
基于人脸识别的海量图片的存储和索引优化
2019-03-21 11:35:34阳许军
计算机技术与发展 2019年3期
蒋 园,阳许军
(1.武汉邮电科学研究院,湖北 武汉 430074;2.武汉虹信技术服务有限责任公司 研发部,湖北 武汉 430074)
0 引 言
当前,人脸识别技术在生活中的应用十分普遍且重要,尤其园区的门禁系统中,比如某公司在某幢楼的出入口和楼层的办公室出入口都分别布控摄像机,每天人员通过刷脸进行识别进入公司,摄像机拍摄人脸照片后会将照片存储到文件系统中,在进行检索比对的过程中,特征服务器会将拍摄的照片进行特征提取,对比服务器会将提取的特征码与注册库存放在MySQL中的特征码进行比对来识别当前人物是否是公司员工。而这中间就面临一个问题:选用合适的存储文件系统来存储每天拍摄的海量图片小文件(小于1 M)。目前为止已经出现了一些以Linux为基础的分布式文件系统,以支持高可靠、高性能以及高并发的应用需求[1]。自从谷歌开发了面向集群的大数据分布式文件系统GFS后,相继出现了许多如FastDFS、MogileFS、HDFS、TFS(Taobao FileSystem)等类似的分布式文件系统。这些文件系统的目标都是一致的,都是为了实现高可用性、可伸缩性和高容错性的分布式文件系统需求[2]。但是这些大文件分布式系统往往针对的是TB以上的数据量,一旦存储小文件系统必然面临着性能问题。主要表现在以下几个方面:
(1)元数据的管理效率低下:当今大多的文件系统主要是针对大容量的文件,在磁盘的不同位置会存放着文件的索引,数据,以及目录,从而造成访问一个文件需要访问磁盘的多个地方,但是一旦访问高峰期并发的小文件就会造成磁头大量移动从而降低机械磁盘的读写效率[3]。
(2)数据布局单一:分布式文件系统往往将大文件分成多个小文件分别存放在多台服务器上进行存储,但是由于小文件的容量太小不易切分,只能存放在单台服务器上,导致一旦高峰期本该并发访问多台服务器变成访问单一的服务器,使得性能下降[4]。
(3)人脸识别过程要进行实时数据对比,当面临大量数据访问时要达到实时的效果就要考虑是否需要增加内存数据库[5]。
(4)当处于人流量高峰期,为了快速检索文件就需要建立有效的索引机制[6]。
对此,文中提出一种结合FastDFS小文件存储系统和Redis内存数据库以及Mysql关系型数据库的方案。首先将同一摄像机目录下的小文件合并成大文件并且建立内部索引,然后将合并后的大文件写入到FastDFS中生成大文件索引,同时将大文件索引传给客户端,客户端结合大文件索引和局部索引生成大索引,最后利用Redis的Key-Value特性和Mysql持久化来存储文件名和对应的大索引。但是由于Redis是内存数据库,内存只保存15天的数据文件的文件名和对应的大索引。有时公司需要查出在相邻时间左右出入的人员,因此也增加了预取模块以提高查找效率。
1 系统架构
1.1 FastDFS简介
FastDFS是一个能够存放大量小文件和负载均衡的开源轻量级分布式文件系统[7]。主要有三个角色组成:跟踪服务器(tracker)、存储服务器(storage)和客户端(client)[8]。tracker主要起着调度和负载均衡的作用,记录storage上传的状态信息,不记录索引信息,所以管理的原信息少,全部存储在内存中,存储服务器主要以组为单位可以组内部署多个storage,由于数据互相备份,因此配置尽量相同,存储服务器主要是调用文件系统来管理文件和存储文件,同时向跟踪服务器汇报自身的状态信息[9]。client是FastDFS的客户应用接口,提供如文件上传,修改,追加等功能,同时通过TCP/IP协议来与跟踪服务器和存储服务器进行数据传递。
1.2 Redis数据库简介
Redis是一个基于内存的持久化内存数据库[10]。它支持存储的value类型相对更多,string(字符串)、list(链表)、set(集合)、zset(sorted set-有序集合)和hash(哈希类型)[11]。其优点主要如下:读写速率很高:读速度是110 000次/s,写速度是81 000次/s[12];丰富的数据类型:Redis支持二进制案例的string,list,hashes,set,orderdsets数据类型的操作[13];原子:Redis的所有操作都是原子性的,同时支持对几个操作合并后的原子性操作[14]。
1.3 内部小文件和大文件索引的建立
园区的组织结构如图1所示,并且在相应的结构中安装摄像机。
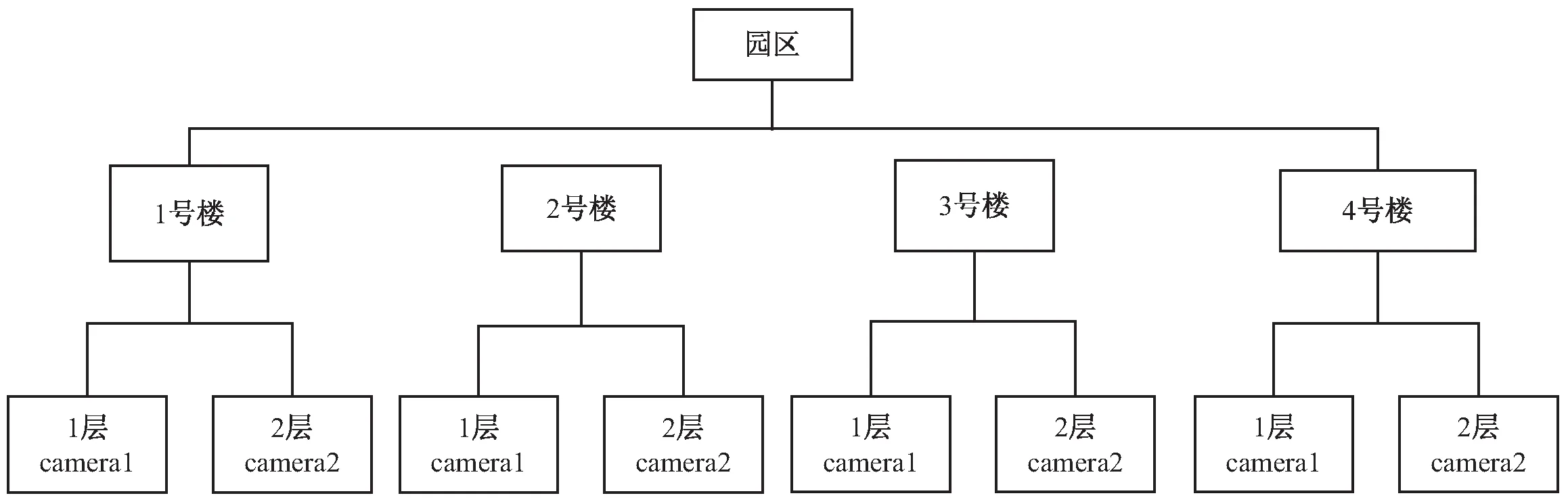
图1 公司园区简图
图2是按条件检索的过程。
针对上述组织结构,相机抓拍服务器的文件目录结构是:园区/楼号/楼层/文件名字及创建时间,比如:A园区/1号楼/1层/camera1/xxx.2018.3.12,因此增加小文件聚合模块,将同一目录下的小文件聚合成大文件并建立内部小文件索引,索引的组织结构是:小文件偏移量:小文件长度。同时将生成的大文件存储在FastDFS也会产生索引,由于FastDFS一般在底层产生2级目录里面的文件名是由存储服务器自动生成的,文件名包括服务器的IP,时间,文件信息等,结构是组名/虚拟磁盘路径/一级目录/二级目录/文件名。FastDFS将大文件索引传给客户端,客户端将大文件索引和局部的索引共同聚合成大索引:组名/虚拟磁盘路径/一级目录/二级目录/文件名/小文件偏移量/小文件长度。
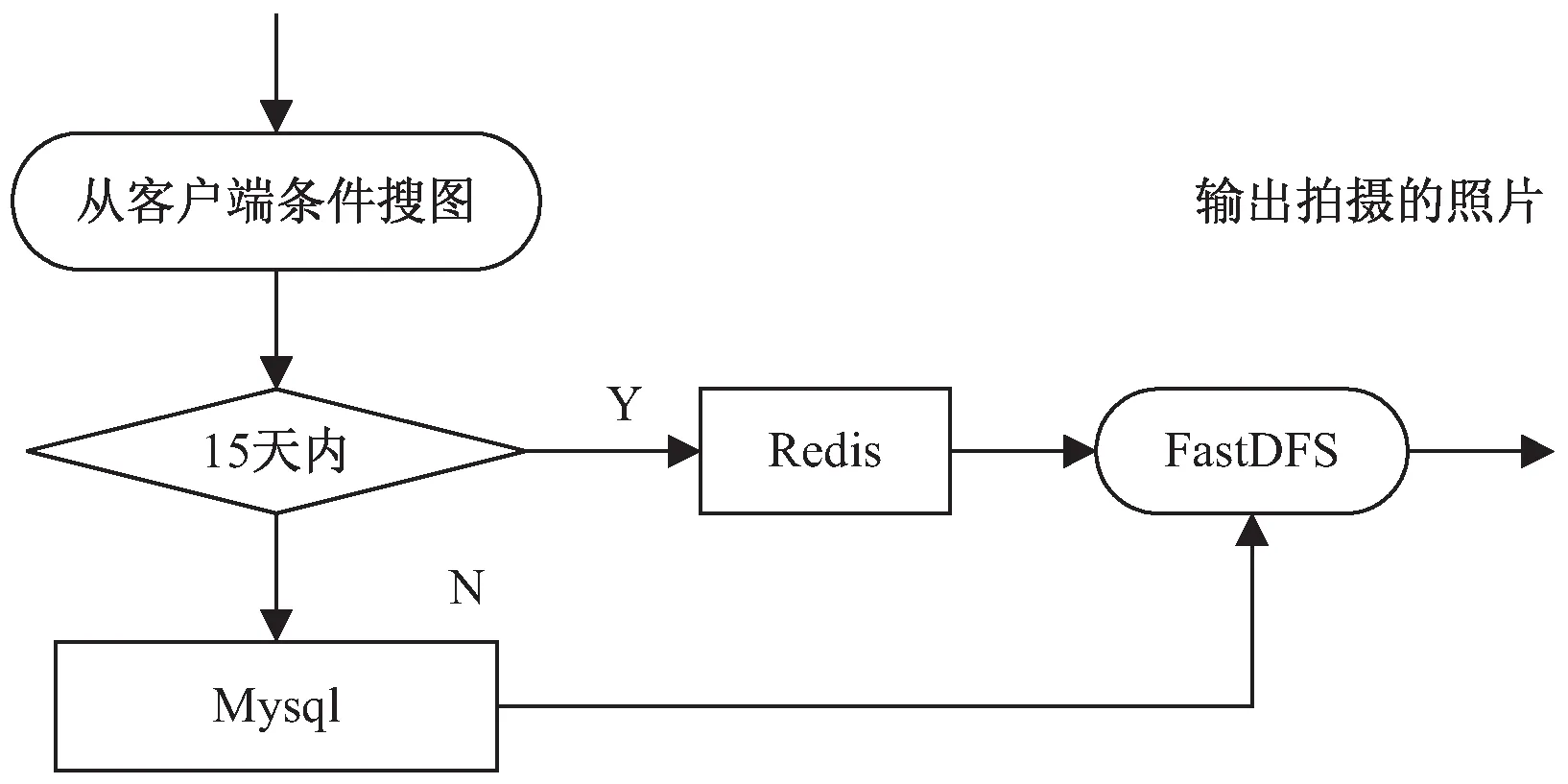
图2 条件搜图的简单过程
客户端将全文索引存放在Redis和Mysql中,文件名由位置点,相机id和创建的时间组成,结构是每一个文件名对应着文件的全局索引。
FastDFS文件存储结果如图3所示。

图3 FastDFS文件存储结构
1.4 具体写入的流程
(1)客户端的聚合模块将来自同一个id像机目录下的图片小文件聚合成大文件并建立局部的小文件索引。
(2)客户端将大文件写入到FastDFS中进行存储,生成相应的大文件索引。
(3)将大文件索引传给客户端,客户端将大文件索引和前面的局部索引建立全文索引。
(4)Redis和Mysql存储大索引和相应的文件名。
将它们聚合成大数据文件再读到FastDFS中,以免随即读写,同时在人脸识别的过程中尤其在公安系统的监督过程中往往根据查询条件读取在时间前后出现的图片,因此该系统还会在客户端添加预先读取模块,其工作流程如图4所示。

图4 预先读取流程
针对以上特点,文中开发了五大功能模块,即小图片的聚合存储功能模块、系统索引功能模块、小文件读取功能模块、小文件删除功能模块和小文件修改功能模块[14]。根据聚合存储功能模块将目录下的小文件合并成数据文件并且建立局部的相关索引,再通过FastDFS写文件接口将数据文件写入到FastDFS进行存储,最后FastDFS返回数据文件索引给客户端,客户端将数据文件索引和局部文件索引一起反馈给Redis和Mysql,Redis和Mysql中的系统索引功能模块将全局索引和局部索引一起生成全局索引。
2 实 验
2.1 实验环境的搭建
实验搭建在一台电脑上,LENOVO 20269Intel(R)Core(TM)i5-4200U CPU@1.60 GHz(4 CPUs),4 096 MB RAM,电脑上安装VMware虚拟机VMware®Workstation 12 Pro,在虚拟机上安装两个Linux操作系统,Ubuntu 64位,内存都是512 M,处理器1,Redis-2.8.4,Mysql-5.7.21。
2.2 实验数据
实验数据来源于武汉某公司园区各个楼层摄像机近30天拍摄的图片文件,挑选了1 000张进行实验写性能的测试,同时将改进方案运用在系统中30天以检测读的性能。
2.3 实验对比
实验主要测试4次,分别记录FastDFS系统和FastDFS-Redis-Mysql系统每秒读写小文件的数据量,然后再将最终的数据求平均值进行对比,从而得出实验结果。
2.3.1 小文件写入性能对比
实验中分别向FastDFS系统和FastDFS-Redis-Mysql系统传入1 000张图片(800 K),各吞吐量统计数据如表1所示。由于后者是通过客户端聚合模块合并图片小文件进行聚合写操作的,客户端与存储服务器的网络交互次数要少得多,因此FastDFS-Redis-Mysql的写吞吐量普遍大于FastDFS的写吞吐量。FastDFS-Redis-Mysql系统和FastDFS系统的平均吞吐量分别为8.45 MB/s和9.09 MB/s。实验结果表明,FastDFS-Redis-Mysql能够提高人脸识别中海量小图片文件的写入性能。
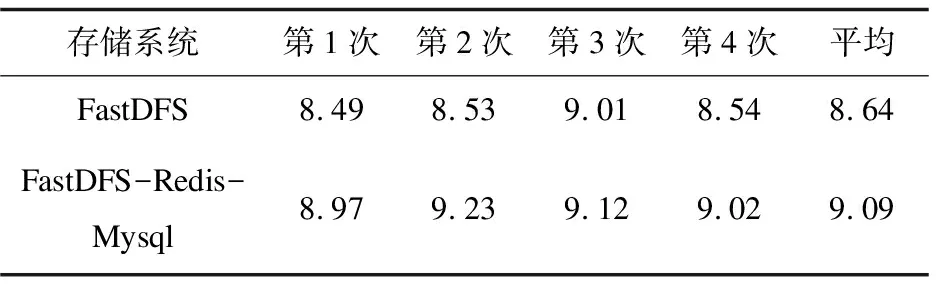
表1 FastDFS和FastDFS-Redis-Mysql的 小文件写入吞吐量统计
2.3.2 小文件读取性能对比
按照日期进行读查询,第一次和第二次是查询15天之内的图片文件,第二次和第三次是15天以上的图片文件,FastDFS和FastDFS-Redis-Mysql系统的读取吞吐量如表2所示,平均吞吐量分别是8.17/s和8.58/s。因此相应的吞吐量提高5.01%。

表2 FastDFS和FastDFS-Redis-Mysql的 小文件读取吞吐量统计
3 结束语
基于人脸识别平台,提出一种存储和索引的优化方法。首先将相同目录下的小文件通过聚合模块合并成大文件进行写操作,同时建立内部小文件索引;然后客户端结合大文件传入到FastDFS生成的文件索引和局部索引建立全文索引;最后Redis根据文件名和全文索引来存储15天的数据文件的文件名和对应的大索引,Mysql持久化存储以往所有的数据文件,同时采取预读取机制提前读取相邻的数据文件。
猜你喜欢
电脑爱好者(2019年9期)2019-10-30 03:43:29
电脑爱好者(2019年13期)2019-10-30 03:36:29
网络安全和信息化(2018年9期)2018-03-03 18:11:15
信息安全研究(2018年1期)2018-02-07 01:44:46
网络安全和信息化(2017年12期)2017-11-08 10:39:14
软件导刊(2016年9期)2016-11-07 21:35:42
通信电源技术(2016年5期)2016-03-22 01:09:49
石油知识(2016年2期)2016-02-28 16:20:16
自动化仪表(2015年11期)2015-04-01 01:02:40
电脑迷(2014年8期)2014-04-29 07:37:40
