
基于分布式环境的数据挖掘算法研究
2019-03-15 13:31姜文秀
电脑知识与技术 2019年2期
姜文秀
摘要:随着海量数据处理的关注程度逐渐提升,分布式数据挖掘算法也成为一个热点研究领域。在实际挖掘特定兴趣时,会用到数据挖掘中的关联规则,数据的海量性必然要求采用分布式挖掘方法,以此减轻计算压力。分布式环境中的数据挖掘可以将数据分发到不同节点进行处理,最后将局部结果汇总,从而完成整个计算过程。
关键词:分布式;数据挖掘;关联规则;分类;聚类
中图分类号:G642 文献标识码:A 文章编号:1009-3044(2019)02-0232-02
随着知识发现应用于各个领域,数据挖掘技术扮演的角色也越来越重要;由于通常会涉及海量的数据,因此实际应用数据挖掘过程中通常会采取分布式技术,以缓解海量数据带来的计算压力。
传统的数据挖掘技术存在一个中央服务器,将其他各个节点采集到的数据通过数据仓库汇总到中心服务器后,再进行数据挖掘或其他运算;但是,这种中心化的节点在面临庞大的数据量时可能会存在性能瓶颈;除此之外,其他节点同时将大量的数据汇总到中心服务器时也会需要大量的带宽,而且汇总过程中也还会面临一定的数据安全问题。
分布式数据挖掘算法可以克服传统的数据挖掘算法中存在的中心化单点问题,另外,由于分布式数据挖掘环境是建立在多个服务器上的,因此这种并行计算能力提高了整体的数据挖掘效率;相比传统的数据挖掘算法而言,分布式数据挖掘算法在处理的数据量以及效率方面都有很大的优势。
1 分布式技术
作为基于分布式计算环境的软件,Hadoop能够在很大程度上解决数据不断增长的问题:有一个分布式文件系统HDFS以及分布式编程模型MapReduce。新一代架构的Hadoop2.0支持集群横向扩展,甚至可以支持成千上万台服务器机器,大大提高了计算能力;HDFS文件系统不仅可以处理常见的文本数据,还能够处理结构化及非结构化数据。最重要的是,Hadoop具有强大的容错机制,其冗余备份机制能够有效处理集群节点的异常突发情况。
Hadoop中包含一个分布式存储HDFS,提供了相应的api,以完成诸如创建文件、读写文件、删除/移动文件等操作。Hadoop集群中有一个主控服务器Namenode,负责维护整个HDFS文件系统的目录结构,并管理数据block和其他数据节点之间的关系,还会保存一些元数据信息,比如文件名、文件副本数目和位置等[1]。Hadoop集群中的其他节点是数据节点Datanode,主要功能是存放数据副本。为了实现冗余备份的目的,每个文件都会有多个数据副本。
传统的数据挖掘计算模型中,计算操作一般都是在一台中心服务器上进行,但是单机环境势必会存在计算瓶颈。Hadoop中的MapReduce计算框架可以克服传统的中心式计算的缺陷,在将数据量很大的计算任务分块存储后,把计算问题分解成多个子任务,以此转换为支持并行运行的Map任务和Reduce任务。
可以使用一个计算单词数目的经典程序来分析MapReduce计算模型的分布式计算思想。WordCount程序的设计思路是:把文本文件的内容以单词为依据进行划分,并统计相同單词出现的次数。具体的MapReduce分布式计算过程是[2]:(1)Mapper过程。此阶段的主要任务是从HDFS文件系统中读取数据,并把这些数据转换为数据挖掘算法可以处理的结构;这一阶段会把文本信息以单词为粒度进行拆分,得到形如key-value形式的结果;以拆分的单词Hello出现1次为例,保存结果就是
2 分布式数据挖掘方法
分布式数据挖掘方法涉及很多方面,接下来主要介绍分布式文本分类算法、关联规则算法以及分布式聚类算法。
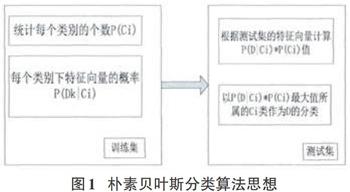
分布式文本分类算法的基础是MapReduce计算思想,并结合了朴素贝叶斯分类算法。朴素贝叶斯分类算法的思想如图1所示:
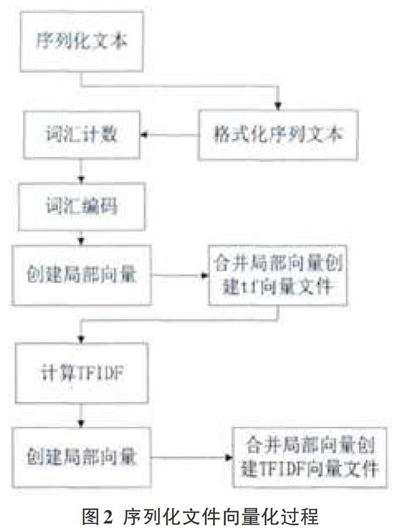
在朴素贝叶斯分类算法的基础上,分布式贝叶斯分类算法主要包括三个过程:使用训练集进行Map操作,使用训练集进行Reduce操作,使用测试集进行Map操作。具体的分类流程是[3]:(1)将文件序列化。Hadoop将普通的文本文件处理为使用key-value格式进行存储的文件类型,key存放目录名或文件名,value存放文件内容。(2)向量化序列文件。把上一步得到的序列化转换为有序字符串列表,即为经过分词后的有序文本信息。用这些有序文本信息生成词频向量,在计算每个词汇出现次数的基础上,把结果保存在wordcount文件内。把序列化文件进行向量化的算法如图2所示。(3)使用训练集生成训练器。根据向量化的序列文件创建缓存,以便存储每个分类label对应的ID,并把每个分类label对应的所有向量汇总起来,得到每个特征的权重。(4)进行分类。前面步骤中得到的
数据挖掘中,关联规则算法的目的是找出数据集中的频繁项集合。FP-Growth是一种常用的关联规则算法,会执行两次遍历数据库的操作:第一次是开始的时候遍历数据库生成单项频繁项集,第二次是进行分布式关联优化,以缓解单机的压力。其主要流程是[4]:(1)样本被分块输入到Hadoop集群中的各个节点,Map程序从HDFS系统中得到本节点的
3 分布式数据挖掘算法的应用
可以将分布式数据挖掘算法应用于微博热点分析,包括数据预处理、文本预处理、特征提取处理、热点分析等步骤。
在分析微博热点时,本文采用的是阿里巴巴天池比赛的新浪微博预测大赛数据,包括了一定时间内新浪微博的用户转发数、评论数以及点赞数等,能够真实反映微博用户的关注领域、评论的心理特征等。
数据预处理是分布式数据挖掘的基础,对于微博数据来说,需要对以下数据进行预处理:一天之内的重复微博数据、以URL为主体的数据。以URL为主体的微博数据可能是网站推广或广告营销,这样的数据如果大量存在,则可以采取过滤删除的处理方式。对于一天内的重复微博数据,则需要根据实际的微博内容进行合并处理。Hadoop平台中的Hive组件可以针对结构化数据文件完成sql操作,sql语句被转换为MapReduce任务运行,实现对数据的预处理。
针对微博数据的短文本特性,从效率方面选择IKAnalyzer分词器对微博数据进行处理。整个数据集分为9个大类,每个类中包括2000个左右训练样本。对于每类数据都挖掘其频繁项,以此作为微博热点博文进行展示。为了去除没有实际意义的词汇,诸如“你”“我”“的”等,在为FP-Growth算法选择输入时,把按照主题划分的分词数据作为输入。
采用k-means算法划分微博的主题,其基本原理是[5]:初始选择若干个聚类中心,然后根据数据和聚类中心的距离,把每个数据划分到最近的聚类;然后计算每个聚类中所有数据的均值,作为新的聚类中心,迭代进行若干次运算,直到满足终止条件。
选择微博数据的转发数、点赞数以及评论数作为特征向量,使用此特征向量实现分布式数据挖掘k-means算法。
4 总结
本文对分布式的数据挖掘算法进行研究,首先简要介绍了分布式技术,并以此为基础阐述了分布式数据挖掘算法;最后,对分布式数据挖掘算法的应用进行了研究。
参考文献:
[1]方少卿,周剑,张明新.基于Map/Reduee的改进选择算法在云计算的Web数据挖掘中的研究[J].计算机应用研究,2018, 14(2):255-279.
[2] 周奇年,张振浩,徐登彩.用于中文文本分类的基于类别区分词的特征选择方法[J].计算机应用与软件,2017(3):15-26.
[3] 陈湘涛,张超,韩茜.基于Hadoop的并行共享决策树挖掘算法研究[f].计算机科学,2013(11):36-39.
[4] Trap N L, Dugauthier Q, Skhiri S. A Distributed Data Mining Framework Accelerated with Graphics Processing Units[C]. International Conference on Cloud Computing & Big Data. IEEE Computer Society, 2017:366-372.
[5]馬青霞,王智钢,李广水.基于RESTFUL的面向服务数据挖掘原型系统的设计与实现[J].计算机应用与软件,2016(2):41-43.
猜你喜欢
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
雷达与对抗(2015年3期)2015-12-09
自动化博览(2014年12期)2014-02-28
电子设计工程(2014年18期)2014-02-27
