
基于自动文摘的作文素材标签提取方法研究
2019-04-01 12:44:00朱晓亮吴逸尘
计算机应用与软件 2019年2期
朱晓亮 吴逸尘 殷 姿
1(华中师范大学国家数字化学习工程技术研究中心 湖北 武汉 430079)2(华中师范大学教育大数据应用技术国家工程实验室 湖北 武汉 430079)
0 引 言
语文课程标准[1]以及语文学科研究者均明确强调,在小学语文作文中要加强写作素材的积累,并使学生能结合自身实际加以利用[2]。然而,当前语文作文教学中提供的素材数量庞杂且缺乏组织,在小学生有限的认知能力之下,若不经过加工直接推送,极易造成认知过载以至于引发学习迷航。因此,在当前小学中高年级语文写作教学过程中,缺少有效的作文素材资源辅助,这就要求在小学语文学科作文领域的信息化建设中,把握好优秀作文素材的存储管理工作,并且能够为个性化的作文素材提供数据支撑。
对小学语文作文素材的存储,借助知识图谱[3]的概念,将各个优秀作文语料视为本体的同时,必然会涉及到如何对本体进行有效的属性描述。而能够从作文语料本身抽取属性,即作文的标签,则是描述的核心内容。一方面,传统的标签抽取策略大部分采用关键词抽取方案,没有做到对作文语料的合理安排,即缺乏对小学语文作文标签的定义。另一方面,原始语料文本中包含的大量冗余信息也会对文本的关键信息抽取产生干扰。
综上所述,文本利用自然语言处理中文本自动摘要的方法去除冗余,并在定义了小学语文作文语料标签的前提下,提出了一种基于自动文摘技术的小学语文作文语料自动标签抽取方法。
1 相关技术研究
1.1 作文自动摘要方法
1.1.1 自动摘要
在对小学语文作文原始语料的处理过程中,为了使语料能更好地表达文章中心思想,则需要对原始语料进行去除冗余操作,其中,最常用的方法是文本自动摘要。自动文摘最早于1958年由Luhn提出,起初没有得到较高的关注度,但随着信息时代数据的爆炸式增长,人们逐渐意识到自动文摘对于文本去除冗余、提取中心的重要性。
自动文摘主要过程为文本分析、信息选取及文摘语言转换[4],从不同角度可以分为不同类型,从文摘的获取方式上可分为抽取型文摘和理解型文摘。抽取型文摘主要是从原文中选取合适的句子组成文摘,理解型文摘[5]则是通过对原文进行语义上的分析生成文摘,而理解型文摘因其较为深入的自然语言特征,一直处于技术攻坚阶段,故不具有实用性。本文采用抽取型文摘的技术方案对语料进行预处理。
图1为抽取型自动摘要的一般流程。其中,预处理环节主要对文本内容进行编码及断句处理。特征分析阶段则通过不同的分析方法获取原文中句子的权重,再通过对权重排序,选出适量句子,重新排序后输出。
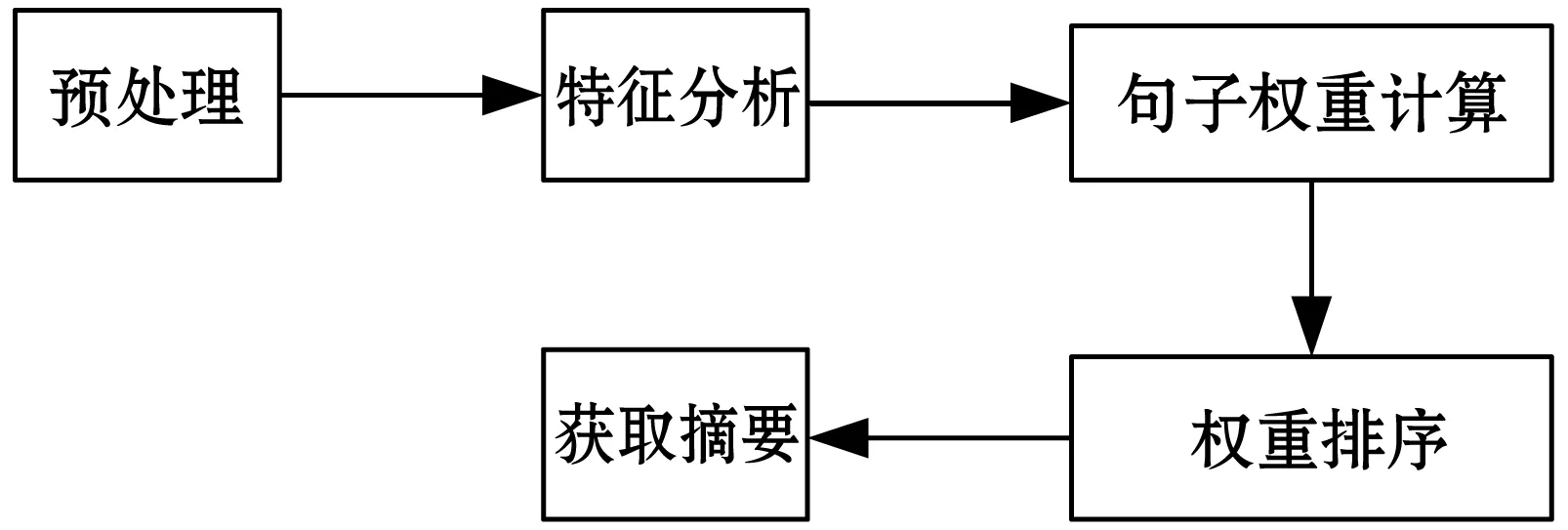
图1 抽取型摘要的一般流程
1.1.2 作文自动摘要
目前主流的抽取型文摘方案来自于Rada Mihalcea和Paul Tarau提出的TextRank算法,是对谷歌基于图的网页权重计算方法PageRank加权重演变而来[6],主要用于关键词抽取和文摘句抽取[7]。
TextRank算法分为计算相似度和排序两个部分,对于一篇语料而言,首先将句子分离出来,依据PageRank的思路建立图。其中,图的节点就是句子,节点之间的权值就是句子之间的相似度。然而,选择不同的相似度算法,对TankRank产生的最终结果也有不同影响[8]。因此,本文比较了几种主流的相似度计算方法,进而选择出一种最适用于作文语料处理的自动文摘方法。
1) 经典相似度算法。该方法借助于两个句子之间的共有词语来达到整体相似度计算的目的。
2) 基于编辑距离的相似度算法。该方法的核心思想为计算从一个子串转移到另一个子串所需要的最小步骤,主要操作为“替换”、“插入”和“删除”。通常认为,两个子串的编辑距离越小,相似度越大。
3) 基于Word2Vec的相似度算法。Word2Vec可用于对文本进行词语聚类,获取关键词[9]。其主要思想是将自然语言中的词汇,映射到一个共同的维度内,使之成为一个个具有统一意义的短向量[10]。本文首先需要训练基于Skip-Gram+HierarchySoftmax的模型,然后获取词语之间的相似度关系,最后推算出句子间的相似度。
4) 基于BM25的相似度算法。BM25算法基于概率检索模型,其核心思想为解析搜索词,生成对应的语素信息,并将语素与文档进行比对,最后由每一个比对结果进行加权求和得到最终的相似度。
本文采用ROUGE对这四种相似度算法进行评价。ROUGE是由Chin-Yew Lin在2004年提出的一种针对自然语言处理的自动评价方法[11],在其评价指标中,Precision用于描述机器摘要的准确率,也被称为查准率;Recall用于描述机器摘要的召回率,也被称为查全率;F-Score是Precision与Recall的加权平均值,反映了机器摘要结合准确率和召回率的统一分数。通过对1 410条数据进行摘要处理,得到测试结果如表1所示。

表1 四种自动摘要相似度算法的ROUGE评分结果

续表1
从表1中可以看出,基于Word2Vec的相似度算法在F-Score上的得分较低。基于编辑距离的计算方法在准确度上得分较高,基于BM25的计算方法在查全率上得分较高,并且,两者在最后的F-Score得分上相差不大。经典相似度计算方法在各个指标上均获得了较合理的分数,类似的情况也体现在ROUGE-2、ROUGE-W的评分方法中。
但在实际的标签抽取过程中,由于语料内容繁多,因此对时间效率也有一定的要求。本文在测试时,也对这4种算法的时间消耗做了记录,结果如表2所示。

表2 四种自动摘要相似度算法的耗时
从表2中可以看出,BM25算法虽然在ROUGE得分上不是最高的,但在计算的时间效率上领先较多。在F-Score相差甚微的前提下,本文最终选取BM25算法作为作文语料自动文摘预处理的相似度算法,并得到基于TextRank算法的作文语料抽取型自动文摘结果。
1.2 基于摘要的作文标签获取
1.2.1 分 词
在进行标签抽取之前,需要将句子以词汇组合的形式呈现,在自然语言处理中,通常采用中文分词的方法加以实现。目前主要的分词方法有基于词典的方法和基于统计的方法,由于基于词典的方法在算法复杂度以及分词速度上更具有优势,故本文选取基于词典的分词方法进行分词处理。
在基于词典的分词方法中,选择基于N-最短路径的分词算法作为主要算法。其基本思想是根据词典,顺序匹配出在中文字串中所有可能的出现的词的集合[12]。相较于传统分词算法,其特性更适合发掘命名实体,故最适合本文分词方案。
1.2.2 命名实体识别
在小学语文作文标签抽取的过程中,需要对经过分词处理后的作文语料进行词性标注,识别出能够代表作文类型的词语,这就涉及命名实体识别。
目前对中文语料中普通的人名、地名等命名实体识别的研究中,中科院俞鸿魁等设计的一种层叠隐马尔可夫模型就能达到不错的效果。层叠隐马尔可夫模型由三层隐马尔可夫模型构成,自下而上分别是人名识别HMM、地名识别HMM和机构名识别HMM。
通过对作文语料的观察发现,机构名出现的频率并不高,因此本文将重点关注人名和地名的识别。基于层叠隐马尔可夫模型中关于人名和地名的部分标注角色见表3。

表3 人名及地名的部分角色标注
利用层叠隐马尔可夫模型可以高效地识别小学作文语料中的重要人名地名,从而协助标签抽取过程中的作文分类标签的获取。
1.2.3 词典设计
在实际处理作文语料时发现,一些特殊名词如“父亲”、“母亲”等,命名实体识别模型不会对其作出实体判断。但实际上,这些词语应归类于人物描写标签的范畴。另外,一些地名中包含的名词出现频率较高,分词模型可能会对其进行单独分类。为了避免这些情况,本文提出了一种自定义的词典内容来协助标签抽取。针对人物相关名词,本文结合实际经验,借助不同类型名词分类建立专属词典,与命名实体识别模型相结合达到更准确的结果。具体分类见表4。
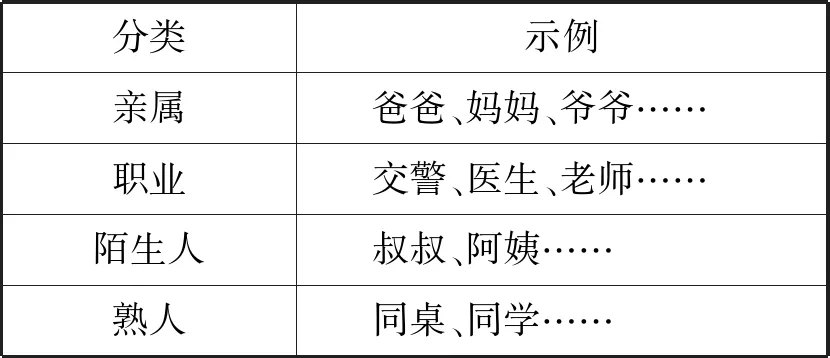
表4 人物描写类型自建词典
针对地名的情况,可依据词缀来进行相应识别,具体分类见表5。通过对实际语料分析表明,小学语文作文中对家乡的描写一般以风景为主,故把其归类到景物描写中。
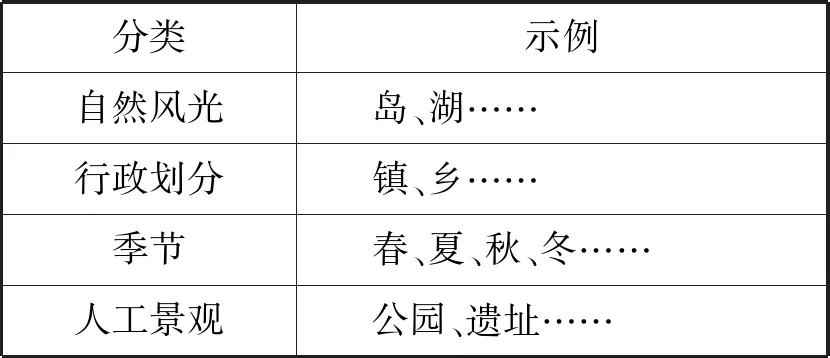
表5 景物描写类型自建词典
2 基于自动摘要的作文标签抽取策略
前一节针对摘要的自动获取方法以及标签抽取过程中所需要的分词、命名实体识别以及词典设计等技术方法进行了比较与分析。本节将介绍基于自动摘要的作文标签抽取策略,该策略的实现方式如图2所示。

图2 基于自动摘要的作文标签抽取方法
2.1 标签定义
通过对小学作文语料的分析,本文将文章标签总数限制为6个,同时根据标签涵盖的内容将其分为文章类型、核心实体、关键描述三个大类。其中,文章类型指的是小学语文作文的分类,由于小学语文作文的具体类别界限可以从不同维度、不同细分程度来划定,而作文分类并非本文的唯一目的,故后文对文章类型的阐述主要以人物描写和景物描写两个大类进行区分。
核心实体是从文章中获取的最核心命名实体。在人物描写分类中,核心实体是主要描写的人物;在景物描写分类中,核心实体是景物场景。关键描述是文章中频繁出现的形容词或文章中出现的俗语、成语等描述性词语。各分类限制词数见表6。

表6 标签三个分类的词数规定
2.2 抽取实现
分词及命名实体识别基于开源自然语言处理框架HanLP实现,抽取过程如图3所示。

图3 标签抽取整体步骤
命名实体识别在分词的结果上进行,最终以词性标注的方式显示。去除停用词目的在于去除抽取结果中的常用词语,减少对抽取策略的干扰,采用综合停用词表法实现。对于本文所需要的标签词语,其词性类型如表7所示。其中,nr、ns代表最终获取的标签类型中的核心实体的词性,其他词性为关键描述中所涉及的词性。
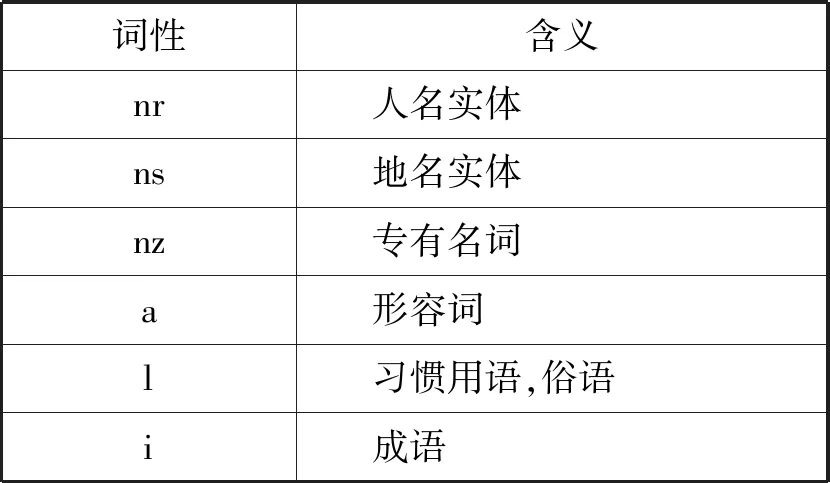
表7 标签抽取重点关注词性及实体
其中,习惯用语、俗语一般为4字以上词语,是为了与文本中字数少且出现频繁的词语加以区分,从而更加精确地获取与文章核心实体相关的描述性词语。将经过命名实体识别后的结果按照词语-词性存储为列表,并按照降序从上而下排列,从高频词开始分析,具体分析过程见图4。
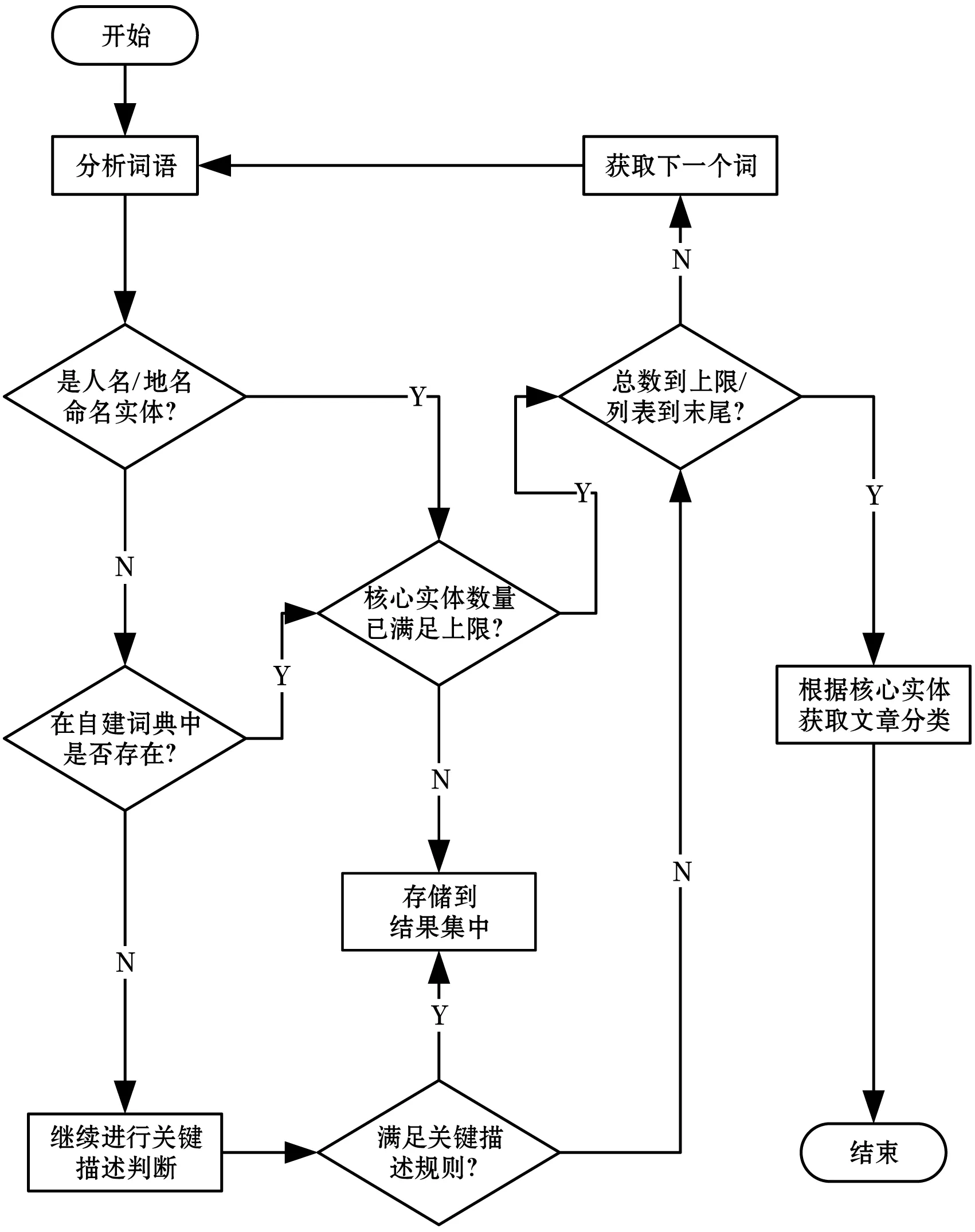
图4 词语-词性列表分析流程
对于核心实体的获取过程主要分为两个步骤,第一,依据标准命名实体识别的方法进行识别,当词语词性为nr/ns时,检查该分类下计数器是否等于上限次数2个,若已达到上限则不作处理,反之将其加入到结果集中。第二,对于进行标准命名实体识别方法后没有标记出的词语,优先采用自建词典配对,若该词语存在于自建词语中,则进行与第一步类似的操作。
获取到的实体除了存储到结果集中以外,还需要记录词频来表示该实体所属类型占的权重,若结果集中核心实体的次数已满足,则后续识别到的词语继续计算权重但不添加到结果集中。若自建词典中也不存在当前分析的词语,则该词语进入到关键描述的判断中,关键描述判断的具体描述规则如下所示,依据以下规则,可以获取到标签分类中的关键描述部分。
关键描述判断流程:
(1) 当前词语长度是否超过2,不满足则输出否;
(2) 当前词语的词频是否大于等于2,不满足则输出否;
(3) 当前词语词性是否为所要求的描述性词语词性,不满足则输出否;
(4) 同时满足(1)、(2)、(3)条件的,判断词语属于关键描述;
(5) 特殊情况下,出现次数超过3次且长度大于等于2的一般名词(词性为n)及专有名词(词性为nz)将被判断属于关键描述;
(6) 当列表读取结束,总标签数仍不满足目标的情况下,对词语列表中词频为1,但字数在4个以上的俗语及成语进行补充录入。
当从列表中获取的标签数已经满足需求或者词语-词性列表已经读取到末尾,则结束词语列表分析。此时,判断命名实体中的两个大类的权重对比,即判断nr.weight和ns.weight,来确定文章类型标签。若nr.weight>ns.weight,则该分类标签为人物描写;若nr.weight 对于抽取标签的结果,没有现行的统一标准。因此,本文设计三个维度来评价抽取的结果,这三个维度分别为分类准确度、实体准确度和形容词准确度,总分值设为6分。 1) 分类准确度用于描述标签中作文分类的正确与否。分类主要为人物描写和景物描写两个大类,正确得1分,错误得0分,该项评分总分1分。 2) 实体准确度用于描述标签中核心实体的正确程度,该项总分2分。由于核心实体标签数量为1~2个,故具体得分情况为:当核心实体标签数量为1个的时候,实体选取正确得2分,错误得0分;当核心实体标签数量为2个的时候,根据正确得数量获取得分。 3) 关键描述准确度用于描述标签中获取到的形容词或重要名词是否合适,该项总分3分。多个形容词情况下,从前至后按词频比求取加权平均值,共划分为4个层级进行评分工作,分别为: (1) 所摘取关键描述与核心实体之间的关联度高,且对核心实体的描述十分贴切,如“险峻”之于“华山”,该情况得分为3分。 (2) 所摘取形容词与核心实体之间关联度一般,但对于核心实体所属类型而言,较为贴切。如“波澜不兴”之于“滇池”,该形容不具有代表性,但对于湖泊而言,相对通用,该情况得2分。 (3) 所摘取形容词于核心实体之间关联度较低,但对于分类标签而言,尚可利用。如“层峦叠翠”之于“太湖”,虽不具有较强关联性,但对于景物描写分类而言,尚有利用价值,该情况得1分。 (4) 所摘取形容词于核心实体之间无关联度,且于分类标签无价值。如“勤奋”之于“死海”,该情况得0分。 本文研究基于上述评分标准,以总分6分,3个维度入手,通过人工评价的方式对标签抽取进行分数评估。通过严格设定各评分段位界定方法,可以有效降低人工评价中主观色彩过强引起的结果偏差。 本文对比测试选择关键词抽取算法,由于对比项为关键词抽取,不具有文章分类能力,故选取5个关键词来与本文标签抽取策略获取的结果进行除分类外的对比。 TF-IDF即词频-逆文件频率,是常用于资讯检索及资讯探勘的一种加权技术,其核心思想为一个词在一篇文档中出现频次高,而在其他文档中出现频次小,则具有代表价值。对应到单文档的关键词抽取中,则将对应句子视为评估单位。 TextRank算法也常被用于关键词提取。为了计算句子之间的关联性,在PageRank的基础上引入了边的权值概念,并运用相应的相似度算法进行计算。而在获取关键词的过程中,若将词视为句子,则所有节点之间的权重变为0,那么TextRank算法的计算就退变回了PageRank算法。 Word2Vec可以将词语转换为语义向量,自然也能运用于关键词提取。本文对比方案利用朴素贝叶斯假设,将句子序列视为词语序列的集合。具体计算词语权重的方法为将序列集合中词语与词语之间的转移概率进行求和操作。 测试数据为小学语文作文共50篇,涉及到的年级为三年级、四年级和五年级。采用人工盲评的方式进行打分,计算结果取平均分,保留小数点后三位最终的得分结果如表8所示。 表8 测试结果 本文提出的标签自动抽取方案在不计算分类准确度的情况下最终得分为2.625分,计算分类准确度的情况下最终得分为3.431分,明显优于常用关键词算法。其中,分类准确度达到80%,能够比较有效地区分人物描写和景物描写。在实体准确度上,本文方案、TF-IDF算法以及TextRank算法在实体准确度上都取得了较好的效果,但Word2Vec的结果却差强人意,这可能是由于在关键词权重计算方法上缺少针对性。 在关键描述的得分结果上,本文得分明显优于其他三类得分,这说明本文所提出的标签抽取策略在该评价标准下取得了较好的效果。一方面是因为本文方案在选取关键描述的时候主动排除了动词的干扰,但是在另外三种算法中却没有体现。另一方面,由于本文方案采用了自动摘要去除冗余,因此能够更好地获取到中心内容,而另外三类算法没有对原始语料进行去除冗余操作,导致一般性动词的大量留存,最终干扰了关键描述的抽取结果。 最后,在对不同年级的评分结果进行比较时发现,高年级的平均得分明显高于低年级,这是因为高年级学生用词更加丰富,更加适合本文方案。当然,在对关键描述的获取上,本文仍有较大的进步空间,但这并不妨碍本方案的可用性。 本文围绕当前小学语文作文辅助中,作文素材的非结构化特征与语料信息化所需要的结构化数据之间的矛盾,提出了基于文本自动摘要的小学语文作文标签提取方法,实现作文语料的结构化组织。 本文对标签抽取过程中涉及的关键技术进行了对比分析,选取了抽取型自动文摘方法、基于词典的分词方案以及有监督的命名实体识别方法等作为主要技术框架。同时,本文尝试给出了小学语文作文标签的定义并根据应用场景设定了相应的评价指标。仿真实验表明,本文方法在小学语文作文领域的标签准确度评估中相较于传统的关键词算法有较大提升。3 测试与评价
3.1 评价指标
3.2 对比方案
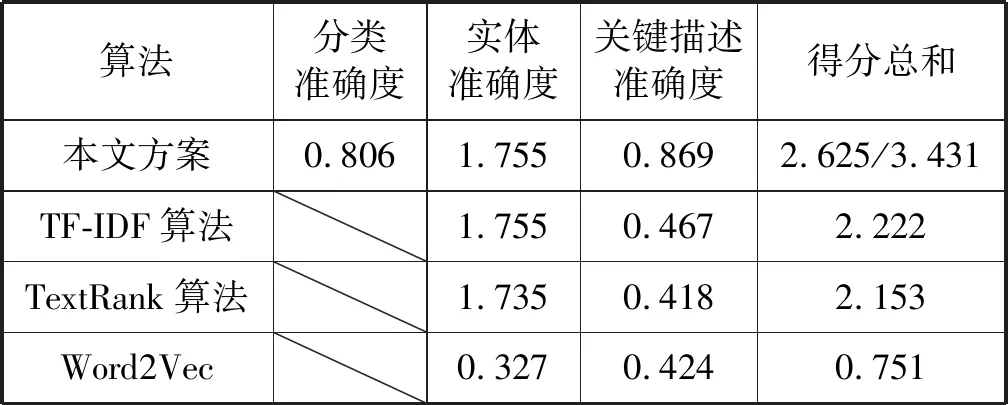
3.3 测试结果
4 结 语
猜你喜欢
环境影响评价(2020年2期)2020-12-02 01:23:50
中国外汇(2019年18期)2019-11-25 01:41:54
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
宝藏(2017年2期)2017-03-20 13:16:46
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
