
基于依存语法的祈使句分类研究
2019-04-01 12:44:02涂锦宇
计算机应用与软件 2019年2期
涂锦宇 朱 敏
(华东师范大学计算机科学与软件工程学院计算中心 上海 200062)
0 引 言
在人机交互过程中,系统的第一步就需要理解人类自然语言传达的含义。人类向机器传达的自然语言存在着多种句式。针对汉语问句这一句式,研究者们利用问句依存语法分析[1],在智能问答系统的模型中如何进行特征提取和分类进行了研究。而在智能驾驶、智能家居等其他领域中,祈使句这一特殊的自然语言类型,在常规的人机交互的自然语言中也占着较大的比重。人类向特定系统传达自然语言指令,需要被不同的功能模块接收,例如“把电饭煲切换成保温模式”这句指令,在经过初步的信息分拣后,应被分入厨房模块进行继续加工,卧室、客厅等其他模块就无需对这句话进行处理。如何将收集的命令式的自然语言信息进行分拣,成了一个亟待解决的问题,而以祈使句为对象的自然语言处理研究却很少。因此本文提出了一种基于核心词语义方法,该方法利用祈使句这一特殊的句式语法依存关系,对语义依存树进行剪枝操作,提取其核心动词以及核心名词,构建词库进行分类。
1 相关研究
1.1 依存语法
在依存语法模型理论中,将以句为单位的语料划分为一棵依存语法树,句中唯一确定一个核心词作为语法依存树的根,支配着句中其他所有的词,且每个词的父节点有且仅有一个,其余的词直接或间接依赖于这个核心词,在依存语法树中表现为树的子节点或叶子节点。将每一句祈使句转化为依存语法树,是提取祈使句核心词汇的必要前提。
1.2 短文本特征提取
常见的文本分类在完成分词和停用词等预处理之后,往往将文本词袋化。普通文本中可以使用文档频率DF、信息增益IG等多种方法[2]提取词袋特征。而短文本,包括句子(陈述句、问句、祈使句)具有分词少、缺乏信息量、词袋特征稀疏的特点,相较于长文本难于进行分类。基于LDA主题扩展的方法[3],补充了短文本中较少的文本特征,增加了特征维数,使得分类准确率有所提升;也利用卡方统计和知网文本相似度计算的方法[4],预先筛选出对某个测试数据分类结果产生影响的若干样本,再进行短文本分类。然而,上述一些方法都将文本看作词袋模型,在简化问题的同时,与自然语言的实际结构不符,即忽略了词序、句法以及语法等信息。本文针对祈使句的语法特性,进行语义依存分析,从句子对应的依存语法树中提取特征,达到特征提取和特征扩展的目的。
1.3 文本的表示方法
传统的One-Hot文本表示方法将每个词语表示成一个维度为词典大小的向量,向量的每一个分量表示为该文本中是否有该词汇。这样产生的One-Hot向量配合向量分类效果较好的常用的SVM[3]、KNN[4]等分类算法能基本完成一些自然语言处理中的分类任务。然而这样的词语表示方法有很大的不足,例如向量维数过大容易造成维数灾难;无法完整刻画词与词之间的相似性,造成词汇鸿沟等。而Mikolov等[5]提出的词向量是一种分布式的词语表示形式。通过语料学习,将每个词映射到预先设置好维数大小的实数向量中,词向量维数一般在几十到几百之间,远小于语料中词典的大小,从而解决了One-Hot表示方法产生的维数灾难和向量系数的不足。同时词向量的距离也能否反映词向量所对应的词在语义上的相似度。
2 基于依存语法的祈使句分类实现方法
2.1 基本步骤
在语义依存树构建时,将语法树的构建转化为序列标注问题,并修改编码方式,对句法树的剪枝操作以完成核心词提取。相关领域语料库训练出的词向量来表示提取的依存关系核心词与样本中的核心词产生的词向量进行相似度计算,以实现祈使句的分类。具体流程如图1所示。
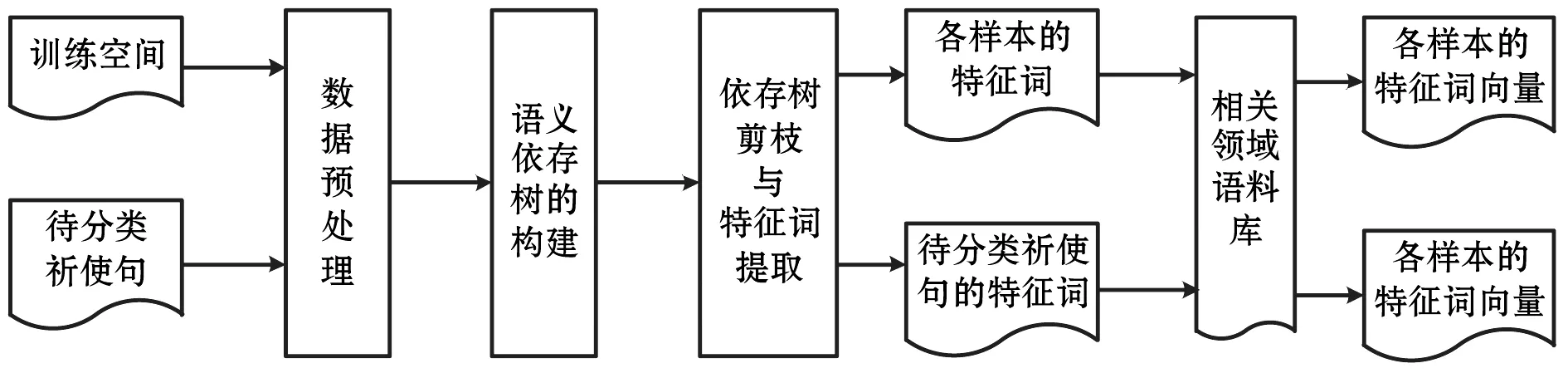
图1 基于依存语法的祈使句分类方法流程图
2.2 语义依存树的构建
在“清华大学语料依存关系集合”[6]中,定义了包括核心关系在内的59种依存关系,通过标注语料编码的方式,将语义依存树的生成问题,转化为常见的序列标注问题,利用条件随机场的模型进行训练,具体过程如下:
对于一句含有n个词的祈使句,将其视作为随机变量序列X=(x1,x2,…,xn),为了方便求得序列标注的随机变量Y=(y1,y2,…,yn),根据已标注的语法依存树,将利用支配词距离编码的方式,来实现特征随机变量的降维,组成标签集合T,其中y1,y2,…,yn∈T。
根据文献[7]中提出的特征模板,提取一元特征特征函数su(yi,x,i)以及二元特征函数tb(yi-1,yi,x,i):
(1)
(2)
计算各随机变量分布的条件概率:
(3)
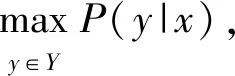
2.3 核心词的提取与句法树的剪枝
核心词用于体现祈使句的特征,传统的句法树的序列标注类标过于复杂,影响特征函数训练时间,因此需要将句子中与祈使句分类特征相关的核心词重新编码标注,缩短训练时间。核心词的选取原则是需要使得核心词与祈使句分类标签存在显著联系,根据祈使句语法构成的不同,定义特征依存关系集合DEP={受事、内容、关系主体、类指、处所、存现体、参照体}[6],提取某祈使句Imp的核心词集合动词集合coreVerb和名词集合coreNouns规则的伪代码如下:
Fun(Imp)
coreVerb.add(Imp.root);
node=Imp.root;
while(node←node.child)
if(DEP.contains(node.deprel)&node.lemma=‘noun’)
then coreNouns.add(node.word);
return coreVerb, coreNouns;
End Fun
本文根据提取核心词结果,总结归纳出特征形式主要分为以下三类:V型、VN型和VNN型。
2.3.1 V型
针对祈使句这类自然语言,每句祈使句对应的语法依存树的根,也就是核心关系的词,都为动词,且这一核心动词蕴涵了祈使句中的类别的信息。例如“快停下”句中,核心动词为“停”,因此将每句祈使句的核心词列为判断其类别的特征值之一。
2.3.2 VN型和VNN型
这一核心动词连接的子节点,直接依存于此核心动词的受事等名词,代表了核心动词操作的对象以及结果,对于类别区分,也存在贡献。例如VN型“开启雨刷”的语法依存树:核心动词:开启;核心名词:雨刷。如图2所示。
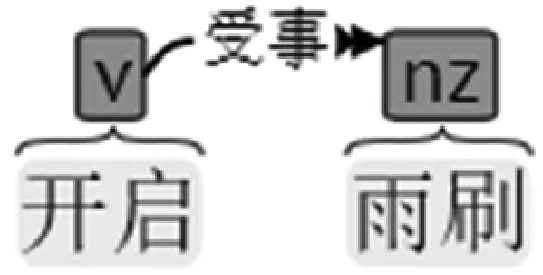
图2 VN型语义依存树举例
VNN型“把电饭煲切换成保温模式”的语义依存树:核心动词:切换;核心名词:电饭煲、保温模式。如图3所示。

图3 VNN型语义依存树举例
由于在语义依存树中,其他分词在分类时属无关信息,因此可以根据此类原则对语义依存树进行剪枝操作。
2.4 分类方法
在提取语义依存关系核心词后,本文采用了基于One-Hot表示方法和基于词向量的分布式表示方法的多种分类算法。
2.4.1 基于One-Hot的分类方法
将每个出现过的核心动词和核心名词排列,组成一个共有n个词的词典D=[d1,d2,…,dn],再根据每个类别的核心词库BPi=[bpi1,bpi2,…],BPi是词典D的子集,定义类别向量VPij:
(4)
将测试集T={t1,t2,…}中每个句子的核心词BTk=[tpk1,tpk2,…]⊆D取出后,根据词典向量,生成一个祈使句向量,公式如下:
(5)
由于类别特征向量和每个句子向量维数统一,都为词典中词的个数,利用余弦距离:
1≤j≤n
(6)
和Jaccard相似度[8]进行样本与类别向量之间的计算, 计算方法为祈使句向量与类别向量的交集元素个数与并集元素个数之商:
(7)
同时针对样本个体,利用生成的核心词向量,对文献[2]中总结的SVM和KNN分类方法进行分类。
2.4.2 基于词向量的分类方法
在词向量训练模型中,相关度在朴素假设的前提下[9],即特征之间相互独立的情况下,两个多元变量之间的互信息,等于两两单变量之间的互信息之和,因此互信息是可加的。即:
(8)
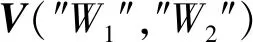
在计算提取了m个语义依存核心词的待分类祈使句S和有n个语义依存核心词的类别C的相关性:
(9)
并选择相似度最大的类作为最终分类类别。
3 实验与分析
3.1 实验背景
针对各大高校开设的Office办公软件课程,为了减轻阅卷老师重复机械的阅卷工作,目前已开发出不少计算机操作题的判题系统进行阅卷。文献[10]中目前的阅卷系统分为大两类:一类基于VBA实现,针对每套试卷,录制标准答案相关的一系列宏,利用宏进行批阅;另一类方法基于微软制定的组件对象模型COM标准实现,通过C#等编程语言的编程实现对Office文档中COM节点及其属性的访问,并与标准答案对应的COM节点及属性进行匹配的方式来批阅试卷,在利用此类方法的实际阅卷过程中,不需要对判题函数做出频繁的修改。
然而针对不同的考题,由于考点类别不同,调用的判题函数也是不同的。由于考题的句式均为祈使句,且包含了核心关系以外的较多其他依赖关系作为祈使句分类的干扰项,可以利用基于依存语法的分类方法进行考题的考点分类,以便于根据分类后的类别,调用对应的判题函数,进行阅卷。
3.2 实验数据
3.2.1 相关领域语料库
在训练词向量时,需要用到相关领域的语料库。本文利用了近年全国计算机等级考试(NCRE)中MS office操作题和相关的模拟题,以及华东师范大学2014-2017《大学计算机》课程考试中Office操作题考题作为合并作为语料库进行词向量的模型训练,语料库中包含24.8万词。
3.2.2 祈使句分类数据
在考题祈使句分类中,本文利用了华东师范大学《大学计算机》课程考试2014-2017学年Office Excel操作题考题作为数据集,考题类别由任课老师根据考纲标注。其中每一学年的考题共有10套试卷,每套试卷有17~22题不等的考题,综合覆盖了57个不同的考点。实验采用3年考题作为样本,1年考题作为测试数据的交叉验证方式。
3.3 数据预处理
将考题语料以每道考题对应一个考点为单位进行简单的分割,并将考题结构化,即将考题以考题文本、分值、考试信息等数据存入样本语料库、测试集语料库中,以备在考点分类后的批阅过程中使用。
考题原语料举例:“在工作表1中,计算出各种价格的平均值,并为图表边框设置“内部右下角”的阴影。(4分)”;“为第一行标题添加如样张所示的双线边框。(2分)”
预处理后的结构化存储方式如表1所示。

表1 考题祈使句结构化存储方式举例
3.4 实验结果
3.4.1 语义依存树的生成与剪枝
本文利用选自人民日报的标注好完整语法依存树的20 000句短句,利用剪枝前后的标注方式经两次编码后训练出条件随机场分类模型。根据结构化后的文本内容字段,分别进行分词和编码,编码的序列标签分别为未剪枝与剪枝后,并将编码的结果放入条件随机场模型进行计算,得出序列标注结果如表2所示。

表2 剪枝前后的序列标注结果举例
解码后对应的语义依存树分别如图4-图5所示。

图4 16102号考题语义依存树解析(剪枝前)

图5 16102号考题语义依存树解析(剪枝后)
通过对文献[6]中编码方式针对于祈使句式的简化,重新对分词标签进行编码,减少语法标签,实现对语义依存树的剪枝,从而使训练时间减少约70%。
3.4.2 类别核心词库的生成
根据基于依存语法的核心词汇提取,根据标注的样本标签,汇总到每个考点,每个考点类别形成了一个由若干词组成的核心词库,如表3所示。

表3 考题类别核心词库举例
3.4.3 词向量的训练
利用Google的开源工具包Word2Vec在NCRE试题及模拟题和计算机基础课操作题的语料进行分词、停用词删除和数据清洗之后训练,词向量维数为200。训练出的词向量以“行楷”、“函数”两个词为例,分别与其语义相关性最大的相关词结果如表4所示。
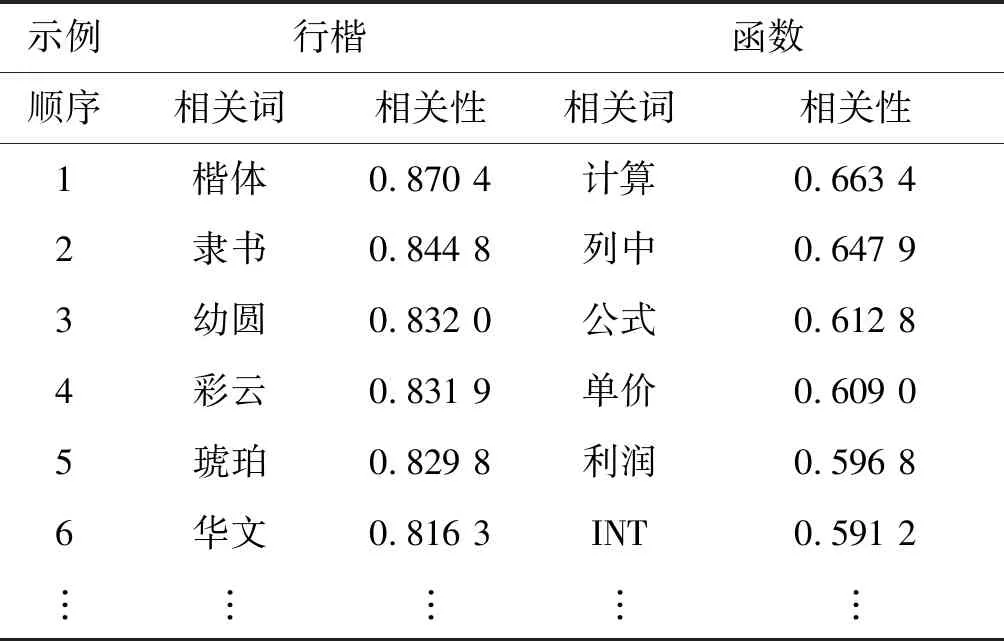
表4 基于词向量的语义相关性计算结果举例
3.4.4 分类结果与分析
根据核心词汇的提取与统计,One-Hot核心词典中共286个词,分别将考点核心词库和测试集中考题语料向量化后进行基于类别特征的余弦相似度、Jaccard相似度的计算。同时将待测文本向量在样本空间中进行KNN和SVM算法分类,并利用卡方指数提取核心词作为对比实验。其中KNN和SVM算法均使用实验后效果最佳的参数,Word2Vec词向量表示向量为200维。实验结果如表5所示。
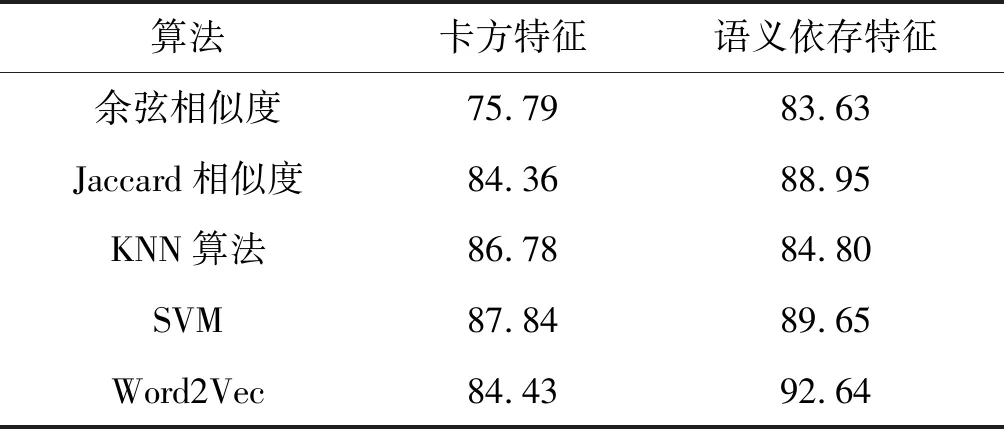
表5 考题分类结果
从实验结果可以看出,提取语义依存核心词,并用这些核心词的词向量进行相似度计算,产生的分类效果最佳。语义依存特征在大部分分类算法的情况下的分类效果都优于卡方核心词。因此语义依存核心词的提取,更能在祈使句中刻画句子特征。
4 结 语
相比于普通的句子分类方法,本文利用了祈使句的特殊性,运用依存语法特征选取方法,将语义依存的特征信息作为向量权重映射到向量空间,并分别采用了包括Word2Vec相似度和传统分类方法在内的多种方法实现了将祈使句分类。
在实际运用部分,本文以Office Excel考题为例,阐述了祈使句分类算法的实例,即为考题根据考点分类的方法,可以直接推广在其他操作类主观题自动评阅系统中,以减轻评阅教师为自动评阅系统标注分类考点的压力。还可以用于将考题分类结构化,实现自动出题、分析考试错误率分布情况等方面。
除了考题考点分类之外,针对其他领域的祈使句类型,本文的方法还可以运用于智能驾驶、智能家居等领域的自然语言命令预分拣模块,从而简化系统,减少系统不必要的负荷。
本文的方法也有不足之处。对相关领域语料有一定规模的要求,完全影响到生成的词向量的质量。同时对复合类别的祈使句类别分析效果欠佳。
猜你喜欢
保健医苑(2022年5期)2022-06-10 07:47:22
中学生数理化·中考版(2021年12期)2021-12-31 03:24:36
中学生数理化·中考版(2021年11期)2021-12-06 07:29:12
成都信息工程大学学报(2021年6期)2021-02-12 03:00:54
高中生·天天向上(2018年3期)2018-04-14 09:39:52
学生天地(2017年4期)2017-05-17 05:48:29
天津诗人(2017年2期)2017-03-16 03:09:39
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
