
基于自适应区域监督机制的场景分类算法*
2019-03-29 10:52陈志鸿胡海峰马水平于遨波
中山大学学报(自然科学版)(中英文) 2019年2期
陈志鸿 ,胡海峰 ,马水平 ,于遨波
(中山大学电子与信息工程学院,广东 广州 510006)
场景分类问题是计算机视觉领域一项重要且具有实用价值的任务。早期的场景分类问题主要采用一些浅层学习结构,诸如支持向量机[1-2]、单隐层神经网络[3]、核回归[4]等机器学习方法。这些传统的场景分类方法需要人工设计特征并且方法的鲁棒性不强,难以在复杂的分类问题上有效地表现出性能以及泛化能力。随着深度学习的出现和大规模标注数据集的发展,许多具有挑战性的计算机视觉任务包括场景分类任务取得了很好的表现。
然而,在识别性能提升的同时,深度卷积神经网络的参数也越来越多,算法效率也随之降低。GoogLeNet模型[5]提到了尺度增强变换的方法,通过对图像进行随机裁剪以降低训练难度,这种方法往往会裁剪出与分类标签无关的区域,从而使用了错误的图像数据进行模型训练,使得训练出来的深度网络不能有效地表征场景特征,导致裁剪后的图像与其标签的相关性降低。本文提出了一种基于自适应区域监督机制的场景分类算法,通过训练热点图生成层,得到识别性能符合设定阈值的网络,以生成代表图像关键信息的热点图。研究结果表明,基于自适应区域监督机制的场景分类算法识别率和效率更高、模型的泛化能力更好。
1 基于自适应区域监督机制的场景分类算法
传统的提高神经网络性能的方法为增加网络的深度。然而,随着深度的增加,参数和计算量都将大幅提升,并且容易产生过拟合的现象。为了解决这一问题,GoogLeNet[5]用Inception结构将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能。在图像进入网络前,首先将图像大小调整为256、288、320和352四种比例。在调整好的图片中提取左、中、右三个正方形区域,对于每个正方形,裁剪其四个角以及正中心区域。这样,一张图片就被分为144块区域,得到的区域包含图片的绝大多数信息,在这些区域中随机选择图片进行后续的卷积操作。但在随机选择区域时,所选区域与其标签的相关性是不确定的,以致可能使用错误的图像数据去训练模型,从而降低了模型的泛化能力。针对这一问题,本文提出了基于自适应区域监督机制的场景分类算法,其具体算法流程图如图1所示。
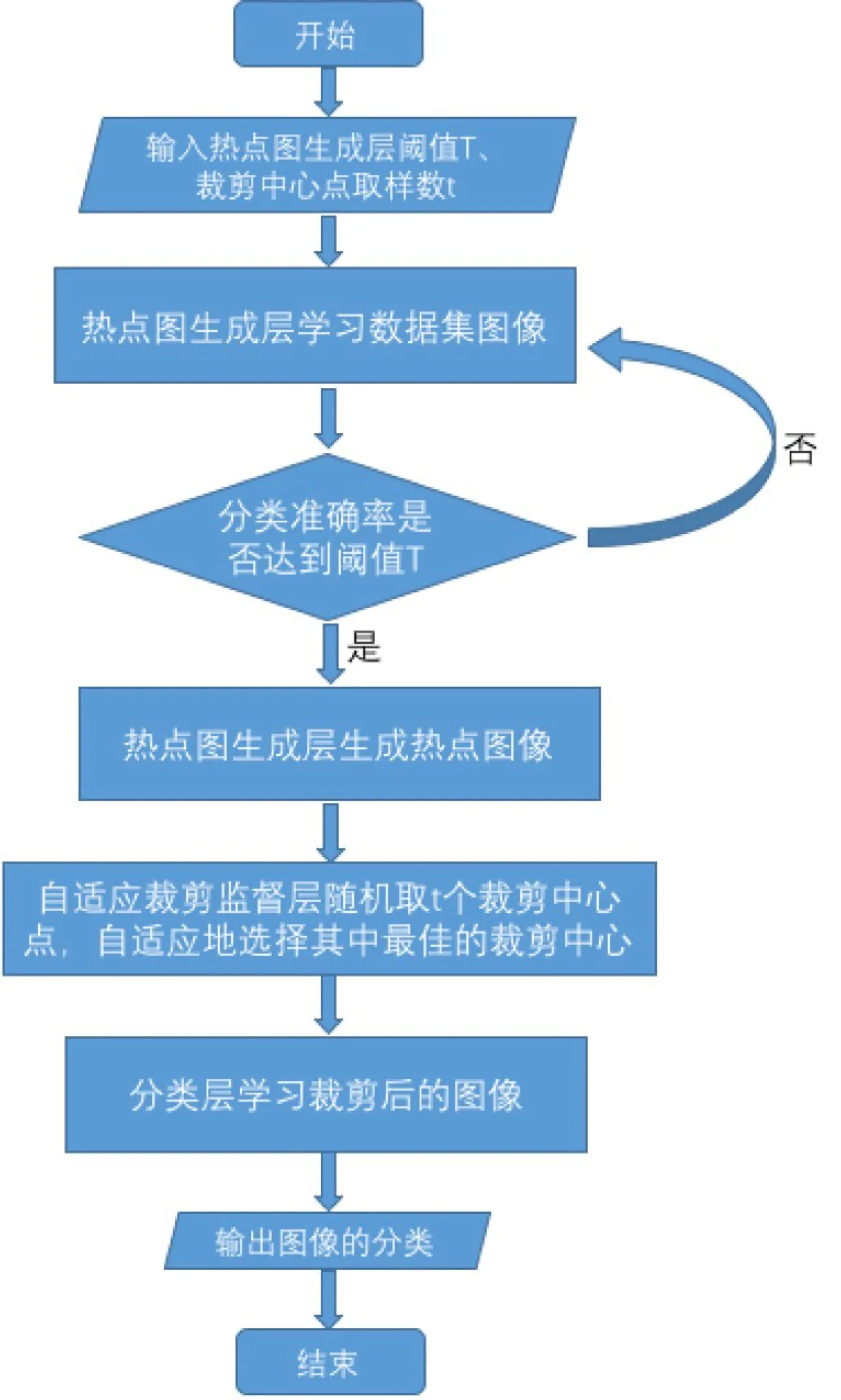
图1 基于自适应区域监督 机制的场景分类算法流程图Fig.1 Flowchart of scene classification algorithm based on adaptively regional supervision
在热点图生成层中学习每张场景图像的重要信息并且生成热点图像,在自适应监督裁剪层中依据热点图自适应地进行裁剪,最后将裁剪的图像输入分类层进行训练,得到对于图像的分类结果(算法如图2所示)。相比于原始的卷积神经网络算法,本算法既减小了网络参数的规模,又提高了网络的识别性能,使得算法模型具有更好的泛化能力。
1.1 热点图生成层
本层方法受到Zhou等[6]的启发。Zhou等[6]使用了类似于Network in Network[7]和GoogLeNet[5]的网络框架,提出了类别激活图(class activation map,CAM)[6],文中使用类别激活图进行弱监督的目标检测及分类,并且取得了与全监督卷积神经网络相当的识别度。
类别激活图是通过卷积神经网络中的全局平均池化(global average pooling,GAP)实现,全局平均池化输出最后一个卷积层每个单元特征映射的空间平均值,这些值的加权总和用于生成最终输出。同样,计算最后一个卷积层的特征图的加权和可以获得类别激活图,利用这些特征来得到每一类别的得分。本文的热点生成层基于此方法,通过设定的阈值,当模型分类的准确度达到此阈值时,使用其进行热点图生成。
给定一张场景图像,让fk(x,y)表示最后一个卷积层第k个单元上(x,y)位置上的值,对于单元k,使用全局平均池化可以得到结果
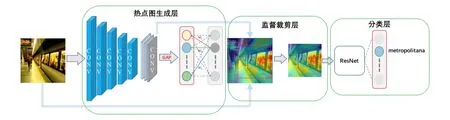
图2 基于自适应区域监督机制的场景分类算法示意图Fig.2 Sketch map of scene classification algorithm based on adaptively regional supervision
:
Fk=∑x,yfk(x,y)
(1)
对于给定的一个类别c,最后输出层(softmax层)的输入为:
(2)
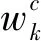
(3)
因此,得到每个类别的得分:
(4)
定义类别c的类别激活图中每一个空间点的激活值为:
(5)
图3是热点生成层效果示例图。热点生成层通过学习MIT Indoor数据集[8],生成了该数据集中一张标签为“酒吧”场景图的热点图,其中红色至蓝色由大至小表示相应区域与标签的相关程度,图中“吧台”等被标识为红色,表示其与标签“酒吧”具有更高的相关性。

图3 热点图示例图Fig.3 Example of heat map
1.2 自适应监督裁剪层
自适应监督裁剪层是为了对原始场景图像进行自适应有监督的裁剪以获得下一层网络的输入。本层以热点图为依据,自动地调整场景图裁剪区域,自动地适应不同场景图的关键信息,从而提高裁剪图像与分类标签的相关性,减少分类层网络的参数,降低网络训练的难度。
假设原始图像的大小为M×N,所需要裁剪的区域大小为m×n,每一次训练的过程中随机产生t个裁剪中心点:
(x,y)⊂{(x1,y1),(x2,y2),,(xt,yt)}
(6)
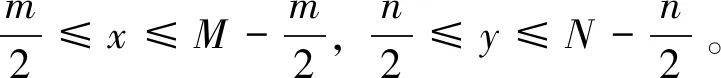
(7)
其中,1≤i≤t。 最后,选取得分最大的区域作为裁剪区域,其裁剪中心点值为:
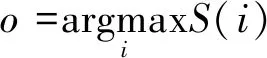
(8)
1.3 分类层
设定自适应监督裁剪层产生的裁剪中心点为(x0,y0),按照裁剪尺寸进行裁剪,得到一个大小为m×n的图像矩阵作为分类层的输入。
分类层使用的是He等[9]提出的残差网络(residual network,ResNet)结构, 为了解决深度网络准确度达到饱和之后下降的问题,ResNet采用残差模块(如图4所示)作为基本组成单元, 原始卷积层外部加入越层连接(shortcut)支路构成基本残差模块, 使原始的映射H(x)被表示为H(x)=F(x)+x。其中,F(x)被称为残差映射,x为输入信号,从而卷积层对H(x)的学习转化为对F(x)的学习。
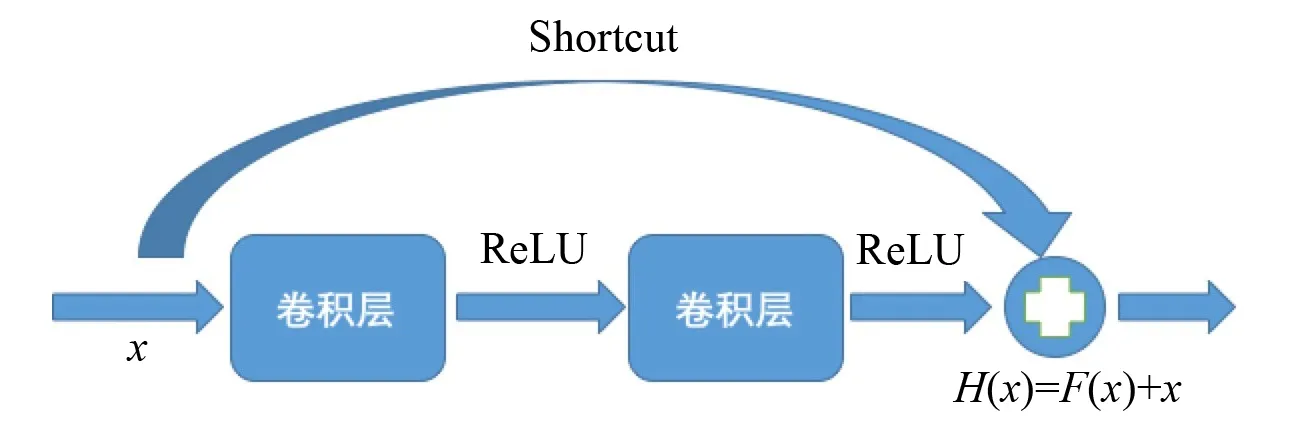
图4 残差模块示意图Fig.4 Sketch map of residual block
使用残差模块构成残差网络[9]作为分类层。假设分类的类别个数有I个,则通过热点生成层、监督裁剪层得到图像输入分类层之后,分类层的输出即softmax层的输出为:
output=[s1,s2,,sI]T
(9)
最后,将output中值最大的元素对应的分类,作为
对应图像的分类结果。
2 结果与分析
为了验证基于自适应区域监督机制的场景分类算法的有效性以及可靠性,本文在15-Scene和MIT Indoor两个数据集上进行了实验。15-Scene和MIT Indoor是两个使用于场景分类的权威数据集,被广泛应用于场景分类方面的实验。15-Scene[9]数据集由15种场景类别图组成,其中13种场景图由Fei-Fei发布,另外2种场景在其后进行补充;MIT Indoor由67个复杂室内场景组成,是一个权威的室内场景数据集。本文将所提的基于自适应区域监督的场景分类算法在15-Scene和MIT Indoor两个经典的场景分类数据集上进行了实验验证。
2.1 15-Scene数据集
在15-Scene数据集中,共有15个场景类别,平均每种场景有300张图片(共4 485张场景图)。图5是15-Scene数据集中五种不同场景的示例图。根据文献[10]的配置,对于每一类场景,随机选取100张场景图作为训练样本,其余为测试样本,进行20次独立实验,取均值作为实验结果。

图5 15-Scene数据集中不同类别的场景Fig.5 Examples of scenes in 15-Scene dataset
在参数设置方面,热点生成层的阈值T设置为90%,监督裁剪层生成裁剪中心点数t设置为10,实验过程中保持不变。实验中分类层使用了三种常用的网络,他们分别是ResNet50、ResNet152、Inception-ResNet。
为了验证本文所提出的算法的有效性(效率),分别使用ResNet50、ResNet152、Inception-ResNet网络以及本文基于自适应区域监督机制的场景分类算法在15-Scene[9]数据集上进行实验,统计不同方法单个Epoch的平均运行时间。图6为不同方法时单个Epoch消耗的平均时间。由图可知,裁剪使得输入网络的图像尺寸变小,网络的参数规模变小,基于自适应区域监督机制的场景分类算法的运行效率均比原始网络框架高。
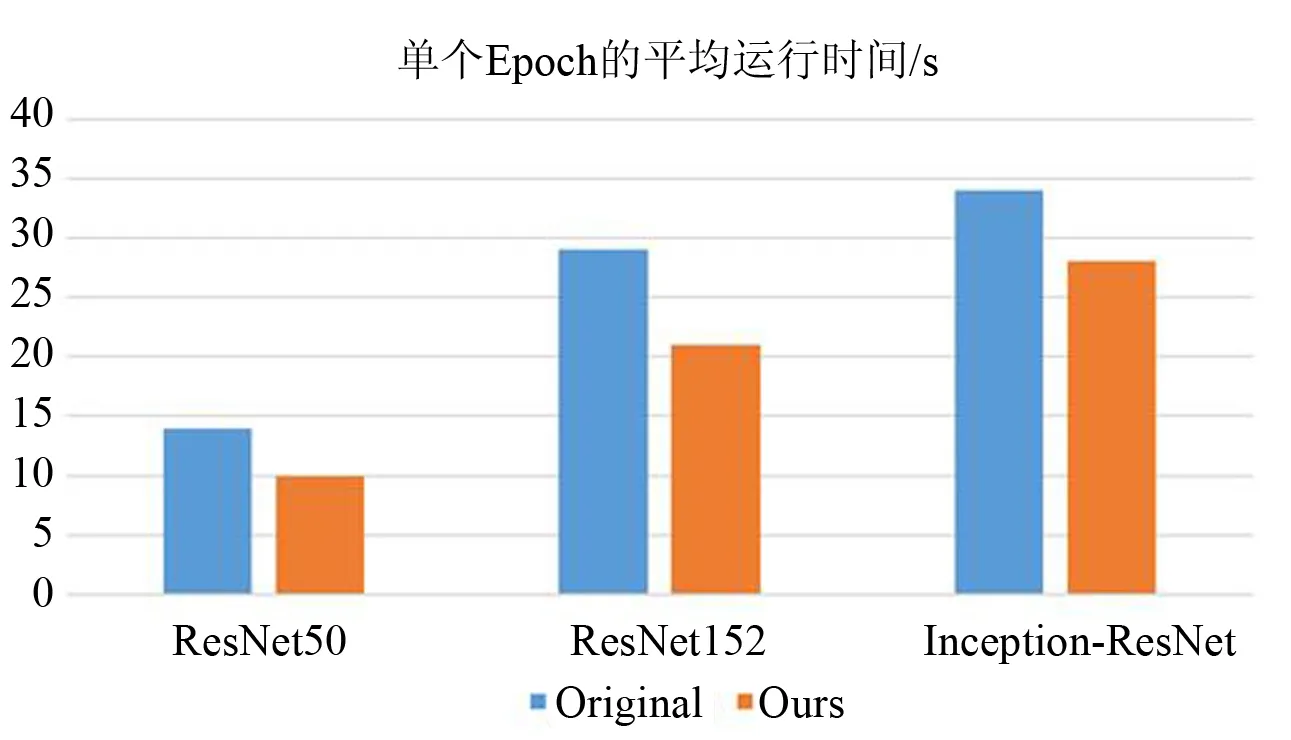
图6 15-Scene数据集训练 过程中单个Epoch的平均运行时间Fig.6 The average runtime of a single Epoch during the training of 15-scene dataset
为了验证本文提出的算法的可靠性(识别率),分别使用随机裁剪场景图的ResNet50、ResNet152、Inception-ResNet算法以及本文算法在15-Scene数据集上进行实验。表1是在15-Scene数据集上的的实验结果。从实验结果可以看出,不管是ResNet50、ResNet152、Inception-ResNet,基于自适应区域监督机制的场景分类算法的Top1、Top3、Top5准确率都有明显的提升;相对于随机裁剪图像的算法,基于自适应区域监督机制的ResNet50的Top5准确率提升5.64%, ResNet152的Top5准确率提升8.76%, Inception-ResNet的Top5准确率提升1.04%。另外,相比于文献[6]中的ImageNet预训练模型结合SVM分类器、Places预训练模型结合SVM分类器两种算法以及文献[11]中的LESMLIP算法,本文所提出的算法自适应地关注到场景图中重要的信息,并且使用这些信息进行深度神经网络的训练,使得网络具有较高的准确度,具有实际的参考价值。
2.2 MIT Indoor数据集
在MIT Indoor数据集中,共有67个室内场景类别,每个类最少有100张图片(共15 620张场景图)。图7是MIT Indoor数据集中五种不同场景图像的示例图。根据文献[8]的配置,对于每一类场景,训练样本为80张,测试样本为20张,进行20次独立实验,取均值作为实验结果。
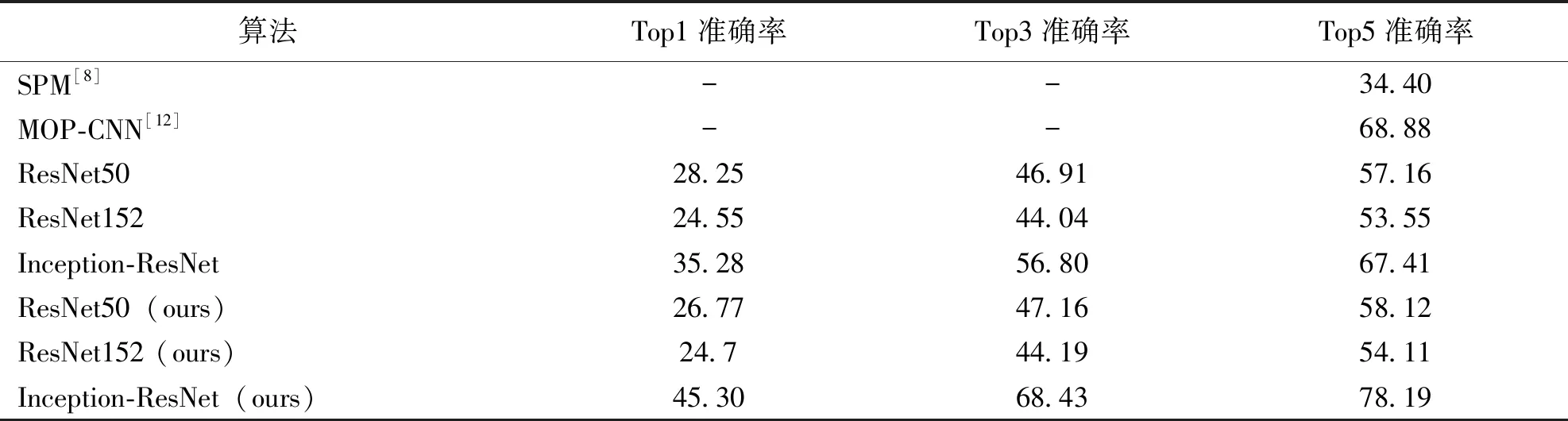
在参数设置方面,热点生成层的阈值T设置为55%,裁剪中心点取样数设置为10,实验过程中保持不变。为了更好地进行比较对照,除了在ResNet50、ResNet152、Inception-ResNet进行实验以外,还与文献[8,12]在MIT Indoor的实验结果进行比较。
表2是在MIT Indoor数据集上的的实验结果。从实验结果可以看出,除了个别指标外,基于自适应区域监督机制的ResNet50、ResNet152、Inception-ResNet的Top1、Top3、Top5准确率都有提升;其中,相比随机裁剪图像的算法,基于自适应区域监督机制的ResNet50的Top5准确率提升1.68%,ResNet152的Top5准确率提升1.05%,Inception-ResNet的Top5准确率提升15.99%。基于自适应区域监督机制的Inception-ResNet相对于随机裁剪图像的算法准确率有了很明显的提升。另外,相比于文献[8]中的SPM算法以及文献[12]中的MOP-CNN算法,本文所提出的算法准确地关注到了与标签相关的场景信息,使得分类具有较高的准确度,其中随机裁剪的Inception-ResNet准确率低于MOP-CNN[12];而,基于自适应区域监督机制的Inception-ResNet关注到了场景图中的重要信息,从而准确度相比于MOP-CNN提升了13.51%。
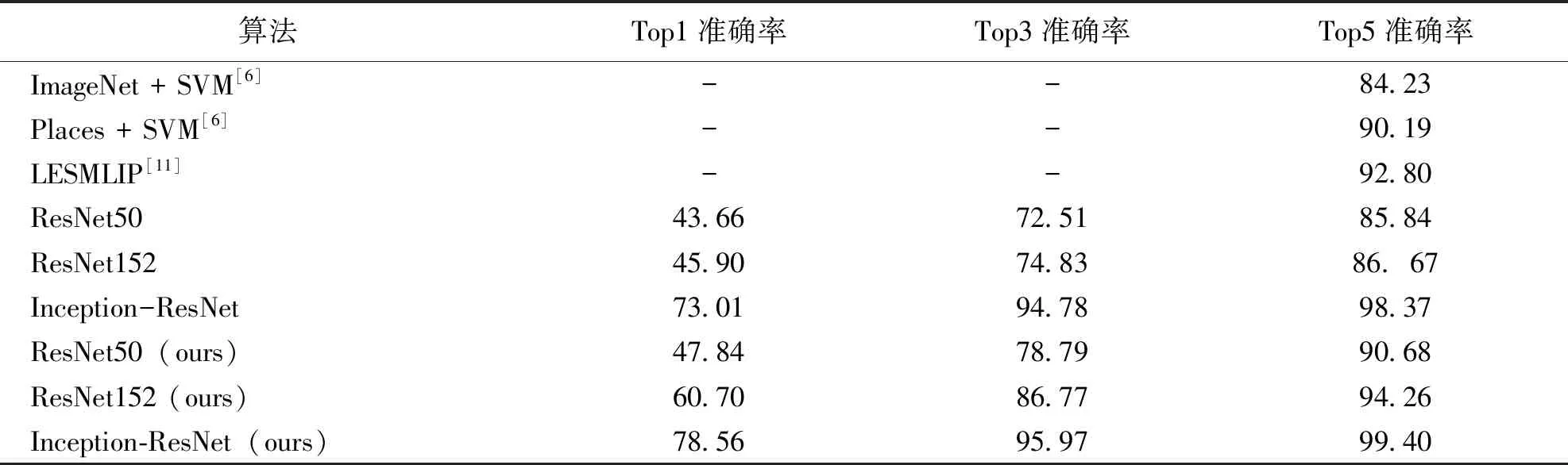
表1 15-Scene数据集中Top1、Top3、Top5准确率Table 1 Top1, Top3 and Top5 accuracy in 15-Scene %

图7 MIT Indoor数据集中场景图像的示例图Fig.7 Examples of scenes in MIT Indoor dataset
2.3 结果分析
通过在15-Scene和MIT Indoor两个数据集的实验,基于自适应区域监督机制的场景分类算法能够提高运行效率以及识别准确率,在15-Scene数据集中最高识别率达到99.40%,在MIT Indoor数据集的最高识别率达到78.19%。结果表明,基于自适应区域监督机制的场景分类算法能够减小网络参数的规模,算法的运行效率高,能够裁剪出与标签相关较强的图像,对复杂场景的适应性和鲁棒性好。
3 结 语
本文提出了基于自适应区域监督机制的场景分类算法。算法由三部分组成:热点图生成层、自适应监督裁剪层、分类层。热点图生成层通过学习图像数据集以生成热点图,自适应监督裁剪层依据热点图自适应地调整最佳的裁剪位置,最后分类层学习裁剪后的图像,输出每张图像的分类。这种自适应区域监督机制,能够提高裁剪图像与分类标签的相关性以提高算法的识别率,并且能够减小了网络参数的规模以提升算法的运行效率。在15-Scene和MIT Indoor两个数据集上的实验表明:相对于原始算法框架,本文算法的效率以及识别率更高,对复杂的场景图像具有更好的适应性。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
车迷(2019年10期)2019-06-24
消费导刊(2018年8期)2018-05-25
快乐语文(2018年7期)2018-05-25
消费导刊(2017年24期)2018-01-31
消费导刊(2017年24期)2018-01-31
理论导刊(2016年11期)2016-11-19
