
混合协同过滤算法在推荐系统中的应用
2019-03-21 11:35:34沈鹏,李涛
计算机技术与发展 2019年3期
沈 鹏,李 涛
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引 言
推荐系统是向用户推荐或建议适当的事物的机器软件。推荐系统主要由三个重要阶段组成,分别是目标数据收集,相似性判定和预测计算[1]。另外,市场上的推荐系统[2]主要基于三大方法[3]。基于内容[4]的方法充分利用物品的甚至是用户的内容(属性)。而文中方法使用了题材和标签。因此,使用这种方法可以发现一部电影的内容与用户喜欢的其他电影的内容之间的相似性[5]。为了预测目标用户的偏好,协同过滤也考虑了目标用户的近邻,用来发现邻居和目标用户之间的相似性,以便选择最相似的邻居并且将他们的评分和偏好推荐给目标用户[6]。因此,用户的偏好推荐将取决于在活跃用户的邻居中存在的其他用户。此外,协同过滤的领域依赖特性可能使其易受稀疏性和冷启动的影响。这种类型的推荐系统可以分为基于记忆的,基于模型的[7]以及两者的混合[8]。由于协同过滤在很大程度上取决于用户的评分,因此,如果域中的用户数量与事物相对比较低,则可能导致冷启动[9]。文中提出的混合方法是基于内容属性和协同过滤算法的[10]。在后面的章节中,将讨论混合协同过滤算法如何优于纯协同过滤算法[11]和基于内容属性的算法[12]。
1 相关工作
梅尔维尔等提出过一种内容提升的混合协同过滤算法,将内容和协同过滤算法结合起来提供推荐。用户-事物评分矩阵的稀疏度为97.4%,伪评级矩阵是使用了借鉴用户画像的基于内容的过滤算法计算出来的。内容提升的混合协同过滤算法中使用的朴素贝叶斯文本分类器对不同电影的内容进行比较和分类,并通过协同过滤方式生成的伪评分矩阵进行预测。对于两部电影之间的相似性,作者使用了Pearson相关性[13]进行度量。而文中方法修改了基于内容的算法部分,使用了一个简单的比较器,而不是根据朴素贝叶斯进行文本匹配,它可以比较和匹配在Movielens数据集上测试的两部电影的标签和题材,并与SVD和纯CF进行比较。此外还确定,与以前的模型相比,用户项目评分矩阵中的初始稀疏度较高。
2 数据集描述
为了测试修改后的混合内容推荐方法,使用了推荐系统的标配实验数据─Movielens数据集[14]。数据集中包含用户为特定电影提供的个人评级。该数据集中总共包含100 004个评分,这些评分由671个用户给出,针对9 125部电影,评分范围从0到5。电影的题材总数为20。用户和电影组成了671*9 125的用户-事物评分矩阵,其中行表示用户,列表示电影。Movielens数据集包含以下属性:userId,movieId,标题,评分,标签和题材。紧接着数据集被过滤,用文中算法对稀疏度为98.36%的用户评分矩阵进行了测试。数据集中最初提供的评分数量为100 004。在这些评分中,将2 000个评分分开,用于之后测试文中算法的准确性。分离这些评级后,留下了训练数据集,构成了98 004个评分,其稀疏度为98.3%。现对于进一步的读数设置,从稀疏度增加的方向随机删除训练数据集中一定比例的评分,并用对预测评分进行测试。通过这种方式,总共采集了六次读数,其中的稀疏度从98.3%到99.8%不等。
3 提出的方法
文中提出的算法考虑了数据集中指定的标签和题材,并且对基于内容的预测,应用了一组匹配比较器。该比较器返回两部电影之间公共属性的数量。这里的属性一词是指标签和题材。对于每部特定的电影,标签和题材都合并到一个集合中。这给了每部电影庞大的内容,而更多的内容则可以产生更好的预测。获取一组通用属性后,计算每部电影的权重。
一旦将权重分配给每个组,则它们将被用于使用先前比较的额定电影来提供未评级电影的评级。首先在该方法中,分配给用户的每部电影所打上的标签都要使用,并且将其转换为单个列表。每部电影的题材都附加到相同的标签列表中。该最终列表被称为特定电影的属性。将为每部有效影片设置的属性与数据集中每部其他影片的属性集进行比较,并将成功匹配的对象分配到一组。该组的长度用于预测评分,预测的公式如下所示:
R=M*(Hr/M')
其中,R为有效电影的评分;M为普通对象的数量;M'为数据集中任意两部电影之间匹配对象的最大数量;Hr(highest_rating)为可以分配给一部电影的最大评分,在该例中是5。如果评级大于2.5(阈值等于最低和最高评级的平均值),那么可以将该电影及其计算的评级分配给相似的一部有效电影的电影集。接下来,使用数据集构建用户评分矩阵。这个矩阵的稀疏度为98.36%。使用形成的相似电影列表,减少了用户评分矩阵的稀疏性。对于用户评分矩阵中的每个非零条目,使用上述步骤中形成的列表找到与其类似的影片。一旦来自用户评分矩阵的稀疏性降低,就使用Pearson相关性来应用CF,并据此为用户生成最终的预测。
算法流程见图1。
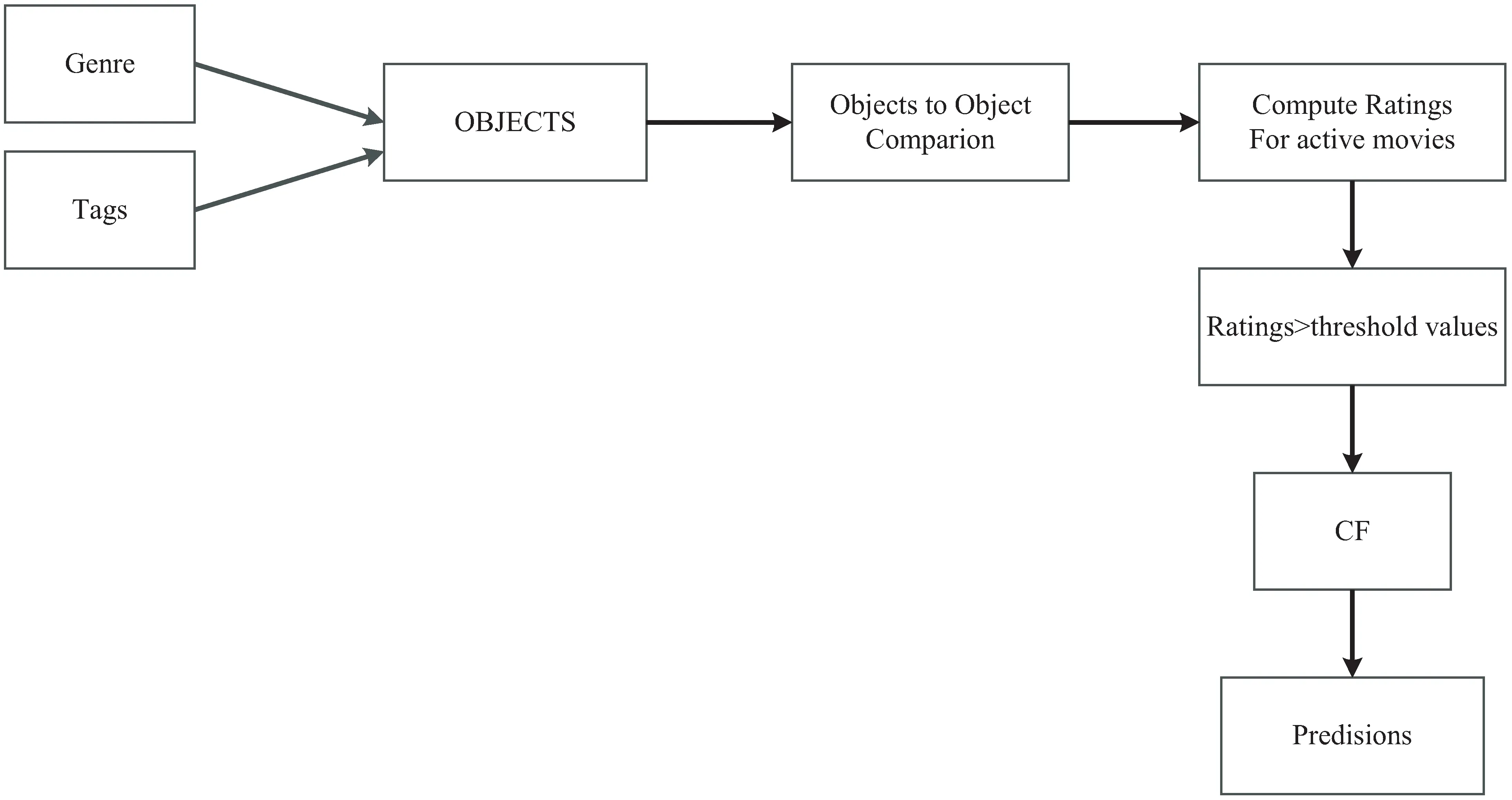
图1 改进的电影推荐混合协同过滤算法流程
4 评 估
在评估提出方法时,采用两种传统推荐方法作比较,即Pure CF和SVD。用这两种方法在相同的Movielens数据集但不同的稀疏度上进行测试。此外,选择这两种方法进行评估和测试的原因在于,此前提出的内容提升的CF[10]的方法也是与这两种方法进行了比较。由于文中算法是为了比较梅尔维尔等所做的改进而设计的[10],因此,采用了前者在其工作中使用的相同评估方法进行测试。另外,凭借这种评估,可以清楚地看到提出的方法的结果和功效的差异。该模型使用平均绝对误差(MAE)进行评估。平均绝对误差是一个强大的评估模型,它是平均误差的更自然的度量。此外,维度评估和相互比较模型应该使用MAE作为评估指标[12],它是预测值与实际值的偏差。为了计算MAE,考虑了预测评分和实际评分。MAE值是在用户-事物矩阵的稀疏度级别不同上计算的,并针对所有三种算法分别进行了计算。此外,这里用于测试和评估的数据集要优于第二节提到的类似方法中使用的数据集。尽管用户总数较少,但是电影数量掩盖了这一事实,并且由于电影数量更多,因此允许算法在更稀疏的用户评分矩阵上运行,因此在下一节中提供的结果是合理的。
5 结 果
与Pure CF和SVD的方法进行比较的结果如表1所示。
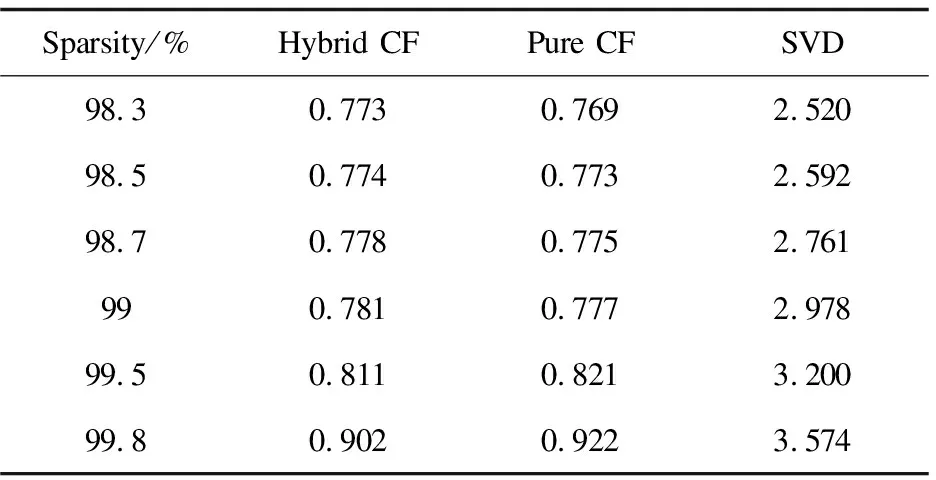
表1 混合CF、纯CF和SVD的MAE值
与Pure CF相比,发现文中方法对高稀疏度的有效性比Pure CF更好,MAE值比Pure CF产生的要稍高。原因是Pure CF算法取决于用户评分矩阵可用的数据,在高度稀缺的情况下,可用数据较少,因此Pure CF的性能表现不佳。另一方面,文中方法的主要兴趣领域是通过应用物-物比较来减少稀疏水平,因此,在这种情况下基于内容的过滤之后使用的CF比纯CF在更高的稀疏性的情况下使用效果更好。在图2中可以看出,在稀疏水平为98.5%左右时,Pure CF和文中方法结果几乎没有差异,但在稀疏性进一步增加到99%左右的情况下,用Pure CF产生的结果的差异增加。如图3所示,当文中方法与SVD进行比较时,在稀疏度水平介于98%到100%的情况下,发现改进的混合CF推荐算法表现的比SVD更有效。从表1可以清楚地看出,在98.3%的稀疏度时,MAE是2.520,随着稀疏度的增加,MAE值也随之增加,两种算法的MAE值的差异是巨大的。由于数据稀疏性较低,SVD无法有效执行。表2显示了提出的方法是如何成功地降低了给定用户-事物评分矩阵的稀疏性的。
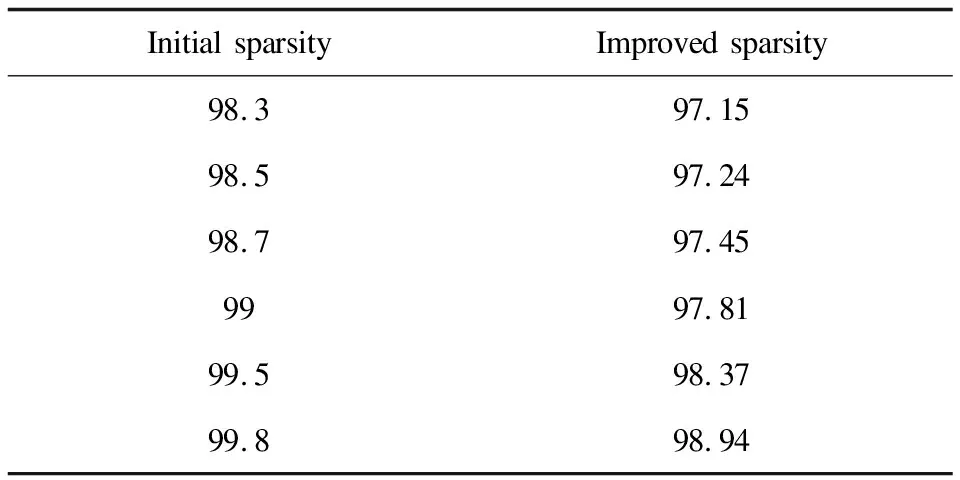
表2 应用混合CF之后改善的稀疏性 %

图2 Hybrid CF和Pure CF的MAE值与稀疏性的比较
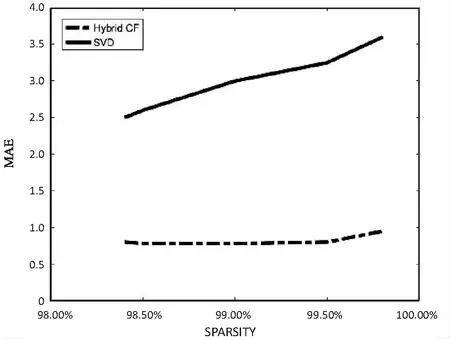
图3 混合CF和SVD的MAE值与稀疏性增加的比较
6 结束语
文中方法是一种新颖的替代方法,描述了一种可以在基于内容的过滤中使用集合交集来找到两个特征之间的相关性的简单方法,该方法可以找出两个事物
之间的相似性并使用CF预测它们的推荐。以前相关的方法在基于内容的算法中使用了朴素贝叶斯等文本分类器,而文中算法进一步测试并与Pure CF和SVD进行了比较。评估后生成的MAE值提供了成功的比较。虽然混合内容推荐可产生更好的MAE值,并将数据集的稀疏性提高了1%~2%,但使用较大的数据集进行测试时,结果可能会有所不同。
猜你喜欢
现代装饰(2022年5期)2022-10-13 08:47:36
科学大众(2020年23期)2021-01-18 03:09:08
数学小灵通(1-2年级)(2020年4期)2020-06-24 05:47:08
汽车观察(2019年2期)2019-03-15 06:00:50
作文周刊·小学一年级版(2016年23期)2017-06-05 23:27:03
中国卫生(2016年5期)2016-11-12 13:25:26
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
南都周刊(2015年1期)2015-09-10 07:22:44
