
基于SGAN的中文问答生成研究
2019-04-01 13:11:04瞿遂春任福继邱爱兵
计算机应用与软件 2019年2期
沈 杰 瞿遂春 任福继 邱爱兵 徐 杨
1(南通大学电气工程学院 江苏 南通 226019)2(德岛大学先端科学技术部 日本 德岛 7708506)
0 引 言
20世纪90年代,Brown等提出的统计机器翻译模型[1]应用于问答系统,提供了有效的相关性特征。2014年, Sutskever等提出基于Sequence to Sequence架构的神经机器翻译模型[2]。由于问答系统可看作是特殊的翻译模型,所以使用Seq2Seq框架来实现问答聊天回复的自动生成成为一种可能。然而国内外研究的对话模型多以英文为主,且多有标准的训练数据集,例如2016年斯坦福大学公开的SQuAD[3]和2018年的CoQA[4]数据集。高质量的中文对话语料缺乏成为限制中文对话模型取得良好效果的关键性因素。为了解决数据集的匮乏,Goodfellow 等[5]在2014年提出一种基于博弈论思想的网络模型,即生成式对抗网络 GAN。该网络由生成器(Generator)和判别器(Discriminator)两部分组成[6]。生成网络和判别网络都可以选用目前流行的深度神经网络结构[7]。GAN网络的优化目标是达到纳什均衡[8],使得生成网络能够预测样本数据的分布。在自然图像和机器视觉领域,GAN的研究与应用是最广泛的[9-12]。
中文问答文本的生成是解决离散序列的问题。起初,GAN被设计用来生成实数连续数据,直接生成离散词序列是十分困难的[13]。另外,GAN只有在生成时才能给出整个序列的得分/损失;对于部分生成的序列,平衡现在和未来的得分作为整个序列得分是很困难的事情[7]。本文仅研究中文开放域问答聊天数据的生成,同时为了解决这两个问题,设计一种新的序列对抗生成网络SGAN,对抗训练出一个生成序列,使得网络生成的序列和人为给出的序列相似,不易被分辨出来。同时本文采用SeqGAN模型[13]中的思想,将对话生成任务视为一个强化学习[14]的问题,选用Actor-Critic策略评估的方法,替换了蒙特卡洛策略梯度算法[15-16]。同时对新网络模型用精准率和召回率等评价标准进行了评价实验。
1 序列生成对抗网络
1.1 序列生成网络结构
本文提出的序列生成对抗网络SGAN是基于GAN模型设计而得的,同样由生成网络G和判别网络D组成。该网络计算流程如图1所示。虚线框中的结构是GAN的计算流程[17]。网络输入分别为真实数据x和随机变量z。如果判别网络D的输入是人为给定的真实数据x,则标注为1;如果D的输入是生成样本数据G(z),则标注为0。判别网络作为二分类来判断样本数据的真和伪。如果判断结果为真,数据来源于x;如果判断结果为伪,数据来源于G(z)。为了使G(z)的样本分布和x表现一致,网络需要经过无限的迭代优化,使生成器G性能得到提升。对抗网络问题实质是一个极小-极大的问题,用表示真实样本数据,是服从均匀分布的随机噪声。GAN对抗优化过程如下:

(1)

图1 SGAN计算流程
1.2 对话生成序列对抗网络
SGAN中的生成器G采用类似于Seq2Seq(Sequence-to-Sequence)模型为主体的问答回复结构[2,18]。该结构使用递归神经网络将源输入映射成一个向量表示,然后使用激活函数softmax计算在目标中生成每个序列句子的概率,损失函数用交叉熵。判别器D实质是一个二分类器,采用CNN网络基础结构[19]。对话序列{x,y}作为D模型的输入,输出一个标签。标签指示输入是人为生成的真实样本还是机器生成的伪样本。在给定一个问题的情况下,生成器G通过编码-解码过程生成一个伪回复,这个伪回复将和问题构成一个负样本,相反,问题与训练数据中人给定的回复构成一个正样本。处理问答序列设计的SGAN模型的对抗框架如图2所示。
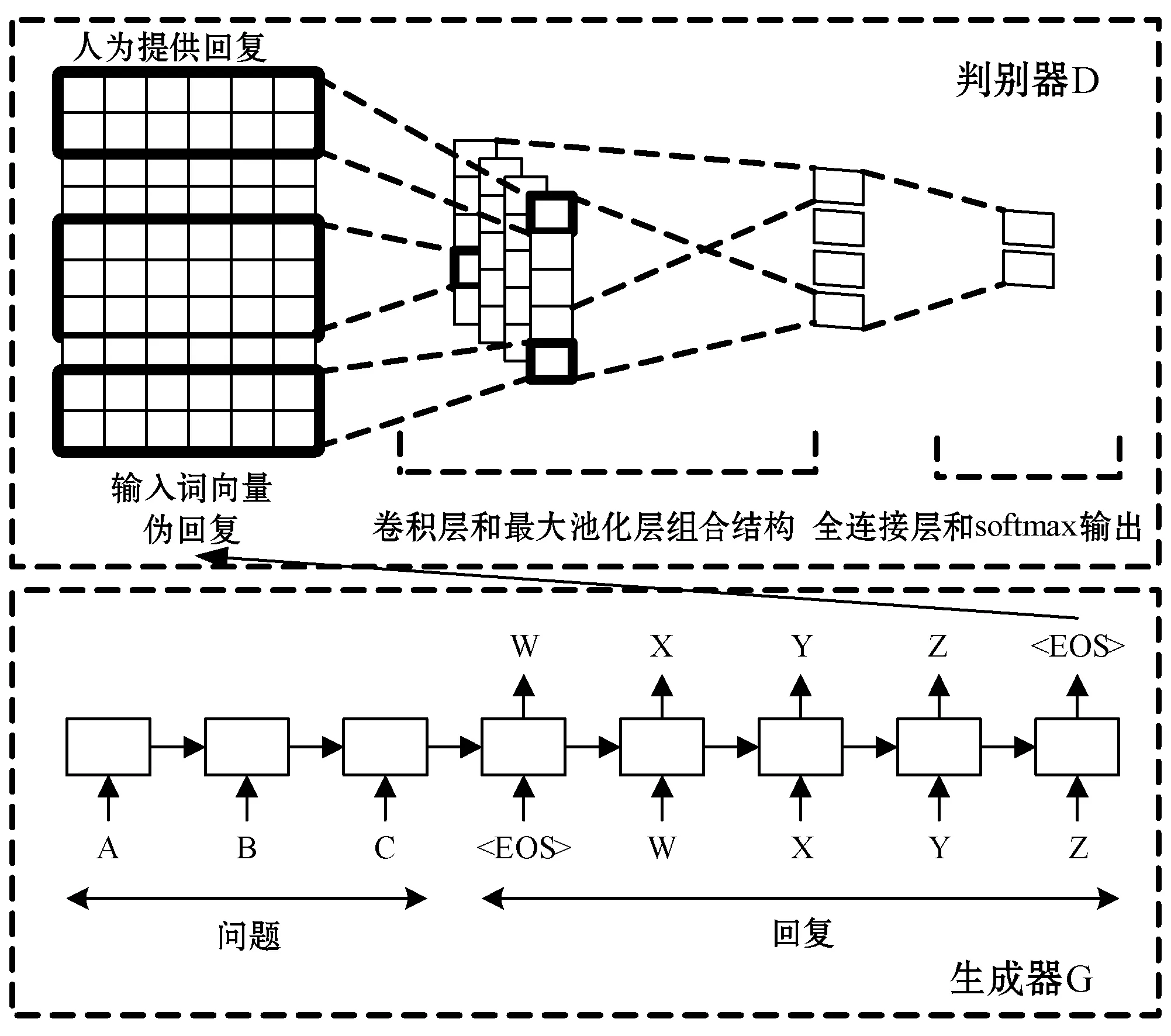
图2 SGAN的对话框架
在SGAN结构中,基于Actor-Critic策略梯度[20]算法来训练生成网络,根据判别器D的输出判别概率通过增强学习来更新D,增强学习的奖励通过D来计算。
1.3 生成网络和判别网络
生成器G模型是基于RNN的Seq2Seq。输入一个序列问题
(2)
判别器D采用CNN卷积神经网络结构。本文重点关注判别器预测完整序列是人为真实样本数据的概率。输入序列x1,x2,…,xt表示为:
ε1:T=x1⊕x2⊕…⊕xT-1⊕xT
(3)
式中:xt是k维词向量,⊕是矩阵级联算子,用内核ω对l个词进行卷积运算来产生一个新的特征映射:
ci=ρ(ω⊗εi:i+l-1+b)
(4)
式中:ρ是非线性函数,⊗运算符是点积和,b是偏值。用不同数量且尺寸不同的内核来提取不同的功能;用最大池化对特征映射ci处理。激活函数为Sigmoid,判别器D的输出是判别出真实样本(标签值为1)的概率。优化目标是最小化值标签与预测概率之间的交叉熵,表示为:
minEY~pdata[log2D(Y)]-EY~G[log2(1-D(Y))]
(5)
SGAN的训练伪代码如下:

Initialize G,D with random weights Pre-train G Generate negative samples using G for training D Pre-train DFor i=1, G-steps do Sample (X,Y) from real data Sample Y^~G(·|X) Compute reward r for (X,Y^) using D Update G on (X,Y^) using rend forFor i=1, D-steps do Sample (X,Y) from real data Sample Y^~G(·|X) Update D using (X,Y) as positive samples and (X,Y^) as neg-ative samplesend for until SGAN converge
2 Actor-Critic策略梯度
序列生成过程是一个连续的决策过程。生成模型被视为强化学习(Reinforce Learning)的主体(agent),状态(State)是目前为止所生成的词,动作(Action)是待生成的下一个词。强化学习的基本流程如图3所示。
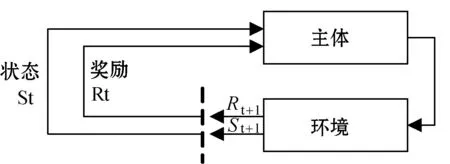
图3 强化学习流程图
Actor-Critic策略梯度与对抗网络GAN结合,可以对网络模型进行多级优化使其稳定,同时Actor-Critic策略梯度方法能够很有效处理强化学习中的序列任务[21]。Actor-Critic是一种近似估计的策略梯度方法,所以会不可避免地引入偏差值,容易使模型出现复杂化或者过拟合的现象。
判别器D用来评估序列并反馈评估,以指导生成模式。用Actor-Critic策略梯度直接训练生成模型,避免了GAN中离散数据的分化困难。强化学习可以解决顺序决策过程。将序列生成器建模为选择下一个词的策略,可以采用策略梯度方法来优化发生器。SGAN使用基于强化学习的生成器扩展了GAN,可以解决序列生成问题。
使用策略梯度方法是促使生成模型能够生成与人类话语混淆的语句。将判别模型D判别出真实样本的概率值视为回报值,用R+{x,y}表示,该回报值可以作为生成模型G的奖励,并用Actor-Critic算法来训练出生成模型的最大期望奖励:
J(θ)=Ey~p(y|x))(R+({x,y})|A(s,a))
(6)
为了保证当前问答状态的梯度不变,原则是基线函数仅与状态有关,和行为无关。为了减少方差,使用了基于行为-价值函数减去偏差基线值的方法。式(6)中A(s,a)是优势评估的行为价值函数。给定一个中文问题序列输入x,通过该策略抽样生成回复y,将{x,y}放入判别模型D。基于基线函数的Actor-Critic策略梯度可表示为:
▽J(θ)≈[R+({x,y})-b({x,y})]▽log2π(y|x)=
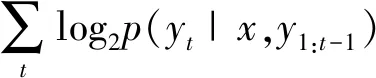
(7)
式中:π表示生成响应的概率。b({x,y})表示用于减少估计的方差同时保持其无偏差的基线值。判别模型D会以人为生成的对话为正例,机器生成的对话为负例进行同步更新。为了在模型更新时,不同人生成的样本对应不同的权重且保证人为生成的样本总具有非负权重值,判别器将对人为生成和机器生成的句子分别打分。如果人为生成的句子高于设定的基值,那么生成器G将对人为生成样本和分值进行更新。
Actor-Critic策略评估解决了原先蒙特卡洛树搜索算法带来的方差较大的问题,文本利用A(s,a)价值函数相对准确地评估状态价值,并对策略进行及时更新,避免了蒙特卡洛树搜索方法一个状态更新N次的繁琐处理。
3 实验结果与分析
本文用人人网小黄鸡中文闲聊对话语料为预训练生成模型的数据集。由于高质量的中文对话语料较少,所以模型的真实数据是由一种训练好的对话数据清洗模型提供。真实数据是来自于45万多小黄鸡问答数据对,用全部数据集对生成模型Seq2Seq模型做预训练,运用最大似然估计的方法训练模型,同时加入了小批量训练的方法。生成模型学习率为0.000 5,有两层LSTM层共1 024个神经元,梯度最大阈值为5.0,batch_size设置为64,训练迭代次数为250万次。图4为预训练生成器G的损失曲线。纵坐标是损失值,横坐标为迭代次数。在训练至12 000次左右,模型损失已经降到2.5以下,在20 000次左右,loss趋于2.2。此时模型困惑度从45左右降到20附近。模型测试阶段使用beam search算法来寻找最优结果[22],并通过设置K=1得到最优的回复。

图4 损失曲线
由于数据集中存在问题与回复不匹配且低俗暴力的样本,数据集的内容不能全部认为是人为数据。需要从数据集中挑选质量较高的问答对作为真实数据。本文用训练好的数据清洗框架Matcher模型[23]对原始数据集进行处理,获得10万对小黄鸡样本作为SGAN的真实数据,视为正样本数据。将10万对人为样本放入生成器G,获得的10万对机器生成的样本看作为负样本数据。
生成器生成一批序列,然后获得每个词的奖励,将序列与其对应的奖励放入生成器,用策略梯度的方法更新生成器的参数。这个阶段,判别器不发生任何改变,只是给出当前生成情况反馈奖励值。
判别器D的训练集来自于带有标签值为1的真实样本数据和带有标签值为0的生成样本。判别器是一个二分类的CNN卷积神经网络,利用交叉熵为损失函数[24]。同样,判别器也用了最大似然估计的方法作预训练,输入四维张量,经卷积池化线性化得到一个二维张量,预训练中用了L2正则化和Dropout。词向量维度为64,L2正则化的权重值设置为0.2,dropout值设置为0.7,batch_size为64。
预训练之后,生成网络G和判别网络D被交替地训练。生成器通过策略梯度更新参数训练得到进步,判别器需要定期重新训练,以保持和生成器的同步更新。用不同的负样本和正样本组合的方法减少估计的差异。
实验中发现,当生成器G收敛速度提高,判别器D往往得不到充分的训练,导致一直提供错误反馈;当增加判别器的训练次数,训练不稳定情况会得到缓解;用固定的正样本和不同的负样本混合,可以获得多个数据集;当判别器给出多个伪样本时,强调正样本,可以给判别器更好的学习指导。
3.1 模型评价
由于计算困惑度是评价模型和某些数据吻合度的一个很好的指标,但是它不适合于对话模型的评价。虽然基于N-gram算法的BLEU[25]在机器翻译是权威的评判标准,但是同样不适于对话系统,原因是重叠词与给定回复的冲突评价。人为评估方法虽然是理想的,但是没有很好的扩展性与可解释性[26-27]。本文评价模型根据召回率[28-29]和识别精确度[29-30]的综合评价指标来定性评判模型。精确率是就判别结果而言,表示判别为真的样本中有多少是真实数据提供的正样本。召回率是针对样本数据的,表示样本中正样本有多少被判别正确,即判别出人为提供的真实样本。图5给出的是模型训练召回率和精确率的关系分布。
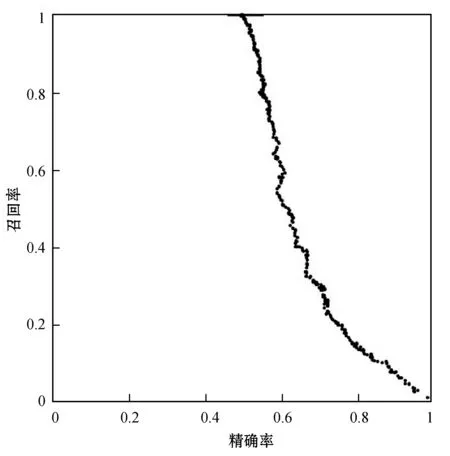
图5 SGAN评价指标关系分布
图5中横坐标为判别器D的精确率,纵坐标为召回率。由图5可以得到,随着对抗模型训练无限的迭代,判别准确率精度越来越高的同时召回率越来越低,意味着生成器G生成的伪样本和真实样本越来越相近,同时判别器D越来越难区分样本的来源是正样本还是负样本。直至模型收敛,召回率为0时,判别器已经无法分辨对话样本数据来源,达到实验目的。
为了进一步直观地评价问答效果,本文还补充了问答相关性的评价试验。基于余弦相似性原则,对平均和贪婪两个指标对问答句中的单词向量进行匹配测试。相关性评价得分结果如表1中给出。

表1 相关性评价指标得分
由表1可看出,序列对抗模型SGAN的问答效果要优于Seq2Seq。由于Seq2Seq模型本身并未考虑问答的多样性和信息性,所以本文并未对回复多样性进行实验验证。
3.2 实 例
为了直观地表现对抗模型和Seq2Seq模型的回复性能,表2给出了一些两模型就单轮对话回复的实例。比较两个模型,可以发现SGAN序列对抗模型可以生成内容更为丰富的回复,比Seq2Seq回复效果要好,且生成的对话皆可作为真实样本数据供以后优化模型训练使用。
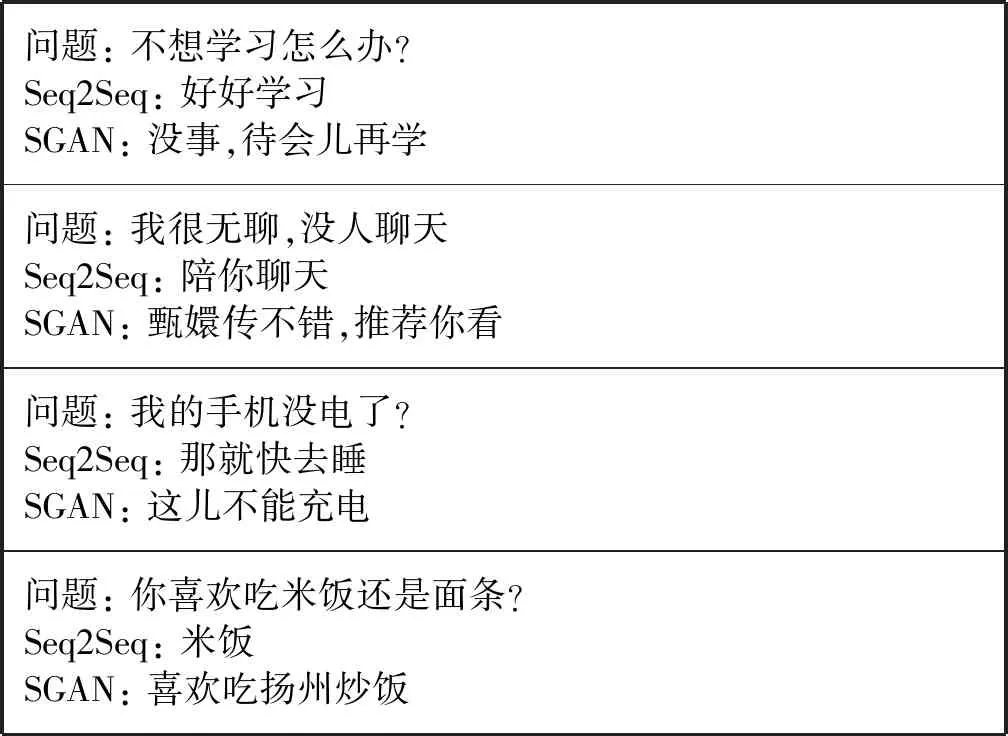
表2 模型生成对话回复的样本实例
4 结 语
本文主要为了解决中文对话语料的缺乏,提出一种基于对抗模型的序列对抗模型SGAN来生成单轮对话。为了有效地训练序列对抗网络,本文使用Actor-Critic梯度评估方法。为了解决模型奖励的及时反馈问题,使用了基线行为函数代替蒙特卡洛树搜索的方法,同时降低了系统方差。本文用召回率和精确率作为模型的评价指标,同时使用辅助的问答相关性指标对所提模型进行直观的测试。实验表明,提出的对话序列对抗模型能够生成足够的中文对话样本来混淆人为提供的样本,对中文对话数据集的构建和优化对话模型有重要的指导意义。
猜你喜欢
数学物理学报(2021年6期)2021-12-21 06:24:38
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
应用数学(2020年2期)2020-06-24 06:02:50
摄影之友(影像视觉)(2019年2期)2019-03-05 08:27:20
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
中国篆刻(2017年5期)2017-07-18 11:09:30
数学学习与研究(2017年3期)2017-03-09 18:12:42
中国老区建设(2016年1期)2016-02-28 09:32:00
诗歌月刊(2014年1期)2014-03-11 17:26:03
