
一种融合用户与项目属性的协同过滤算法的设计与实现
2019-04-01 13:11:46陶志勇崔新新
计算机应用与软件 2019年2期
陶志勇 崔新新
辽宁工程技术大学电子与信息工程学院 辽宁 沈阳 125105)
0 引 言
随着网络的普及,信息量的剧增,推荐系统得到迅速发展。推荐系统的核心是推荐算法,推荐算法的方式可以分为:社交网络的推荐[1]、基于内容的推荐[2]、基于协同过滤的推荐[3]。其中,协同过滤是推荐系统[4-5]中应用最早并且最成功的算法之一。尽管协同过滤算法应用很广泛,但仍面临着数据稀疏、冷启动、推荐精度低等问题。为解决这些问题,学者们提出了隐马尔科夫[6]、支持向量机[7]、神经网络[8-9]等方法,但仍然受数据稀疏的影响严重。在传统的协同过滤算法中,数据稀疏,反馈项目过少势必会造成项目间相似度计算不准确,进一步导致兴趣度的估计值和真实值存在较大的偏差。因此,合理高效地利用已知数据的信息,获得接近真实相似度的计算方法成为学者们研究的热点。杜丹琪等[10]利用项目的属性进行聚类,根据聚类的结果和同一类别的项目属性值加权的方法进行评分预测。同时,为解决用户兴趣随时间变化的问题引入TimeRBM模型再次进行评分预测,最后采用线性组合的方法对两种预测结果进行合理取舍。刘静等[11]提出了一种基于用户兴趣度和项目属性的推荐算法,算法在计算相似度过程中加入基于时间的用户兴趣度权重函数,然后再与项目属性相似度进行融合,最后进行项目预测与推荐。宫志晨等[12]利用多向测量的方法获得用户对项目的评分相似性,然后结合项目属性挖掘用户对项目属性的偏好,采用加权的方式获得最终的用户间相似度。胡建等[13]采用最大差值评分解决了个别项目造成非常相似用户丢失的问题,利用用户的属性进行量化评分,然后再对其评分进行相似度计算,这样有利于目标用户获得较为相似的近邻用户。王三虎等[14]将用户评分相似度、兴趣的倾向相似度、评分相似度的置信度以及用户属性相似度进行融合提出了一种融合用户评分和属性相似度的协同过滤推荐算法。
以上文献一定程度上提高了推荐质量的问题,但并没有做到充分利用已有的数据信息。因此。本文提出了一种充分融合用户和项目属性的协同过滤算法。算法的核心思想为:首先利用用户(项目)属性修改用户(项目)相似度计算方法,确定最相似用户(项目)集;然后将两种算法组合加权,再进行兴趣度估计;最后利用用户和项目属性信息挖掘用户偏好,利用天牛须搜索方法获得融合用户偏好的兴趣度估计方法。本文在Movie Lens 100k的数据集上进行试验,实验表明:本算法缓解了数据稀疏性和冷启动对推荐系统的影响,提高了推荐精度。
1 基本原理
1.1 基于用户的协同过滤
传统的user-based CF算法是使用用户的历史信息,获取用户间的相似度,然后选择相似性最高的用户作为最相似用户集。兴趣度估计常用的相似性度量方式有Jaccard公式、余弦公式。sim(u,v)表示用户u和用户v之间的相似度,则以上相似性的度量公式如下:
(1)
(2)
式中:N(u)表示用户u有过正反馈的项目集合;N(v)表示用户v有过正反馈的项目集合。由于式(2)过于粗略,John S.breese提出了修正余弦公式如式(3)所示。本文的用户相似度计算就采用式(3)。
(3)
推荐生成的核心是兴趣度估计,即利用目标用户的类似用户来估量目标用户对未浏览过项目的兴趣度,兴趣度估计方法如下所示:
(4)
式中:s(u,k)表示用户u的k个最近邻,N(i)代表对项目i有过行为的用户集合,rvi代表用户v对项目i的兴趣度,因为使用的是单一行为的隐反馈数据,所以rui=1。
user-based CF的时效性较强,适用于用户个性化不太明显的领域。存在如下缺点:(1) 当用户有新行为时,对推荐的结果影响不大。(2) 经常推荐的是抢手项目,推荐长尾里的项目能力不足。(3) 当新的用户对很少的项目产生行为时,不能进行个性化推荐。
1.2 基于项目的协同过滤
传统的item-based CF是利用项目之间的相似度进行推荐的,首先计算项目间的相似度,相似度的计算方式和1.1节用户相似度计算方式类似。项目i和项目j的相似性计算方式如下:
(5)
式中:N(i)为浏览过项目i的用户集合;N(j)为浏览过项目j的用户集合;N(g)为浏览过项目i也浏览过项目j的用户集合。其次得到项目间的相似性后,寻找用户浏览过项目的最相似项目集,利用该集合估计用户对未浏览过的项目的偏好。兴趣度估量计算方法如下:
(6)
式中:N(u)表示用户u有过正反馈的项目集,s(i,k)表示项目i的k最近邻,rui表示用户u对项目i的兴趣度。这里和基于用户的协同过滤一样,rui=1。
item-based CF有较强的新颖性,容易挖掘长尾里的项目,利于满足用户的个性化需求。用户有新行为,一定会导致推荐结果的实时变化,但是也存在一定的缺点。由于item-based CF是通过项目间的相似性进行推荐的,很难探索到用户潜在喜欢的项目,推荐的项目样式单一。
2 融合用户和项目属性的协同过滤算法
融合用户和项目属性的协同过滤算法,简称UIACF算法,下面详细介绍UIACF算法的主要内容。
2.1 改进相似度计算方法
带有不同属性的用户对项目的需求有所不同,比如用户的年龄属性,年轻人和老年人的消费观念差别很大,年轻人更加注重的是购物过程中的享受和愉悦感,而老年人更加注重物美价廉,所以,用户属性影响用户之间的相似度。因此,本文在传统的用户相似度计算方法中,引入了用户属性权重。根据MovieLens 100k(http://www.grouplens.org/)[15]数据集提供的用户属性信息,引入用户年龄、性别、职业属性的权重。
年龄为yu的用户u、年龄为yv的用户v,他们的年龄权重的计算方式如下所示:
ageweightu,v=e-|yu-yv|
(7)
MovieLens 100k数据集将用户的职业按行业属性分为21种。用户u的性别和职业属性的集合记为Xu,用户v的职业属性和性别属性的集合记为Xv,则这两个属性的权重用式(8)来计算:
(8)
引入用户属性的相似度计算方法为:
simim(u,v)= (1-a1-a2)×sim(u,v)+
a1×soweightu,v+a2×ageweightu,v
(9)
式中:ageweightu,v和soweightu,v分别为用户年龄属性权重和性别职业属性权重,a1,a2∈[0,1]为未知参数,实际应用时可以根据用户类别属性做回归分析拟合得出。
同理具有相同属性的项目的相似性也较高,而传统的项目相似度计算的过程中却忽略了这一点,因此引入项目属性权重作为衡量项目相似度的一部分,在项目相似度计算中引入项目属性权重。项目i和项目j属性的集合分别记Ti和Tj,项目属性权重计算方式如下所示:
(10)
最后改进的电影相似度计算公式为:
simim(i,j)=(1-b1)sim(i,j)+b1×typeweighti,j
(11)
式中:typeweighti,j∈[0,1],为电影类型权重,b1∈[0,1],实际应用时可以根据项目类别属性做回归分析拟合得出。
2.2 基于用户和项目结合的协同过滤算法
2.1节详细介绍了融合用户属性的用户相似性度量方法和融合项目属性的项目相似性度量方法,改进用户相似度的计算方法后的兴趣度计算方式如式(12),改进项目相似度后的兴趣度计算方式如式(13)。
(12)
(13)
式(12)、式(13)会得到用户对同一种项目的两种兴趣度估计值,为了得到更加准确的兴趣度,采用加权的方式,进行综合预测。引入控制参数a,最终的兴趣度估计方式如下:
PUI(u,i)=(1-a)×pI(u,i)+a×pU(u,i)
(14)
式中:a为控制参数,当用户数量多于项目数量时,用户相似度计算占主导地位,参数a权重应该偏小;反之,项目相似度计算占主导地位,这时参数a应该偏大,实际应用时参数a可以根据用户数量和项目数量统计确定。
两种算法的结合不仅弥补了基于用户的协同过滤存在的对用户新行为反映不及时、推荐长尾项目能力不足的缺点,还解决基于项目的协同过滤存在的推荐项目多样性性能差的问题。
2.3 兴趣度估计
2016年中国旅游领域用户行为画像及偏好分析认为旅游行业各领域中男性偏爱航空服务,女性偏爱旅游攻略,同时也反映了用户的某些属性对带有某些属性项目的兴趣度存在影响。因此本节首先进行了用户属性偏好的挖掘,然后利用用户偏好对兴趣度计算方式进行改进。
(1) 用户年龄和项目类型 根据数据的用户年龄属性将用户的年龄进行分段。年龄阶段为x的用户的集合记为Ux,观看过t类型项目的用户的集合记为Iut,x阶段的所有用户观看过的t类型项目总和记为sum(u∈Ux,i∈Iut)。x阶段的用户对t类型项目评分的平均值为他们对t类型项目的偏好值,计算方式如下所示:
(15)
(2) 用户职业和项目类型 统计不同类型项目的浏览用户以及各个类型中的不同职业的用户对该类型打分的平均值,把这个平均值定义为不同职业对项目类型的偏好值。Uo表示职业为o用户的集合,Iut表示用户u浏览过的项目中类型为t的电影集合。sum(u∈Uo,i∈Iut)表示职业为o的所有用户浏览过的项目类型为t的个数总和。职业为o的用户对t类型项目偏好值的计算方式如下:
(16)
(3) 用户性别和项目类型 统计不同类型的项目的浏览用户以及各个类型中的不同性别的用户对该类型打分的平均值,把这个平均值定义为用户性别对项目类型的偏好值。性别为g的用户的集合记为Ug,用户u浏览过的项目中类型为t的项目集合记为Iut,性别为g的所有用户浏览过的项目类型为t的个数总和记为,则性别为g的用户对t类型的项目偏好值计算公式如下:
(17)
(4) 用户和项目类型 不同用户具有不同的偏好,前几部分是针对用户的不同属性对项目类型的偏好。统计用户对不同类型电影打分的平均值,用这个平均值反映用户的对不同项目类型的偏好值。Iut表示用户u浏览过的项目中类型为t的项目集合。表示用户浏览过项目类型为t的个数。则用户u对电影类型t的偏好值计算方式如下:
(18)
通过上述对用户历史信息的处理,利用用户属性对应项目类型的偏好值,调节用户对项目的兴趣度的估计值。引入用户年龄与项目类型的权重因子ωa、用户职业与电影类型的权重因子ωo、用户性别与项目类型的权重因子ωg、用户个体和项目类型的权重因子ωu,最终的调节方式如下:
PUIA(u,i)= (1-ωa-ωg-ωo-ωu)×PUI(u,i)+
ωa×aweight(x,t)+ωg×gweight(g,t)+
ωo×oweight(o,t)+ωu×uweight(u,t)
(19)
式中:ωa、ωg、ωo、ωu为控制参数,用于调节4种属性偏好在最终的兴趣度中所占的比重,使得兴趣度更加接近真实情况。控制参数的确定是通过天牛须搜索获得。天牛须搜索BAS(Beetle Antennae Search)[16-17]是2017年提出的一种高效的智能优化算法,类似于遗传算法、粒子群算法等智能算法。与传统的智能算法相比,该算法具有不需要函数的具体形式、不需要梯度信息就可以高效寻优的优点。其生物原理为:天牛的身体长有两只触角,在觅食时根据两只触角来判断食物气味的强弱。哪边接收到的气味强度大,天牛就会往哪边飞。数学建模如下:
(1) 创建天牛须朝向的随机向量且做归一化处理。
(20)
式中:rands()为随机函数;k表示空间维度。
(2) 创建天牛左右须空间坐标。
(21)
式中:xrn和xln分别表示天牛右须、天牛左须在第n次迭代时的位置坐标;xn表示天牛在第t次迭代时的质心坐标;d0表示两须之间的距离。
(3) 创建适应度函数f(x),并计算f(xl)和f(xr)。
(4) 迭代更新天牛的位置。
xn+1=xn-δn×b×sign(f(xrn)-f(xln))
(22)
式中:δn表示第n次迭代时的步长因子;sign()表示符号函数。
本文协同过滤的适应度函数为:
(23)
式中:x=[ωa,ωg,ωo,ωu];Nx(i)表示x取值的情况下,对目标用户ui推荐商品列表。目标用户ui在测试集上有过历史行为的电影的集合,记为T(i)。
2.4 兴趣度估计UIACF推荐算法描述
目前推荐系统的推荐方式可以分为评分预测和top-N,评分预测估算的是用户对项目发生行为后对项目的满意程度,而top-N估算的是用户对项目发生行为的可能性。在实际应用中,top-N比评分预测更有应用价值。这是因为即使用户对一个项目发生行为后的评分非常高,但是时间、场合等因素一直对该项目没有发生过行为。这时,评分预测没有意义。本文的兴趣度预测采用的top-N推荐,具体的算法步骤如下:
输入:目标用户u,用户-项目的评分矩阵H,最相似用户集合U*的大小k1,最相似项目集I*的大小k2,推荐个数N。
输出:对目标用户的N个推荐结果。
步骤1根据式(9)、式(11)分别计算目标用户(项目)和其他用户(项目)的相似度,确定最相似用户集合U*和最相似项目集合I*。
步骤2根据式(12)、式(13)分别计算目标用户对未浏览项目的兴趣度的估计值,然后进行user-based CF和item-based CF的估计值的组合,跟据式(14)计算兴趣度。
步骤3根据式(15)-式(18)统计不同用户的属性对应的项目类型的偏好值。
步骤4根据天牛须搜索算法式(20)-式(23)获得最佳的权重参数。然后利用式(19)计算校正后的兴趣度,进行排序,推荐兴趣度最高的前N个电影。需要注意的是当一个用户是新用户时,他没有任何历史信息,在热门的项目中通过用户属性与电影类型的关系进行用户对项目的兴趣度估计。假设,一个新的用户属性信息分别为xu、ou、gu。则他对电影i的兴趣度计算公式如下:
p(u,i)=ageweight(xu,ti)×occupationweight(ou,ti)×
genderweight(gu,ti)
(24)
3 实 验
为了验证算法的性能,在Windows server 2008 64位操作系,16 GB内存,Intel®Xeon®CPU E5-2630 v3 @2.40 GHz,python2.7的环境下对算法进行仿真分析。利用MovieLens 100k数据集将该算法分别与user-based CF和item-based CF、PCEDS算法[18]以及Pearson算法做比较,并且对得到的结果进行分析。
3.1 评价标准
本实验采用的衡量指标为准确率、召回率。用户的集合为U,对目标用户ui推荐N个商品,记为N(i)。目标用户ui在测试集上有过历史行为的电影的集合,记为T(i)。计算方式如下:
(25)
(26)
3.2 实验结果及分析
本文设计了6组实验,分别是user-based CF、item-based CF、基于用户和项目组合的协同过滤算法、用户相似度改进后的组合协同过滤算法、相似度改进后组合的协同过滤算法、融合用户和项目属性的协同过滤算法。6组实验验证了算法组合、相似度改进以及兴趣度矫正的有效性。为了方便描述实验结果,本文采用表2中的缩写来表示对应的算法,采用k1表示最相似用户的个数,采用k2表示最相似项目的个数。

表1 本文算法和拟比较算法
(1) 算法结合的有效性 该实验主要是验证两种算法的组合对推荐质量的影响。本文实验的推荐个数定为10。首先,利用召回率和准确率作为评判标准来测试使UCF结果达到最佳的参数k1的值,用11个k1值来测试UCF算法的推荐质量。得到的实验结果如图1所示。由图1中可以看出,取值在30附近时,该算法的召回率和准确率最高。为了便于对比,UIACF算法实验的最相似用户集的大小定为30。

图1 基于用户的协同过滤
用9个k2值来测试ICF算法,实验结果如图2所示。由图2可以看出k2取值在500~900范围内时,召回率稳定在0.104~0.105之间,准确率也稳定在0.450~0.455不再有大的波动,召回率和准确率变化趋势相同。同样,为了方便比较,在UIACF算法中最相似项目集的大小值取为500。

图2 基于项目的协同过滤
将上述两种算法结合后,得到结果如图3所示。图3中,由本文的算法结合方式可知,当a=0时,对应点纵坐标的值为ICF算法的推荐精度;当a=1时,对应点的纵坐标的值为UCF算法的推荐精度。而a=0.3时,对应的推荐精度高于这两种情况的任何一种。说明两种算法的结合提高了推荐质量。由图1、图2、图3可以看出准确率和召回率的趋势相同,在后面的实验选择了召回率作为算法的衡量指标。
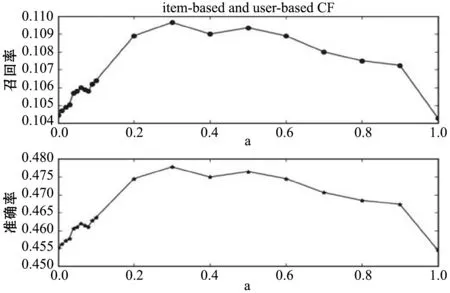
图3 用户和项目组合的协同过滤
(2) 相似度改进的有效性 本实验主要是验证相似度改进的有效性,IUICF的实验结果如图4所示。由图4可知:b1取值为0.05时推荐的质量最高,b1的取值为0时,相当于项目相似度未改进前单纯的两种算法结合的推荐质量。项目相似度改进后将召回率从0.109 6提高到0.110 7。
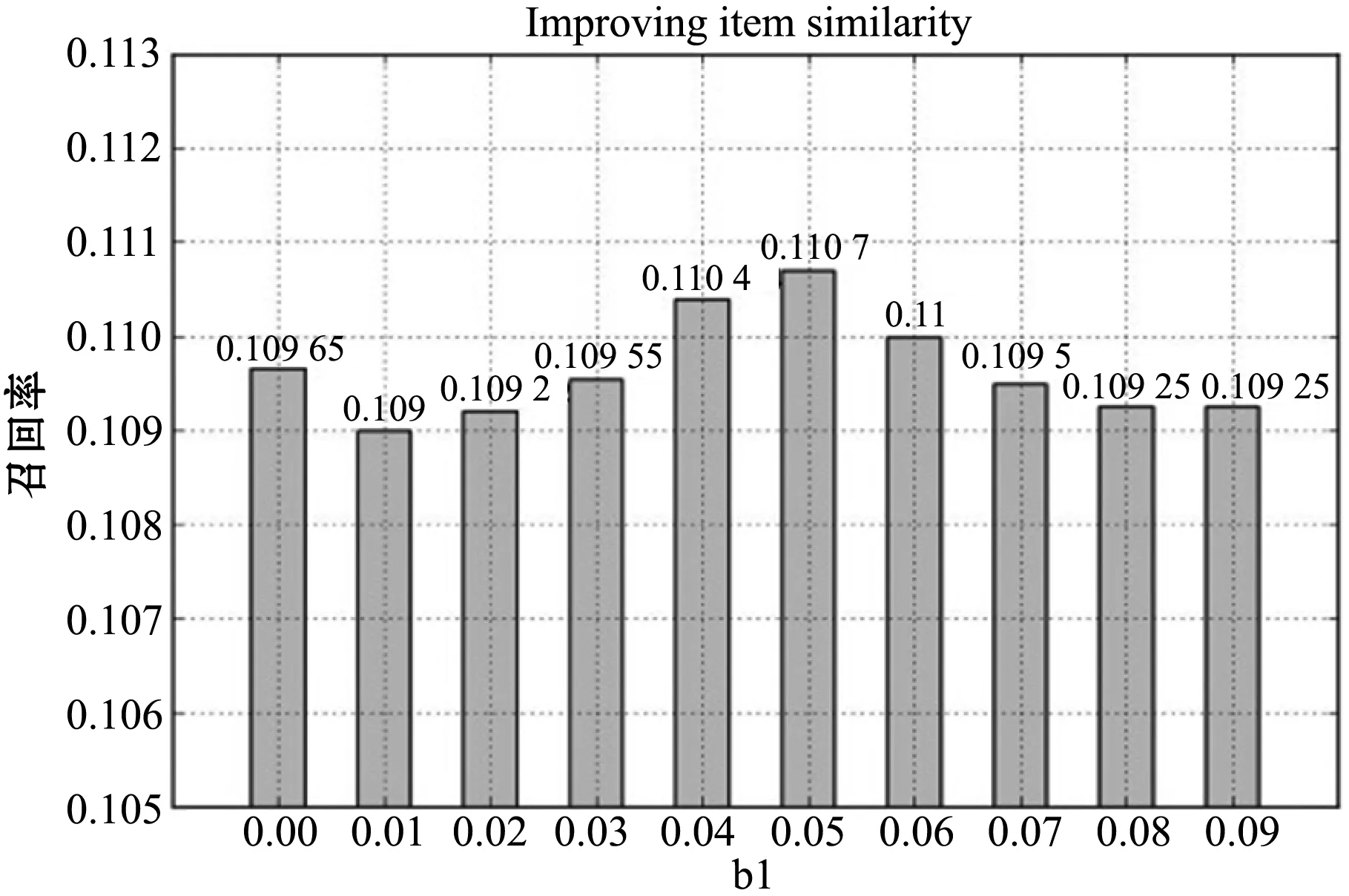
图4 项目相似度参数测试图
UIUICF的实验结果如图5所示。由图5可以得到该算法在a1=0.04,a2=0.01时的结果最佳。当a1=a2=0时,相当于IUICF的推荐精度。实验表明,用户相似度改进后,召回率从0.110 7提高到0.112 2。说明用户的性别,年龄和职业对用户的相似度有影响,性别决定总体相似度的1%,年龄和职业决定总体相似度4%。
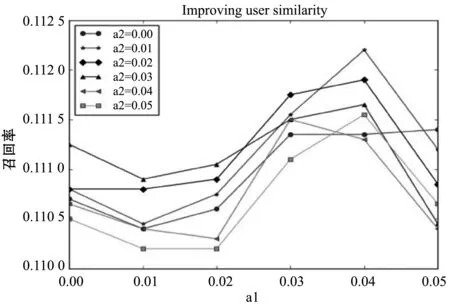
图5 用户相似度参数测试图
通过上述实验,可以确定提出的用户和项目相似性计算方式的改进均可以降低数据稀疏对协同过滤算法的影响,提高推荐质量。
(3) 兴趣度矫正的有效性 本实验主要是验证用户偏好矫正兴趣度的有效性。利用2.3节提出的数据处理方式,得到用户属性对应项目类型偏好值。由于评分的范围是1~5,所以偏好值的范围也为1~5。偏好值为0时,代表该属性的用户对应类型的项目没有发生过行为。
利用式(15)计算用户年龄对应电影类型的偏好值。图6为各年龄段的电影类型偏好分布图,由图6可知:各年龄段的用户存在电影类型的偏好,且各有不同。在图中的十种电影类型中,青少年更倾向于科幻片,青年更中意犯罪片,中年人喜欢看美剧,老年人更偏爱推理电影。
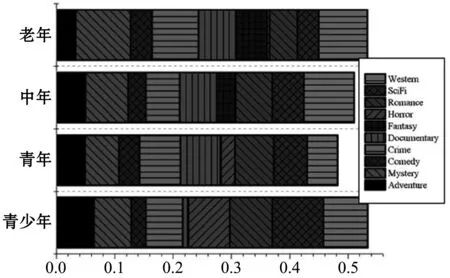
图6 各年龄段的电影类型偏好分布图
利用式(17)计算用户性别对应电影类型的偏好值。图7为不同性别对6种电影类型偏好程度图。图7表明:男女性别对电影类型的偏好存在差异。在图中的6种电影类型中,男性比较偏好科幻片,而女性比较偏好爱情片。同理,根据式(16)和式(18)挖掘到用户的职业以及用户个体对应的电影类型偏好均存在差异。
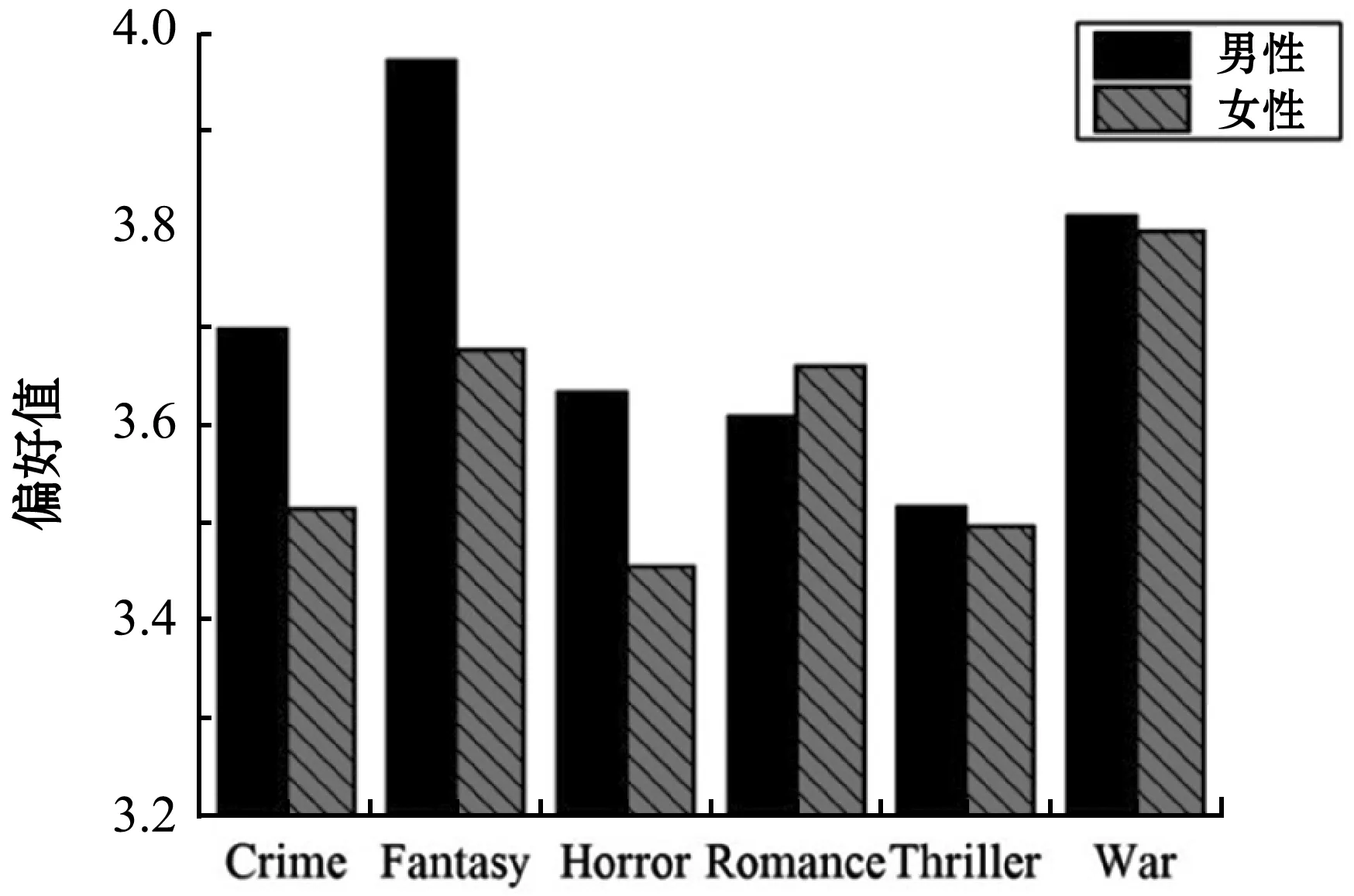
图7 用户性别的电影类型偏好
利用上述获取得的用户属性对应电影类型的偏好值,分别用式(19)进行准确度矫正。利用天牛须搜索算法寻找最优的参数,总迭代的次数为500,迭代大约200次时,实验结果收敛。最终的实验结果如图8所示。当权重因子ωa、ωo、ωg、ωu分别取值为0.01、0.01、0.003 061、0.001时,用户的属性矫正的兴趣度最接近真实兴趣度。本次实验的结果验证了实验最初的假设,表2为实验结果对照表。
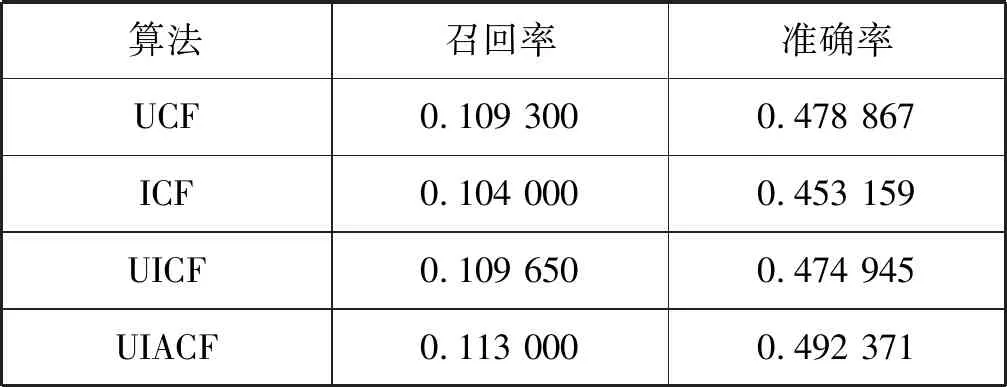
表2 实验结果对照表
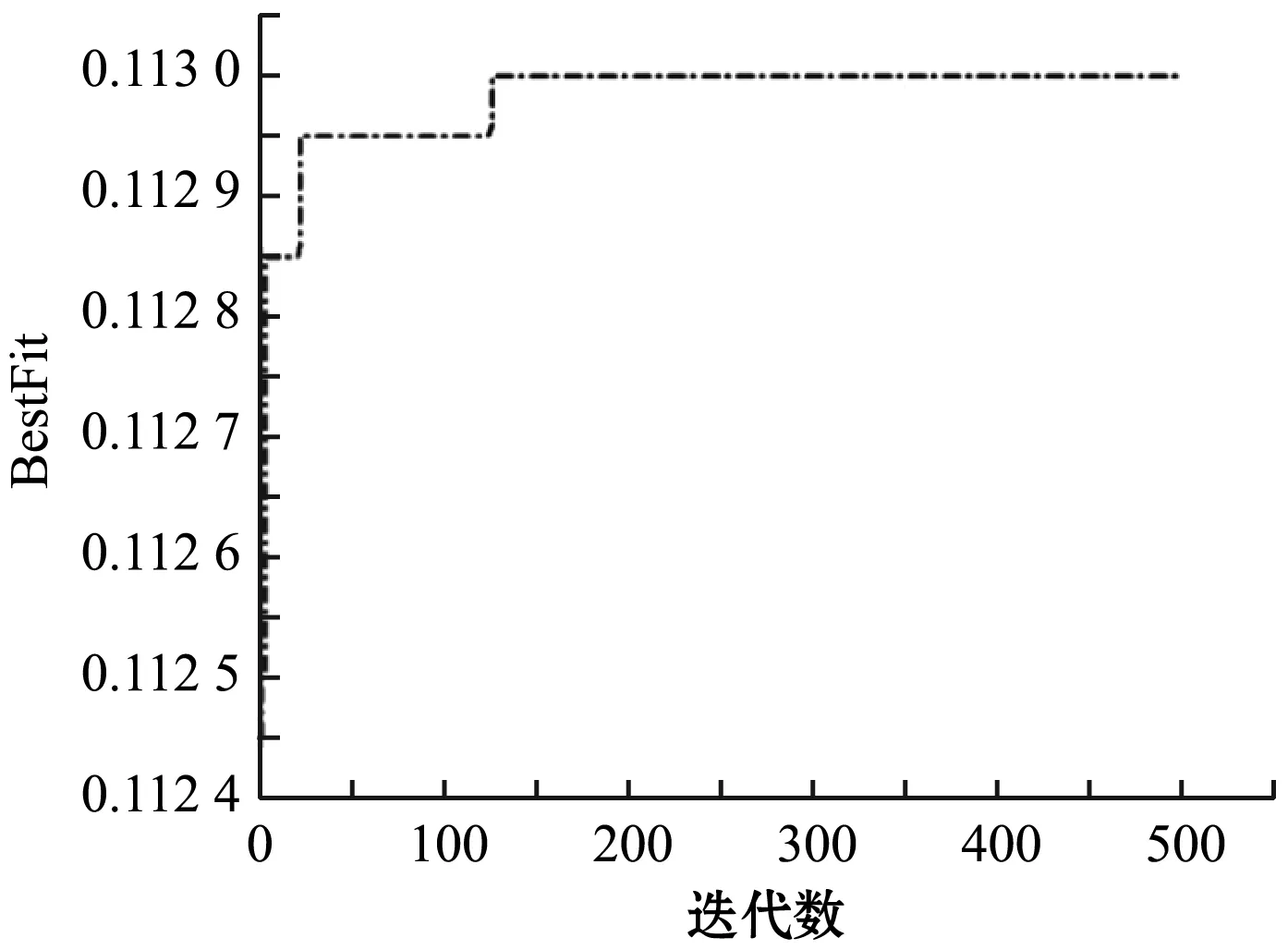
图8 协同过滤适应度曲线
(4) 不同算法之间的对比 近邻数分别取15、20、25、30、35、40、45,对文献[20]中的PCEDS算法、Pearson算法、UCF算法、ICF算法以及UIACF算法进行比较,实验结果如图9所示。实验结果表明:UIACF算法的性能不仅优于UCF和ICF,还优于PCEDS算法。同时也说明了合理地利用用户和项目的属性信息对推荐系统推荐质量的提高有很大的价值。
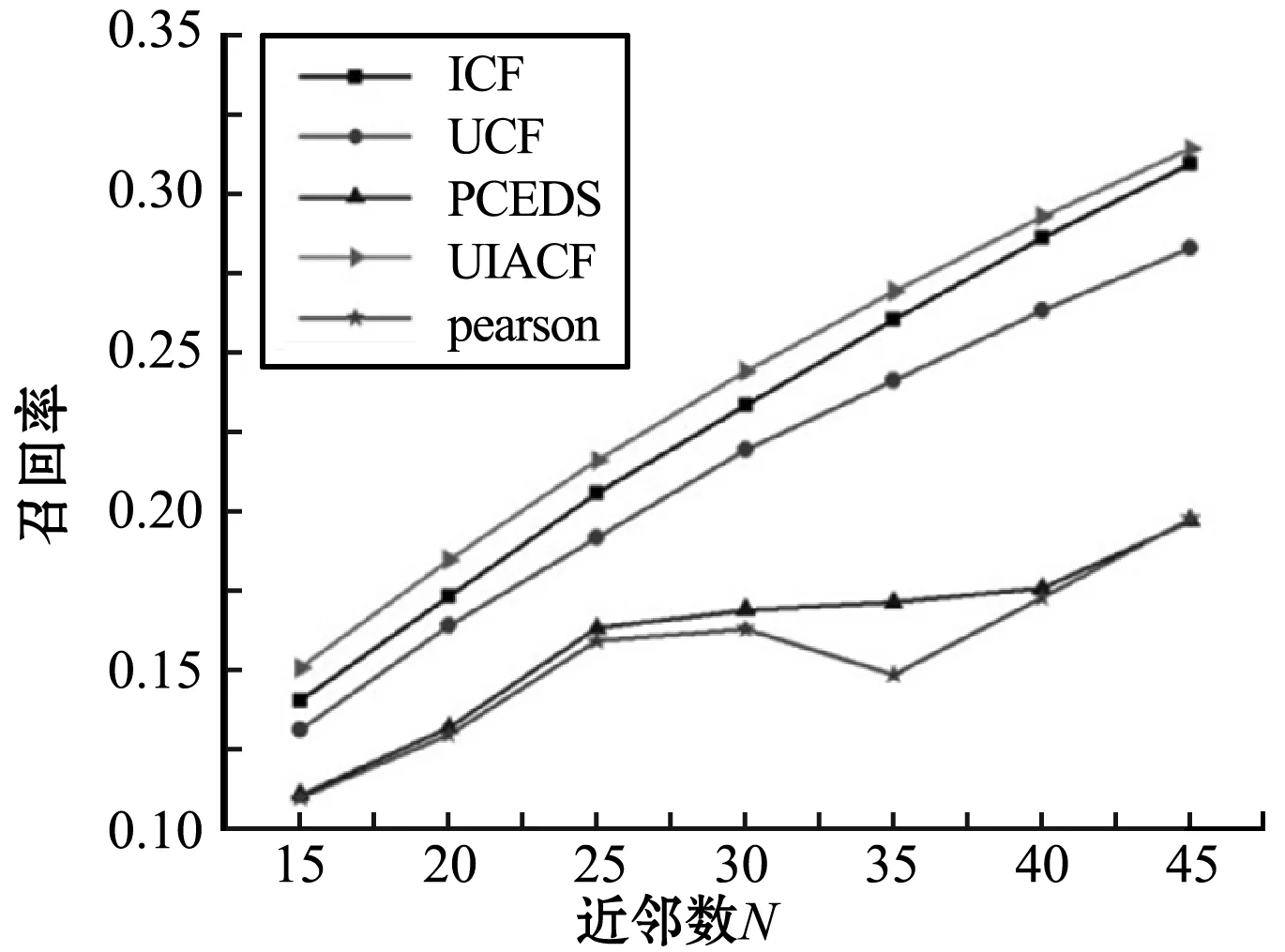
图9 算法对比图
4 结 语
传统的user-based CF和item-based CF以及目前存在的一些算法缺少对用户的属性和项目属性的充分考虑,从而导致冷启动、数据稀疏性、推荐精度低等问题。本文在传统的协同过滤基础上,提出一种融合用户和项目属性的协同过滤算法。利用两种算法的结合、用户属性对应的偏好以及天牛须搜索算法来调整兴趣度的预测,从而使预测的兴趣度更接近真实的兴趣度。此外,传统相似度的度量忽略了用户属性和项目属性对相似度的影响,本文引入用户的年龄、职业权重以及项目的类型权重因素。实验结果表明,本文提出的算法在召回率上与用户协同过滤相比提高了3.39%,较传统项目协同过滤算法提高8.65%。本算法存在的不足是需要数据集带有用户和项目的属性信息,受属性细度划分的影响严重。下一步的工作是在本算法的基础上研究如何进行属性细度划分,进一步提高推荐系统的推荐质量。
猜你喜欢
科学大众(2020年23期)2021-01-18 03:09:08
当代陕西(2020年17期)2020-10-28 08:18:18
成都信息工程大学学报(2019年4期)2019-11-04 00:56:02
阅读与作文(英语初中版)(2019年8期)2019-08-27 03:59:25
汽车观察(2019年2期)2019-03-15 06:00:50
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
人大建设(2018年5期)2018-08-16 07:09:00
电信科学(2017年6期)2017-07-01 15:44:57
中国卫生(2016年5期)2016-11-12 13:25:26
现代防御技术(2016年1期)2016-06-01 12:13:27
