
基于数学教学的知识图谱构建
2019-03-21 11:35:42戈其平钟艳如
计算机技术与发展 2019年3期
戈其平,钟艳如
(桂林电子科技大学 计算机与信息安全学院,广西 桂林 541000)
0 引 言
在新课程背景下,提高学生对数学的自主学习能力,不仅有利于掌握本阶段的一些知识,而且更能促进数学综合素质的提升[1]。但是对于不同学生,在对同样的数学知识进行学习的时候会产生不同的学习效果。产生这一现象主要是因为知识是对事物结构的认识,不同的学习者对知识结构的组织也会不同。一般来讲,效果好的学习者对知识结构会进行系统化处理,让知识进行分层排布,使得知识能以网络的结构来在脑海中进行存储。因此在数学教学过程中,如何让学生构建数学知识网络结构是很重要的[2]。
知识图谱是利用知识间的语义关系,将分散的知识收集起来的网络结构。它首先利用自然语言技术自动抽取实体,然后通过本体策略构建出结构化或半结构化的数据[3],以找出它们之间的联系,最后通过可视化引擎工具进行展示。将知识图谱运用在数学教学上,不仅加强了数学内容章节与章节之间的联系,帮助学生对数学知识进行有效存储,还可以实现知识的共享。与此同时,知识图谱还可以将教学资源进行系统化,以激发学生的自主学习能力,所以构建关于数学内容的知识图谱是解决教学问题的好方法。
通过分析本体与知识图谱的相关概念,通过对数学知识的部分挖掘,并结合知识图谱表示技术,实现基于数学教学的数学内容知识图谱的构建以及可视化。
1 相关知识
1.1 本 体
本体是一种形式化表示方法,表达的是概念的结构、概念与概念之间的关系。对于不同领域,构建本体的方法也是不同的。构建本体的方法一般包括IDEF5、AFM、骨架法、七步循环法、半自动构建法、自动构建法等等。构建本体的开发工具有OntoEdit,WebOnto,WebODE,KAON和protege。本体的构建流程如图1所示[4]。

图1 本体构建流程
1.2 知识图谱
知识图谱是一个结构化的语义知识库,用符号的形式来描述物理世界中的概念及其他的一些相互关系。它的基本组成单位是:“个体-关系-个体”的三元组,个体之间通过关系链进行相互连接[5]。从图的角度而言,知识图谱属于一种概念网络,其中节点表示物理世界中的实体,而实体与实体之间的语义关系则由网络的边表示[6-9]。
对于知识图谱的构建,首先从原始数据出发,采用一系列自动或者半自动的技术手段,抽取其中的知识要素,并将其存入到知识库的数据层和模式层中。然后依次迭代,每一轮的迭代都包含如下阶段:知识建模,信息抽取,知识融合,知识加工。知识图谱常用的构建技术有Semantic Wiki,XTM,自动标引和本体技术等,而构建模式分为四步,六步,七步和核心三要素模式这四种[10]。知识图谱构建步骤如图2所示。

图2 知识图谱构建步骤
2 数学内容知识图谱构建
2.1 数学内容信息抽取
数学内容的信息抽取就是需要从不同年级与不同章节的数据源中抽取出实体、属性以及实体之间的相互关系,在此基础上形成基于数学内容本体化的知识表达。信息抽取如表1所示。

表1 信息抽取
2.2 数学内容知识融合
在完成信息抽取后,通过自然语言处理技术根据实体之间的语义相似度对其进行对齐,来消除实体的矛盾和歧义以及冗余率,降低存储空间和构图复杂性。文中采用共性语义相似度计算方法[11]:
(1)
其中,Sim(A,B)表示A,B之间的相似度;Com(A,B)表示共性;description(A,B)表示个性。
通过语义计算后进行融合,如表2所示。
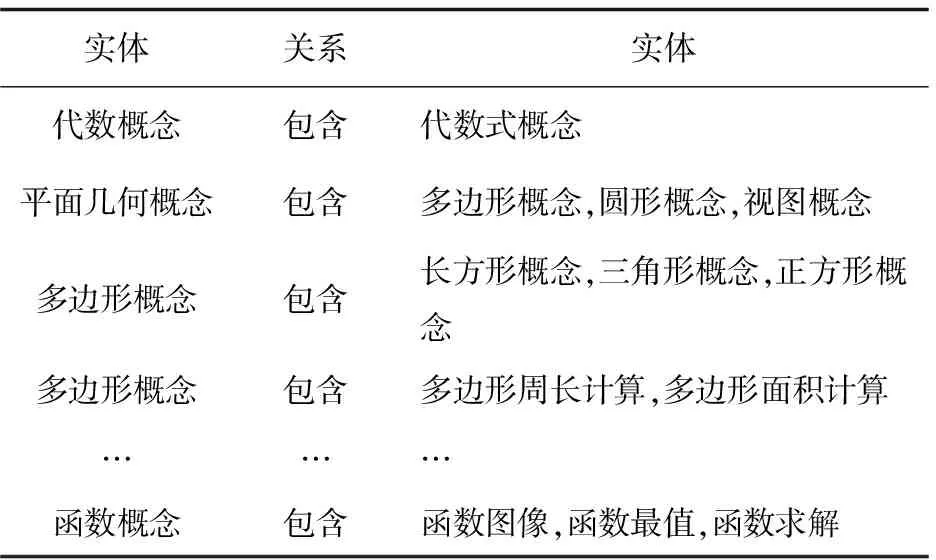
表2 知识融合
2.3 数学内容知识加工
对于经过融合后的新知识,需要经过质量评估,语义相似度检测,才能将合格的部分加入到知识库中,来确保知识库的质量。并且根据相似度及实体之间关联程度设立不同的等级,使得整个知识库更加层次化。当新增数据后,通过推理从而达到获得新的知识的功能。质量评估函数如下[12-15]:
(2)
其中,J表示质量等级;yi表示得到的知识;Y表示监督语料。J的值越小,表示新添加内容越符合该知识库。同时根据J值大小来衡定包含等级,J值越大,包含等级数越高。
知识加工如表3所示。

表3 知识加工
2.4 知识图谱可视化
当知识加工进行完后,在知识图谱中的每一个知识点的定义以及层级结构的划分和知识链也会得到相应的实现。基于Neo4j引擎,文中通过Java语言在Windows下对知识图谱进行了可视化,如图3所示。
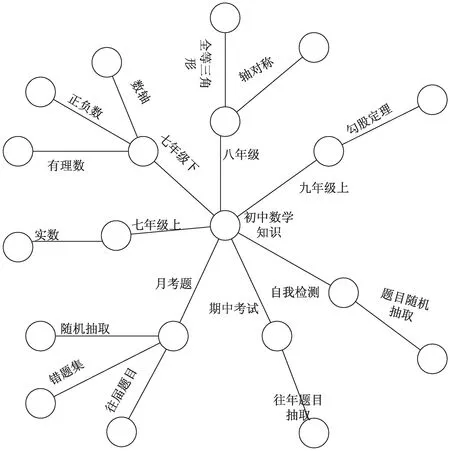
图3 知识图谱可视化
将知识图谱可视化后,点击每一个实体节点后,除了会展示已经设定好的内容,还会爬取互联网上一些类似的教学资源,从而达到将知识系统化的目的。不仅如此,当加入新的知识后,根据自动推理能力就可以将其自动归入到图谱的某一个分支上,从而完成对新知识的自动更新。
3 结束语
提出了一种基于数学教学的知识图谱构建方法,并以数学内容为例对其进行了知识图谱构建与可视化。知识图谱技术在一定程度上能将知识更好地展示,使得教师在教学的过程中更加系统地规划教学路线,学生在学习过程中能够将离散与碎片化的数学知识进行结构化与完整化,从而提高了教学质量与学生学习效率,在一定程度上帮助了智慧课堂的建立。与此同时,虽然在构建过程中采用自然语言技术对碎片化的知识进行了自动抽取与分类,但是由于技术的不成熟,有些步骤还是需要手动添加与排错,不能达到真正意义上全自动的状态。因此,对于知识图谱构建技术的研究还有很多工作需要去做。
猜你喜欢
哲学分析(2023年4期)2023-12-21 05:30:27
少先队活动(2020年12期)2021-01-14 01:47:40
中国音乐学(2020年4期)2020-12-25 02:58:06
制造技术与机床(2019年6期)2019-06-25 10:17:46
中成药(2017年3期)2017-05-17 06:09:01
中国交通信息化(2016年9期)2016-06-06 07:42:23
领导科学论坛(2016年9期)2016-06-05 14:59:58
文学教育(2016年27期)2016-02-28 02:35:15
图书馆研究(2015年5期)2015-12-07 04:05:48
卷宗(2013年6期)2013-10-21 21:07:52
