
5G网络切片中的虚拟网络功能管理器映射算法
2019-03-21 11:35:32徐一凡孟旭东
计算机技术与发展 2019年3期
徐一凡,孟旭东
(1.南京邮电大学,江苏 南京 210003;2.江苏省电信网络融合实验室,江苏 南京 210003)
1 概 述
5G网络中通过虚拟化将一个物理网络分成多个切片网络来应对不同的应用场景[1]。网络切片是一组虚拟网络功能(virtualized network function,VNF)及其资源组成的一个完整的逻辑网络[2]。5G中使用NFV的管理和编排(management and orchestration,MANO)模块来实现切片的部署和管理。
在欧洲电信标准协会(European telecommunication standards institute,ETSI)定义的NFV架构框架中,包括VNF,网络功能虚拟化基础设施(network function virtualization infrastructure,NFVI)和MANO框架[3]。VNF是网络功能的软件实现,NFVI是VNF部署的环境,是硬件和软件资源的组合,可以跨越分散的地理位置,其节点称为NFVI存在点(NFVI-PoP)。
NFV MANO框架能够在满足运营商要求(例如性能和可靠性)的同时,实现资源,VNF和网络服务(network service,NS)的自动化管理[4]。它包含三个功能块:虚拟化基础设施管理器(virtualized infrastructure manager,VIM),VNFM和NFVO。MANO模块通过一组已定义好的参考点与NFV架构框架中的其他功能模块进行通信[5]。
在MANO中,VIM负责对整个NFVI资源的管理和监控,例如管理配置硬件资源和虚拟化资源,收集和报告资源故障和性能信息等。VNFM负责VNF的生命周期管理,包括VNF的实例化,VNF容量的缩放,VNF更新和改进,VNF的终结(释放VNF占用的NFVI资源)。NFVO负责在操作域内NS的管理和相应策略的制定,并且通过与VNFM的协作确保VNF实例满足性能与可靠性要求[6]。
鉴于MANO功能模块所涵盖的角色,它在物理网络中的部署位置对切片的性能有重要影响。因为MANO功能块之间通过广域网(wide area network,WAN)链路进行通信,所以在实际的切片网络中,延迟是难以避免的。这些延迟因地点不同而有所不同,并随着网络流量的改变而改变[7]。MANO的管理功能无法承受高延迟,例如,延迟会阻止频繁收集和分析来自VNF实例和VIM的监控数据[8]。另外,对于VNF故障管理来说,需要快速的故障通知和恢复,以尽量减少故障的影响并保持切片中网络服务的可靠性[9]。所以说降低延迟对于整个切片的管理的影响非常重要。
另外,MANO模块的部署位置也会影响整个切片的运营成本,当系统中有很多的VNFM时这一点尤为明显。实际上,资源成本(包括计算和带宽资源成本)因网络运营商的不同,地点和时间的不同而有所差异,并且网络流量在系统中动态变化[10]。因此,相应地调整VNFM的数量和位置可以为切片的运营节约大量的成本。所以MANO功能块的映射确实是一个需要解决的重要问题。
因为VIM的部署问题是NFVI设计的一部分,所以暂且不考虑。另外,忽略NFVO以缩小问题的范围。所以文中主要讨论的是切片系统中VNFM的位置映射问题。VNFM的位置问题可以映射到虚拟网络映射问题(virtual network embedding,VNE)来解决[11]。VNE问题是NP-Hard问题,目前在研究中是通过启发式的算法(例如遗传算法)来解决这个问题[12-13]。
文中旨在找到VNFM的最佳数量和位置,以在每个时刻都可以在延迟和性能限制下最大限度地降低运营成本。文中的主要贡献包括:
(1)建立了VNFM映射(VNFM embedding,VNFME)数学模型。主要侧重于动态VNFME(即随着映射策略随着时间的推移而变化)的研究,并提出了此问题的ILP公式。
(2)提出了一种基于禁忌搜索的映射算法来解决VFNME问题。禁忌搜索是一种使用自适应内存的高效邻域搜索方法。根据该问题的特殊性,详细设计了算法步骤。
2 VNFM映射模型
2.1 问题描述
5G网络切片通过网络资源与部署位置解耦、切片内资源动态伸缩调整,不仅可以提高5G网络服务的灵活性和资源利用率,而且降低了5G网络的部署与运营成本[14]。也就是说,在切片中,网络服务和VNF可以在保证效率成本的同时,随时随地按需实例化,并进行弹性的容量缩放以满足不断变化的网络需求。因此,切片中VNF实例的数量、类型(如防火墙)和位置可能随时间变化。而对于VNFM来说,在任何时候,它的数量都应该适应部署在系统中的VNF实例,并保证其管理功能的可靠性,以实现切片系统的最佳性能。
由于VNF实例部署在跨地理分布的NFVI-PoP上,因此NFVI-PoP网络成为影响切片性能和运营成本的重要因素。如图1,VNFM通过Ve-Vnfm-vnf,Ve-Vnfm-em,Vi-Vnfm和Or-Vnfm等参考点与VNF实例,网元管理器(element manager,EM),VIM和NFVO交互。另一方面,实际中VNFM与这些功能块之间通过WAN链路进行通信,故VNFM在切片中的映射在确定各个参考点的延迟方面起着至关重要的作用。因此,计划外的VNFM位置会导致计划外的延迟,从而对系统的性能和可靠性产生负面影响。为了保证性能,每个参考点可以受到延迟限制的约束。
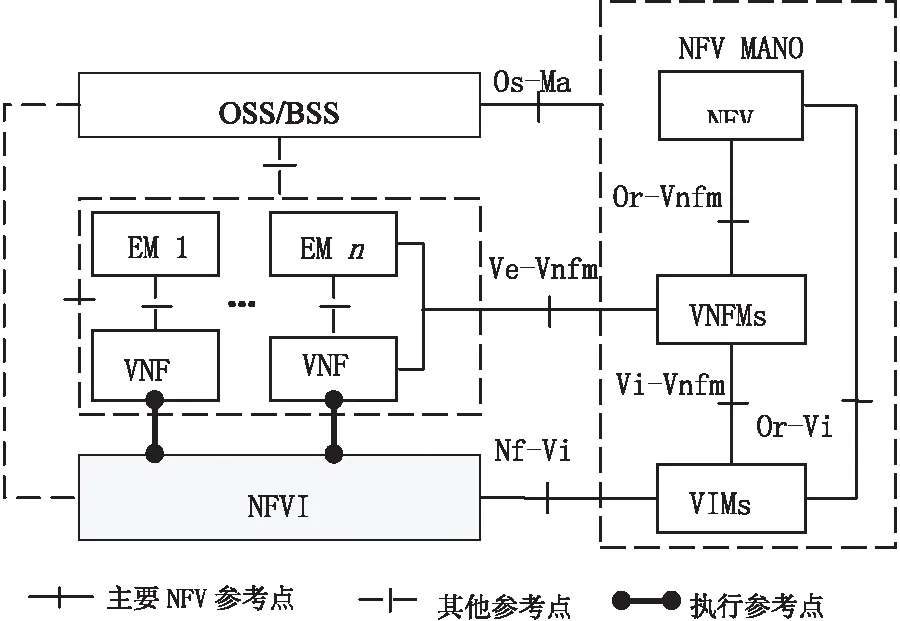
图1 ETSI NFV框架架构
因此,VNFM的位置和数量对整个切片的性能以及成本至关重要。文中将相关问题称为VNFM映射(VNFME)问题。VNFME问题具体定义如下:给定VNF实例的位置和NFVO的位置,目标是找到:(1)管理VNF实例所需的最佳VNFM数量;(2)VNFM的类型(例如通用VNFM,用于管理来自特定VNF的VNFM等);(3)VNFM在NFVI-PoP上的最佳位置。文中旨在满足切片系统中的通信延迟和容量限制(VNFM的容量限制)的同时,以最低的运营成本实现此目标。
VNFME分为静态和动态。在静态VNME中,映射和与VNF实例的关联是永久性的,不会随着时间而改变,这适用于系统中的更改(例如VNF实例数量)对于重新调整VNFM放置无关紧要的情况。但是,在实际的切片系统中,由于资源变化情况复杂,静态的映射策略并不能很好地适应这些变化,常常导致VNFM的数量和位置的错误配置。相比之下,动态VNFME旨在使VNFM数量和映射更好地适应变化。
2.2 系统模型
模型通过一组快照进行操作,定义一个快照t作为固定时间间隔内系统状态的表示。系统状态(如VNF实例的数量,系统中的延迟)可能因快照而异。因此,当系统从一个快照转移到下一个时,该模型考虑四种机制来适应系统以响应变化:添加新的VNFM以应付VNF实例的增加;删除现有的VNFM降低成本;将现有的VNFM迁移到新的位置;将VNF实例重新分配给另一个VNFM。
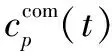
假设NFVO部署在给定的NFVI-PoP上。用hp∈{0,1}表示它的位置,如果NFVO被放置在p∈P,则hp等于1,否则等于0。
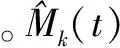
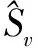

2.3 问题表述
将VNFME制定为ILP问题,目标是根据单个快照制定映射策略,以最小化切片的运营成本。对于静态VNFME,只在一个快照t上操作,代表系统的永久状态,从系统的永久配置中推导公式。而对于动态VNFME,是对系统中的每对连续快照t-1和t进行操作。更确切地说,给定快照t-1和t,在快照t-1结束时,决定VNFM的位置以及它们与VNF实例v在快照t上关联。所有在M(t)中的VNFM的放置决定允许是否添加新的VNFM,以及保留,删除或迁移现有的VNFM。Mk(t)定义如下:
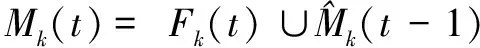
(1)
其中,Fk(t)是一系列可以被添加到系统中的快照t上类型为k的新VNFM的集合,比如:
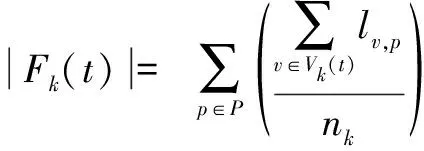
(2)
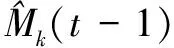
运营成本的定义分为四个不同的部分,定义如下:
生命周期管理成本(Clif(t)):表示快照t上系统执行所有VNF实例的生命周期管理所消耗的网络通信带宽的成本:
(3)
其中
计算资源成本(Ccom(t)):表示在快照t上分配给VNFM的计算资源成本:
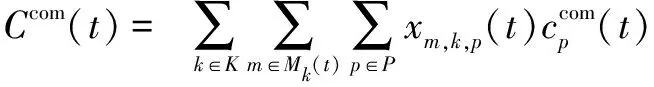
(4)
在此假设VNFM需要单个计算资源单元。这个假设是由于缺乏关于MANO功能模块的资源分配的可用数据。
迁移成本(Cmig(t)):表示在从快照t-1转换到快照t的同时,将VNFM从一个NFVI-PoP迁移到另一个NFVI-PoP时所隐含的成本。
(5)
重新分配成本(Crea(t)):当从快照t-1转换到快照t时,系统中剩余的VNF实例可能会重新分配给新的VNFM。按如下方式计算重新分配这些VNF实例的成本:
(6)
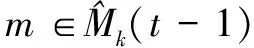
最后,优化问题的目标是最小化以上四个成本的加权和,表示如下:
MinClif(t)+Ccom(t)+Crea(t)+Cmig(t)
(7)
在静态情况下,式7不包括Crea(t)和Cmig(t)。
约束条件如下:
(a)每个VNF实例应该分配给一个VNFM,如式8所示:
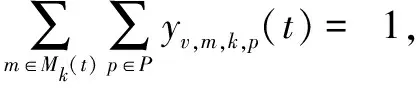
(8)
(b)VNF实例分配给处于同一个NFVI-PoP上的VNFM,如式9所示:
yv,m,k,p(t)≤xm,k,p(t),
∀k∈K,v∈Vk(t),m∈Mk(t),p∈P
(9)
(c)确保分配给每个VNFM的VNF实例数量不超过其容量,如式10所示:
∀k∈K,v∈Vk(t),m∈Mk(t),p∈P
(10)
(d)VNFM只能位于一个NFVI-PoP。这个约束由式11定义:
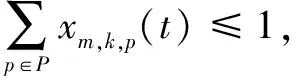
(11)
(e)确保VNFM仅在管理至少一个VNF实例时处于活动状态,如式12所示:
∀k∈K,v∈Vk(t),m∈Mk(t),p∈P
(12)
(f)每个VNF实例有两个延迟限制来控制其分配的VNFM的参考点上的延迟。通过式13和式14来执行这些约束:
(yv,m,k,p(t)lv,q+yv,m,k,p(t)lv,p)δp,q(t)≤φv(t),
∀k∈K,v∈Vk(t),m∈Mk(t),(p,q)∈E
(13)
(yv,m,k,p(t)hq+yv,m,k,p(t)hp)δp,q(t)≤ωv(t),
∀k∈K,v∈Vk(t),m∈Mk(t),(p,q)∈E
(14)
(g)式15保证每条边上的使用带宽不超过其容量:
Blif(p,q)+Blif(q,p)+Bmig(p,q)+Bmig(q,p)+
Brea(p,q)+Brea(q,p)≤γp,q(t),
∀(p,q)∈E
(15)
其中
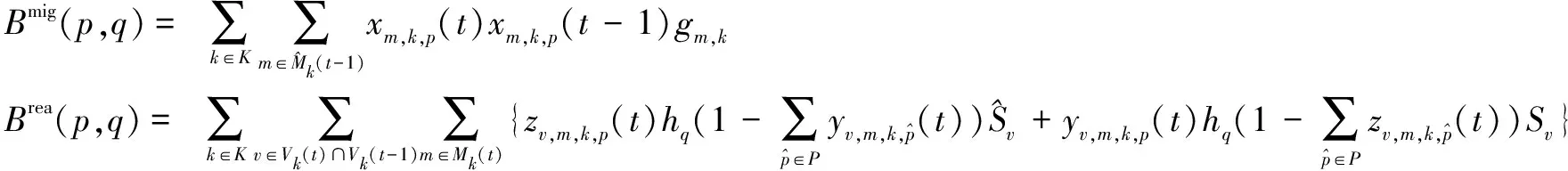
在静态情况下,式15不包括Brea(t)和Bmig(t)。
3 算法描述
禁忌搜索是一种元启发式算法,用于指导局部搜索过程以找到组合优化问题的近似最优解。它从初始解开始探索搜索空间,并迭代地执行移动以从当前解决方案转移到其邻域中的另一个解决方案,直到满足终止标准[15]。文中设计的算法步骤如图2所示。

图2 基于禁忌搜索的VNFM映射算法伪代码
3.1 初始映射策略
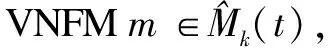

3.2 邻域移动
文中的禁忌搜索算法采用四种移动类型来生成邻域解,定义如下:
VNF重新分配:随机选择一个VNF实例将其重新分配给另一个VNFM。新的VNFM可能处于活动状态或不活动状态。如果是不活动的,则VNFM被激活。如果旧VNFM不再有与其关联的VNF实例,则停用。
VNFM重新定位:随机选择活动的VNFM并移动到另一个NFVI-PoP。选择新的位置,以便不违反所有分配的VNF实例的延迟限制。
批量VNF重新分配:随机抽取活跃的VNFM。然后,如果剩余的活动VNFM具有足够的容量来管理其分配的VNF实例,同时满足它们的延迟约束,则重新分配VNF实例,并且停用所选VNFM。

3.3 禁忌列表和渴望水平条件
禁忌搜索使用称为禁忌表的内存结构来记录有关最近搜索历史的信息,这可以避免局部最优化,并防止对先前得到的最优解的重复访问。在后面的迭代中,如果移动已经存在于禁忌表中则被禁止。此外,如果禁忌表中的移动达到渴望水平条件,则被解禁并可以重新选择。
3.4 评价函数
在每次迭代中,禁忌搜索算法评估一组候选移动并选择生成最优邻域解的移动。该算法使用分层目标函数(f)来评估邻域解,其中主要目标首先被最小化,然后对于相同的主要目标值,次要目标被最小化。主要目标被定义为由模型目标函数和与解相关的总惩罚之和。次要目标是活动的VNFM与其相关的VNF实例之间的延迟总和。最终目标是最大化Pm(t)对于所有活动的VNFM,然后检测并消除重叠覆盖。
3.5 终止准则

4 仿真实验与分析
4.1 仿真环境
仿真实验使用配置为12 GB内存,64位Win10操作系统,Intel Core i5处理器的计算机进行评估,使用MATLAB进行编程,实验中的物理网络及虚拟网络拓扑都采用GT-ITM生成。
预设参数信息如下:

表1 仿真参数
4.2 结果分析
文中将从成本和VNFM数量这两个方面对基于禁忌搜索的VNFM映射算法的性能进行评估。为了更加直观地了解此算法的性能,将使用此算法获得的结果与基于贪婪算法获取的初始结果和基于遗传算法的映射算法取得的结果进行比较。图3为三种算法在不同的VNF实例数量的情况下,其最优映射策略下切片运营总成本的对比。可以看出,提出的基于禁忌搜索的VNFM映射算法总能在初始解的基础上产生更优的解,一定程度上降低了切片的运营成本,验证了该算法的有效性。同时可以看出这些解与基于遗传算法产生的解相比基本一致,有时甚至更加优秀。

图3 三种算法总成本对比

图4 C1和C2不同比例对所需VNFM数量的影响
图4描述的是VNF实例的数量和C1,C2在VNF总量中所占不同比重对切片系统中所需的VNFM数量的影响。可以看出,随着VNF数量的增加,VNFM容量有限,所以VNFM数量必然也需要增加以管理更多的VNF,但是随着C1类型的VNF所占比重的增加,系统所需VNFM的数量更多,并且其增长速率也更高。这是因为C1类型的VNF的性能和延迟要求较高,所以对管理它的VNFM的性能要求也就相应的高。要想保证切片系统的性能,系统只能使用相匹配的高性能的专用VNFM来管理,或者减少通用型VNFM的容量来保证其管理性能的可靠性,所以相比于性能要求不高的C2类型的VNF,C1类型的VNF需要更多的VNFM来管理。
图5为不同快照中随着系统中VNF实例数量的变化,动态VNFME与静态VNFME产生的切片运营总成本对比。可以看出,动态VNFME产生的成本要低于静态情况,并且随着VNF数量的变化,动态VNFM下成本的变化相对应较为平缓。而静态的VNFME显然无法很好地适应切片系统状态的变化,并且成本也更高。
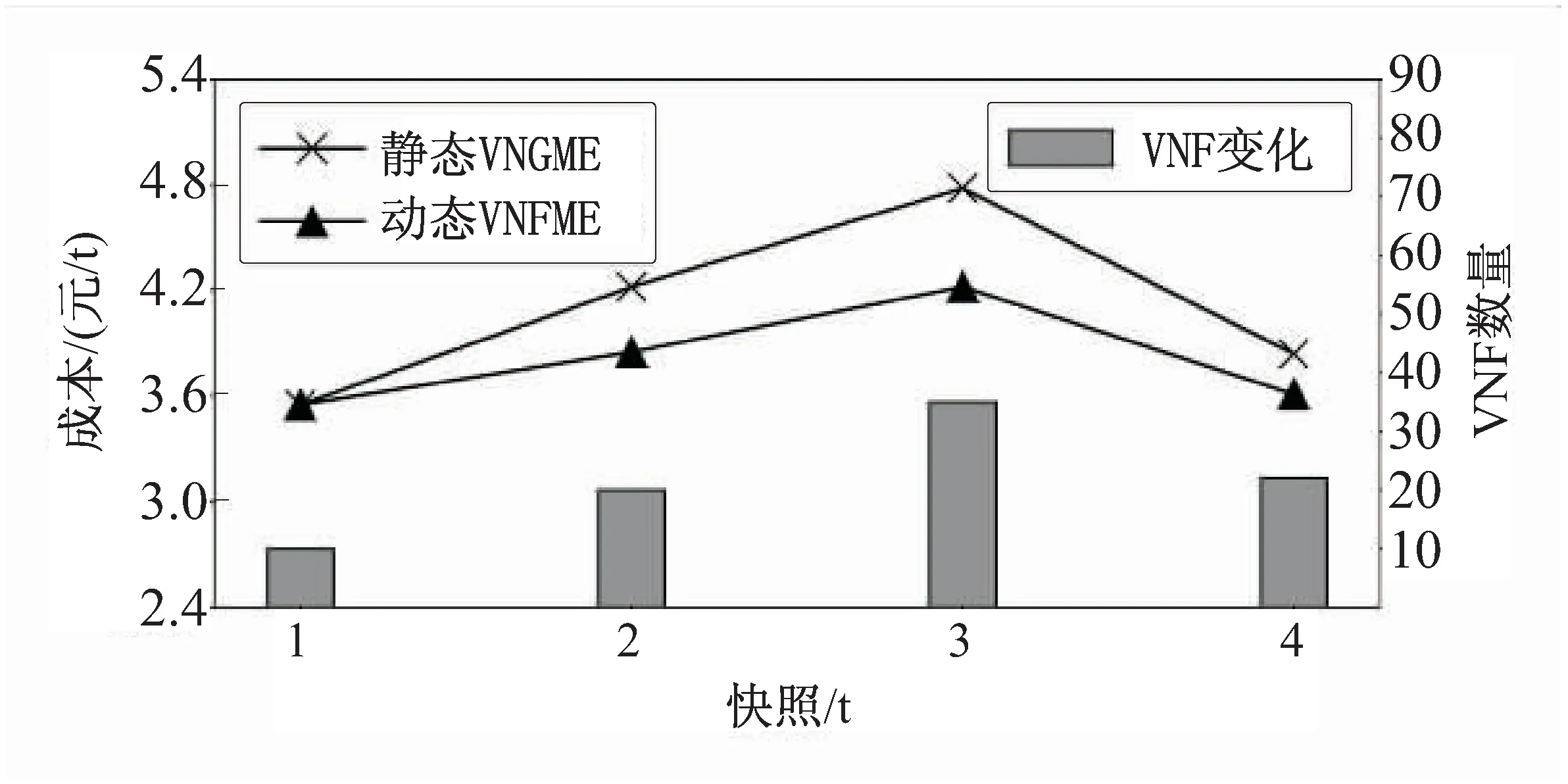
图5 动态VNFME与静态VNFME总成本对比
5 结束语
介绍并研究了5G网络切片中的VNFME问题。通过分析实际网络切片系统中的延迟与成本因素,建立了问题的整数线性规划最优化模型,并提出了禁忌搜索算法来获得最优的映射策略。实验结果表明,禁忌搜索算法总能得到使切片运营成本最小的映射策略。并且在动态VNFME中,相对于静态VNFME,该算法可以使策略适应系统中的变化,从而使切片运营成本显著降低。
猜你喜欢
天津科技(2022年5期)2022-05-31 02:18:08
网络安全和信息化(2017年3期)2017-03-10 07:45:51
电信科学(2016年11期)2016-11-23 05:07:58
中国组织化学与细胞化学杂志(2016年3期)2016-02-27 11:15:40
网络安全和信息化(2015年11期)2015-03-17 21:54:44
中国当代医药(2015年17期)2015-03-01 02:03:38
发明与创新(2015年21期)2015-02-27 10:39:11
高中生学习·高三版(2014年3期)2014-04-29 06:11:18
高中生学习·高三版(2014年3期)2014-04-29 06:10:49
河北医科大学学报(2010年10期)2010-03-25 10:15:06
