
融合社交因素和评论文本卷积网络模型的汽车推荐研究
2019-04-11 12:14冯永陈以刚强保华
自动化学报 2019年3期
冯永 陈以刚 强保华
汽车相对于普通生活用品,属于特殊商品,一是价格高,在购买时用户相对更谨慎;二是用户购买需求复杂,决策过程的总体时间相对较长.由于汽车自身具有复杂度高、交易和消费频次低等特点,所以在推荐任务执行过程中,会遇到用户相关领域知识匮乏、用户历史交易数据少、商品属性复杂等困难.
针对相关领域知识匮乏和商品属性复杂,研究者一般通过构建相关知识领域专家系统应对.这些专家系统通过与用户进行信息交互来准确获得用户的信息及需求,在此基础上结合已有的领域专业知识体系协同计算分析,从而对用户提供高效的推荐[1].然而,专家系统的构建过程相对繁琐,在系统构建初期,需要将领域专家提供的信息和知识体系转化成系统能理解的数据模型,这些数据模型主要包括专业知识库、规则集合等,这个过程需要花费大量的时间和人力.同时,在整理专业知识和规则时,由于人为将需求和属性特征关联,导致专家系统的知识库和规则库产生一定的片面性和主观性,最终对推荐结果形成干扰.针对用户历史交易数据少,一些研究者利用社交网络来获取用户更多的相关信息来弥补信息缺失,而另外一些研究者则使用项目信息(例如项目描述、简介、评论文本信息)进行处理.虽然在社交网络和评论文本这两个领域的研究已分别有了瞩目的成果,但是将社交网络和评论文本相互结合的研究却相对较少.社交网络为用户提供了丰富的社交信息,可缓解用户历史交易记录少的困难,而评论文本分析则可缓解用户相关领域知识匮乏和商品属性复杂带来的负面影响.
本文首次将评论文本与社交网络信息结合应用于汽车商品推荐领域,一方面构建购买用途需求社交圈,在此社交圈的基础上分析个人偏好和偏好相似度两种社交因素,并给出合理的量化计算方法.另一方面,以评论文本为汽车的附属信息,利用卷积神经网络提取文本隐特征.在设计汽车推荐模型时,融合社交环境因素和评论文本卷积网络获得的附加属性信息,从而提升汽车推荐系统的效果.
综上,在对社交网络和评论行为两方面的数据充分挖掘的基础上,设计汽车推荐模型这一研究在技术理论和现实应用层面都具有重要的意义和价值.
1 相关工作
近年来,研究人员提出了几种基于社会信任的推荐系统来提高推荐准确性.事实上,用户可以信任不同类别中的不同朋友.基于这一概念,最近有研究引入了“推断的信任圈”概念[2],用于社交网络中的推荐,考虑人际信任的影响.他们专注于推断类别特定的社交信任圈.然而,一些社交网络用户喜欢选择与他们的个人偏好密切相关的产品,很少考虑人际影响.研究者探索使用矩阵分解工具设计社交推荐从而解决“冷启动”问题.Jamali等[3]在社会网络中探索了这类方法,将信任传播机制加入到推荐模型中.潘涛涛等[4]利用置信系数区分评分值之间的可信度.信任传播已被证明是社会网络分析和信任推荐中的关键因素.Yang等[5]提出社会网络中“信任圈”的概念.他们的模型优于BasicMF[6]和SocialMF[3].用户之间的信任值由矩阵S表示,用户u与用户v的有向加权社会关系由正值表示.其基本思想是用户特征应该类似于他/她的好友的特征的平均值,其种类为c中的权重.除了文献[5]中的人际影响因素外,Jiang等[7]提出另一个重要因素:个人偏好.他们对中国的人人网数据集和腾讯微博数据进行了实验,结果表明社会语境因素(个人偏好和人际影响)在模型中有重要的意义.例如张燕平等[8]利用历史记录获取用户声誉来建立声誉推荐系统.Qian等[9]提出了一种结合用户人际兴趣相似性、人际影响力和个人兴趣因素的个性化推荐模型(Personalized recommender model,PRM).Wang等[10]提出使用社会传播模拟和内容相似性分析来更新用户内容矩阵.他们还构建了一个联合的社会内容空间来衡量用户和视频之间的相关性,为视频导入和重新分享推荐提供了高度的准确性.Feng和Qian[2]提出了一个推荐模型,以满足用户(特别是对有经验的用户)的个性.此外,他们的方法不仅考虑个人偏好,而且结合了人际信任影响和人际兴趣相似性.
隐含狄利克雷分布(Latent Dirichlet allocation,LDA)和栈式降噪自编码器(Stacked denoising auto-encoder,SDAE)等基于文档建模的方法主要是利用了评论、摘要或概要的项目描述文档[11−14].具体来说,Wang等[11]提出了协同主题回归(Collaborative topic regression,CTR),在概率方法中结合了LDA和协同过滤.而CTR的变体是将LDA集成到协同过滤中通过使用不同的集成方法来分析项目描述文档[12−13].Wang等[6]提出了协同深度学习(Collaborative deep learning,CDL),将SDAE整合到概率矩阵分解(Probabilistic matrix factorization,PMF)中,从而在评分预测精度方面产生更准确的隐义模型[14].
但是,现有的集成模型不能完全捕获文档信息,因为它们采用词袋模型,该模型假定忽略如周围单词和单词顺序文档的上下文信息.但文档内的这种细微差异也是成为更深入理解文档的重要因素,并且进一步理解有助于改进评分预测准确度.为了解决上述问题,部分研究者尝试使用卷积神经网络(Convolutional neural network,CNN).CNN通过本地接收场、共享权重和亚采样的建模组件有效地捕获图像或文档的局部特征[15−16].因此,CNN的使用有助于更深入地理解文档,并且产生比LDA和SDAE更好的隐义模型,特别是缺乏评分的描述文档.此外,CNN能够利用预训练的词嵌入模型,例如Glove[17],以便更好地理解项目描述文档,而LDA和SDAE不能利用预训练的词嵌入模型.
然而,现有的CNN不适合推荐任务.具体来说,常规CNN主要解决预测词、短语或文档的标签分类任务.相反,推荐的目的通常是回归任务,旨在准确地逼近用户对项目的评分.因此,现有的CNN不能直接应用于本文的推荐任务.为了解决该技术问题,Kim等[18]提出了一种文档上下文感知推荐模型—卷积矩阵分解(Convolutional matrix factorization,ConvMF),利用CNN捕获项目描述文档的上下文信息,进一步增强评分预测精度.
2 SCTCMAR模型
本文对汽车推荐系统进行研究,为了更好地理解用户的评分行为,需要挖掘用户的个性化特征.本文从两方面入手:1)社交环境对用户的影响,在特定的车型下构建购买用途需求的社交圈,在此社交圈的基础上,分析用户的个人偏好和偏好相似度两个社交因素,并计算量化其社交关系;2)分析评论文本对项目的影响,通过深度学习技术构建了四层卷积神经网络来学习文本特征.最终,本文提出了新颖的SCTCMAR汽车推荐模型,该模型融合了社交影响和评论文本特征,即用户的个人偏好、偏好相似度以及项目的评论文本特征,最终将这三个因素注入到推荐模型中体现社交因素和评论文本特征因素对用户决策过程的影响.
2.1 汽车推荐框架
本文提出的模型如图1所示,中间的点线框为PMF,左边线框是社交因素,右边线框是CNN.该模型在概率矩阵分解(PMF)的基础上,融合社交因素对用户的影响和评论文本特征对项目的影响,提出了SCTCMAR模型.推荐模型中的符号定义见表1.
假设有N个用户和M个项目以及真实评分矩阵,目标是找到用户和项目的隐义模型,求其乘积来重构评分矩阵R.通过概率矩阵分解模型使用W,F和Q不断地影响用户和项目的隐义模型,从而求其乘积得到预测u到i的评分值,不断逼近预测值与实际值之间的差距,从而提高推荐精准度.在概率上真实评分的条件概率分布如下:
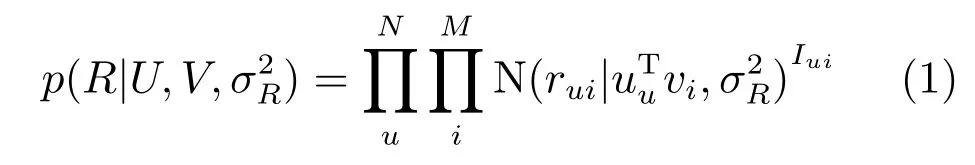
其中,N(x|u,σ2)表示均值为u,方差为σ2的高斯分布概率密度函数,Iui是指示函数,如果用户u对项i评价过,则Iui=1,反之为0.

表1 推荐框架的符号定义Table 1 Notations in recommender framework
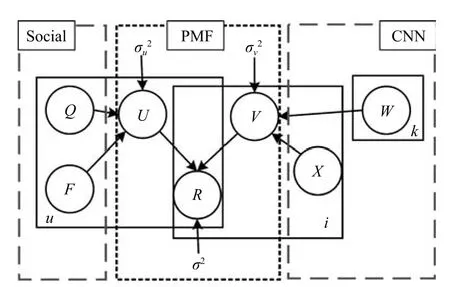
图1 SCTCMAR的图模型Fig.1 Graphical model of SCTCMAR
对于用户隐义模型有三个因素:1)为了防止过拟合的0均值高斯先验概率;2)在已知该用户社交圈中朋友的偏好隐特征时,用户隐特征的条件概率;3)在已知该用户社交圈中个人偏好隐特征时,用户隐特征的条件概率.具体定义为
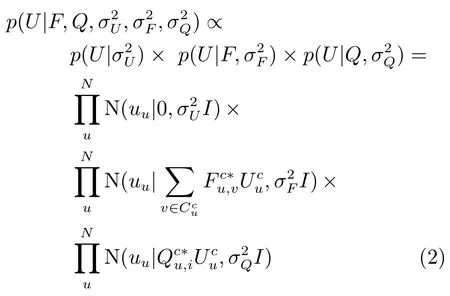
与常规PMF中的项隐义模型不同,我们假设从三个变量生成项目隐义模型.1)CNN中的内部权重W;2)表示项i的文档Xi;3)εi变量作为高斯噪声.这使我们能够进一步优化项隐义模型的评分.因此,最终项隐义模型为
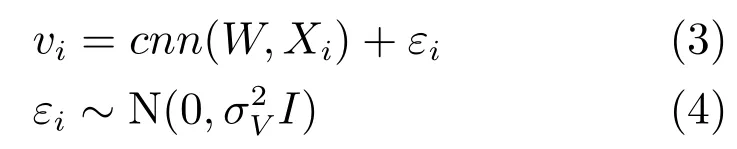
其中,cnn表示卷积运算.
对于W中的每个权重wk,设置最常用0均值高斯先验概率.具体定义如下:
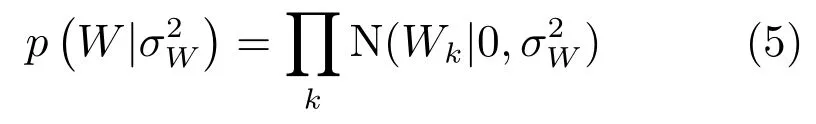
于是,项隐义模型的条件概率如下:
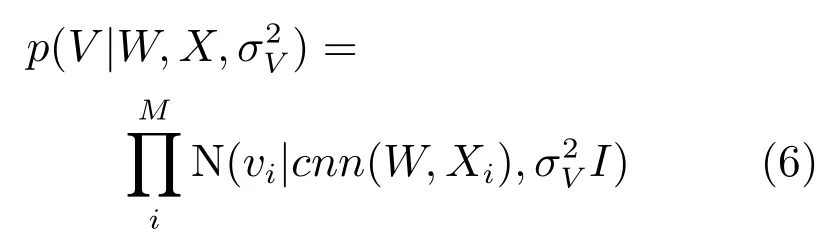
其中,X是项目的描述文档集合.为了建立CNN和PMF之间的桥梁,使用从CNN模型获得的评论隐向量作为高斯分布均值,并且项的高斯噪声作为高斯分布的方差,这有助于完全分析描述文档和评分.
接下来将按以下过程详细介绍:
1)为了确定社交环境的影响范围,需要构建基于购买用途需求的社交圈;
2)在该社交圈的基础上分别分析用户的个人偏好和偏好相似度;
3)使用卷积神经网络提取评论隐特征.
2.1.1 社交圈
给定用户u,类别c和用途t,本文使用Yang等[2]提出的推理规则为当前类别评分用户建立社交圈.
定义1.基于购买用途需求的社交圈.在特定类别c下,对于用途t,原始社交网络SN(Social network)满足以下条件的所有用户v构成u的社交圈,即.
1)在SN中用户u和用户v有直接社交关系,即SNu,v=1;
按照给出的说明,图2展示了购买用途需求的社交圈的构造过程.每个用户购买用途需求使用括号标注在用户旁边,例如用户u的购买用途需求为t1,t2,t3.用户u为了构造特定购买用途需求t1下的社交圈,首先需要在SN中找出与u有直接社交关系的用户集合,再按照条件进行筛选,最后找到用户集合是用户u在购买用途需求t1下的社交圈.同理,可推出u在t1和t2下的社交圈和.下文对社交影响中的社交因素的有关研究全部限制在购买用途需求的社交圈范畴内.
2.1.2 个人偏好
Feng和Qian[2]提出了一种基于项类别分布向量来衡量用户个人偏好的方法,但忽略了历史用户评分值.然而,u对项i的评分值反映了u喜欢i的程度.因此,将项类别分布与用户评分数据结合,可以更精确地学习用户的个人偏好.关于类别c,可以从评分矩阵Rc获得用户评分数据.矩阵Rc的每一行归一化如下:
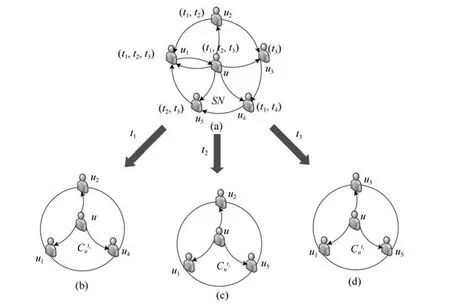
图2 构造购买用途需求的社交圈Fig.2 The inference process of purpose-based social circle of users
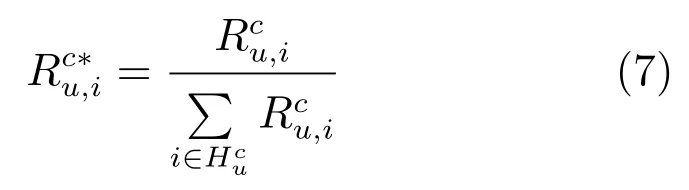
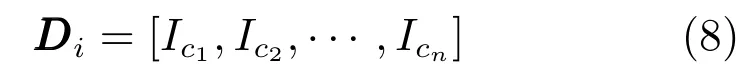
其中,Icn是指示函数,如果项i属于类别cn,则Icn=1,反之亦然.n是目录的数量.
定义2.个人偏好是用户u在特定类别c下对汽车主题的偏爱分布情况,用表示.
如果u在类别c中具有评分,则其个人偏好应该类似于项类别分布向量的加权平均值.u在类别c中的个人偏好为
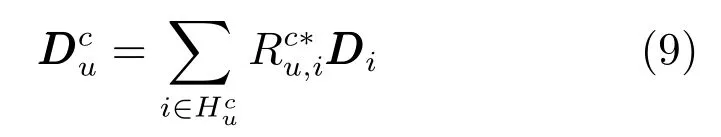
如果u从来没有为类别c中的项评分,作为其个人偏好的近似值,使用属于他的社交圈的朋友的个人偏好的平均值.从而
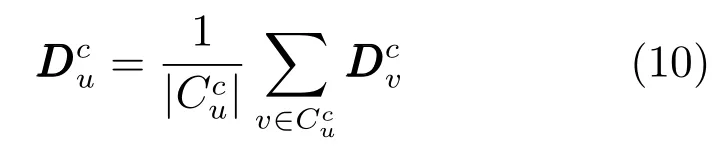
在实践中,用户u的个人偏好与项目i的主题的相关性被视为用户u在项目i上的隐实际评分值,用Qu,i表示.
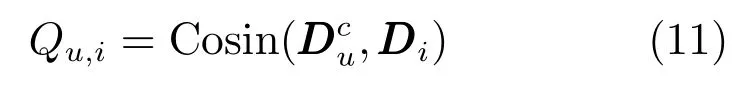
其中,Cosin表示两个向量间的余弦相似度.
2.1.3 偏好相似度
定义3.偏好相似度是在特定类别c下,用户u和v之间的主题偏好向量相似度,用表示.具体来说,本文采用Feng和Qian[2]提出的方法来度量偏好相似度.
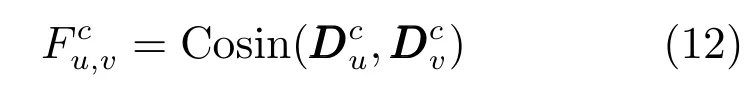
归一化后如下:
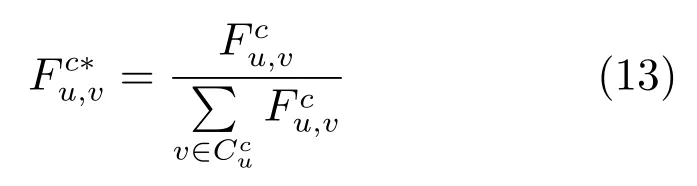
2.1.4 评论隐特征
CNN的目标是从汽车评论文本数据中学习文本的隐特征向量.图3显示了CNN的结构,包括Embedding层、卷积层、Pooling层和输出层.
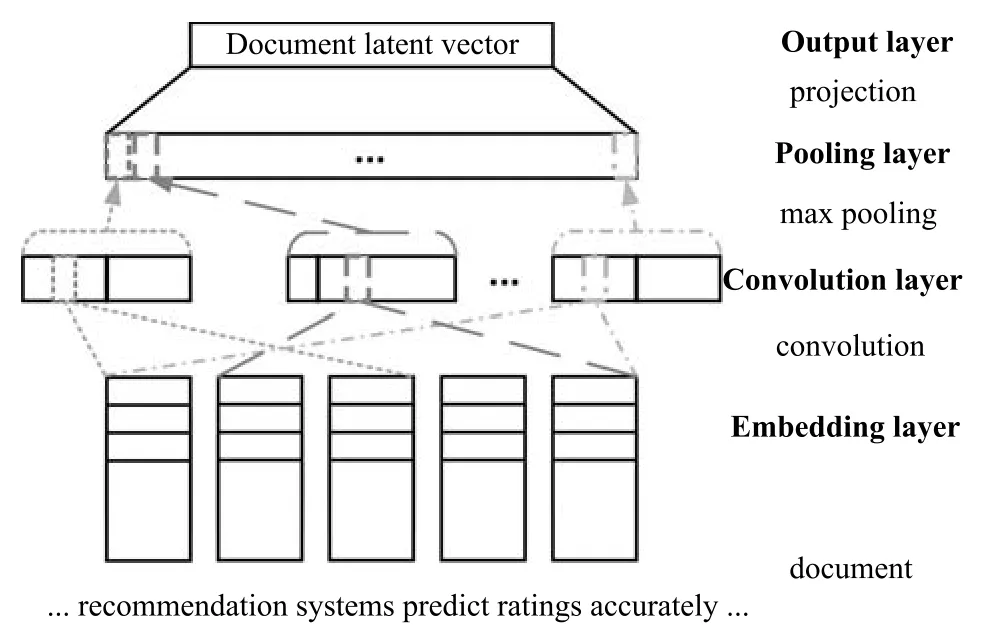
图3 卷积神经网络结构Fig.3 Structure of convolutional neural network
1)Embedding层
该层将预处理的汽车评论文本变换成表示下一个卷积层文档的密集矩阵.具体来说,对于作为l个词的序列文档,通过连接文档中词的向量将文档表示为矩阵.词向量由随机初始化或用词向量嵌入模型GloVe预先训练好,通过优化过程进一步训练,文档矩阵D∈Rp×l变为
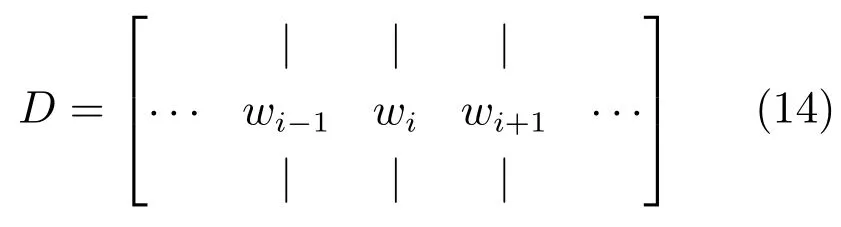
其中,l为文档长度,p为wi的嵌入维度大小.
2)卷积层
卷积层提取上下文特征.
定义4.上下文特征向量用来提取汽车评论文本的上下文信息的向量,用表示.

其中,∗是卷积算子,是的偏差,f是非线性激活函数.在诸如sigmoid、tanh和ReLU的非线性激活函数中,使用ReLU来避免梯度消失的问题,导致优化收敛慢并且可能导致差的局部最小值[19−20].带有权重文档的上下文特征向量由下式构成:
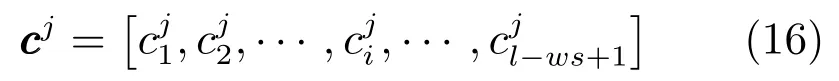
然而,一个共享权重只能捕获一种类型的上下文特征.因此,使用多个共享权重来捕获多种类型的上下文特征,能够生成与Wc数量nc一样多的上下文特征向量.例如中的.
3)Pooling层
Pooling层从卷积层提取表征特征,并且通过构建固定长度特征向量的池化操作来处理文档的可变长度.在卷积层之后,文档被表示为nc个上下文特征向量,其中每个上下文特征向量具有可变长度(即l−ws+1个上下文特征).然而,这种表示存在两个问题:1)存在太多的上下文特征ci,其中大多数上下文特征可能不会帮助增强其性能;2)上下文特征向量的长度变化,使得难以构建接下来的层.因此,利用max-pooling,通过从每个上下文特征向量中仅提取最大上下文特征,将文档的表示减少到nc个固定长度向量中.
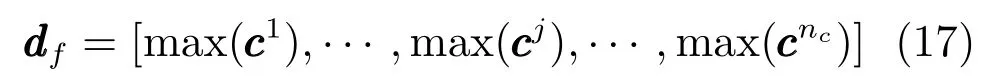
4)输出层
通常,在输出层,从前一层获得的高级特征应该被转换用于特定任务.因此,在推荐任务的用户和项目隐义模型的k维空间上投影,通过使用常规非线性投影最终产生评论隐向量.
定义5.评论隐向量是表示汽车评论文本中的隐义特征向量,又作为评论隐特征,用表示.
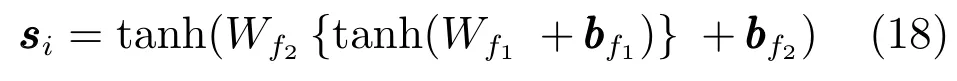
通过上述过程,CNN架构以预处理的汽车评论文本为输入函数,返回每个文档的隐向量作为输出.
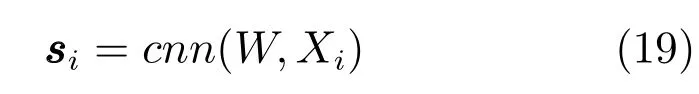
其中,W表示所有权重和偏差变量,以防止混乱.Xi表示项目i的文档,si表示项目i的评论隐向量.
3 汽车推荐模型
3.1 SCTCMAR模型
本文采用低阶矩阵分解技术将用户–评分矩阵分为用户隐特征矩阵UT∈Rn×k和汽车隐特征矩阵V∈Rm×k,k是隐空间的向量维度,对于每个类别c,汽车推荐模型SCTCMAR的目标函数为
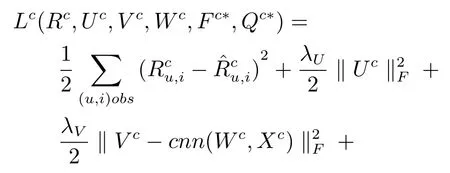
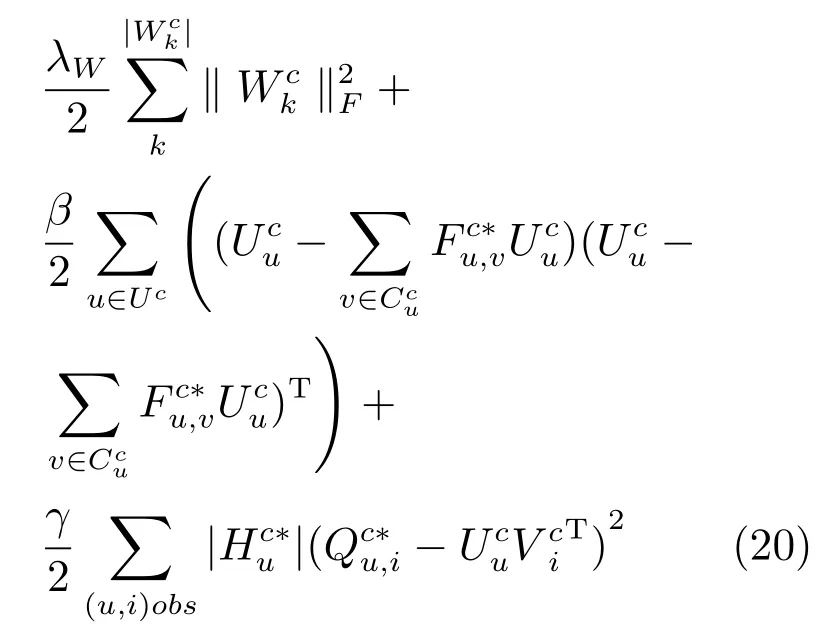
3.2 模型训练
针对推荐模型SCTCMAR的目标函数,使用梯度下降法进行优化,将看作变量并求偏导.
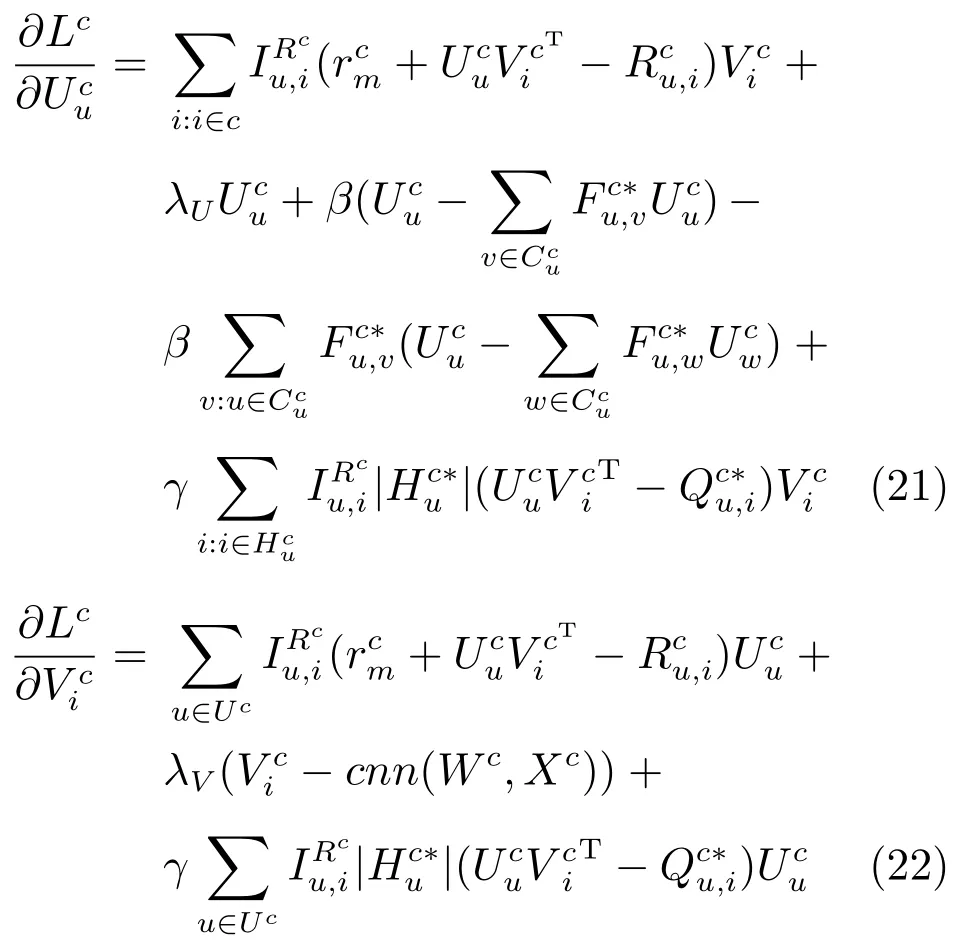
求偏导后同时更新用户隐特征向量和汽车隐特征向量,然后把更新后的隐特征向量代入目标函数中重新计算,使目标函数值最快速度下降,循环迭代该过程直到目标函数收敛为止,最终经过训练得到用户隐特征矩阵和汽车隐特征矩阵.
然而,由于W与CNN结构中的特征(例如max-pooling层和非线性激活函数)密切相关,所以W不能像对U和V一样由梯度下降的方式来优化.然而,当U和V是暂时恒定时,我们观察到L可以被解释为具有如下的L2正则化项的平方误差函数.
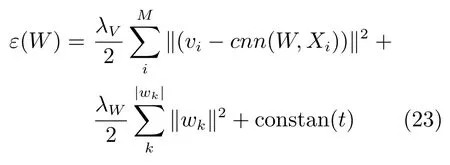
其中,constan表示返回一个常量.
W是每一层的权重和偏置,为了优化W,使用反向传播算法.重复整个优化过程(U,V,W交替地更新)直到收敛.通过优化U,V,W,最终可以预测用户对汽车的未知评分.

4 实验及结果分析
4.1GloVe,available:https://nlp.stanford.edu/projects/glove,2017 数据集
本文实验主要使用网络爬虫从Internet抓取的汽车基本信息、用户信息、用户对汽车评论信息和与汽车有关的语料文本集.汽车和用户数据主要来源于汽车之家和网易汽车,预训练词嵌入模型主要将语料数据集作为训练数据,通过使用GloVe工具1GloVe,available:https://nlp.stanford.edu/projects/glove,2017来构建.该工具使用的是一种无监督学习算法,主要用于获取词特征向量,本质上是具有加权最小二乘的log-bilinear模型,其模型的主要来源于观察的现象,即词–词共同出现可能性的比例具有编码某种形式的意义的潜力.此外,分词过程中使用了数据堂和搜狗输入法提供的汽车领域字典以及爬取的互联网上的汽车字典资源,如表2所示.
汽车评论文本预处理的主要任务包括,数据清理和中文分词两部分.1)清理:由于实验数据主要是通过网络爬虫技术从相关的汽车网站上抓取得到的,所以数据信息的格式有很多不规范的地方,存在结构化和非结构化数据.得到的数据中存在HTML标签、Javascript代码、广告标语等不同形式的噪点,需要进行去噪、清洗,转为合适的数据结构,便于使用和理解.去噪主要采用正则表达式,对广告标语主要靠人工清理.2)分词:在自然语言处理的相关研究工作中,分词占据着重要的地位.对于中文语料,分词工作更是如此.本文采用ICTCLAS2ICTCLAS,available:http://ictclas.nlpir.org,June 10,2017系统作为研究工作中的分词工具,主要使用基于词典的分词功能.
爬取的数据经过清理、去重和整合处理之后,最终数据集中有266995个用户信息、702辆汽车信息以及用户购买的汽车信息,其中每一个用户的购车用途需求有多个,例如上班、接送孩子、自驾游等;汽车车型有11种类型,如跑车、小轿车、SUV、皮卡等.用户对其购买汽车的评分主要是1~5的整数.本文将数据集分成5组,进行5-fold交叉验证来评估算法的性能.
4.2 评价指标体系
针对汽车的推荐性能,主要从三个方面进行评价:1)汽车推荐列表中用户真正购买的比例;2)在用户–汽车测试集中向用户成功推荐的比例;3)汽车推荐列表中用户最终购买汽车的排名.评价指标为精确率(Precision)和召回率(Recall).
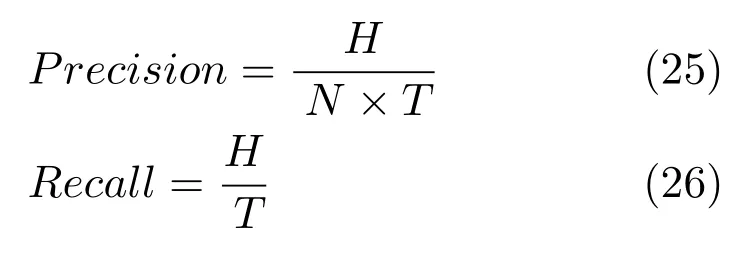

表2 数据集信息列表Table 2 The list of datasets
其中,T为用户数,N表示系统为用户推荐的汽车列表长度,H指最终购买汽车推荐列表中的汽车的用户数.
对于汽车这一特定商品,还采用平均倒序排名(Average reciprocal hit rank,ARHR)[21]对推荐排序准确度进行评价.排序准确度评估指标衡量的是系统产生的推荐集中商品的排序与用户个人偏好的相似度,平均倒序排名衡量推荐系统向用户输出的效用性,用户最终购买的商品在推荐列表中的排名越高,该推荐系统的效用性越强.在推荐列表中,排序位置pi的成功推荐效果值设置为1/pi,然后进行迭代,迭代后求平均值得到平均倒序排名值.具体如下:
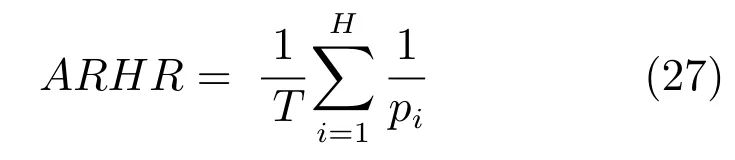
4.3 与其他推荐算法的对比
为了验证提出的汽车推荐模型SCTCMAR的有效性,选用具有代表性的推荐算法与SCTCMAR进行比较,被选入实验对比的四种推荐算法如下:
1)FMM(Flexible mixture model).由Si等[22]提出的灵活混合模型.FMM通过将用户和项目同时聚类在一起,同时进行协同过滤来扩展现有的分区/聚类算法,而不必假定每个用户和项目只应属于单个集群.实验中,按照该算法的主要思想,将用户和汽车以购买用途需求分别进行聚类,实现了FMM模型,最终完成测试用户的汽车推荐任务.
2)TR(Trust rank).由Zou等[23]提出的算法.该算法利用可用于电子商务的用户信任网络来处理冷启动问题给推荐系统带来的限制.用户信任网络由用户在其中指定的友谊或信任关系形成,主要通过应用个性化的PageRank算法,扩展了给定用户的朋友,即其他具有类似购买记录的人的朋友.在实验中,根据该模型的主要想法,构造一个以购车用户组成的社交网络,并且实现了该模型和算法.
3)RS(Random sampling).从整个汽车信息集中随机抽取N辆汽车向用户推荐,作为其他算法的对比实验.
4)SCTCMAR+.本文提出的推荐算法的另外一个版本,该方法使用了GloVe预训练词嵌入模型.
现有的深度学习平台和工具种类繁多[24],本文使用Python和Keras3F.Chollet.Keras.http://github.com/fchollet/keras,2017库来实现本文模型SCTCMAR.良好的学习率策略可以显著提高深度学习模型的收敛速度,减少模型的训练时间[25].为了训练CNN的权重,本文使用小批量的RMSprop(自动调节学习速率的深度学习优化方法),每个小批量包括128个训练项目.至于详细的CNN架构,本文使用以下设置:1)将文档的最大长度设置为3000.2)SCTCMAR:随机初始化维度大小为50的词潜在向量.SCTCMAR+:通过尺寸大小为50的预训练词嵌入模型初始化词潜在向量.两种词潜在向量都将通过优化过程训练.3)在卷积层中,使用的各种窗口大小为3,4和5,并且使用每个窗口大小的100个共享权重.4)代替与CNN的权重相关的L2正则化器,使用dropout和设置dropout率为0.2以防止CNN过度拟合.本文按照原文的调优成果将FMM算法中的用户和汽车种类分别设为10和20,对于TR算法和其他参数的设置设为默认值.
在实验对比中,首先对比N取值为5,10,15,20的情况下的精确率和召回率.表3、表4和图4是各算法的精确率和召回率的比较,以及SCTCMAR+相对于其他方法提升百分比的实验结果.
表3、表4和图4表明,SCTCMAR相较于其他方法在精确率和召回率上的性能好,进一步验证了算法对于汽车这个特殊商品的推荐有效性.无论是精确率还是召回率,随机抽取算法比其他各个算法都低很多.具体来说,在精确率方面,从图4(a)可以看出,SCTCMAR汽车推荐模型比FMM和TR推荐算法性能要好,相对于FMM在N=5时提升了46.1%,而相对于TR在N=10时提高了41.1%;召回率方面,从图4(b)可以看出,当N=5时,SCTCMAR达到54.6%,相对于FMM上升了43%,TR上升了25.8%.从图4可以看出,N值越大,各个算法的推荐精准率逐渐下降,即推荐列表中的汽车越来越多,算法错误推荐的概率也越大;而召回率的走势与精确率相反,随着N值增大,召回率逐渐上升,N值越大,算法预测到用户最终购买汽车的概率越大.
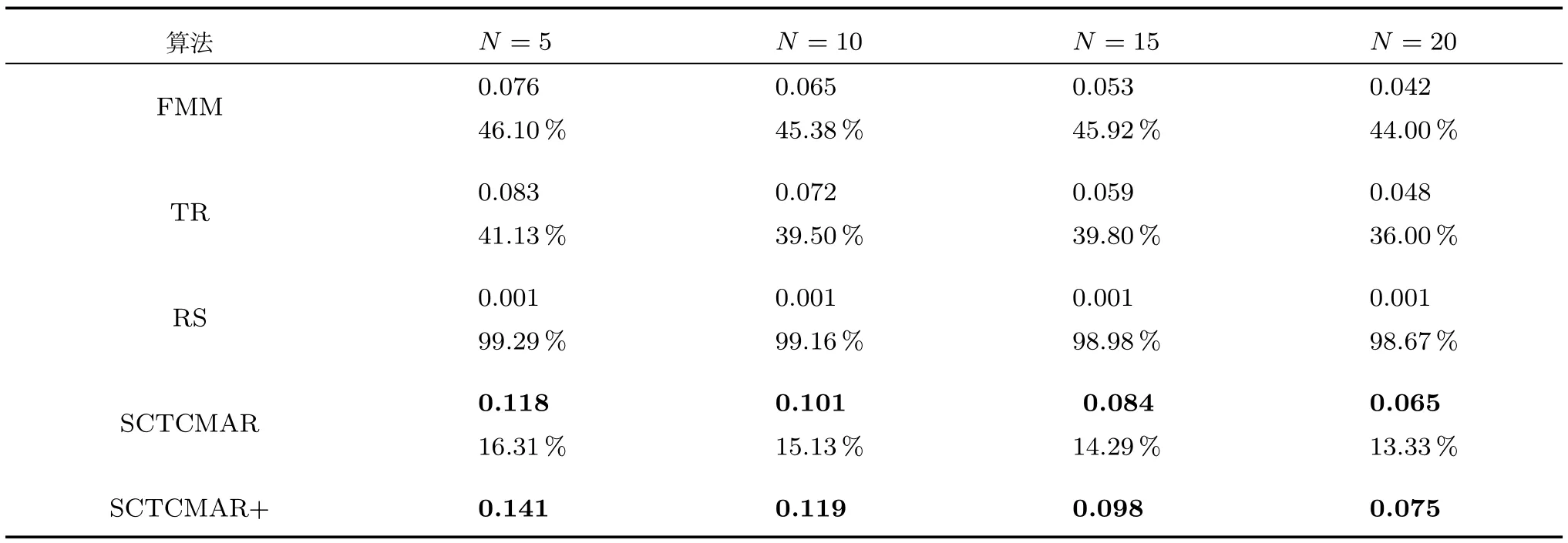
表3 本文提出的算法与其他算法在推荐精确率上的比较及提升百分比Table 3 Precision comparison and improvement between our algorithm and other algorithms
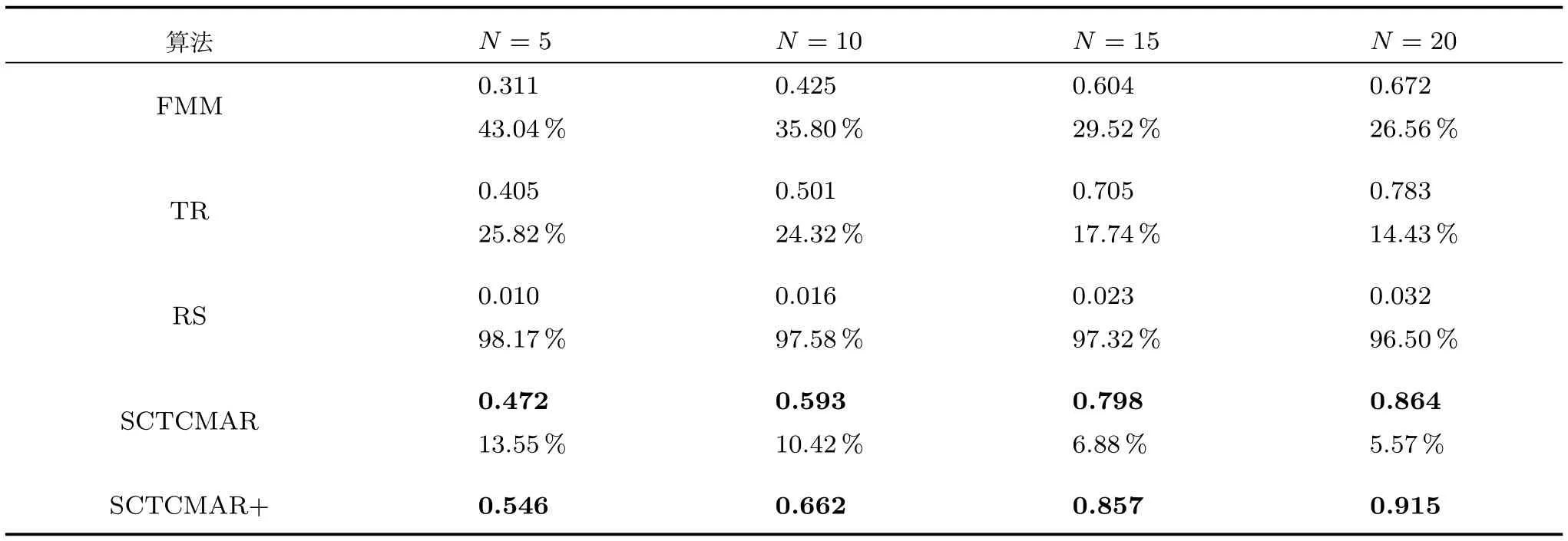
表4 本文提出的算法与其他算法在推荐召回率上的比较及提升百分比Table 4 Recall comparison and improvement between our algorithm and other algorithms
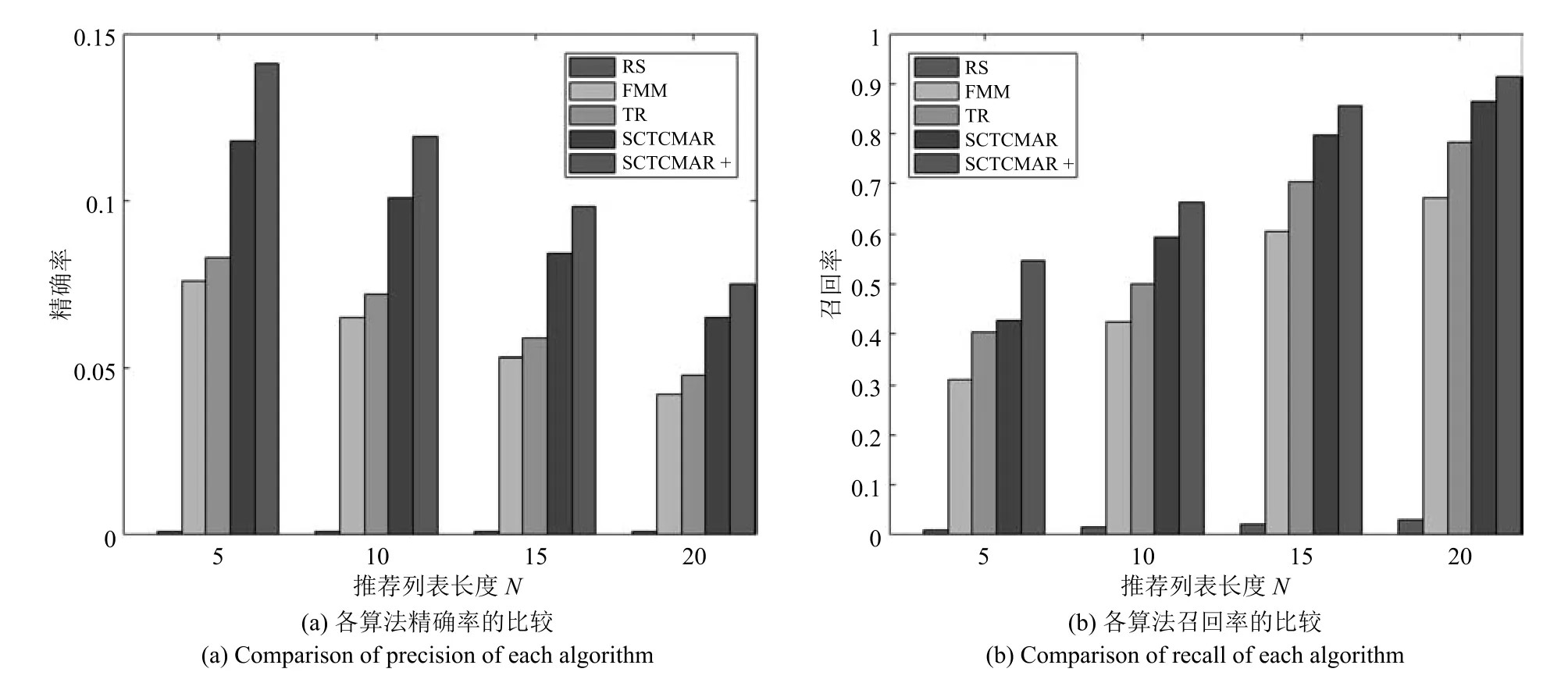
图4 在精确率和召回率上本文提出的算法与其他算法的对比Fig 4 Precision and recall comparisons between our algorithm and other algorithms
但是,从表3和图4可以发现,相对于一般消费商品来说,本文中各个算法精确率都很低,主要是由精确率的定义和汽车这种特定商品的属性造成的.从精确率的定义来看,它计算推荐列表中用户真正购买的汽车比例.对汽车而言,用户通常情况下只会选购列表中的一辆,即所占比例不会超过1/N.
为了对系统推荐准确性进行更好的评估,本文还采用了平均倒序排名ARHR[21]这一评价标准.平均倒序排名值越大,表明用户真正购买的汽车在推荐列表中的排名越靠前,对于购买汽车用户的推荐效果越优.实验结果如表5和图5所示.
从图5可以看出,各算法远比随机抽取的平均倒序排名高.在汽车这种特定领域商品Top-N推荐任务中,SCTCMAR相比于FMM和TR算法在平均倒序排名上有更好的推荐准确度.进一步可知,N值越大,各推荐算法的平均倒序排名越高,最终慢慢趋于平稳.说明该评价标准对于汽车商品推荐的有效性,也进一步说明将社交因素与评论文本特征融合到推荐模型的有效性.
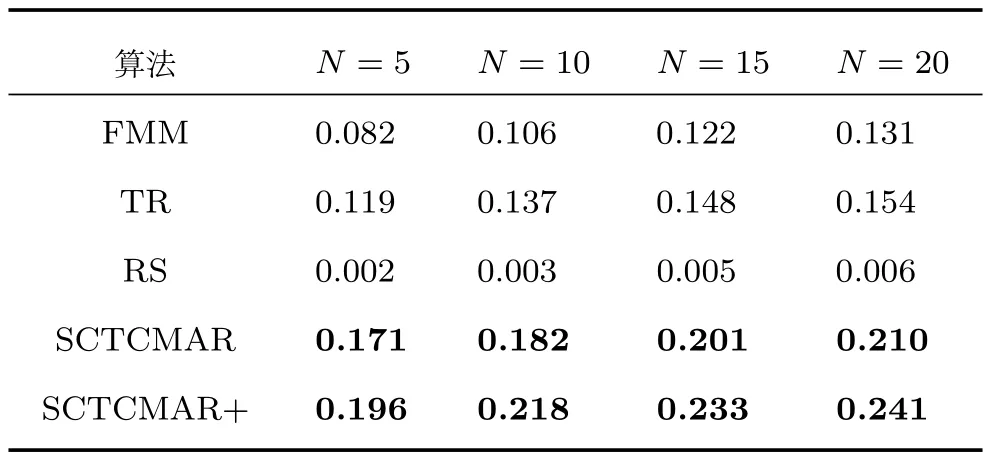
表5 各算法在平均倒序排名上的对比Table 5 ARHR comparison between our algorithm and other algorithms
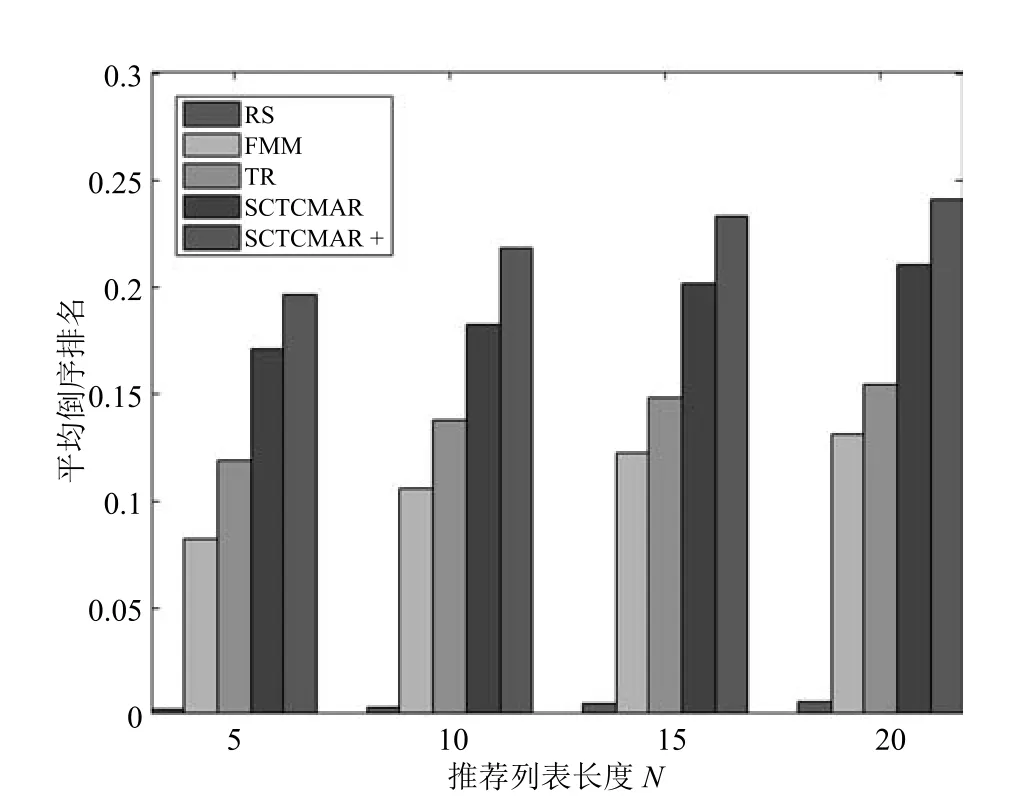
图5 各算法在平均倒序排名上的对比Fig 5 ARHR comparison between our algorithm and other algorithms
4.4 进一步分析
1)预训练词嵌入模型的影响
与协同过滤的主题回归(CTR)和协同深度学习(CDL)不同,SCTCMAR能够利用预先训练的词语嵌入模型,例如GloVe[17].因此,通过使用GloVe预先训练的词嵌入模型初始化SCTCMAR的CNN的嵌入层来分析预训练的词嵌入模型对汽车推荐任务的影响.表3~5显示了SCTCMAR+与SCTCMAR在数据集上的实际变化,精确率、召回率和平均倒序排名都有不错的提升,但是可以看出词嵌入模型对SCTCMAR的影响与推荐列表长度N没有直接关系.为了进一步分析预训练词嵌入模型的影响,实验选取皮卡(pika)、面包(mianbao)、小型车(small)和紧凑型车(compact)四种车型在N=5时的平均倒序排名影响.其中车型的评分数据稀疏度是pika>mianbao>small>compact.实验结果如表6所示.
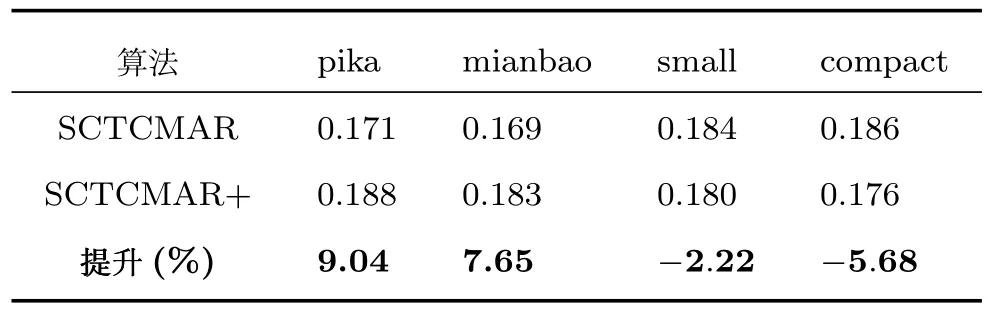
表6 本文算法使用词嵌入模型在平均倒序排名上的影响Table 6 ARHR comparison between our algorithm with pre-trained word embedding model
在表6中,尽管有微小的变化,可以观察到一致的趋势,评分数据越来越稀疏,预先训练的词嵌入模型有助于提高SCTCMAR的性能.因为预先训练的词嵌入模型的语义和句法信息补充了评分的不足.还可以观察到,给定足够数量的评分来训练,则预先训练的词嵌入模型使SCTCMAR的性能恶化.换句话说,由于评分直接反映了用户和项目之间的关系,最好是充分利用评分信息,而不是在评估数据相对密集的时候,使用从外部文档获得的预先训练的词嵌入模型.
2)因素组合的影响
在实验中将研究的因素的参数设为一定值,将剩余其他的因素的参数设为0.在SCTCMAR模型中,对于个人偏好因素,设定γ=5和cnn(Wc,Xc)=λw=β=0,对于偏好相似度因素,设定β=5和cnn(Wc,Xc)=λw=γ=0;对于评论隐特征因素设定β=γ=0.SCTCMAR模型有两个社交因素,因此性能比较时设置相同的参数.
我们系统地比较了不使用因素以及使用1个、2个、3个因素的各种方法,比较结果如图6所示.UP,PS,CTC分别表示SCTCMAR中的个人偏好、偏好相似度和评论隐特征.+表示因素组合.通过比较可以发现,所有因素对提高平均倒序排名都有积极影响.进一步,SCTCMAR模型中的每一个因素比PMF中的每个社会因素都有更好的表现.此外,SCTCMAR的多因素组合比其他方法更好,例如FMM,Trust rank和Random sampling.
5 结语
本文主要针对汽车推荐进行研究,重点探索社交因素和评论文本因素对用户购车决策过程的影响,融合以上两方面提出了新颖的SCTCMAR推荐模型.虽然实验结果表明SCTCMAR模型在一定程度上改善了推荐性能,但是还没有考虑用户购车需求与决策过程中更多的关联关系以及更多的汽车属性信息.下一步工作将考虑将更多的汽车属性信息和交互关系信息融入到推荐模型中,进一步提高推荐精准度,并找到更有趣的规律.
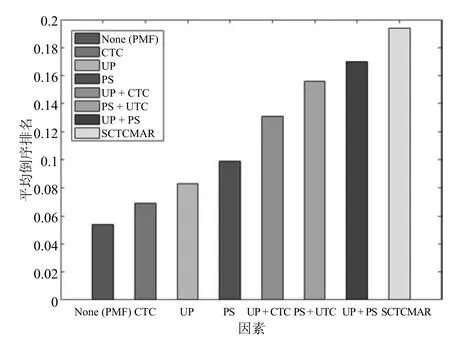
图6 本文算法多因素联合对平均倒序排名的影响Fig 6 ARHR line chart of impact of factors combination in our model
猜你喜欢
客联(2022年3期)2022-05-31
意林彩版(2022年2期)2022-05-03
好日子(2021年8期)2021-11-04
文萃报·周五版(2021年39期)2021-10-18
中国新闻周刊(2021年26期)2021-07-27
中欧商业评论(2021年5期)2021-06-11
第一财经(2020年4期)2020-04-14
文苑(2018年17期)2018-11-09
大众理财顾问(2018年7期)2018-07-13
电脑爱好者(2017年7期)2017-05-06
