
机器学习算法在预测男男性行为人群中HIV感染的应用*
2019-03-18 03:31天津医科大学公共卫生学院流行病与卫生统计学系300070
中国卫生统计 2019年1期
天津医科大学公共卫生学院流行病与卫生统计学系(300070)
郭长满 郭 敏 刘媛媛 李长平 崔 壮△ 马 骏
男男性行为人群(men who have sex with men,MSM)是感染HIV、性病风险最高的人群之一,也是感染人数增长较快的人群[1],在最新确认的HIV感染者中,MSM所占比例稳步增长,甚至一度达到了新确诊的22.8%[2]。当前的研究已经表明高危性行为,如多性伴、群交、使用物质(助性剂)以及无保护性交均为HIV感染的高危因素[3]。针对具有这些高危因素的人群采取必要的预防保护措施可以有效地减少HIV在该人群中的传播,提高该人群的健康水平,尽管当前已经有大量的检测措施可以早期发现和治疗HIV感染者,但是每年仍然有大量未被发现的新增HIV感染者,并且有一部分人群仍在接受不必要的预防服务,从而造成医疗资源的浪费,因此,开发一种准确而有效的识别早期HIV感染者的方法,具有重要的现实意义。
已有的模型如logistic回归分析和Poisson回归分析已经在男男性行为人群中的HIV感染广泛应用,然而这些模型在男男性行为人群中的分类和预测性能却少有研究,机器学习算法的发展为评估该高危人群的特征提供了一种新的思路。
机器学习又称为人工智能,即通过计算机网络处理各个变量间的复杂和非线性关系并使误差最小化的方法[4]。目前广泛应用的机器学习算法包括神经网络、随机森林和支持向量机,这些算法已经广泛应用于工程学、建筑学等领域,却很少有研究将这些算法应用于男男性行为人群,为了更好地评估这些算法是否能提高预测HIV感染的精确度,以及寻找具有最好分类效能的分类算法,本研究比较了四种算法的分类效能。
原理与方法
1.logistic回归的原理
logistic回归分析在医学研究中应用广泛。目前主要是用于流行病学研究中危险因素的筛选,但它同时具有良好的判别和预测功能,尤其是在资料类型不能满足Fisher判别和Bayes判别的条件时,更显示出logistic回归判别的优势和效能[5]。
2.BP神经网络的原理
BP神经网络是一种有监督的前馈运行的神经网络,它由输入层、隐含层、输出层以及各层之间的节点的连接权所组成,这个学习过程的算法由信息的正向传播和误差的反向传播构成,在正向传播过程中,输入信息从输入层经隐含层逐层处理,并传向输出层,每一层神经元只影响下一层神经元的输出,信息完成正向的传播后,如果在输出层不能得到期望的输出,那么误差将进入反向传播,运用链导数法则将连接权关于误差函数的导数沿原来的连接通路返回,通过修改各层的权值使得误差函数减小[6]。
3.随机森林的原理
随机森林由Leo Breiman(2001)提出,它通过自助法(bootstrap)重采样技术,从原始训练样本集N中有放回地重复随机抽取n个样本生成新的训练自助样本集合,然后根据自助样本集生成n个分类树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定[7]。
4.支持向量机的原理
支持向量机通过结构风险最小化原理来提高泛化能力,它较好地解决了小样本、非线性、高维数、局部极小点等实际问题。其主要思想:首先选择一非线性映射把n维样本从原空间映射到特征空间,在此高维特征空间中构造最优线性决策函数。在构造最优决策函数时,利用了结构风险最小化原则,同时引入了间隔的概念。并巧妙地利用原空间的核函数取代了高维特征空间的点积运算,避免了复杂计算[8]。
5.算法的比较
本研究纳入了四种常用的数据分类算法,即logistic回归、神经网络、随机森林和支持向量机,比较这四种分类算法基于已有的变量信息对目标人群是否感染HIV进行分类。为了比较四种分类算法的分类效果,将数据集分为训练集和测试集,训练集用于对分类算法进行训练,测试集用于对训练的结果进行比较和总结。原数据集分别经过10次、50次和100次有放回bootstrap重抽样[9],从而产生10个、50个和100个与原数据集大小相同的子样本集,基于bootstrap重抽样的特性,每次抽样时原数据集中总会有约37%的样本不被抽到,用这部分不被抽到的样本集来分别作为测试集,新产生的子样本集来分别作为训练集,基于每种分类算法的分类结果进行综合评价。
6.统计学方法
分类器的分类性能采用测试集的分类结果来进行评价,分类效果的评价采用C统计量来进行[10],即曲线下面积(AUC),及其95%置信区间,用实验室检测得到的样本人群HIV感染情况作为金标准,而每个分类器每次采用验证集分类的结果和金标准进行比较从而可以得到灵敏度、特异度、精确度和相应的曲线下面积。关于神经网络、支持向量机和随机森林最优参数的选取基于3折交叉验证的方法,最优模型的选取依据分类模型的曲线下面积,选择具有最大曲线下面积时所对应的参数。其中,神经网络的隐藏层神经元个数范围为(0,10),支持向量机选择的核函数为径向基核函数,对于cost设置参数选择范围为(2-5,20,215),gamma的范围为(2-15,20,23),随机森林中节点数范围为(3,4,5),决策树的个数为范围为(100,200,500),从中选择最佳的参数来进行建模和预测。Nnet包被用来实现神经网络算法,randomForest包用来实现随机森林算法,e1071包用来实现支持向量机算法,rminer包用于模型调参。所有的统计分析均运用R语言实现的。
结 果
1.研究人群和研究变量
本次研究的资料来源于天津市某男性同性恋志愿组织调查收集的关于男男性行为人群的资料和体检信息,入选标准:①年龄≥18周岁;②在天津市居住≥6个月;③在过去六个月曾发生过至少一次商业男男性行为。对数据进行核查、清洗,排除不符合入选标准,数据大量缺失以及有逻辑错误的样本。最终纳入研究的目标人群有3086人。对研究变量与HIV的关系进行单因素分析,筛选出结果有意义的,以及文献研究显示可能有影响的变量。该目标人群HIV感染率为8.39%。最终研究中用到的变量如表1所示。

表1 研究中纳入的变量
2.分类算法在训练集上的表现
表2显示了经过10次、50次和100次重抽样后,计算四种分类算法在训练集里的指标及其95%CI,结果支持向量机在灵敏度、特异度、准确度(PRE)以及曲线下面积(AUC)上表现最好。
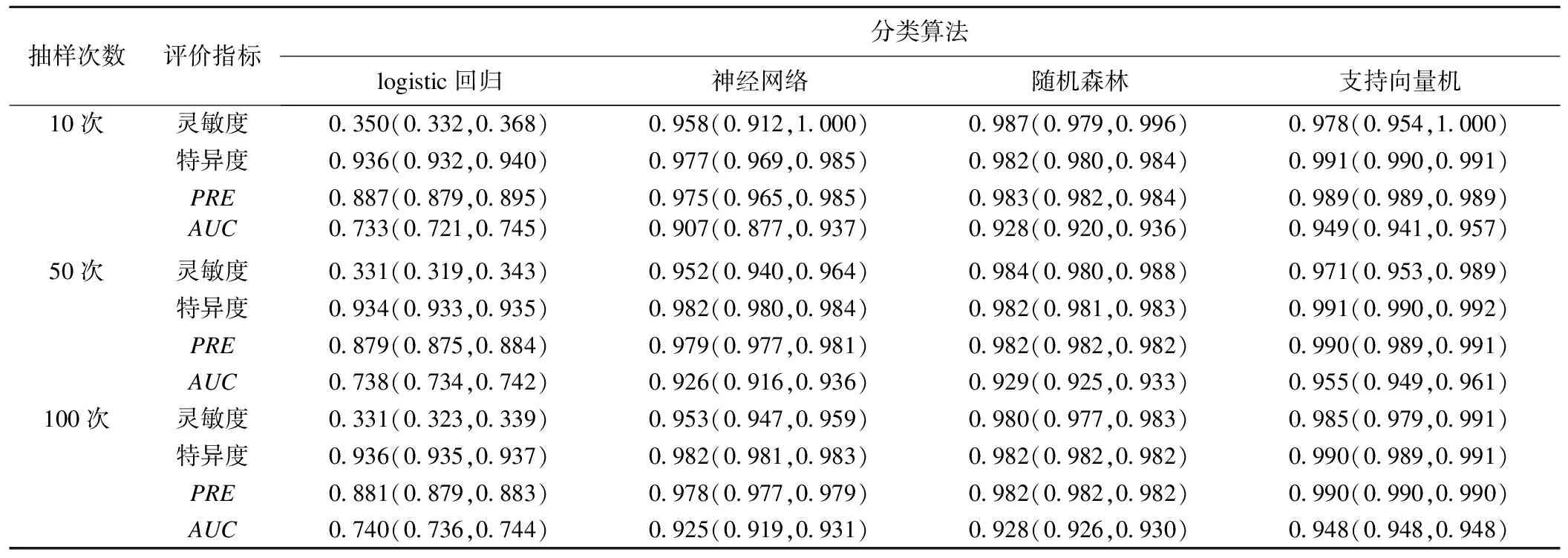
表2 四种分类算法在训练集上的分类效能
3.分类算法在测试集上的表现
表3显示了经过10次、50次和100次重抽样后四种分类算法在测试集上的效能指标及其95%CI,结果显示随机森林的灵敏度最高(97.6%),支持向量机在特异度,准确度(PRE)以及曲线下面积(AUC)上表现最好。
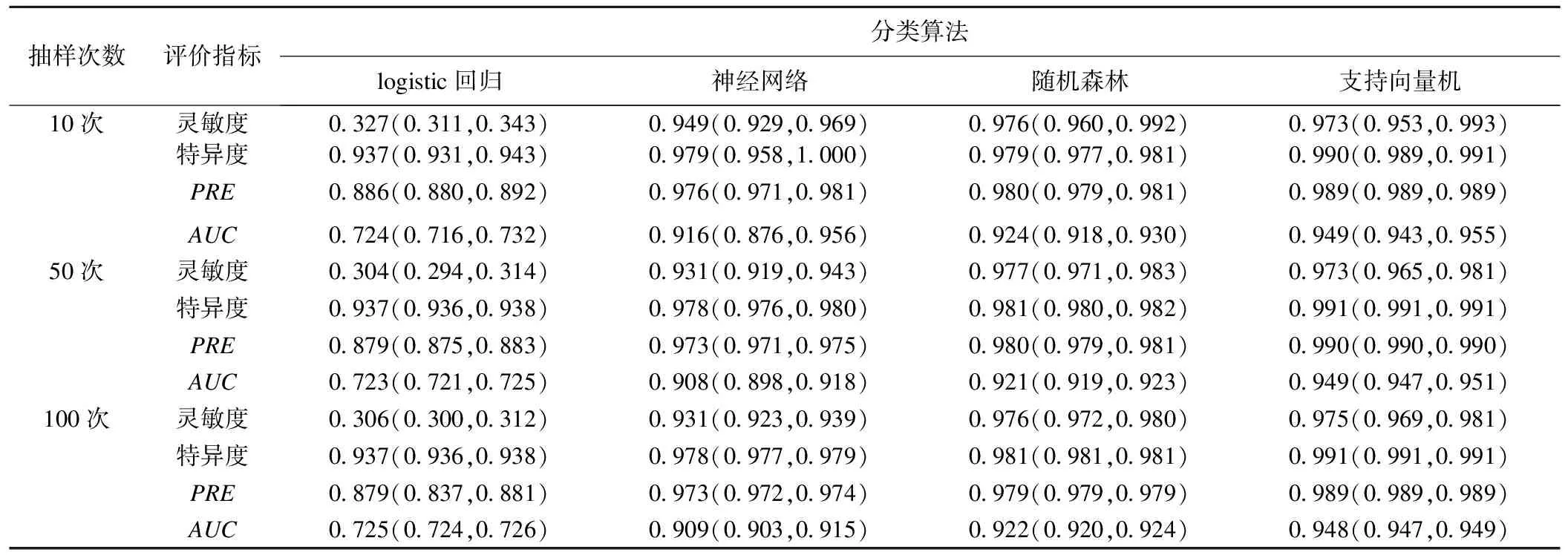
表3 四种分类算法在测试集上的分类效能
4.四种不同分类算法预测性能比较
预测性能用曲线下面积(AUC)来表示,分别经过10次、50次和100次bootstrap重抽样后:logistic回归分类结果对应的AUC分别是为0.724、0.723和0.725;神经网络为0.916、0.908和0.909;随机森林为0.924、0.921和0.922;支持向量机为0.949、0.949和0.948;经过100次重抽样后,相比于logistic回归,神经网络、随机森林和支持向量机的预测性能分别提升了18.4%、19.7%和22.3%,具体可参见表4。
5.变量重要性
图1列出了所有变量的重要性,并使用训练集进行计算,通过设置各种算法的最优参数得到每种算法训练100次后变量的平均重要性。HIV感染的预测算法的变量重要性列于图1。
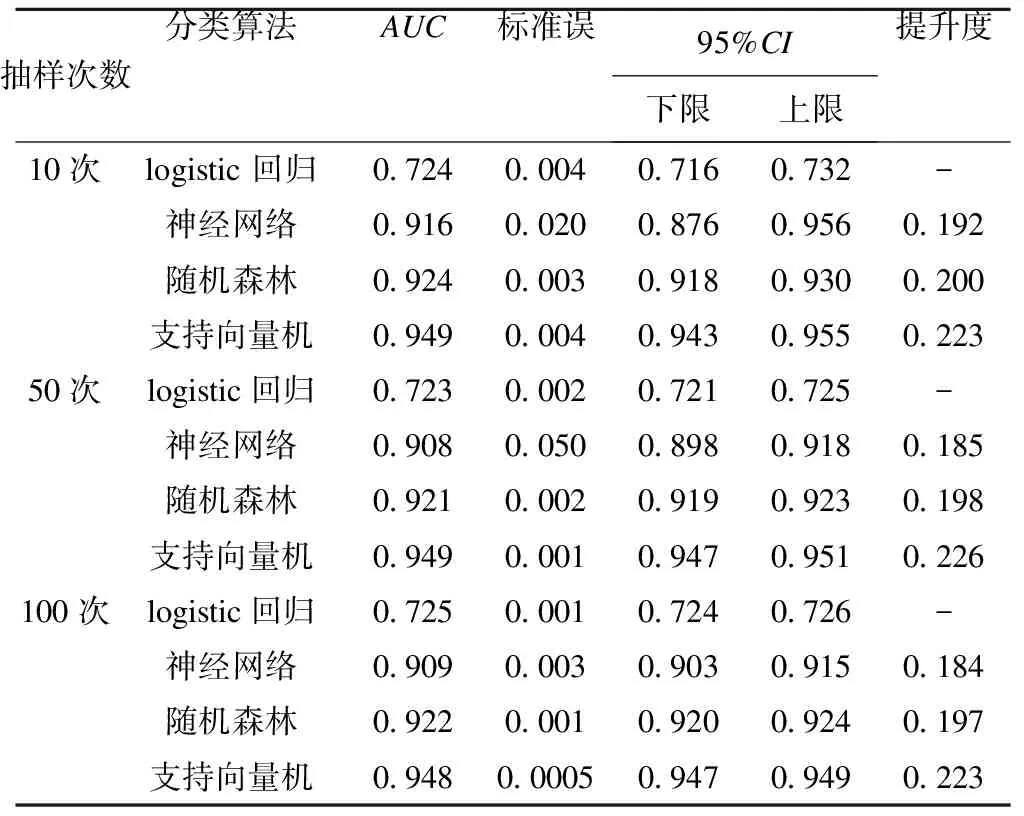
表4 不同分类算法预测男性同性恋人群HIV的比较
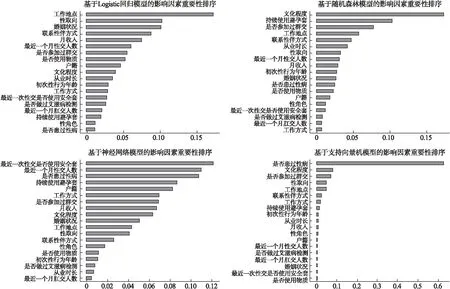
图1 基于机器学习算法的变量重要性
讨 论
男男性行为人群是HIV感染的高危人群[3],近年来的研究发现该人群HIV感染率在10%左右[11]。一方面由于其隐蔽性和不可及性,该人群的健康状况资料较难获得,因此研究该目标人群时常常受到样本量的限制。另一方面,由于HIV的高危性,一旦感染HIV却未得到及时的抗病毒治疗将会导致病情的发展并最终导致艾滋病的发生。因此为了实现基于有限的样本数据,提高分类模型(或分类器)的分类能力的目标,我们尝试采用传统模型和机器学习算法结合,探索适用于男男性行为人群研究的最佳分类器。
本研究是第一次将机器学习算法应用到男男性行为人群中进行分类的研究,采用bootstrap抽样方法用来对数据进行抽样,结果具有较好的稳定性[9],经过100次bootstrap重抽样后,相比于logistic回归,神经网络、随机森林和支持向量机表现出较好的分类效能,所对应的曲线下面积(AUC)分别提高了18.4%、19.7%和22.3%,且支持向量机为最优分类算法,有最高的分类准确度(98.9%)和曲线下面积(94.8%)。
在变量的重要性的计算中,不同的算法具有不同的理论基础[12]。其中logistic回归的变量重要性用回归系数和标准差的乘积来衡量。随机森林是基于平均基尼系数或平均精确度减少量;神经网络使用模型内变量的总体加权;支持向量机则是基于信息值的变化来衡量。结果显示各个变量在不同算法中的重要性大小不一,但是综合上述算法最终结果显示,高危性行为及性病史仍然是影响HIV感染的主要因素,这与之前的研究结果相一致[3],因此洁身自好,养成良好的生活方式仍然是预防HIV感染的关键措施。
随着潜在风险因素的数量增加,模型的复杂性可能导致过度拟合,产生不可信的结果。为了避免该问题,常用的方法包括适当选择预训练、调整超参数、交叉验证、bootstrap和正则化等[13]。本研究中,我们通过对原数据集进行bootstrap重抽样并对结果进行10次、50次和100次的循环来验证用训练样本训练的模型稳定性,对比训练集和测试集的结果显示,两者差异不大,分类效能均比较理想,表明模型的泛化能力比较好;其次通过对机器学习算法中超参数的调整,选择最优的超参数使模型达到最优的分类效能。
作为经典的统计学方法,logistic回归仍然是一个可靠的分类方法,其可以计算出各个变量在模型中的系数以及优势比,各个变量在模型中的作用是清晰、明确的。但是对于非线性可分问题,或处理分类能力有限的变量时表现往往不佳。机器学习算法如神经网络、支持向量机和随机森林已成为统计学研究的热点,因其具有较强自适应、自学习、非线性映射、容错和泛化能力,正在越来越多地被应用到实际问题中。应用神经网络时如何选取合适的隐藏层是其中的关键[6],本研究中选取每次训练结果(AUC)最好时的参数作为每次测试集的最优参数。支持向量机算法在处理高维小样本数据时具有比较好的分类效能。其最优模型参数的选取是基于每次训练过程中模型最优性能时所对应的参数,参数的选取采用3折交叉验证法。随机森林比较适合处理海量数据、高维问题、连续性变量,分类变量等。随机森林在生成过程中采用了bootstrap方法进行重抽样,生成其内部的训练集和袋外数据,通过袋外数据来测试模型的分类性能,这种基于Bagging的思想提升了模型的性能和稳定性[7],但也存在运算量大的局限性。时至今日,机器学习算法的“黑箱”特性仍被诟病,它们不能像logistic回归模型那样描述风险因素变量如何相互作用的复杂性以及它们对结果的独立影响,但数据可视化方法有助于对这些模型的理解[14]。
本研究发现机器学习算法有助于识别未被发现的感染HIV的男男性行为人群,从而做到早发现、早诊断、早治疗的目的,同时也为机器学习算法应用于医学数据开辟了思路。
猜你喜欢
现代电力(2022年2期)2022-05-23
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
恋爱婚姻家庭(2020年27期)2020-10-09
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
百花洲(2018年1期)2018-02-07
瞭望东方周刊(2017年45期)2017-12-08
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
