规则都按联盟规则制定,而非联盟节点无法获得任何形式的用户身份信息;2)新区块生成仅需通过2/3的联盟节点验证且可以容忍近1/3的错误节点,区块生成速度更快且容错率更高;3)联盟链由联盟成员共同记账、维护,某用户的身份信息一旦通过验证则被打包存入每个节点本地身份链的新区块中,由联盟节点共享.
由此可见,联盟链的特点可以有效地解决2.1节的问题.在身份链IdentiChain中,每个服务供应商都是联盟节点之一,因此也被称为服务节点,各服务节点共享同一个身份账本.用户在APP发起注册操作时,各服务节点使用PBFT共识算法选取某节点作为新区块的生成者,而让其他节点对主节点广播的身份信息(本模型的广播信息为用户人脸特征值)进行验证,一旦超过2/3的节点验证通过则完成注册,身份信息被写入新区块.IdentiChain的区块结构与比特币区块结构最大的区别如下:1)比特币的区块体存储交易信息,而IdentiChain的区块体存储证件信息;2)比特币使用的共识机制POW需要全网节点进行密集计算互相竞争新区块的拥有权,IdentiChain使用的PBFT机制没有工作量证明的竞争流程,提高了新区块的生成速度.
IdentiChain区块的具体结构如图7所示.每个区块分为区块头和区块体两部分.区块头包含PrevHash(前一区块的哈希值,按式(2)计算出的当前区块哈希值作为下一区块头部的PrevHash)、TimeStamp(时间戳)、ID(人脸特征值)、SignInfo(加密且签名过的证件信息);区块体包含HashInfo(证件信息的摘要).其中,ID是通过人脸识别神经网络模型计算出人脸特征值.
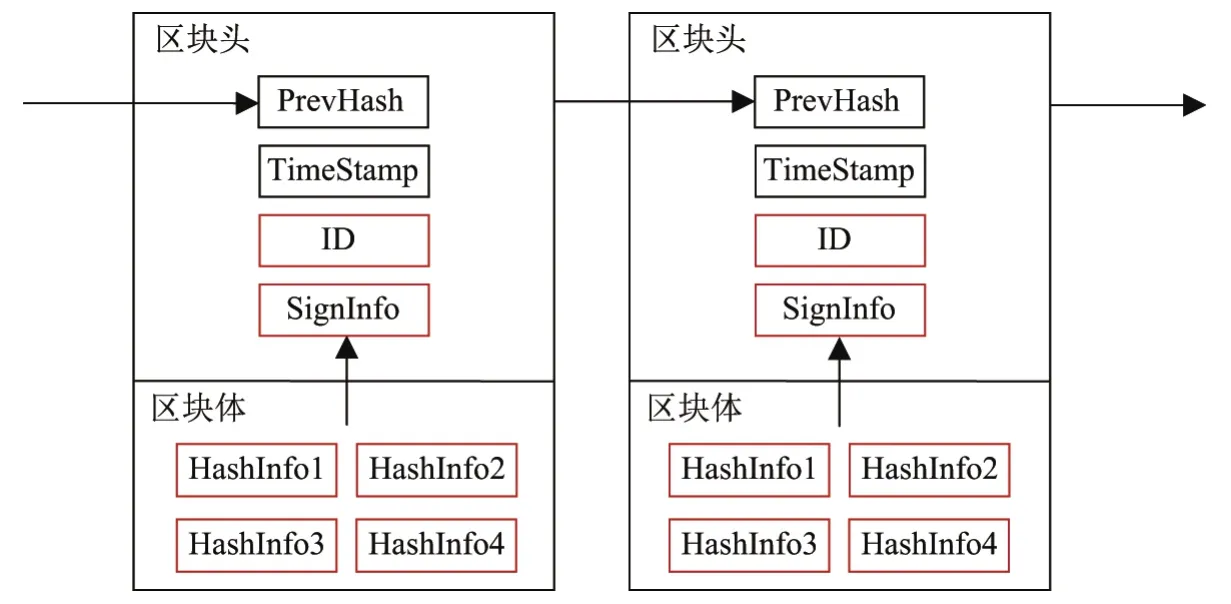
图7 IdentiChain区块结构Figure 7 IdentiChain block strcture
身份链IdentiChain中基于PBFT共识算法的步骤如下:
步骤1 移动端APP发送注册请求给身份链,在IdentiChain内部选举一个节点作为主节点;
步骤2 主节点向其他节点广播注册用户的ID值(降维后的人脸特征值);
步骤3 验证节点收到ID值后,根据该ID值计算哈希摘要并向全网广播;
步骤4 一个节点收到超过2/3的不同节点发来的ID摘要都与其计算的摘要值相等,则向全网广播一条commit消息;
步骤5 一个节点收到超过2/3的不同节点发来的commit消息,对移动端APP反馈并执行注册操作,在本地IdentiChain中的新区块写入身份信息.
主节点将ID、PrevHash和TimeStamp写入新区块的头部,将HashInfo(1~4)4项证件信息写入区块体.然后,对各项证件信息(HashInfo)按照Merkel树算法[26]计算得到SignInfo.Merkel树算法的计算过程如图8所示:每两项HashInfo通过哈希算法计算并合并得到HashInfo12和HashInfo34,HashInfo12与HashInfo34通过哈希算法计算并合并得到root值,即HashInfo1234.HashInfo1234通过RSA算法[27]签名生成SignInfo写入新区块的头部.其中,式(2)用到的哈希(Hash)算法为SHA256[9]算法.

2.3 模型流程
本模型用户和移动端APP发起的请求包括注册和验证.
2.3.1 注册
2.5 产褥期服用营养补充剂的情况 31.5%的调查对象服用营养补充剂或药品,年轻女性中有56.9%服用、婆婆/妈妈中仅有14.0%,两代人在营养补充剂的使用上差异有统计学意义(χ2=295.3,P<0.01)。所服用的营养补充剂主要是叶酸(56.4%)、钙(54.8%)及铁制剂(21.0%),少部分为复合维生素(13.7%)、矿物质(13.3%)、鱼肝油(10.9%)、DHA(7.9%)和锌制剂(7.3%)。
用户希望访问某节点的服务,由于任何服务节点都使用IdentiChain进行身份验证,因此该用户需要成为IdentiChain的认证用户,即进行注册操作.注册流程如图9所示,具体步骤如下:
步骤1 用户向移动端APP上传包含人脸的照片及证件信息.
步骤2 人脸识别模型训练出用户人脸特征值ID并将其返回给移动端APP.
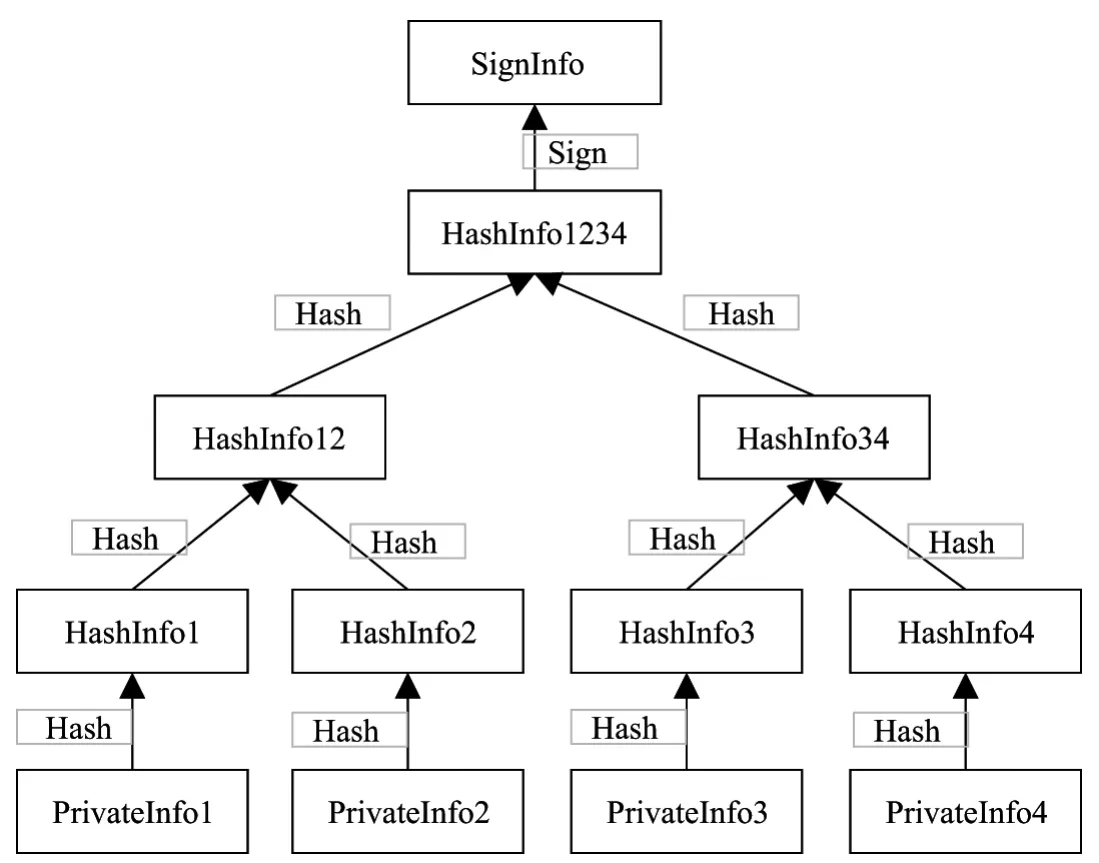
图8 Merkel树结构Figure 8 Merkel tree strcture
步骤3 APP将ID和经过Merkel树算法计算的证件信息HashInfo1234发送给用户请求的服务节点.
步骤4 选举一个节点作为主节点,该节点将ID向其他节点广播,其他节点计算ID的哈希摘要并向全网广播.当一个节点收到2/3不同节点发来的ID摘要都与其计算的相等,则向全网广播一条commit消息,一个节点收到2/3个不同节点发来的commit消息则达成共识;
步骤5 区块创建者将ID的摘要和签名后的证件信息SignInfo写入新区块中.
其中,SignInfo=PrivateKey(Hash(HashInfo1234)).服务节点返回签名所用私钥对称的公钥和服务给APP,APP将服务和封装了公钥的二维码返回给用户作为将来验证身份的凭证之一.
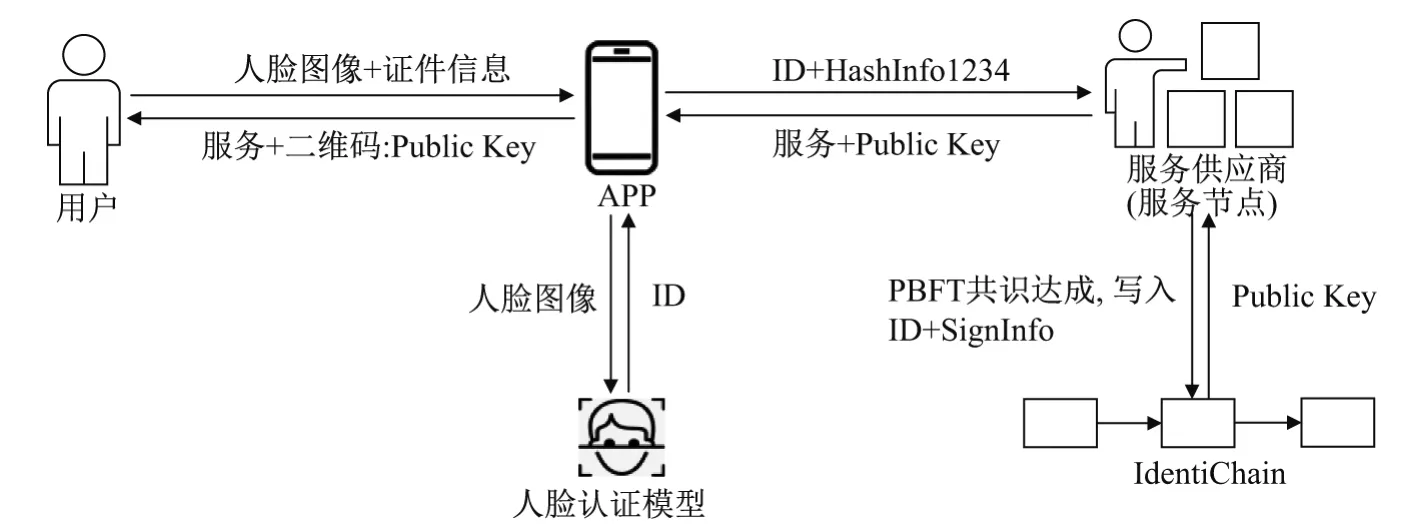
图9 注册流程Figure 9 Register process
2.3.2 验证
已经成为IdentiChain的注册用户希望获取某服务节点的服务,则需通过IdentiChain验证流程.验证流程如图10所示,具体步骤如下:
步骤1 用户向APP输入人脸图像、证件信息和包含公钥的二维码.
步骤2 APP将人脸图像输入到人脸识别模型中,该模型训练得到用户特征ID,并将ID返回给APP.
步骤3 APP利用Merkel树算法计算证件信息得到HashInfo1234,解析二维码得到PublicKey,并将HashInfo1234、ID、PublicKey发送给用户请求的服务节点.
步骤4 该服务节点在IdentiChain中遍历是否存在与HashInfo1234相等的PublicKey(SignInfo)(用公钥解密后的SignInfo).若不存在,则证件信息不符,验证失败;若存在,则该用户证件信息验证通过.
步骤5 计算APP输入的ID与该区块ID的相似度,若不相似则为非法用户,验证失败.若相似,证明其生物特征验证通过.
步骤6 计算Hash(PrevHash+TimeStamp+Nonce)是否等于下一区块哈希值,若不满足则验证失败;若满足,验证成功.
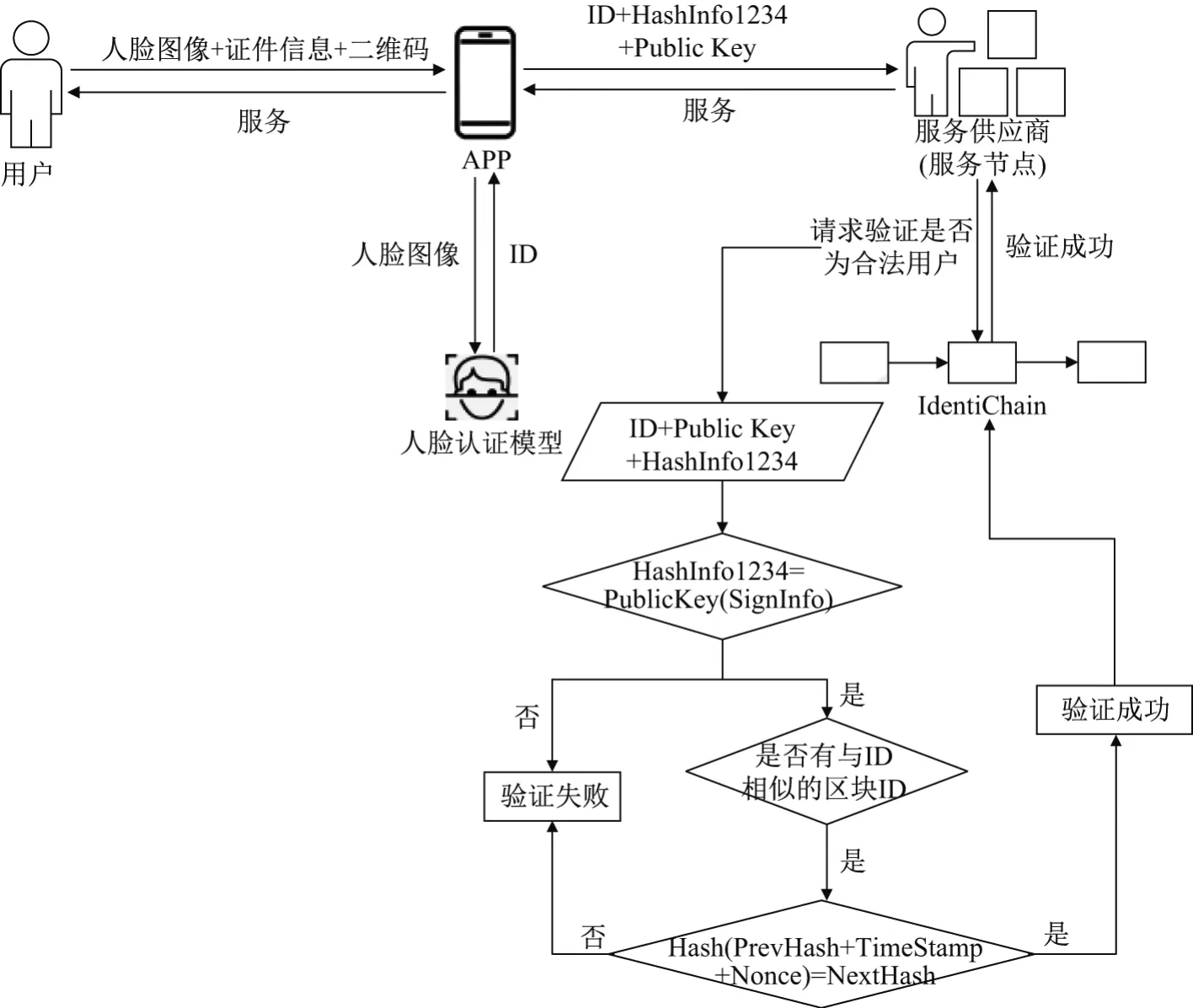
图10 验证流程Figure 10 Veri fication process
3 模型性能分析
为了证明基于区块链和人脸识别的双因子身份认证模型的有效性,本节分别分析其安全性和可用性.在两种极端情况下分别定性、定量地证明了模型的安全性.可用性分析中分别定量地计算了2.2节的两个技术组件的准确率、效率和存储空间的大小.
3.1 安全性分析
为了分析模型的安全性,假设以下两种极端情况分别为攻击者得到了合法用户的证件或通过某种攻击手段得到了本属于服务节点的IdentiChain入口.在两种极端情况下分析攻击者的攻击难度如下:
第1种情况:若攻击者获得了合法用户的证件原件或仿照原件伪造了假证件,那么攻击者也无法冒充合法用户验证通过.验证流程如下:1)需要用户上传的证件信息和区块链中已存的信息比对成功;2)需要扫描包含公钥的二维码才能在验证证件信息时验证通过;3)需要人脸图像通过人脸识别模型的验证.这相对于普通的单因子认证来说,攻击难度变成了3倍.在第1种情况下,攻击者只有流程1)的输入,但流程1)的验证成功也需要流程2)中的公钥配合.因此,在此种情况下攻击者是无法通过本模型的验证流程的.
第2种情况:若攻击者获得了本属于服务节点的IdentiChain入口,那它也无法通过区块中的SignInfo反向推算出每一项证件信息.这是由SignInfo的计算方式––Merkel树算法造成的.若攻击者想计算出原始证件信息,首先要尝试找到正确的公钥将SignInfo解密为HashInfo1234(假设公钥有m项选择需要遍历);接着尝试将HashInfo1234拆解为HashInfo12和HashInfo34;然后将HashInfo12拆解为HashInfo1和HashInfo2;将HashInfo34拆解为HashInfo3和HashInfo4.最后,暴力破解HashInfo1等4个单项哈希加密的信息.但由于哈希加密算法不可逆的特点,攻击者只能通过暴力破解等遍历的手段尝试找到4个单项HashInfo按照反向Merkel树算法计算出的SignInfo等于区块中已存的SignInfo.因此,其破解难度为n2×n2=n4(假设4个单项信息各有n项选择),除此之外还要遍历m个公钥尝试解密.暴力破解单项HashInfo和SignInfo的难度对比如表1所示.

表1 HashInfo与SignInfo破解难度对比表Table 1 Comparison of crack difficulty between HashInfo and SignInfo
若为了保护用户的人脸特征,可用DES[18]、AES[19]等对称加密算法对人脸特征ID进行加密,在计算相似度之前再解密,但这样会牺牲一定的效率.
3.2 可用性分析
由于2.2节中两个技术组件是影响本模型是否可行的关键因素(即人脸识别模型和IdentiChain),因此本节将对两者进行可行性分析.决定两者可用性的重要指标有准确率、效率和占用存储,分析结果如表2所示.
对于人脸识别神经网络模型,由于使用SphereFace算法[10],因此在LFW数据集上A-Softmax损失参数为4的情况下准确率为99.42%;在效率方面,完成1帧人脸图像的认证需要20 ms;每帧人脸图像经模型训练后得到的ID为1 024维向量,每维向量占用存储4个字节,因此1个ID共占用4 kB存储.
对于IdentiChain,由于证件信息和公钥在验证流程时都是保持不变的,只有人脸图像每次输入是不同的,并且需要用人脸识别模型训练出的ID在IdentiChain中遍历计算相似度.除此之外,本模型在验证流程时首先比对证件信息,而证件信息比对的准确率是100%,若证件信息验证失败则直接跳过后续的人脸识别.因此,本模型验证准确率大于等于人脸识别的准确率99.42%;在效率方面,每次验证流程先比对证件信息再比对人脸,假设比对一个区块内的证件信息需要的时间为ξms,IdentiChain共n个区块,因此最多共需ξ×nms的时间遍历n个区块,计算一次ID相似度需0.05 ms,验证一个用户共需(ξ×n+0.05)ms;在存储方面,除了存储人脸特征ID以外,还需存储SignInfo、前一区块的哈希值PrevHash和时间戳TimeStamp.由于一个ID占用4 kB存储,SignInfo占用85字节,PrevHash占用85字节,TimeStamp占用40 byte,因此一个区块占用存储4 210 byte,约为4.21 kB.
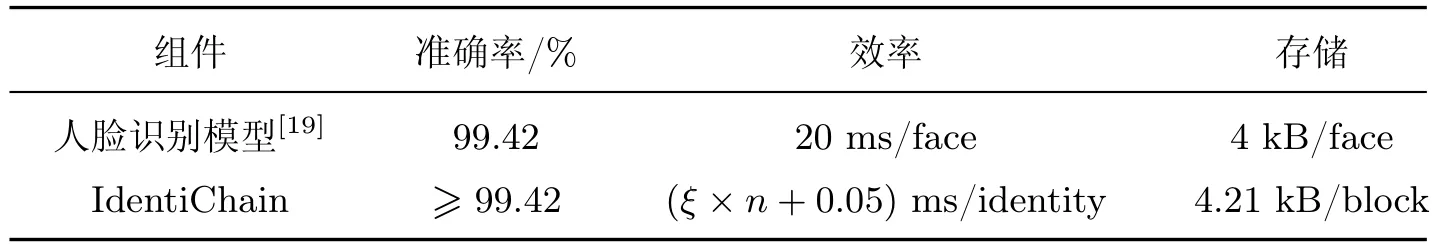
表2 人脸识别模型与IdentiChain可用性分析表Table 2 Analysis table for face recognition model and IdentiChain usability
4 结语
本文针对传统身份认证方式存在的问题,提出了一种基于区块链和人脸识别技术的双因子身份认证模型,解决了传统身份认证中心化存储而造成的泄库风险问题,降低了各服务供应商协作的成本.
本模型的创新点在于以下两方面:1)与传统中心化的身份验证方式相比,本模型采用去中心化的方式对用户信息进行存储与验证.传统的身份验证方式以静态或动态口令验证为主,一旦泄库或发生终端设备遗失事件,攻击者就可以获得存储用户名和口令的数据库文件,利用掌握的彩虹表、暴力破解等手段得到原始的用户名和口令.而本模型去中心化的存储和验证方式则避免了上述问题,即不会将用户信息存储到本地文件中,而是让所有联盟节点共享一个身份账本,虽然身份账本在联盟节点之间是公开的,但非联盟节点无法获得账本;2)与现有的区块链单因子身份认证方式相比本模型采用了双因子身份认证方式.业界已有的区块链身份认证机制通常是单一地将所需信息进行加密后写入区块链并返回区块链地址,但若攻击者得到该用户的身份信息及对应的区块链地址便能冒充其身份认证成功.但在本模型中,攻击者即使得到了某用户的身份信息及对应的区块链地址也无法认证成功,因为还需要通过人脸的生物特征认证.
本模型的意义存在于用户和服务供应商两方面.对普通用户意义如下,1)隐私信息的控制权更大,这是由于当某服务节点向用户发起授权邀请时,用户只授权该节点所需信息即可;2)注册成本更低.所有节点共享了记录用户ID和信息的IdentiChain身份账本,因此用户通过某个节点注册一次后无须再通过剩余节点注册.对每个节点的意义如下:1)去中心化地存储更安全.IdentiChain能完全避免中心化存储用户隐私信息的文件泄库;2)人脸识别更安全.因为生物特征是每个人独一无二的特征;3)维护IdentiChain的成本更低.经分析,本模型的安全性、准确率、效率与存储等可用性都得到了验证.
猜你喜欢
作文中学版(2022年1期)2022-04-14
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
学生天地(2020年31期)2020-06-01
电子制作(2019年14期)2019-08-20
动漫星空(2018年9期)2018-10-26
中国人民警察大学学报(2018年2期)2018-03-14
电子制作(2017年1期)2017-05-17
百科知识(2016年16期)2016-10-29
奇闻怪事(2014年5期)2014-05-13
