
注意力增强的双向LSTM情感分析
2019-04-02 02:55关鹏飞李宝安吕学强周建设
中文信息学报 2019年2期
关鹏飞,李宝安,吕学强,周建设
(1. 北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101; 2. 首都师范大学 北京成像技术高精尖创新中心,北京100048)
0 引言
随着互联网的发展,近几年,网民数量急剧上升。人们在信息交互的过程中,产生了大量的对诸如人物、事件、产品等有价值的评论信息。这些信息表达了人们的各种感情和情感倾向。通过对情感信息的挖掘,可以更好地理解用户行为,从而预测出事件的发展方向或趋势[1]。但随着信息规模的急剧膨胀,仅靠人工已经不可能完成情感分析工作,所以,使用计算机进行高效准确的情感分析工作有着重要的意义。
目前情感分析技术主要分为三类: 基于情感词典的方法、基于特征的方法和基于深度学习的方法。基于情感词典的方法主要根据文本中的情感词来判断文本的情感倾向,需要人工构建情感词典,结合情感词典和人工设置规则实现对文本的情感分析[2-3]。这种方法基于人类语言的表述方式,通过情感词可以反映人的情感倾向,但没有考虑到上下文的语义信息。基于特征的方法是采用统计学知识,从大量语料中选取特征,使用这些特征对文本进行表示,然后使用决策树、支持向量机(SVM)等机器学习算法进行分类[4-5]。该方法对经验要求较高,特征的选取直接影响分析结果。基于深度学习的方法可以分别对词语、句子和篇章进行向量化表示,学习文本的深层语义信息[6]。该方法有强大的特征学习能力,省去了特征选取和规则制定等步骤。常见的深度学习模型有: 卷积神经网络(Convolutional Neural Networks,CNN)、循环神经网络(Recurrent Neural Networks,RNN)等。
本文以短文本为情感分析的研究对象,提出一种注意力增强的双向LSTM(Bi-directional Long Short-Term Memory,BiLSTM)模型。BiLSTM模型用于获取文本的语义信息,注意力机制(Attention Mechanism)用于获取文本中的关键词信息。与传统使用注意力机制方式不同,本文不再使用注意力机制学习CNN、LSTM等模型的输出,而是直接在词向量的基础上使用注意力模型来发现文本中的重要信息。实验表明该模型在情感分类上取得了较好的效果。
本文将在第1节介绍使用深度学习技术进行情感分析的相关工作;在第2节介绍注意力增强的BiLSTM模型的结构及原理;第3节对实验数据进行介绍,并在数据集上使用不同模型进行对比;最后一节对本论文的工作进行总结并提出展望。
1 相关工作
自2006年Hinton等提出深度学习后,深度学习在计算机视觉方面取得了巨大的成就,越来越多的学者开始将深度学习应用到自然语言处理领域。由于短文本包含的信息量较少,同时传统方法不能发现文本中的深层语义信息,所以深度学习成为情感分析研究的主流方法。
基于深度学习的情感分析通常是使用神经网络将文本表示成一定长度的向量,所以基于深度学习的情感分析可以理解为自动学习文本编码然后分类的过程。Kim等[7]在多个英文语料上利用卷积神经网络实现句子级别的分类任务,并在相关电影评论数据集上讨论了词向量预训练及参数调整等细节工作。Cao等[8]利用迁移学习的思想,将CNN提取的文本特征使用SVM进行分类。该方法将传统机器学习模型和深度学习模型相融合,在情感分析任务上取得不错的效果。冯兴杰等[9]使用CNN和注意力机制在词向量的基础上表示文本,相比于CNN网络方法有明显的提高。该模型结构对本文的工作有很大的启发。Qian等[10]通过改变损失函数的方式,把情感词典、否定词和程度副词等现有语言规则融入到句子级LSTM情感分类模型中,在没有增大模型复杂度的情况下,有效地利用语言学规则,在实验数据集上取得了较好效果。张仰森等[11]采用BiLSTM网络分别对微博文本和文本中包含的情感符号进行编码。该方法通过将注意力模型和常用网络用语的微博情感符号库相结合,有效增强了对微博文本情感语义的捕获能力,提高了微博情感分类的性能。胡朝举等[12]通过BiLSTM将主题词向量和文本词向量进行训练,将得到的主题特征和文本特征进行特征融合,经过深层注意力机制的处理,使模型加强了对主题特征和情感信息的有效关注。
现阶段基于深度学习的情感分析是以发掘文本语义信息为主,但在情感分析工作中,句中每个词对于整体情感倾向的影响是不同的,尤其是一些情感词,往往能够直接反映出人的情感倾向。Qian等[10]虽然使用了注意力机制学习权重分布,但是在BiLSTM编码的基础上进行的,没有直接从文本中挖掘重点信息。本文提出一种注意力增强的BiLSTM模型,使用注意力机制直接从词向量的基础上学习每个词对情感倾向的权重分布。本模型通过使用BiLSTM学习文本的语义信息,最终使用重点词增强的方式提升分类效果。
2 注意力增强的双向LSTM结构
本文采用注意力机制与BiLSTM结合的方式,使用BiLSTM学习文本语义信息,使用注意力机制加强对重点词的关注,整体结构如图1所示。首先对输入的句子利用预训练好的词向量进行表示,然后分别经过BiLSTM模型和注意力模型学习表示,将两部分表示后的向量拼接,最终通过分类器完成文本情感分析工作。
2.1 词语表示层
词作为该模型处理的基本单元,第一步是对词进行符号化表示。与传统的表示方法不同,本文使用连续的稠密向量作为模型的输入。随着Mikolov等[13-14]提出了Word2Vec模型,词向量可以在低维空间中更好地学习词语蕴含的语义信息。词语表示层会在相关语料上预训练出一个RN×d规模的词典,N表示词典中词的个数,d表示词向量的维度。在进行词语表示时,用xt表示文本中的第t个词,xt∈Rd。若文本长度为T,则输入文本表示为式(1)。
S=[x1;x2;…;xT]∈RT×d
(1)

图1 词向量注意力机制的BiLSTM模型结构
2.2 语义学习层
自然语言的词语之间存在时序关系。为了让模型可以学习词语间的语义依赖关系,本文采用BiLSTM模型对句子的语义信息进行编码。BiLSTM由正反两个LSTM模型组成,长短期记忆网络(Long Short-Term Memory,LSTM)[15]是循环神经网络的一种,它有较强的长距离语义捕获能力,图2是LSTM的基本结构。

图2 LSTM结构
xt为t时刻LSTM单元的输入数据,ht是t时刻输出,C是不同时刻记忆单元的值。LSTM主要用三个门结构来控制模型中信息的加工。遗忘门ft决定记忆信息的通过量,该门将xt和上一时刻输出ht-1作为输入,输出值在0和1之间,值用来描述每个部分通过量的多少。ft的计算公式如式(2)所示。
ft=σ(Wf[ht-1,xt]+bf)
(2)
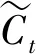
Wi为输入门权重,bi是输入门偏置,tanh为双曲正切函数,WC为更新后候选值权重,bC为更新候选值偏置。接下来更新记忆单元的状态,由状态Ct-1至Ct状态,原来状态Ct-1根据遗忘门的值丢弃要屏蔽的信息,根据输入门的值添加新的信息。Ct更新公式如式(5)所示。
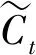
(5)
输出门ot控制输出信息,该门通过xt和上一时刻输出决定从当前状态中输出的信息量,状态Ct通过tanh函数得到区间在-1和1的值,该值乘以ot作为本时刻的输出值。ot和ht的公式分别为式(6)、式(7)。
式中Wo为更新输出值的权重,bo是更新输出值偏置,ht为最终输出值。
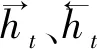
对BiLSTM单元的输出取平均作为语义学习层输出,如式(11)所示。
(11)
2.3 重点词关注层
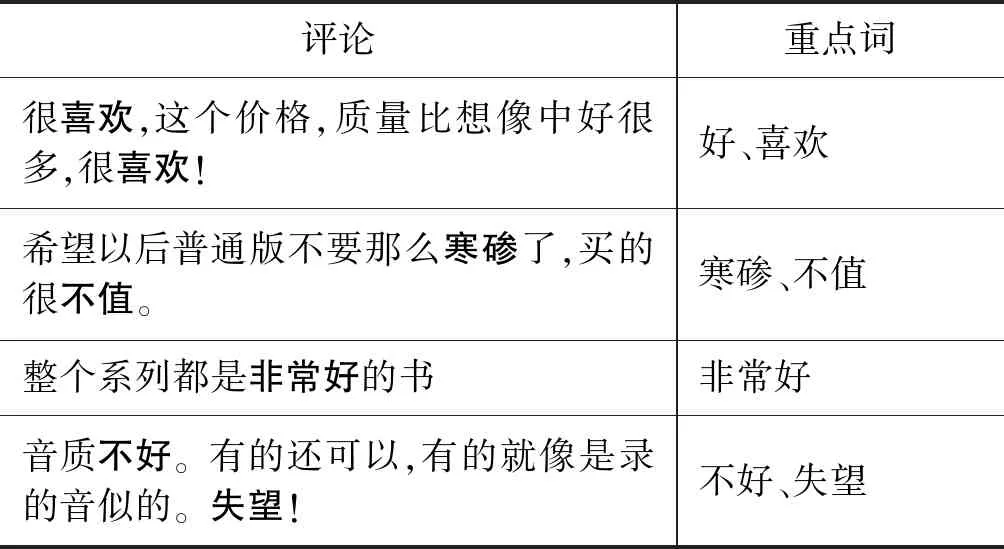
表1 重点词分析
注意力机制最早在计算机视觉领域提出来的,模仿人类的注意力机制,给图像不同的局部赋予不同的权重。后来Bahdanau等[16]将注意力机制应用到机器翻译,这也是注意力机制在自然语言处理领域的首次应用。但是机器翻译中的注意力机制是将前一时刻输出的隐含状态与当前时刻输入的隐含状态进行对齐的模式,而在情感分析任务中使用对当前输入自适应加权的自注意力机制(Self-attention)更合适。Wang等[17]把自注意力模型应用到方面级(Aspect-level)情感分析任务上,将自注意力机制与LSTM结合在一起,通过自注意力机制去获取对不同方面更重要的上下文信息,来解决某个给定的方面情感分类的问题。自注意力机制通常也不会使用其他额外的信息,它会自动从所给数据中学习权重分布,如式(12)、式(13)所示。
其中at表示第t个词对于当前文本的重要程度,vtA作为一种评分制度由模型从语料中自动学习,A、W均为权重矩阵,b为偏置。得到每个词的权重后,假设句中词数为T,将词向量按权重求和作为重点词语关注层的输出,如式(14)所示。
(14)
2.4 分类层
文本情感分析本质上是一个分类任务,所以模型的最后一层是分类层。分类层将语义学习层和重点词语关注层的结果连接作为输入:
inputclassify=[outputsema,outputatt]
(15)
输出每类的概率为pc:
wclassify为L×C的权重矩阵,L为输入向量的维度,C为类数,bclassify为分类层的偏置向量。在得到预测的概率分布后,本文采用交叉熵损失函数来衡量真实分布和预测分布之间的差距,从而利用反向传播对模型中的参数进行更新。
3 实验与分析
3.1 实验数据
本文的实验数据为NLPCC2014情感分析(NLPCC-SCDL)评测任务中文数据集。该数据集中,共收集12 500条中立、负面均衡的网购商品评论。从语料随机选取中立、负面数据1 250条作为测试数据(共2 500条),其余作为训练数据。实验语料采用Jieba分词工具进行分词,分词后句子长度分布如图3所示。
与此相似,在现实生活中,我们干掉高考这个BOSS以后,武功进入了一个瓶颈期,每个人的斗志也因此消磨许多。所以,我们不妨试着将这四年的大学时光,当作是一段特殊的“闭关修炼”,修身养性,格物致知,潜心修炼内功和外功。在不断提升自我的同时,抵御绑定了潜在风险的外来诱惑。
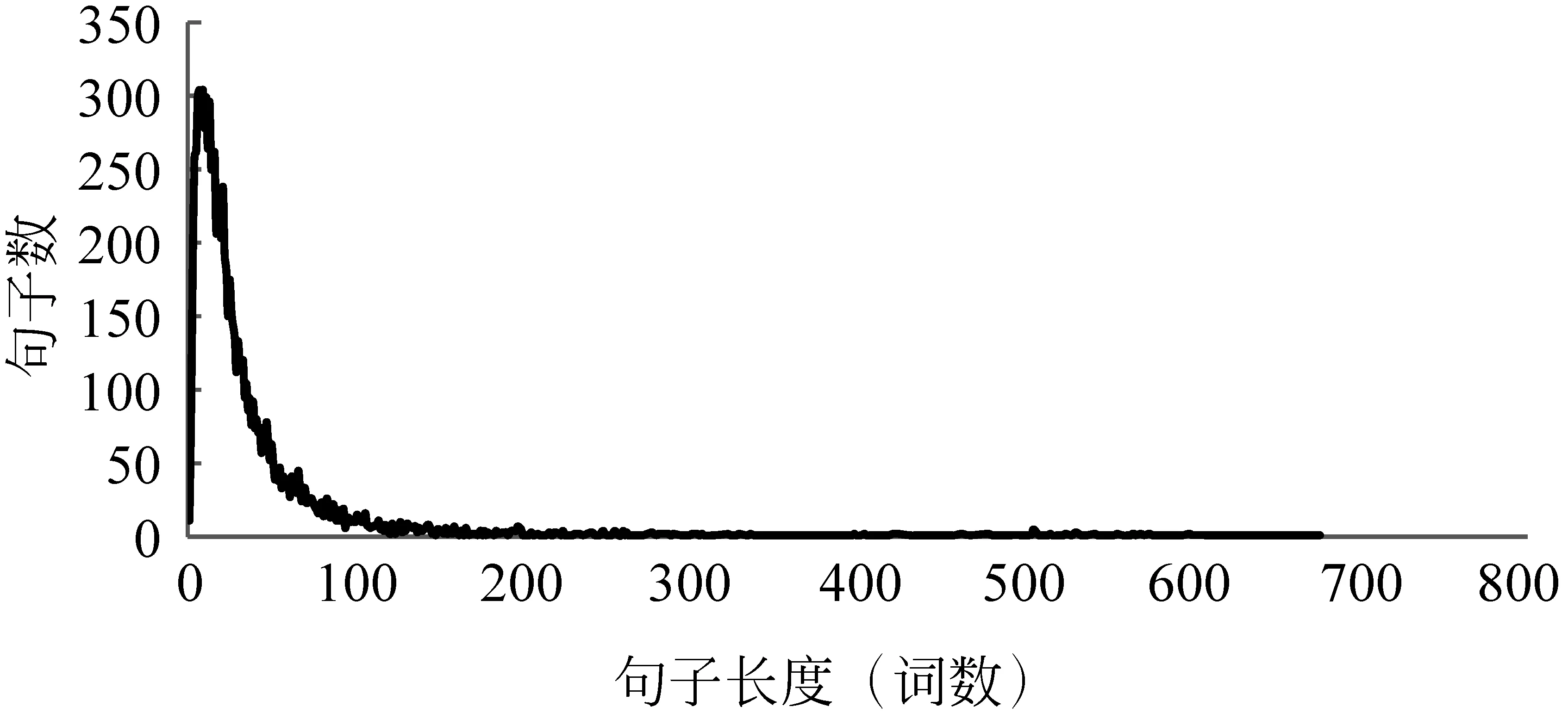
图3 语料句子长度分布
本文选用维基百科的中文语料作为预训练词向量的语料库。因为中文维基百科语料中含有大量的繁体字,所以需要先对语料进行繁简转换,再使用Jieba进行分词。本文利用Google开源的Word2Vec工具预训练词向量,选择cbow模型,上下文窗口大小设置为5,词向量维度大小设为200,采样值大小设为0.001,其他参数使用模型的默认值。在使用预训练的词向量时采用随机初始化
3.2 评价标准
本实验采用正确率(Precision)、召回率(Recall)、F1值(F1-measure)、准确率(Accuracy)作为评价标准(下标neu和neg分别表示中立和负面)。
TP: 正确分类中的中立条数;
FP: 错误分类中的中立条数;
TN: 正确分类中的负面条数;
FN: 错误分类中的负面条数。
3.3 实验对比模型
NBOW: Mikolov提出的神经网络词袋模型。该模型将句中的词向量的平均值作为句子表示,在文本分类任务中的效率很高。
CNN: 基于Kim等人提出的CNN分类模型,使用卷积核大小为1、2、3分别提取文本特征,经过最大池化后使用softmax进行情感分类。
CNN+SVM: Cao等人提出的使用CNN提取文本特征,使用迁移学习的思想,利用SVM进行文本分类。该模型在NLPCC-SCDL任务上取得了最好的效果。
CNN+EMB_ATT: 冯兴杰等人提出的基于词向量注意力机制的卷积神经网络模型。
LSTM: 使用LSTM进行语义学习,将每个输入对应的输出取平均作为文本表示。
LSTM+ATT: 使用LSTM进行语义学习,使用自注意力机制学习LSTM输出的权量,最后将LSTM的输出加权平均作为句子的向量表示。
BiLSTM: 使用BiLSTM学习文本语义,将每个输入对应的输出取平均作为文本表示。
BiLSTM+ATT: 使用BiLSTM进行语义学习,使用自注意力机制学习BiLSTM输出的权重,最后将BiLSTM的输出加权平均作为句子的向量表示。
BiLSTM+EMB_ATT: 本文提出的注意力增强的BiLSTM模型。
3.4 实验参数
因为模型输入需要一定的长度限制,根据3.1节中的语料句子的长度分布,将模型输入文本的最大长度限制在100个词,超出100个词的句子截取前100个词,不足的用
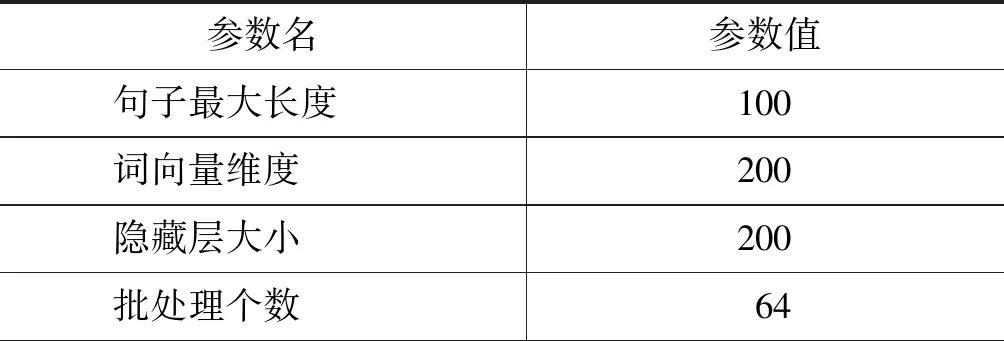
表2 模型中的参数设置

续表
3.5 实验结果及分析
本实验在服务器上进行,服务器CPU为2个英特尔至强(R)处理器E5-2603v4,GPU为NVIDIA Tesla K40M。在训练阶段,将训练数据分为5份做交叉验证,最终实验结果取5次实验的平均值。实验结果见表3。
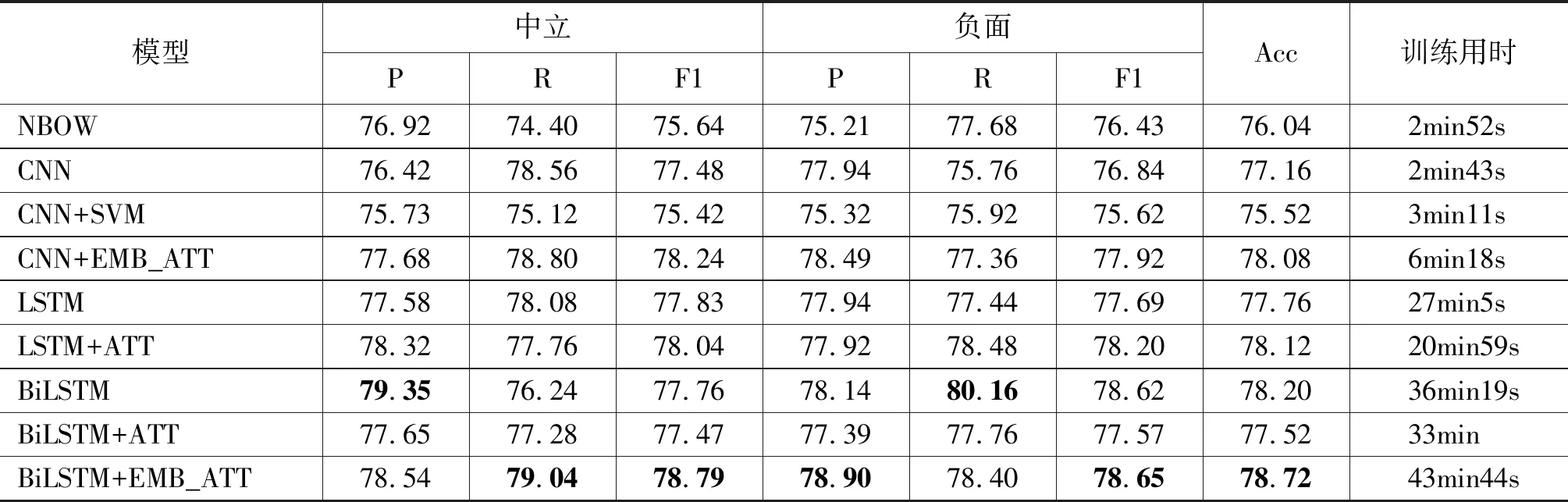
表3 实验结果
从表3中可以看出,本文提出的BiLSTM+EMB_ATT模型在除中立准确率、负面召回率两个指标之外,其他指标均取得最好的结果。因为自然语言存在时序性的特点,LSTM模型中的记忆单元有效记录了文本时序信息,本文采用BiLSTM结构学习文本的语义信息,为模型中增加了逆向文本的语义信息,加强了模型对文本上下文的语义学习能力。但LSTM模型只是理论上可以持续记忆文本信息,从实际效果上看LSTM依然存在着不足,而自注意力机制在情感分析的任务需求上,可以通过学习文本规律,以分配不同词语相应权重的方式自动捕获影响文本情感倾向重要信息。为了便于观察文本中的注意力分布,本文将权重输出,如图4。所以可以使用注意力机制作为辅助的方式从文本中得到更多的信息。通过在BiLSTM模型上加入基于词向量的注意力机制,结果得到了提升,验证了可以使用注意力机制加强模型直接从词向量中学习文本信息的想法。
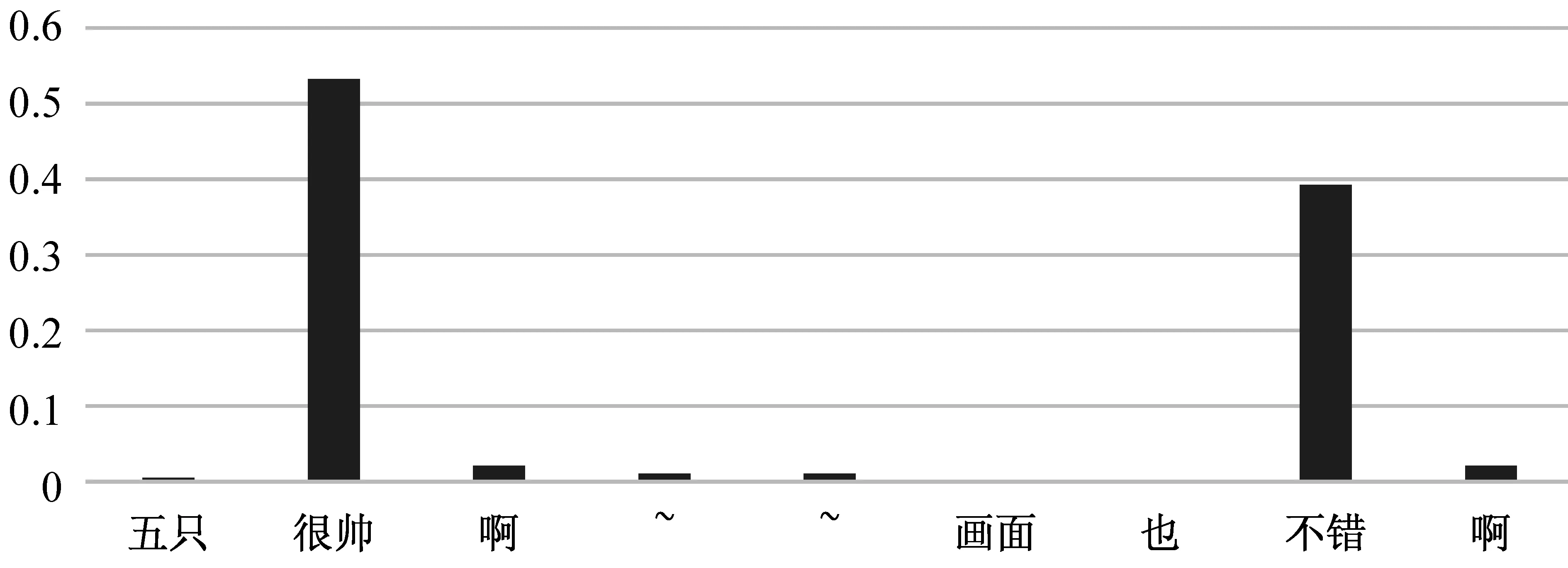
图4 注意力分布图
另外,根据实验结果还可以得出结论:
(1) CNN和CNN+SVM的结果说明了在该实验语料上,使用SVM代替softmax分类器的方式并不能提高结果。因为softmax分类会使用一层全连接网络对特征进行学习,在最小化损失学习后,softmax可以让概率分布更接近标准结果。
(2) 在LSTM模型和BiLSTM模型上,直接加上注意力机制的结构训练用时更短。这说明注意力机制虽增加了模型的规模,但其关注关键信息的特性使得模型的收敛速度更快。
(3) 在LSTM和BiLSTM模型上增加注意力机制并没有达到相同的效果,这说明盲目加入注意力机制有时不会使结果更好。相反,我们在CNN上,加入基于词向量的注意力机制的CNN+EMB_ATT模型和BiLSTM上加入基于词向量的注意力机制的BiLSTM+EMB_ATT模型的效果都得到了提高,这也验证了正确地加入注意力机制有助于模型效果的提升。
4 总结与展望
本文提出了一种注意力增强的BiLSTM情感分析模型。将BiLSTM学习文本的语义信息使用在词向量上,建立自注意力机制加强对句中情感关键词的关注度。与传统BiLSTM模型加注意力机制不同,本文采用的词向量注意力机制与BiLSTM为并行结构。实验表明,本文提出的模型表现出优越的性能,并在多个指标上超过了已有的最好模型。
在深度学习流行之前,前人构建了很多如HowNet等知识库,这些知识是自然语言处理领域的巨大宝藏。现在很多学者都在尝试如何利用这些知识库,在后续的研究中,我们也将深入研究如何用现有的语言学规则和知识库提高注意力增强的BiLSTM模型的效果。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小雪花·成长指南(2022年1期)2022-04-09
通信技术(2021年12期)2022-01-25
甘肃教育(2020年22期)2020-04-13
开放教育研究(2020年2期)2020-03-31
计算机应用与软件(2018年9期)2018-09-26
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
中国修辞(2017年0期)2017-01-31
第二课堂(课外活动版)(2016年2期)2016-10-21
长江学术(2016年4期)2016-03-11
