
基于动态参考书目推荐的英语创意写作辅助教学系统的设计与实现
2019-04-01 12:43:52王梦雪贾清源
计算机应用与软件 2019年2期
王梦雪 李 俊 贾清源 费 腾
(武汉大学资源与环境科学学院 湖北 武汉 430079)
0 引 言
创意写作是在英美高校非常普遍的一门课程,它以一种具有想象力的、独特的又赋有诗意的方式表达作者的思想情感。近年来,国内已有几所大学开设创意写作课程。在创意写作学习过程中,学生需要阅读大量优秀的英文作品,因此,合适的参考书目尤为重要。如何满足不同用户的需求,在海量参考文献中为每个用户提供精准的、个性化的参考书目,并通过在线推荐系统进行实时推荐,是本文研究的目的所在。
推荐系统是能够为用户提供所需产品信息建议的软件工具和技术手段[1]。目前各平台采用的推荐系统算法主要是基于内容的推荐算法和基于协同过滤的推荐算法[2]。基于内容的推荐算法的主要思想是为用户推荐与他们所喜欢的产品内容相似度最高的产品[3],对于文本相似性,可以通过提取文本特征来度量,主流的方法是利用TF-IDF词频统计算法提取词频特征[4]。除此之外,本文提出用易读性作为文本特征的另一个指标,其大小用Flesch易读性公式[5]衡量,Microsoft Word就是应用Flesch公式来计算文本易读性的[6]。基于协同过滤的推荐算法是使用最广泛的推荐技术,其中基于物品的协同过滤被认为是相对稳定的算法[7-8]。通过计算待推荐产品与用户已评分过的产品间的相关性对产品进行评分预测,从而将预测评分高的产品加入推荐列表。然而,无论是基于内容的推荐算法还是协同过滤,都有自身的优点和缺陷,针对这一点,许多学者提出同时使用这两种方法以解决冷启动问题,提高精度[9-10]。
本文结合基于内容和基于产品的协同过滤推荐算法设计并实现了一个基于动态参考书目推荐的英语创意写作辅助教学系统。首先利用基于内容的推荐实时向用户推送相似文体和文风的参考文章,并通过多用户协同过滤的推荐,不断提高系统推荐的准确率。该系统不仅能应用于在线创意写作平台,还能应用于新闻、微博、商品信息、旅游文记、论文期刊等其他个性化文档推荐的项目中。
1 整体框架
图1展示了构建英语创意写作动态参考书目推荐在线系统的研究框架。该系统分三个模块进行构建:底层数据库模块、中层推荐算法模块和顶层的用户模块。数据库模块存储有文本特征数据和用户信息数据;推荐算法模块进行基于内容和基于协同过滤的混合推荐;用户模块用于前端交互,主要涉及账号密码、用户文章、推荐文章等的输入或输出和其他交互操作。
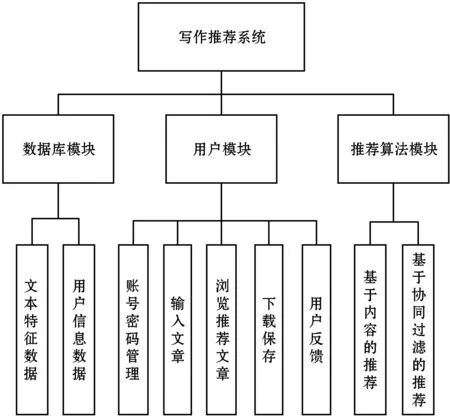
图1 创意写作动态参考书目推荐系统的研究框架
该推荐系统的运行流程如图2所示。在系统投入使用之前要对文库文章进行预处理,分析所有文章的词频特征和易读性特征,将特征值存储在底层数据库中。推荐过程分为两部分:一是基于文本的内容推荐,用户输入文章片段后,在线分析该文本的词频和易读性特征并与文库中文章的特征值比较,计算二者的相似度并将结果排序,输出相似度高的文章列表;二是基于物品的协同过滤推荐,用户查看推荐的文章后,构成浏览记录,对用户的浏览记录进行分析处理,计算文章之间的支持度和置信度,基于此,判断某些文章的关联度并对关联度进行排序,输出与用户浏览记录关联度高的文章列表,作为对基于文本内容推荐的补充。

图2 创意写作动态参考书目推荐系统的运行流程
2 基于内容的推荐
基于内容的推荐需要计算用户内容和产品内容之间的相似度,在大多数情况下需要对描述内容的信息进行分析,其中对用户兴趣的描述来自用户自己提供的信息[11]。本文在基于内容的推荐中,从特征词频相似性方面判断用户提供的片段与文库文章是否相似,并辅佐以易读性差异计算进一步衡量相似度。本文先用TF-IDF算法计算输入片段的词频特征,然后计算输入片段和文库文章排名较高的前100个词的TF-IDF值的余弦相似度,再计算输入片段的易读性,将它与文库文章的易读性进行差值计算,最后对二者的计算结果加权,得到最终的结果。
2.1 相似度计算
根据空间向量模型,一个文件空间中的文件可以看作一组特征值的集合,统计每个特征词的出现频率。将词频信息表示成向量模式,该向量就是文本的特征向量,进而可以利用向量间的余弦相似度计算或者Jaccard公式得到文本相似度。
选取特征词最常用的方法是TF-IDF算法。TF-IDF通过统计文件中每个单词在该文件的出现频率和在所有文件中的出现频率,给该文件中每个单词赋权值,TF指词频,IDF指逆向文件频率[12]。TF-IDF衡量的是给定单词与一篇特定文件的相关性,若一个单词的TF-IDF值高,那么该单词在一个特定文件中出现频率高而在该文件集中出现频率相对低,说明该单词具有很好的类别区分能力[13],将它们作为标识该文件的特征词。这样做的目的是找到衡量文章内容相似性的可靠依据,一篇英语文章中无意义的介词出现频率一般会比具有实际含义的动词或名词高。如果单纯按一篇文章的最高词频计算,那么所有文章的特征词都会充斥着大量的介词、冠词、连词,甚至是无意义的名词和动词。而TF-IDF算法的作用则能降低停止词的权值,提高实义词的权值,筛选出一篇文章中独有且出现次数多的单词,提高相似性计算的准确率。
TF-IDF算法计算过程如下:设一个文件集中有N个文本文件,fij为标识为i的单词在文件j中的出现频次,那么词频TFij定义如下:
(1)
TFij是fij标准化得到的结果,标准化过程是fij除以一个文本文件中所有单词的最大频率值。所以,文件j中出现次数最多的单词的TF值为1,其他单词的TF值都小于1。
设单词i在ni个文件中出现过,那么IDFi定义如下:
(2)
若一个文件j有m个不同的项,那么该文件的内容可以表示为m维向量:
dj=(w1j,w2j,…,wmj)
(3)
式中:
(4)
dj即为文件的特征向量,用这个值来计算文件之间的相似度。在基于内容的推荐系统中,用ContentBasedProfile(c)表示用户特征,用Content(s)表示产品特征[14],有如下所示计算该相似性的函数:
u(c,s)=score(ContentBasedProfile(c),Content(s))
(5)
其中score的计算方式有很多,本文使用夹角余弦相似法,因为该方法计算简便,且能够得到较为精确的结果。该方法是用向量空间中两个向量夹角的余弦值衡量两个对象之间的相似度,计算方法如下:
(6)
两个特征向量的夹角余弦值越大,向量之间的夹角就越小,说明两个文本文件越相似。
本文先统计文章的单词词频,取频次最高的若干个单词,然后用TF-IDF算法从中筛选出100个能标识该文章的特征单词。将这些单词的TF-IDF值作为文章的特征向量,计算出文库文章和输入语句特征向量的夹角余弦值,得到的结果即为二者的词频相似度,作为评价文档相似性的一个指标。
2.2 易读性差异计算
易读性用来衡量文章难度,本文将它作为另一个文本特征,使用Flesch公式计算文本的易读性。该公式用单词音节数衡量单词难度,用文本的平均句长衡量句子的难度。
Flesch易读性公式形式如下:
ReadingEase(RE)=206.835-0.846wl-1.015sl
(7)
式中:wl为每100个单词的平均音节数;sl为句子的平均单词数;RE代表易读性指数,范围为0~100。RE值越大,文本越容易,RE值在0~30被认为很难,是美国大学生水平,60~70被定义为标准难度,相当于初中生水平。
本文对文库文章和输入语句的单词平均音节数和句子平均单词数进行统计,用Flesch公式计算出用户输入和文库文章的易读性差值,作为评价文档相似性的另一个指标。
2.3 基于文本内容的推荐
通过对文本信息的分析计算,得到词频相似度和文章易读性两个指标。本文在决定最终的计算公式时,采用熵权法[15]确定这两个指标的权重系数。
设词频特征相似度结果的权重系数为a,易读性差异计算结果的权重系数为b,可得到用户输入片段和文库文章的相似度的计算公式:
sim(c,s)=a×u(c,s)+b×|REc-REs|=
(8)
式中:sim(c,s)表示用户输入片段与文库文章的相似度,将相似度结果从大到小排序,优先推荐相似度高的文章。
3 基于协同过滤的推荐
在基于物品的协同过滤推荐中,分析每次推荐后产生的用户喜好数据,如果多个用户同时看了某些文章,可以判断这些文章存在着隐含的联系。据此将与用户阅读过的文章关联性强的文章推荐给该用户,帮助其当前的写作,作为对基于内容推荐结果的补充。基于物品的协同过滤的理论之一是数据挖掘中的关联规则,用支持度(support)和置信度(confidence)来反映两个物品之间的关联度,支持度表示两个物品同时出现的概率。
本文采用隐式评分[16],即不需要用户显式输入评分数值,仅通过用户在浏览推荐结果片段后是否点击“阅读全文”来判断用户是否对该文章感兴趣。若判断为是,则将该文章加入到该用户的阅读列表,文库列表中的每一篇文章和其他文章的关联性都要在阅读列表中进行统计计算。对于任意两篇属于文库列表的文章A和B,它们之间的支持度为:
(9)
A对B的置信度表示如果用户阅读过A,他也会喜欢B的概率,公式为:
(10)
给支持度和置信度设置阈值,若A对B的支持度和A对B的置信度分别大于这两个阈值,则判断B是A的强相关性文章,将B添加到A的相关文章列表中。遍历文库中的所有文章,为每篇文章都建立对应的相关文章列表。若用户阅读文章A,则从列表中筛选出用户没有读过的文章B,按照关联度从大到小排序,将排序结果推送给用户。
4 测试分析及改进
本文设计了一种个性化在线推荐系统平台,系统界面如图3所示。用户在左侧文本框输入写作片段,系统根据目前的内容在左下角实时呈现5篇推荐书目的标题,当输入文字较多后推荐列表会趋于稳定。用户点击后以片段方式呈现在右侧文本框供用户试阅,当用户对此文章感兴趣可以点击“full text”阅读全文。此时,系统会在右下角会列出与该文章相关度最高的5篇文章,并将浏览行为记录下来,用于计算更新各文章的相关文章列表。

图3 创意写作动态参考书目推荐系统界面
本文从各网站采集了580短篇英文小说作为实验测试数据,测试平台中设计了评分系统,选择100名学生作为用户分别从内容和主题、表达和情感、用词和句长三个方面进行评价,每个方面评分为1~5分。用户综合推荐的5篇文章对结果进行评分,对评分结果求平均值并进行归一化,得到用户对推荐结果的满意程度,结果如表1所示。
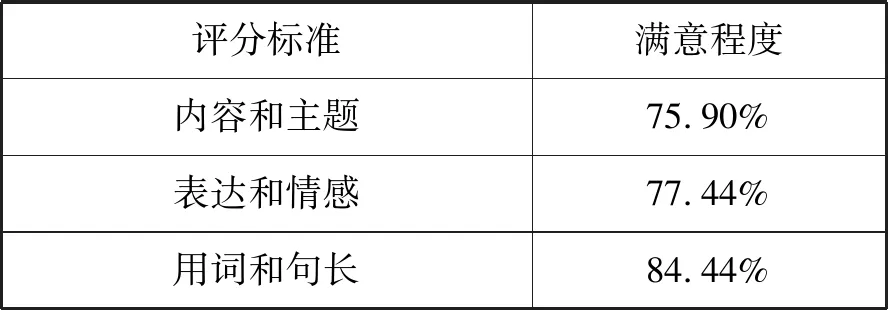
表1 用户满意程度及评分标准
由用户的反馈可以看出,本系统能够较好地满足用户的需求。虽然在情感表达和主题内容上稍有欠缺,但是在词汇和句子难度方面系统能提供较为精准的推荐。
本系统与已有的教学资源推荐系统相比[17-18],优势在于使用基于内容和基于物品的混合式推荐系统,发挥了两种推荐方法各自的优点。在基于内容的推荐中,分别从文章相似度和易读性两个角度出发进行相似计算,从而提高了推荐的准确性。
5 结 语
本文提出了一个基于动态参考书目推荐的英语创意写作辅助教学系统。该系统能根据用户在线输入的英文写作内容,提取多维写作风格特征,进行实时动态相关参考读物推荐。此外,作为一个多用户系统,还基于协同过滤算法,将其他用户的接受推荐行为也纳入推荐考虑范围,利用用户贡献内容(UGC)对系统的贡献,对其基于写作风格的推荐进行补充和修正。该系统在使用中,反应迅速、推荐准确,深受测试用户的好评。可以作为创意写作课程教学与课后辅导信息化的有利工具。
在之后的改进中可以考虑更多方面,如利用自然语言处理进行情感分析,通过文章主题分类提高推荐效果,使推荐系统更符合用户的预期。
猜你喜欢
园林科技(2021年3期)2022-01-19 03:17:48
猪业科学(2021年3期)2021-05-21 02:05:36
幽默大师(2020年10期)2020-11-10 09:07:22
阅读(快乐英语高年级)(2020年8期)2020-01-08 02:21:16
中华诗词(2019年1期)2019-11-14 23:33:56
猪业科学(2018年4期)2018-05-19 02:04:31
智慧少年·故事叮当(2018年11期)2018-05-14 11:48:18
意林(绘英语)(2017年5期)2017-05-15 02:17:23
读者·校园版(2015年7期)2015-05-14 13:11:40
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
