
基于改进免疫遗传算法的索引数据库查询优化方法
2019-03-27 12:28徐千淞陈怡陈云选张刘玲
中国新通信 2019年22期
徐千淞 陈怡 陈云选 张刘玲
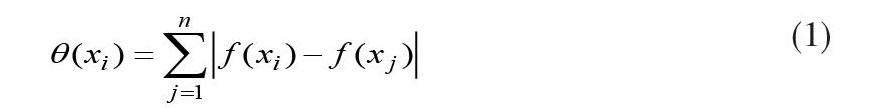

【摘要】 查询优化是提高索引数据库性能的关键技术,针对索引数据库查询优化效率低的难题,提出了一种改进免疫遗传算法的数据库查询优化算法。首先借助免疫算法提高遗传算法的整体性能,解决遗传过程中会出现退化和求解过程中对特征信息利用不够的现象。然后考虑群体中具有相似特性的个体容易聚集的现象,将遗传算法中的交叉操作变为自适应交叉概率操作。结果表明,本文提出的算法是解决数据库查询优化的有效途径,能够获得理想的数据库查询结果,具有实际意义。
【关键词】 索引数据库 查询优化 免疫遗传算法
一、引言
在许多基于数据库的应用中,数据库的查询响应时间己经成为影响整个数据库系统性能的关键性限制因素。研究数据库系统的学者们普遍认为数据库查询效率的目标是:以最快的时间响应用户的查询并且在此基础上控制最少的网络通信费用。在多连结查询中,一个查询随着连结的关系数的增加该查询的执行计划的个数呈现指数级的增长,导致查询优化的计算非常复杂。
在之前学者们的研究中,为了优化查询效率,已经提出了模拟退火算法、遗传算法、SSD-1算法等的思想。其中遗传算法因其效果显著而被广泛应用于数据库查询优化中。Kristin Bemmett等人定义了交叉和变异算子并提出一种基于遗传算法的数据库查询优化的方法[1]。接着SangkyuPho等人又提出了一种新的编码方法,方法定义了基于遗传算法查询优化的执行步骤和代价函数的计算方法[2]。国内对基于遗传算法在数据库查询优化的研究相对较晚。周莹等人提出了基于多蚁群遗传算法的数据库查询优化研究[3],林基明、班文娇等提出了基于并行遗传-最大最小蚁群算法的数据库查询优化[4]。都使用遗传算法对数据库查询进行了一定的优化。虽然在前面国内外己经有过关于遗传算法在数据库查询优化中的大量研究,但是从实际应用的角度来看,他们的方法还是有一定的缺陷,像算法时间复杂度比较大、交叉算子和变异算子的选取有待进一步改进等。
因此,针对上述方法计算复杂度较高,查询时间过长的缺点,本文提出一种改进的遗传算法。結合免疫理论和遗传算法的优点来产生一种新的算法,它不仅具有遗传算法搜索的特性,而且还具有自适应的性质,可以解决免疫算法的目标函数最优解问题。因此,通过在数据库查询优化中使用该算法,可以显着提高索引数据库查询的效率。
二、索引数据库查询
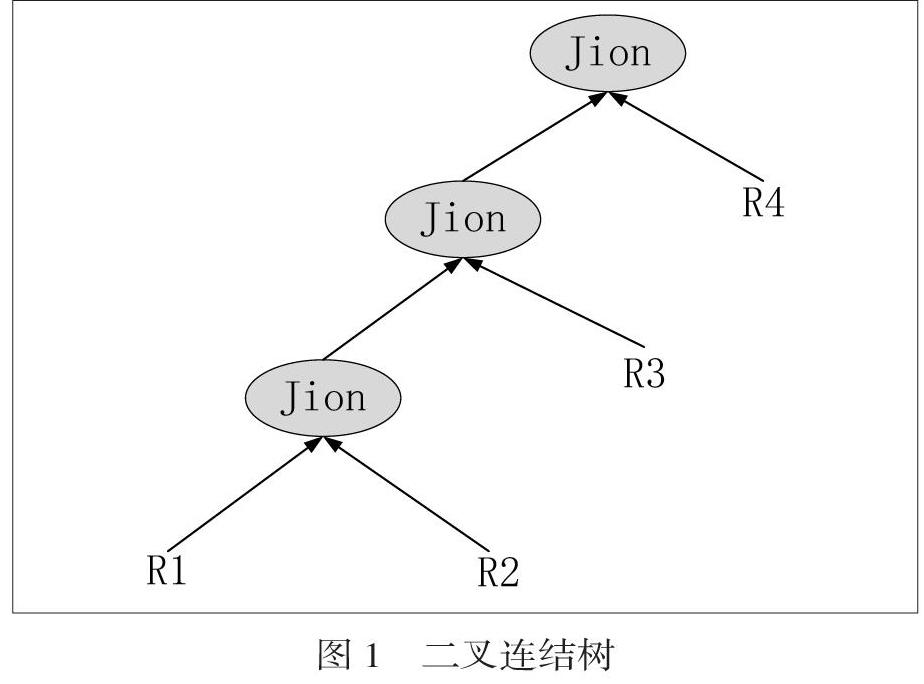
通常采用二叉连结树来表示索引数据库的多连结表查询。查询树中的左节点表示连接操作,右节点表示两个操作之间的关系,如图1所示。
树中定义了操作的执行顺序,索引数据库查询的策略空间大小是由算法所遵循的等价转换规则集和查询执行引擎所支持的物理操作集所共同决定的。一般情况下策略空间都比较大,因此,查询优化算法通常避免在整个策略空间搜索,尽可能在最佳的查询执行计划的一个策略空间的子集中搜索[5]。对于一个复杂查询,等价的运算树的数量可能会很大。查询优化程序一般要限制所考虑的搜索空间。我们考虑浓密树型结构,因其在体现并行化时用途更为明显。选择了搜索空间后,需要选择一个高效的搜索算法了,原则是要使算法的执行时间和找到的查询执行计划的执行计划的和最小。
三、改进遗传算法的数据库查询优化问题求解
算法中选择的概率与群体的适应性有关,群体越多,适应度越强。这使得群体中具有相似特性的个体容易聚集,从而降低算法的收敛速度,并直接影响最优解的质量。针对上述问题,本文考虑依靠抗体间的载体距离和适应性抗体的亲和力,为了将优良的基因个体传递给下一代,遗传算法中的交叉操作变为自适应交叉概率操作。改进的适应性疫苗提取方法可以从优秀的群体中提取疫苗,从而最大化抗体的多样性并减少先验依赖性。对于基因突变,其具有疫苗的作用,可以使基因块重组,提高亲和力从而保证算法的局部优化能力不变。改进过程如下。
3.1遗传算子
遗传算子主要包括三个部分:选择,交叉和变异。首先设置选择概率,定义适应度函数为f(x)。免疫算法中的抗原对应要解决的问题,抗体对应解决方案。在n个抗体的集合中,抗体之间的载体距离为
最后是免疫选择,从组中选择出具有高适应性的个体将(通常为50%)。这些被选择的个体用作下一代初始化的疫苗,以执行下一轮免疫遗传操作,直到算法终止。
四、仿真实验
4.1环境配置
为了测试本文改进免疫遗传算法AIGA(Adaptive Immune Genetic Algorithms, AIGA)的性能,在CPU为Intel Core i7-6700HQ @ 2.60GHz,RAM为8.0GB,操作系统为Windows10的平台下,采用python编程数据库查询优化算法实现仿真实验。数据库来自一个大型资源服务搜索系统的数据,共有141323记录,每条记录包括多个子字段。同时为了使本文算法具有可对比性,选择的对比算法为:基础遗传算法(Genetic Algorithms, GA)、基础免疫遗传算法(Immune Genetic Algorithms, IGA)。
4.2结果与分析
最优查询方案的收敛情况和质量,如图2和图3所示。对图2与图3结果进行分析,可以得到如下结论。
对于10个关系的数据查询问题,当迭代187代时,GA算法才找到最优数据库查询方案,对应的执时间为110.22s;在相同条件,当迭代162代时,IGA算法找到最优数据库查询方案,其执行时间为89.25s,相对于GA算法,性能更优。对于相同问题,AIGA算法迭代141次后得到比 GA算法和IGA算法更优的数据库查询方案,其执行时间为72.29s。相对GA算法,IGA算法提高了求解速度,获得更优的查询解,同时AIGA算法性能得到进一步提高,克服了对比算法存在的不足,是一种速度快、效率高的数据库查询优化方法。
五、总结
针对当前基于遗传算法的数据库查询优化算法存在的遗传过程中出现退化和求解过程中对特征信息利用不够的现象,且免疫遗传算法在群体中具有相似特性的个体容易聚集的缺陷,本文提出一种AIGA算法的索引数据库优化查询方案,在免疫遗传算法的基础上,将遗传算法中的交叉操作变为自适应交叉概率操作,改进遗传算子,并重新构建免疫疫苗。
实验结果表明,AIGA算法能够提高算法的全局搜索能力,较好的克服了GA、IGA算法中存在的缺陷,获得了更优的数据查询方案,在数据库中具有广泛的应用前景。
参 考 文 献
[1] Li D, Han L, Ding Y. SQL Query Optimization Methods of Relational Database System[C]// Second International Conference on Computer Engineering & Applications. IEEE Computer Society, 2010.
[2] Kadkhodaei H R, Mahmoudi F. A combination method for join ordering problem in relational databases using genetic algorithm and ant colony[C]// IEEE International Conference on Granular Computing. IEEE, 2012.
[3] 周瑩, 陈军华. 基于多蚁群遗传算法的分布式数据库查询优化[J]. 上海师范大学学报(自然科学版), 2018(1).
[4] 林基明, 班文娇, 王俊义, et al. 基于并行遗传最大最小蚁群算法的分布式数据库查询优化[J]. 计算机应用, 2016, 36(3):675-680.
[5] Tatar A , Amorim M D D , Fdida S , et al. A survey on predicting the popularity of web content[J]. Journal of Internet Services and Applications, 2014, 5(1):8-12.
